こんにちは!シンプルフォームの山岸です。
当社では現在、Snowflake をベースとするデータ基盤への移行に向けて、機能・非機能それぞれについて検証・構築を進めています。今回は、機能要件の中でも特に重要な要素である ELT アーキテクチャについて、具体的な実装とともにご紹介できればと思います。
アーキテクチャ
早速本題ですが、移行後のデータ基盤として以下のような ELT アーキテクチャを構築しました。
プロダクト環境として product1, product2 ... のような複数の AWS アカウントが存在しているようなケースを想定します。各環境のプロダクト用 Aurora データベースを、Snowflake 環境上のスキーマとして再現します。
Snowflake 環境にデータを取り込んだ後のモデリングは dbt で行います。Staging 層から実際に利用されるテーブルを再現する部分、ソース DB 用スキーマを参照して mart 以降の層を構築する部分を、それぞれ別の dbt プロジェクトとして作成します。
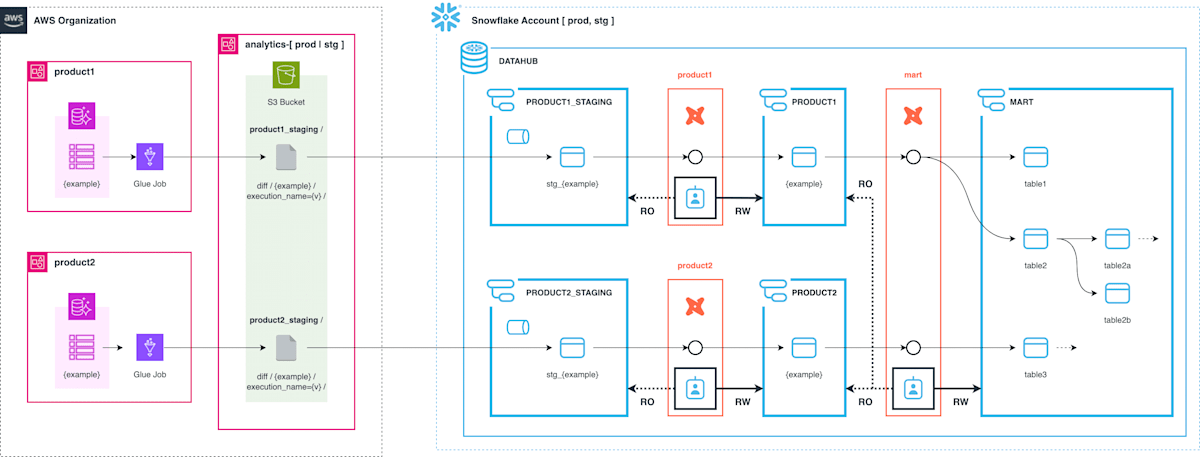
実装の詳細について、以降の章で Load (AWS), Transform (Snowflake) それぞれ説明します。
実装 - Load (AWS)
アーキテクチャ
AWS 環境から Snowflake 環境にデータを取り込む部分のアーキテクチャは以下の通りです。
(大まかには、図の太実線はデータの流れを、破線は処理の流れを示しています)
- スケジュールされた EventBridge ルールなどを起点に、増分更新用の Step Functions (SFN) ワークフローを定期的に実行します。
- SFN ワークフローから呼び出された Glue ジョブが、ソース DB から増分データフレームを取得し、S3 バケットにエクスポートします。
- Glue ジョブがテーブルの出力処理を完了する度に、SNS トピックにメッセージを送信します。このメッセージは、SQS を経由して Lambda 関数がイベントとして受け取ります。
- Lambda 関数は受け取ったメッセージの内容をもとに S3 パスを構成し、テーブルに対応するパイプを実行して Staging 層スキーマの Snowflake テーブルに Ingest します。
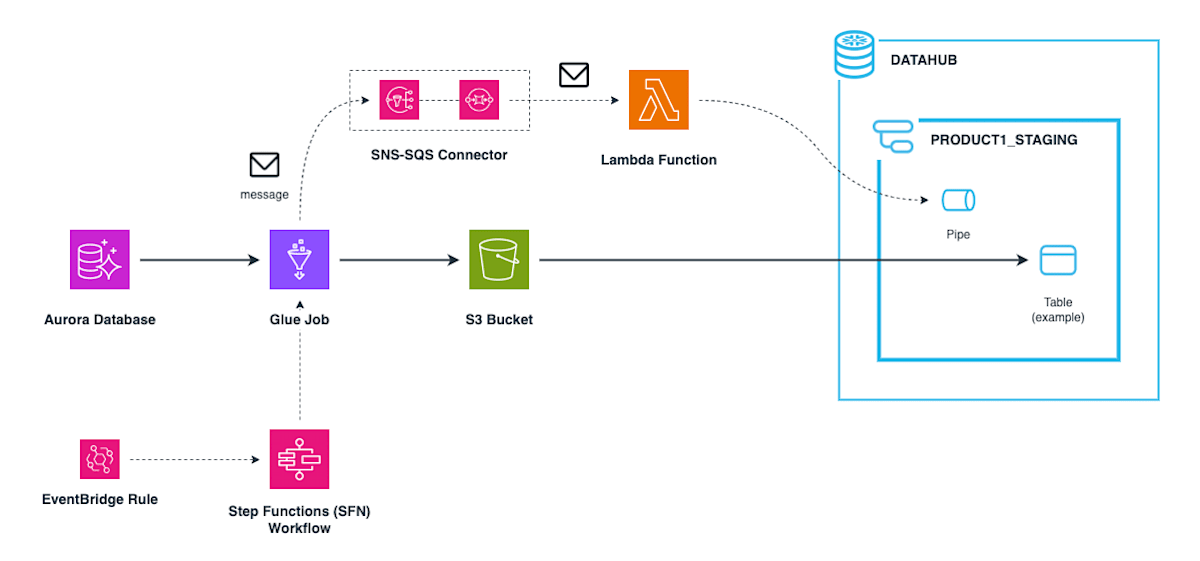
上記アーキテクチャのうち、Glue ジョブと Lambda 関数の実装について以下に解説します。
Glue ジョブ
メインの処理は以下の部分です。連携対象の各テーブルに対して process() に記述された処理を実行しています。実行していることは、ソース DB からデータを読み込み、所定の S3 パスに Parquet 形式でエクスポートすることですが、「データフレーム読み込み」と「メッセージ送信」の実装について、以降に補足します。
def process(table_name: str):
# データフレーム読み込み (後述)
df = load_dataframe(table_name=table_name)
# テーブル固有のカスタム処理
df = custom_processing(df=df, table_name=table_name)
output_s3_uri = f"s3://{DST_S3_BUCKET}/" + os.path.join(
DST_S3_PREFIX,
DST_SNOWFLAKE_DATABASE,
DST_SNOWFLAKE_SCHEMA,
"diff",
table_name,
f"execution_name={EXECUTION_NAME}"
)
print(f"Exporting...: {table_name} to {output_s3_uri}", flush=True)
write_to_s3(df=df, output_s3_uri=output_s3_uri)
# SNS トピックへのメッセージ送信 (後述)
response = publish_to_ingest_db_topic(table_name=table_name)
print(f"Published to SNS: {response}", flush=True)
return
def main():
for table_name in TABLES:
print(f"Processing...: {table_name}", flush=True)
process(table_name=table_name)
データフレーム読み込み
Glue カタログ化されたソース DB から、DynamicFrameReader.from_catalog() を使用してデータフレームを読み込んでいます。この時、sampleQuery オプション [2] を使用して、レコード更新日時カラム updated_at によるソース側での抽出 (= 述語プッシュダウン) を設定しています。
from pyspark.sql import DataFrame
def load_dataframe(table_name: str) -> DataFrame:
def __generate_updated_at_where_clause(start_time: str, end_time: str) -> str | None:
"""updated_at の条件句を生成する"""
if start_time != "-" and end_time != "-":
return f"updated_at >= '{start_time}' AND updated_at <= '{end_time}'"
elif start_time != "-" and end_time == "-":
return f"updated_at >= '{start_time}'"
elif start_time == "-" and end_time != "-":
return f"updated_at <= '{end_time}'"
else:
return None
query = f"SELECT * FROM {SRC_GLUE_TABLE_PREFIX}.{table_name}"
updated_at_where_clause = __generate_updated_at_where_clause(
start_time=TARGET_START_TIME,
end_time=TARGET_END_TIME
)
if updated_at_where_clause:
query += f" WHERE {updated_at_where_clause}"
# 述語プッシュダウンを設定して DataFrame を生成する
df = glue_context.create_dynamic_frame.from_catalog(
database=SRC_GLUE_DATABASE,
table_name=f"{SRC_GLUE_TABLE_PREFIX}_{table_name}",
additional_options={
"sampleQuery": query,
}
).toDF()
return df
メッセージ送信
S3 へのエクスポート完了後、Snowpipe 実行用 Lambda 関数をほぼ同期的に呼び出すため、必要な情報を格納したメッセージを SNS トピックに送信します。メッセージの情報は、Lambda 側で S3 パスを特定するために使用されます。
def publish_to_ingest_db_topic(table_name: str) -> dict[str, str]:
"""
SNS トピックへのメッセージ送信
"""
sns_client = boto3.client("sns")
ingest_db_topic_arn = get_ingest_db_topic_arn(snowflake_account=DST_SNOWFLAKE_ACCOUNT)
message = {
"execution_name": EXECUTION_NAME,
"snowflake_account": DST_SNOWFLAKE_ACCOUNT,
"snowflake_database": DST_SNOWFLAKE_DATABASE,
"snowflake_schema": DST_SNOWFLAKE_SCHEMA,
"table_name": table_name,
"table_layer": "diff",
}
response = sns_client.publish(
TopicArn=ingest_db_topic_arn,
Message=json.dumps(message),
MessageGroupId=EXECUTION_NAME,
MessageDeduplicationId=str(uuid.uuid4()),
)
return {
"MessageId": response["MessageId"],
"SequenceNumber": response["SequenceNumber"],
}
Lambda 関数
Snowpipe を実行する Lambda 関数の実装については、以下のエントリで詳細に扱っています。
SimpleIngestManager オブジェクトの生成などについては割愛しますが、本記事ではハンドラ関数の部分を取り上げます。この Lambda 関数が実行されると、Snowpipe の COPY ステートメントで指定しているテーブル stg_{example} の v カラム (VARIANT 型) にロードされます。
@logger.inject_lambda_context(log_event=True)
def handler(event, context):
if "Records" in event:
# SQS のポーリングでメッセージを受信した場合
assert len(event["Records"]) == 1, "Only one record is expected"
message = json.loads(event["Records"][0]["body"])
m = EventMessage.model_validate(message)
else:
# 直接呼び出しの場合
m = EventMessage.model_validate(event)
# S3 パスを構成
pipe_path = os.path.join(
"integrations",
m.snowflake_database,
m.snowflake_schema,
"diff",
m.table_name,
)
s3_prefix = os.path.join(pipe_path, f"execution_name={m.execution_name}")
# Ingest 対象のオブジェクト群を、StagedFile (名前付きタプル) のリストとして定義
object_keys = get_object_keys(bucket_name=BUCKET_NAME, prefix=s3_prefix)
filename_list = [os.path.basename(key) for key in object_keys]
staged_file_list = []
for filename in filename_list:
staged_file_path = os.path.join(f"execution_name={m.execution_name}", filename)
staged_file_list.append(StagedFile(staged_file_path, None))
try:
# SimpleIngestManager オブジェクトを使用してデータを取り込む
ingest_manager = create_ingest_manager(m.secret_name, m.qualified_pipe_name)
response = ingest_manager.ingest_files(staged_file_list)
logger.info(response)
return {"statusCode": 200, "body": response}
except Exception as e:
logger.exception(e)
return {"statusCode": 500, "body": str(e)}
実装 - Transform (Snowflake)
Snowflake 環境内での dbt を用いた Transform の実装について以下に説明します。
Staging 層のテーブル PRODUCT1_STAGING.STG_EXAMPLE から、ソース DB と同じテーブルスキーマを持つテーブル PRODUCT1.EXAMPLE を生成する部分を扱います。(アーキテクチャ全体像の中の、赤枠の部分)
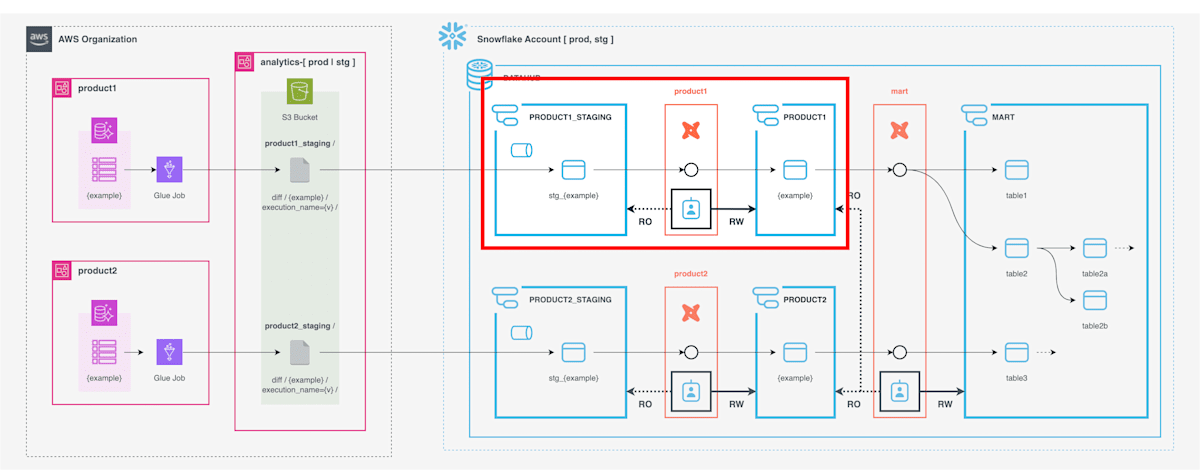
dbt モデルの実装
増分更新を実現するため、dbt の incremental モデル [3] で実装します。
モデル定義全体を以下に示します。最後の SELECT で指定しているカラム名のリストは例ですが、実際のソース DB スキーマに存在するカラムを指定することを想定しています。本記事の文脈で重要な意味を持つカラムは、id (主キー) と updated_at (レコード更新日時) の2つです。
-- 1. incremental モデルの設定
{{
config(
materialized='incremental',
unique_key='id',
)
}}
-- 2. Staging 層の参照
WITH stg_example AS (
SELECT v FROM {{ source('product1_staging', 'stg_example') }}
{% if is_incremental() %}
AND updated_at >= (select coalesce(max(updated_at), '1900-01-01 00:00:00') from {{ this }})
{% endif %}
),
-- 3. 行番号を付与
stg_example_ranked AS (
SELECT
v,
ROW_NUMBER() OVER (PARTITION BY v:id ORDER BY v:updated_at DESC) AS row_num
FROM
stg_example
)
-- 4. テーブルの更新
SELECT
v:id::string AS id,
v:note::string AS note,
parse_json(v:content::string) AS content,
v:created_at::timestamp AS created_at,
v:updated_at::timestamp AS updated_at,
v:deleted_at::timestamp AS deleted_at,
FROM
stg_example_ranked
WHERE
row_num = 1
id 重複排除
上記モデルのうち、id 重複排除の実装箇所について補足します。
Staging 層から読み込んだデータフレームをそのまま挿入してしまうと id 重複が生じる可能性があるため、同一 id 内でユニークな連番 row_num を振った中間テーブル stg_example_ranked を設けています。連番は、updated_at カラムが新しいほど若い番号を与えます。
最後の SELECT 実行の際、WHERE 句で row_num が最小値 1 のレコードのみを抽出することで、ターゲットのスキーマでは最新のレコードのみを保持し、id 重複を排除できます。
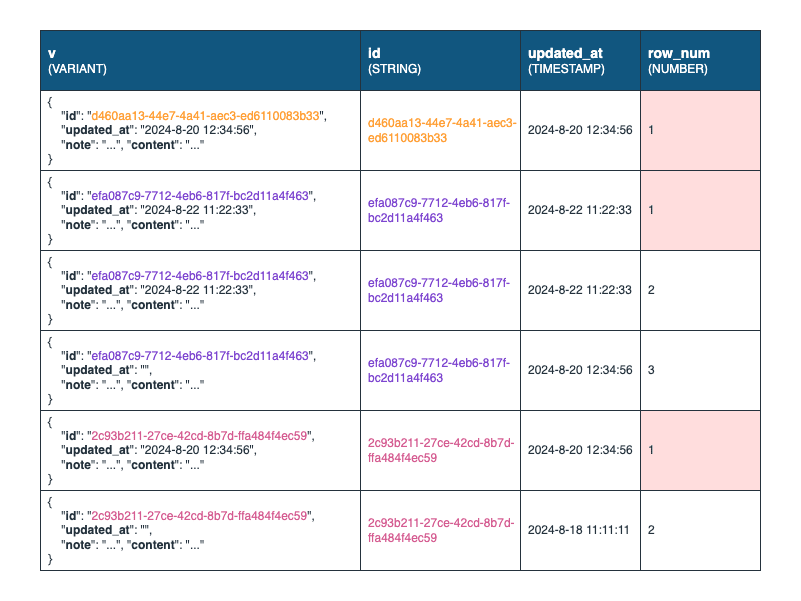
stg_example_ranked のイメージ
モデルの更新
こちらのモデルに対して run を実行すると、増分更新になります。カラムが追加された場合など、モデル全体を構築し直す必要がある場合は --full-refresh オプションを同時に指定します。
# 通常の増分更新
% dbt run --select example
# モデル全体の再構築
% dbt run --select example --full-refresh
データテスト
schema.yml に、該当モデルの data_tests として主キーが満たすべき unique と not_null を追加してみます。test を実行すると、Staging 層で id 重複がある場合でも、ターゲットのスキーマでは id のユニーク性が担保されていることを確認できます。
version: 2
models:
- name: example
columns:
- name: id
description: "Primary Key"
data_tests:
- unique
- not_null
% dbt test --select example
01:11:15 Running with dbt=1.8.0
01:11:16 Registered adapter: snowflake=1.8.3
01:11:16 Found 2 models, 2 data tests, 2 sources, 448 macros
01:11:16
01:11:18 Concurrency: 1 threads (target='dev')
01:11:18
01:11:18 1 of 2 START test not_null_example_id ......................................... [RUN]
01:11:19 1 of 2 PASS not_null_example_id ............................................... [PASS in 1.86s]
01:11:19 2 of 2 START test unique_example_id ........................................... [RUN]
01:11:20 2 of 2 PASS unique_example_id ................................................. [PASS in 0.85s]
01:11:20
01:11:20 Finished running 2 data tests in 0 hours 0 minutes and 4.17 seconds (4.17s).
01:11:20
01:11:20 Completed successfully
01:11:20
01:11:20 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
さいごに
Snowflake × dbt を使用した ELT アーキテクチャの実装について書いてみました。
dbt は今回のデータ基盤移行の中で初めて触ってみましたが、モデリングの柔軟性やテスト追加のしやすさなど、非常に強力なツールであることを早くも実感することができました。
実運用を考慮したとき、今後取り組んでいきたい検証などにも触れたかったのですが、長くなりすぎてしまうのでまた別の機会に譲りたいと思います。
今回もたくさんの先人の発信に助けて頂きました。この場を借りて感謝申し上げたいと思います。
最後まで読んで頂きありがとうございました。
参考記事
- Snowflake x dbt x Terraform マルチデータプロダクト基盤 [DataOps Night #4] - SpeakerDeck
- dbt 入門 - Zenn 本
- dbtで始めるデータパイプライン構築〜入門から実践〜 - Zenn 本
- Snowflake + dbt におけるELT処理の私的ベストプラクティス - Zenn
- dbt-snowflake で delete+insert の incremental model を実装する際には join の爆発に気をつけよう - Medium
- Snowflakeを使って高速に差分更新するようなデータ基盤を作る - Qiita
- 【dbt小ネタ】 ログの集計 : incremental モデルの実運用 (upsert, リカバリ手法や自動復旧の実現) - Kayac engineers' blog
-
Amazon S3 用 Snowpipe の自動化 - Snowflake Documentation ↩︎
-
AWS Glue ETL のプッシュダウンによる読み取りの最適化 - AWS Glue ユーザーガイド ↩︎
-
Configure incremental models - dbt docs ↩︎

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion