こんにちは!シンプルフォームの山岸です。
Glue クローラーで Snowflake テーブルを Glue データカタログ化し、ソース DB とのスキーマドリフトが発生しているかどうかをチェックする方法について考えてみたので、今回はその内容についてご紹介できればと思います。
本記事の背景
当社ではソース DB 上のテーブルを分析用の Snowflake テーブルに再現するにあたり、以下のような ELT アーキテクチャを実装しています。
- ソーステーブルの増分データフレームを Glue ジョブで S3 に出力します。
- S3 に出力されたファイルを Snowpipe 経由でステージングテーブルに取り込みます。このとき、レコード毎に全カラムのデータを VARIANT 型カラム
vにまとめます。 - ステージングテーブルをソースとして dbt ジョブを実行し、分析用テーブルを構成します。dbt ジョブでは、カラムの再構成や id 重複排除などを行います。
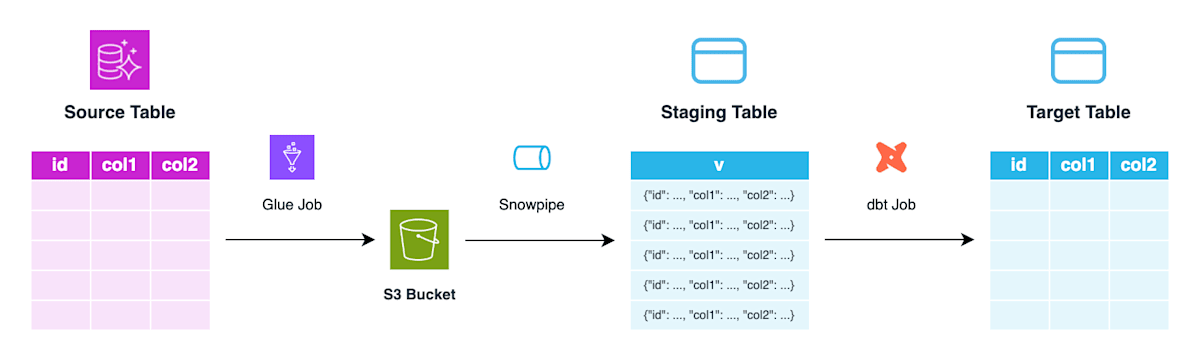
ステージングテーブルからのカラムの再構成については、dbt モデルを定義する CTE (Common Table Expression) の中で明示的にカラム情報を定義しています。ソース DB 側でスキーマ変更が発生し、例えば col3 カラムが追加された場合、モデル定義にも対応するカラムを追加する修正を加える必要があります。
WITH stg_table AS (...)
SELECT v:id::string, v:col1::string, v:col2::number,
FROM stg_table
-- ... 略 ...
しかし、ソースでのスキーマ変更が発生する度に開発者ーデータエンジニア間のコミュニケーションが必要になる、もしくはデータエンジニアが DB マイグレーションを追い続けるのは運用上の負荷が大きいと思います。
上記の課題感を踏まえ、ソース DB 側のテーブルと Snowflake テーブルのスキーマを比較することで、スキーマドリフト発生の有無をチェックできる仕組みを作ってみたいと思います。
調べてみたところ、AWS Glue クローラー のデータソースとして Snowflake にも対応しているようだったので、Snowflake DB のスキーマ情報を AWS 環境内に取り込み、スキーマドリフトチェックのワークロードも AWS 環境内で動かしてみます。
- AWS Glue クローラーで Snowflake のサポートを開始 - AWS What's New (Nov 21, 2022)
- Announcing AWS Glue crawler support for Snowflake - AWS Big Data Blog
アーキテクチャ
実装するアーキテクチャは以下の通りです。
- ソース DB をデータソースとする Glue データカタログ A を作成します。(一般的な構成であるため、本記事では説明を割愛します)
- Snowflake DB をデータソースとする Glue データカタログ B を作成します。
- Glue データカタログ A, B の内容を比較し、検出すべき差分を抽出するスクリプトを用意します。これは Lambda 関数や ECS タスクから実行される想定のものです。

実装
Snowflake テーブルスキーマ抽出
Snowflake テーブルスキーマを抽出するための Glue クローラーと、Glue クローラーから Snowflake DB に接続するのに必要な Glue 接続 を作成します。
Glue 接続
Glue 接続を作成する Terraform コードは例えば以下のようになります。
data "aws_secretsmanager_secret" "default" {
name = var.secrets.default
}
data "aws_secretsmanager_secret_version" "default" {
secret_id = data.aws_secretsmanager_secret.default.id
}
locals {
secret = jsondecode(data.aws_secretsmanager_secret_version.default.secret_string)
# JDBC 接続 URL・オプション
jdbc_connection_url = "jdbc:snowflake://${local.secret.account_identifier}.snowflakecomputing.com/"
jdbc_connection_options_string = join("&", [
"user=${local.secret.username}",
"db=${local.secret.database}",
"role=${local.secret.role}",
"warehouse=${local.secret.warehouse}",
])
}
# Glue 接続
resource "aws_glue_connection" "default" {
name = var.glue_connection_name
connection_properties = {
JDBC_CONNECTION_URL = "${local.jdbc_connection_url}?${local.jdbc_connection_options_string}"
SECRET_ID = data.aws_secretsmanager_secret.default.name
}
physical_connection_requirements {
availability_zone = "ap-northeast-1a"
security_group_id_list = var.network.security_group_ids
subnet_id = var.network.private_subnet_id
}
}
aws_glue_connection の connection_properties.JDBC_CONNECTION_URL に指定する JDBC 接続 URL 形式は以下の通りです。
- URL 形式 ...
jdbc:snowflake://${account_identifier}.snowflakecomputing.com/?user={username}&db={db_name}&role={role}&warehouse={warehouse}
接続オプション user, db, role, warehouse はこの順序で指定する必要があります。[2]
また、接続用 Snowflake ユーザーにデフォルト Warehouse が指定されていれば、warehouse に関しては省略可能であることを確認しました。
Glue クローラー
Glue クローラーを作成する Terraform コードは例えば以下のようになります。
jdbc_target.connection_name には、作成した Glue 接続名を指定します。Snowflake DB 全体を抽出対象とすることも可能ですが、jdbc_target.path を調整することで、特定のスキーマに対象を絞ることも可能です。
IAM ロールには、Glue 接続に指定したシークレットに対する読み取り権限が必要です。
# Glue データカタログデータベース
resource "aws_glue_catalog_database" "default" {
name = "snowflake_datahub_test_schema"
}
# Glue クローラー
resource "aws_glue_crawler" "default" {
database_name = aws_glue_catalog_database.default.id
name = var.glue_crawler_name
role = aws_iam_role.default.arn
jdbc_target {
connection_name = var.glue_connection_name
path = "DATAHUB/TEST_SCHEMA/%"
}
}
作成した Glue クローラーを実行すると、指定の Glue データカタログに各 Snowflake テーブルのスキーマ情報が登録されていることを確認できます。

スキーマドリフト検出
AWS Glue の GetTables API を使用するなどして、ソース・ターゲット両方の Glue データカタログに含まれる DB テーブルスキーマ情報を取得します。これらの内容を比較することでソース DB のみ、もしくはターゲット DB のみに存在するカラムを抽出します。
Python であれば、例えば以下のように実装できます。
Python サンプルコード
EXCLUDED_TABLES = []
def extract_table_info(table: dict):
"""
GetTable, GetTables API のレスポンスのうち、必要な情報のみを取り出す
"""
return {
"name": table["Name"],
"columns": [column["Name"] for column in table["StorageDescriptor"]["Columns"]],
}
def get_all_tables(database_name: str):
"""
指定された Glue データベースに含まれるテーブル情報を取得する
"""
all_tables = []
next_token = None
while True:
if next_token:
response = glue_client.get_tables(DatabaseName=database_name, NextToken=next_token)
else:
response = glue_client.get_tables(DatabaseName=database_name)
tables = [extract_table_info(table) for table in response["TableList"]]
all_tables.extend(tables)
if not next_token:
break
return all_tables
def main():
results = {}
for target_table in get_all_tables(TARGET_DATABASE_NAME):
table_name_without_prefix = target_table["name"].lstrip(f"{TARGET_TABLE_PREFIX}_")
if table_name_without_prefix not in EXCLUDED_TABLES:
response = glue_client.get_table(
DatabaseName=SOURCE_DATABASE_NAME,
Name=f"{SOURCE_TABLE_PREFIX}_{table_name_without_prefix}",
)
source_table = extract_table_info(response["Table"])
source_columns = set(source_table["columns"])
target_columns = set(target_table["columns"])
results[table_name_without_prefix] = {
"SourceOnlyColumns": list(source_columns - target_columns),
"TargetOnlyColumns": list(target_columns - source_columns),
}
print(results)
実装に関する情報は以上です。
さいごに
ソース DB テーブルと Snowflake DB テーブルの間に生じたスキーマドリフトを検出する方法について書いてみました。
Snowflake DB のスキーマ情報を取得するだけであれば、Snowflake REST API で取得するでも良かったような気もしますが、Snowflake DB 側スキーマ情報を別の AWS ワークロードでも利用することなどがあれば、今回のように Glue データカタログ化してみるのも良いかもしれません。
Glue 接続のオプション指定順序など意外にハマりそうなポイントもあるので、何かしら参考になる情報があれば幸いです。
最後まで読んで頂き、ありがとうございました。
-
テーブルスキーマの進化 - Snowflake Documentation ↩︎
-
how to set JDBC connection URL in Crawler - Snowflake Community ↩︎
-
Supported data sources for crawling - AWS Glue User Guide ↩︎
-
Snowflake Strengthens Security with Default Multi-Factor Authentication and Stronger Password Policies - Snowflake Blog ↩︎
-
Snowflake connections - AWS Glue User Guide ↩︎

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion