こんにちは!シンプルフォームの山岸です。
Snowflake への ELT において、ソースから抽出したデータを参照用テーブルに直接ロードせず、一旦ステージングテーブルを挟んで重複排除などを施してからロードする、という構成は割と一般的かと思います。今回、このステージングテーブルに対する「Cleanup 処理」を Stored Procedure を用いて実装してみたので、本記事ではその内容についてご紹介したいと思います。
Cleanup 処理について
前提
Snowflake データ基盤への ELT の定常状態は以下のようになっています。
- ソース DB から増分データフレームを抽出し、一旦ステージングテーブルにロードします。
- dbt incremental モデルを使用して id 重複排除 等を施し、参照用テーブルとして構成します。

課題感
ステージングテーブルに関する課題感として、以下のようなものが挙げられます。
- 不要なデータが堆積し、ストレージコストの上昇につながる
- ソース DB における物理削除をターゲット側に反映できない

不要なデータが堆積し、ストレージコストの上昇につながる
ステージングテーブルには、更新日時を表す updated_at のようなカラムを元に、増分データフレームを追記していきます。ターゲットテーブルを構成する際は最新のレコードのみが保持されるよう処理を挟みますが、ステージングテーブルには更新前の古いレコードも保持され続けます。
テーブルのデータ量や更新頻度にもよりますが、不要なデータのストレージコストが無視できない規模感になってくるかもしれません。
ソース DB における物理削除をターゲット側に反映できない
より問題なのは、ソース DB における物理削除が発生した際に、増分データフレームには削除されたレコードに関する情報がないため、ターゲット側に反映できないことです。
変更データキャプチャ (CDC) 等で削除イベントを保持していれば何らかの方法で反映できそうですが、このためだけに CDC を実装するというのもコストに見合わないように思います。
Cleanup 処理とは
上記の課題感を踏まえ、本記事では以下のレコードを削除する処理を以後「Cleanup 処理」と呼称するもとのします。
- id に対して更新日時が最新でなく、ターゲットテーブルの構成において不要になったレコード
- ソース DB において削除され、ターゲットテーブルからも削除されるべきレコード
実行手順
0. id 全量出力 / 1. Cleanup 済み tmp テーブルの作成

0. id 全量出力
Cleanup 処理の事前準備として、「id 全量出力」を実行します。本記事では、「その時点でテーブルが保持する全ての id を抽出し、Snowflake テーブル ids_{table_name} にロードしておく処理」を意味するものとします。
1. Cleanup 済み tmp テーブルの作成
Cleanup 対象となるステージングテーブル、および ID テーブルを入力として、以下の CTAS クエリで cleanup 済みの tmp テーブル stg_{table_name}_tmp を新規に作成します。
CREATE TABLE stg_${TABLE_NAME}_tmp AS
WITH ranked AS (
SELECT
stg.v,
ROW_NUMBER() OVER (
PARTITION BY stg.v:id ORDER BY stg.v:updated_at DESC
) AS row_num
FROM stg_${TABLE_NAME} stg
INNER JOIN ids_${TABLE_NAME} ids ON stg.v:id = ids.v:id
)
SELECT ranked.v
FROM ranked
WHERE row_num = 1;
2. テーブル名交換 / 3. tmp テーブル削除

2. テーブル名交換
新規作成した Cleanup 済みテーブルを今後のステージングテーブルとして使用していきたいので、ALTER TABLE SWAP の機能を使用して stg_{table_name} と stg_{table_name}_tmp の間でテーブル名交換を行います。
ALTER TABLE stg_${TABLE_NAME} SWAP WITH stg_${TABLE_NAME}_tmp;
3. tmp テーブル削除
テーブル名交換後の tmp テーブルは保持するデータが Cleanup 処理前のものであり、以後不要なのでテーブルごと削除します。
DROP TABLE stg_${TABLE_NAME}_tmp;
Stored Procedure 実装
複数の SQL ステートメントを必要とし、頻繁に実行されるタスクを自動化するようなケースにおいて、Snowflake の Stored Procedure を使用することができます。
前述の [ 実行手順 ] にある一連の処理を、Stored Procedure として実装してみます。
ステートメント
JavaScript の場合、Procedure に設定するステートメントの実装は例えば以下のようになります。
TABLE_NAME を入力とし、そのテーブルを対象に Cleanup 処理を実行します。
var TABLE_NAME;
var create_cleansed_table_sql = `
CREATE TABLE stg_${TABLE_NAME}_tmp AS
WITH ranked AS (
SELECT
stg.v,
ROW_NUMBER() OVER (PARTITION BY stg.v:id ORDER BY stg.v:updated_at DESC) AS row_num
FROM stg_${TABLE_NAME} stg
INNER JOIN ids_${TABLE_NAME} ids ON stg.v:id = ids.v:id
)
SELECT ranked.v
FROM ranked
WHERE row_num = 1
`;
var swap_table_sql = `ALTER TABLE stg_${TABLE_NAME} SWAP WITH stg_${TABLE_NAME}_tmp`;
var drop_tmp_table_sql = `DROP TABLE stg_${TABLE_NAME}_tmp`;
try {
snowflake.execute({sqlText: create_table_sql});
snowflake.execute({sqlText: swap_table_sql});
snowflake.execute({sqlText: drop_tmp_table_sql});
return 'Procedure executed successfully';
} catch (err) {
return 'Error: ' + err.message;
}
Terraform + Terragrunt
Terraform モジュール
Terraform モジュールの実装は例えば以下のようになります。
前述のステートメントは snowflake_procedure リソースの statement 属性に、Terraform の file() 関数を使用して設定しています。
resource "snowflake_procedure" "default" {
for_each = var.procedure_configs
name = upper(each.key)
language = "JAVASCRIPT"
comment = "JavaScript procedure for '${each.key}'"
database = local.database_name
schema = local.schema_name
statement = file("statements/src/${each.key}.js")
return_type = each.value.return_type
dynamic "arguments" {
for_each = each.value.arguments
content {
type = arguments.value.type
name = arguments.value.name
}
}
execute_as = each.value.execute_as
null_input_behavior = each.value.null_input_behavior
}
variable "procedure_configs" {
type = map(object({
return_type = string
arguments = list(object({
name = string
type = string
}))
execute_as = optional(string, "CALLER")
null_input_behavior = optional(string, "RETURNS NULL ON NULL INPUT")
}))
}
ステートメント(ハンドラ)の設定方法なども含め、基本的には以下の記事でご紹介している Snowflake UDF / UDTF と同様のモジュール構成です。
terragrunt.hcl
Terragrunt を利用している場合、モジュール呼び出し用の子 terragrunt.hcl は以下のようになります。
include "root" {
path = find_in_parent_folders()
}
terraform {
source = "${dirname(find_in_parent_folders())}/modules/(path-to-module)/"
}
inputs = {
procedure_configs = {
cleanup_staging_table = {
arguments = [
{ type = "VARCHAR", name = "TABLE_NAME" },
]
return_type = "VARCHAR"
}
}
}
動作確認
検証用に以下のようなデータを用意します。
# For stg table
stg_records = [
("0001", "Alice", "2024-10-01 09:00:00"),
("0002", "Bob", "2024-10-01 09:00:00"),
("0003", "Charlie", "2024-10-01 09:00:00"),
("0003", "Carol", "2024-10-02 10:00:00"),
("0004", "Dave", "2024-10-02 10:00:00"),
("0002", "Bill", "2024-10-03 11:00:00"),
("0005", "Ellen", "2024-10-03 11:00:00"),
("0004", "David", "2024-10-04 09:00:00"),
("0006", "Frank", "2024-10-04 11:00:00"),
("0006", "Frank", "2024-10-04 11:00:00"),
]
# For ids table
ids_records = [("0002", ), ("0004", ), ("0005", ), ("0006", )]
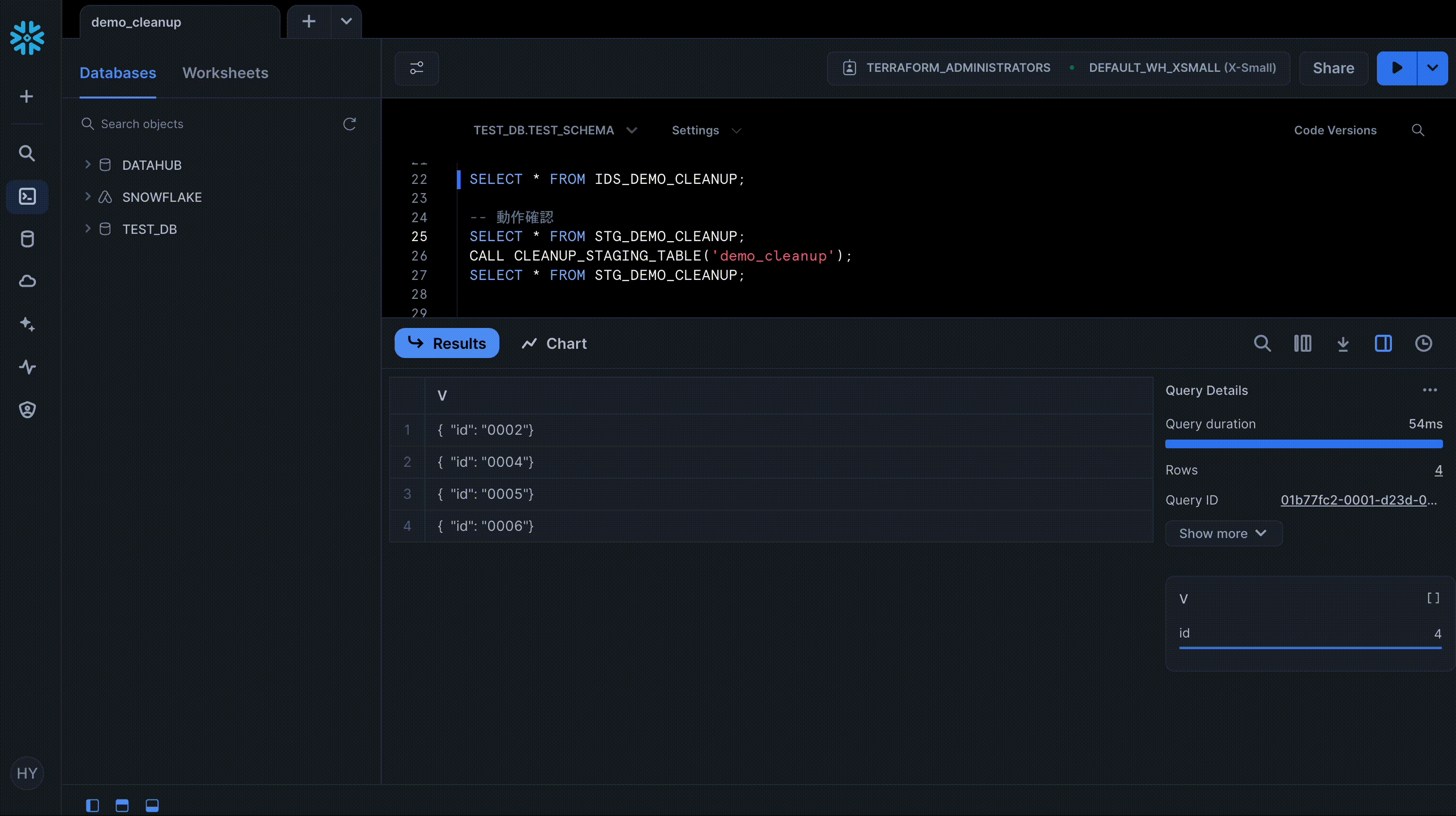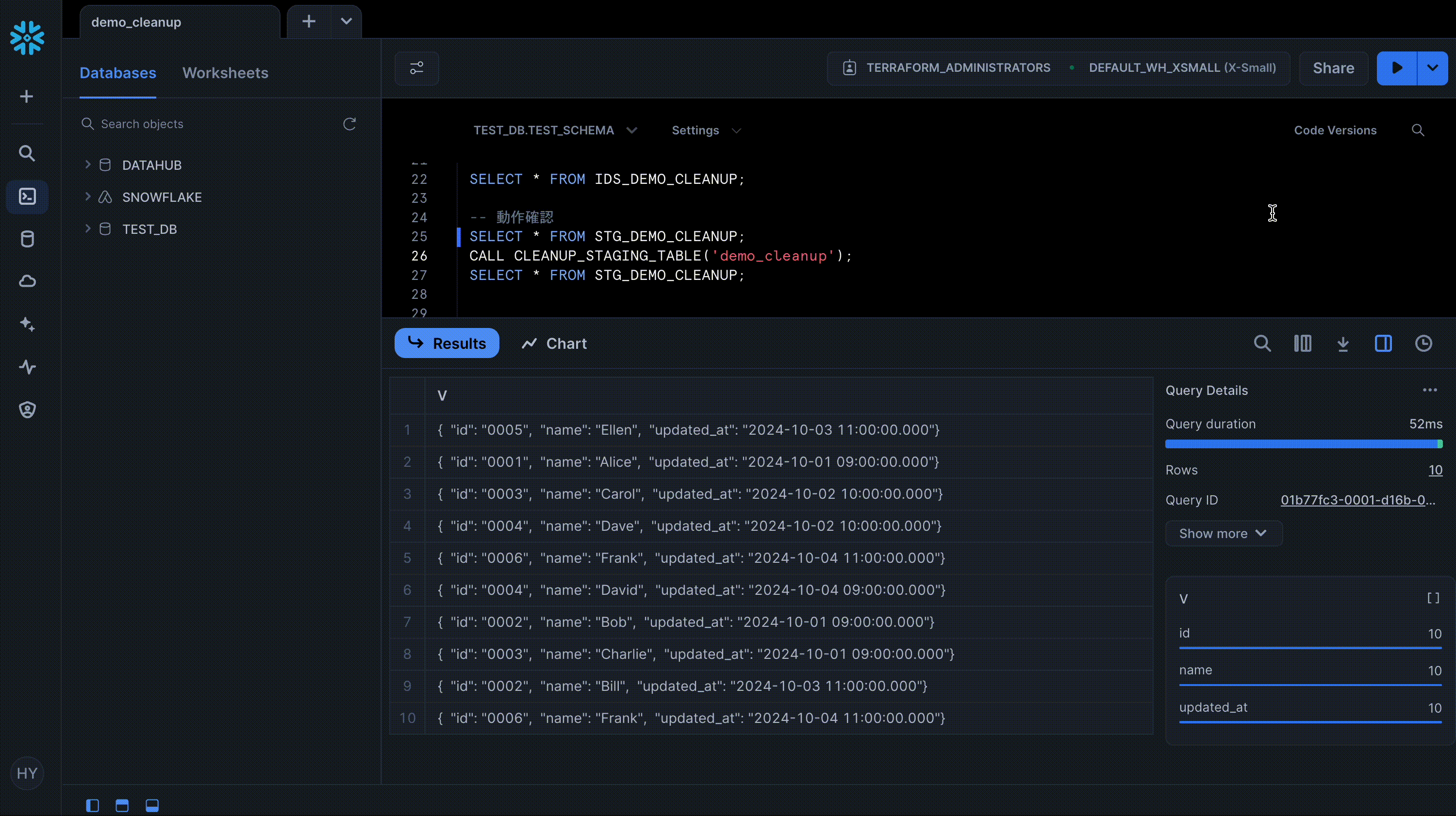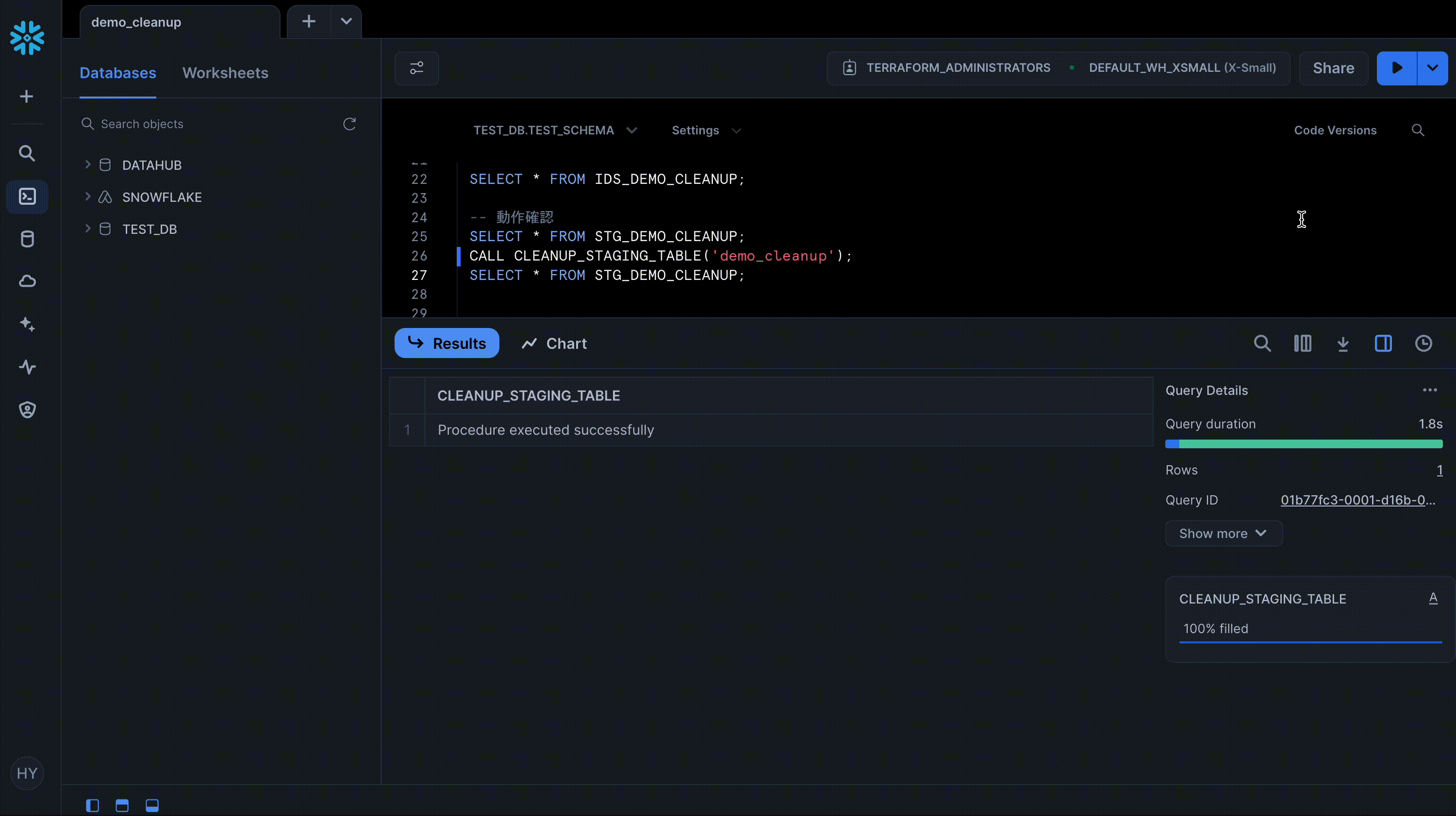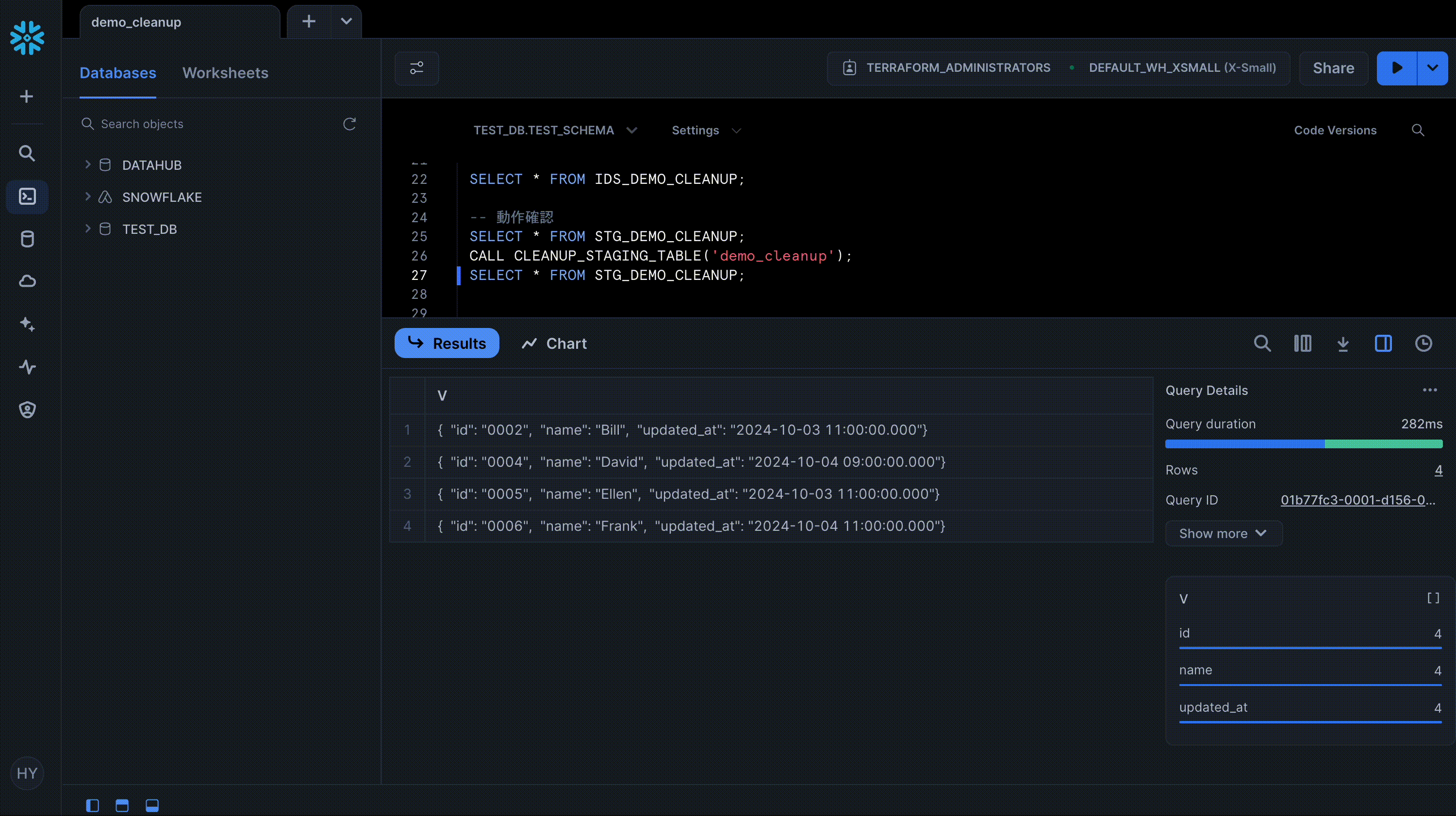
要件に照らして、想定される結果セットは以下の通りです。
results = [
("0002", "Bill", "2024-10-03 11:00:00"),
("0004", "David", "2024-10-04 09:00:00"),
("0005", "Ellen", "2024-10-03 11:00:00"),
("0006", "Frank", "2024-10-04 11:00:00"),
]
作成した Procedure を CALL して前後の結果を比較すると、削除されるべきレコードがきちんと削除されていることを確認できます。
SELECT * FROM STG_DEMO_CLEANUP;
CALL CLEANUP_STAGING_TABLE('demo_cleanup');
SELECT * FROM STG_DEMO_CLEANUP;
内容は以上です。
さいごに
ELT におけるステージングテーブルの Cleaup 処理を、Snowflake の Stored Procedure で実装してみる、という内容で書いてみました。
ソース DB における物理削除を運用として禁止している場合には、今回取り上げた機構を実装する必要性は下がりますが、テーブルによってはこの制約をなかなか徹底しきれないケースもあるのではないでしょうか。ソース側とターゲット側でレコード件数の不一致があった際に、整合性を回復する手段があるというのは、運用において一定の安心になるのではないかと思います。
最後まで読んで頂き、ありがとうございました。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion