はじめに
データソリューション事業部の宮澤です。
私はこれまで言語処理系のコンペに参加することが多く、実務でもLLMやマルチモーダルLLMを用いていました。一方で、画像系のモデリング技術も身につけたいと考え、今回は過去に開催された画像コンペであるatmaCup#18の復習に取り組みました。本記事はその取り組みについてまとめたものとなります。これから画像コンペや画像を用いたタスクに取り組む方の参考になれば幸いです。
本記事はDAL Tech Blog Advent Calendar 2025として投稿しました。全ての記事は以下からご確認いただけます。
atmaCup#18について
当時の参加記録は以下の記事に記しています。
コンペの概要についてはatmaCup公式ページもしくは以下の記事をご覧ください。
簡単なタスク概要は以下の通りで、画像とテーブル情報をもとに車両の将来位置をx(前後), y(左右), z(上下)の3軸でそれぞれ6時点分の計18の予測を行うものです。

atmaCup #18 参戦記(Public7位→Private17位)より引用
評価指標は予測値全体に対しての平均絶対誤差(Mean Absolute Error)です。
データについて
画像とテーブル情報になります。データについての詳細も上の記事に記載しておりますので、そちらをご参照ください。
当時の振り返り
本コンペでは当時CNNとLightGBMを用いたノートブック共有され、これが精度が高く使いやすいノートブックであったため、多くの参加者はこちらを利用していたと思われます。(閲覧にはユーザー登録とログインが必要です。)
私たちのチームも例に漏れず、こちらのノートブックを転用させていただいていました。しかし、当時は技術力と時間の問題で、公開ノートブックのbackboneを変えたりハイパーパラメータを変更したりアンサンブルを増やしたりと、ちょっとしたカスタマイズまでしか取り組むことができませんでした。
今回は画像を入力としたモデリングをしっかりと技術として身につけたいという意図があったため、こちらのノートブックは参考程度として、できるだけ自らの手(+AIコーディング)でゼロからモデルを実装することを試みました。
また、当時はCNN→GBDT(スタッキング)という2-stageのパイプラインを組んでいましたが、今回は特に画像モデリングの技術と知識を身につけたいという目的があったため、GBDTを使わない1-stageのみで精度を高めることを試みました。
取り組んだこと
基本的には1st Solutionを参考にさせていただき、それをなぞる形で自分の手(+AIコーディング)で実装と実験を試みました。
- シンプルなCNNでのベースラインの作成
- backboneの差し替え
- テーブル特徴量の組み込み
- Projecorの改善
- 補助ロスの導入
- 周辺フレームを用いたLSTMの組み込み
- データ拡張
- VLM特徴量の組み込み(※)
(※)…上位解法にはありませんでしたが独自の取り組みとして試したものです。
解法アイデアは以下の資料を参考にさせていただきました。
1. シンプルなCNNでのベースラインの作成
まずはシンプルなCNNでベースラインとなるパイプライン作成に取り組みました。上述の通り、コンペ当時は公開ノートブックを用いていたので、ここをゼロから作っていくのが勉強になったと同時に大変な部分でした。ただ単にデータをロードしてモデルに流せばよいだけではなく、後に工夫を加えたり、実験結果を管理することを考えて拡張性のあるコードにする必要があり、その点に難しさを感じました。
実験準備
編集や管理をしやすくするために、諸々の設定はdataclassを用いて管理しました。
@dataclass
class PathsCfg:
images_dir: Path = Path("../atmacup18_dataset/atmaCup#18_dataset/images/")
train_features_dir: Path = Path("../atmacup18_dataset/atmaCup#18_dataset/train_features.csv")
test_features_dir: Path = Path("../atmacup18_dataset/atmaCup#18_dataset/test_features.csv")
folds_dir: Path = Path("../outputs/folds")
models_dir: Path = Path("../models")
submit_path: str = "../submissions/{exp_name}_oofmean.csv"
@dataclass
class DataCfg:
id_col: str = "ID"
group_col: str = "scene"
skf_col: str = "class"
suffixes: Tuple[str, str, str] = ("image_t-1.0.png", "image_t-0.5.png", "image_t.png")
target_cols: Optional[List[str]] = field(
default_factory=lambda: [f"{ax}_{t}" for t in range(6) for ax in ("x", "y", "z")]
)
num_workers: int = 8
prefetch_factor: int = 4
また、実験管理のツールとしてはwandbを利用しました。
モデル構築
ここからはモデル構築についてですが、まずは以下のように畳み込み層を複数重ねたシンプルで小さいモデルを構築しました。また、画像は1行のデータにつき3枚(時点順)あるため、RGBの3チャネル*3枚=9チャネルとしてモデルに入力するようにしました。
def __init__(self, in_ch=9, out_dim=18):
super().__init__()
self.backbone = nn.Sequential(
nn.Conv2d(in_ch, 32, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d(1),
)
self.head = nn.Sequential(
nn.Flatten(),
nn.Linear(128, 128),
nn.ReLU(inplace=True),
nn.Linear(128, out_dim),
スコアは以下の通りです。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
2. backboneの差し替え
次に、画像モデリングでよく使われているtimmというライブラリを用いて既存の事前学習済みモデルを使うことを試みました。まずは残差ブロックを導入して勾配消失問題を解決したことでよく知られるResNetを用いました。初期層での改良が入っているResNet34dを用いることとしました。また、後継のモデルであるConvNextに差し替えての実験も行いました。backboneで特徴抽出して最後にLinear headを設ける形となっています。
lass CustomModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.backbone = timm.create_model(
cfg.model.backbone,
pretrained=cfg.model.pretrained,
in_chans=cfg.model.in_ch,
num_classes=0,
global_pool="avg",
)
feat_dim = self.backbone.num_features
# Linear 1層ヘッド
self.head = nn.Linear(feat_dim, cfg.model.out_dim)
backboneのモデルを差し替えることで精度が大きく向上しました。
cv, public ともにconvnext_largeが大きく上回っていたため、以降の実験ではこのモデルを使うことにしました。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
3. テーブル特徴量の組み込み
ここまでは画像のみで推論をしていましたが、テーブルデータとしても速度・加速度・ハンドル角など様々存在するため、これらをモデルに組み込むことを試みました。組み込む方法としては、conv_nextから得られた特徴量と、標準化したテーブル特徴量をProjectorに通した出力と結合して、最後にLinearを通す形としました。

# テーブル特徴量を処理する層
class TabularMLP(nn.Module):
def __init__(self, cfg):
super().__init__()
layers: list[nn.Module] = []
current_dim = cfg.model.tab_in_dim
for hidden_dim in cfg.model.tab_hidden:
layers.extend([
nn.Linear(current_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim) if cfg.model.tab_use_bn else nn.Identity(),
nn.ReLU(),
nn.Dropout(p=cfg.model.tab_dropout),
])
current_dim = hidden_dim
self.net = nn.Sequential(*layers)
self.out_dim = current_dim
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
# 画像を処理してテーブル処理層と結合する
class CustomModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.backbone = timm.create_model(
cfg.model.backbone,
pretrained=cfg.model.pretrained,
in_chans=cfg.model.in_ch,
num_classes=0,
global_pool="avg",
)
feat_dim = self.backbone.num_features
self.tab_mlp = TabularMLP(cfg)
fusion_in_dim = feat_dim + self.tab_mlp.out_dim
self.head = nn.Linear(fusion_in_dim, cfg.model.out_dim)
def forward(self, x_img: torch.Tensor, x_tab: torch.Tensor) -> torch.Tensor:
feats = self.backbone(x_img) # (B, feat_dim)
t = self.tab_mlp(x_tab) # (B, tab_dim)
fused = torch.cat([feats, t], dim=1) # (B, feat_dim + tab_dim)
out = self.head(fused) # (B, out_dim)
return out
スコアは以下の通りで、ここで大きく改善されました。やはり画像からの情報だけでは車両がどの方向にどのくらい進むかは予測しづらく、(当たり前のことですが)現在の速度やハンドル角といった情報が将来の予測に効いているのだと実感しました。Projectorの隠れ層の数を増やしてMLP構成にしたり、次元数を小さくしたりといくつかの設定で試しましたが、Linear層1つと活性化関数で次元が256の場合が最もCVがよかったためこちらを採用しました。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
4. Projectorの改良
Projectorについて調べているうちに、標準化したテーブル特徴量であれば、負の値を全てdropするReLUよりも0以下も滑らかに重み付けして残すGELUの方が情報保持量が大きいと考えられるという情報を目にして、今回は標準化を行なっていたのでGELUへの差し替えをして実験してみました。(理論的に厳密にどちらが今回のタスクに適しているかまでは理解が及んでいません。)
結果としてcvとpublicのスコアが僅かに改善されました。以降の実験ではGELUを用いています。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
| ProjectorのReLUをGELUに変更 | 0.24145 | 0.2395 | 0.2195 |
また、上の表へは記載していませんが、Projectorの中にBatchNormの層を入れていると学習がうまく進みませんでした。事前に標準化をしていることや、カテゴリ変数の0/1に偏りがあったことが原因かと考えられました。したがって上の結果はBatchNormを除いて学習したものです。
5. 補助ロスの追加
MLコンペでは補助ロスを実装することで精度改善した事例がよくあります。私はこれまでLLM系のコンペに参加することが多かったため補助ロスを実装しようという機会があまりなかったのですが、上位解法にならって実装を試みました。
補助ターゲットとしてはメインターゲットである6時点 * 3座標の情報を使って算出した各時点の「速度」と「加速度」としています。(1st Solutionを参考にしています。)
速度は時点位置と時間から算出し、加速度は速度の変化なので、(5つの速度と4つの加速度) * 3座標 が得られます。これらをターゲットとした予測と損失関数を実装しました。損失関数は学習を安定させるためにSmoothL1Lossを使いました。
class CustomModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.backbone = timm.create_model(
cfg.model.backbone,
pretrained=cfg.model.pretrained,
in_chans=cfg.model.in_ch,
num_classes=0,
global_pool="avg",
)
feat_dim = self.backbone.num_features
self.tab_mlp = TabularMLP(cfg)
fusion_in_dim = feat_dim + self.tab_mlp.out_dim
self.head = nn.Linear(fusion_in_dim, cfg.model.out_dim)
self.aux_head = nn.Linear(fusion_in_dim, len(cfg.data.aux_target_cols)) # Auxiliary loss
def forward(self, x_img: torch.Tensor, x_tab: torch.Tensor) -> torch.Tensor:
feats = self.backbone(x_img) # (B, feat_dim)
t = self.tab_mlp(x_tab) # (B, tab_dim)
fused = torch.cat([feats, t], dim=1) # (B, feat_dim + tab_dim)
out = self.head(fused) # (B, out_dim)
aux_out = self.aux_head(fused) # Auxiliary loss
return out, aux_out
補助ロスを加えたモデルのスコアは以下の通りです。cv, publicのスコアともに改善されています。(privateスコアは悪化していました。)
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
| ProjectorのReLUをGELUに変更 | 0.24145 | 0.2395 | 0.2195 |
| 補助ロスを追加 | 0.24043 | 0.2368 | 0.2209 |
6. 周辺フレームを用いたLSTMの組み込み
個人的に実装するのを楽しみにしていたのがこちらの解法です。当時は単純な1シーンの画像回帰ではなく時系列を考慮するためにLSTMを組み込んだという解法を聞いて「なるほど」と思いつつも自分で実装する自信はありませんでした。
前提として、本コンペのデータでは、1行で1つの場面の情報を有していますが、IDが{シーンID}_{シーンのデシ秒数}で構成されているため、時間間隔の一貫性はありませんが、同じシーンの行が複数存在する場合があります。
ここまでは行ごとにモデルで予測を行なっていましたが、同じシーンIDを持つ周辺の場面をまとめてモデルに入力することで、より長期的な時間を考慮した推論が可能になると考えられます。

Turing × atmaCup #18 - 1st Place Solutionより引用
1st Solutionの資料をもとに実装を進めました。パイプラインの全体像としては以下のような形になります。まず入力が行ごとの3枚の画像ではなくシーンのまとまりとなるため、シーンごとに数は異なりますが、同じシーンの複数のフレームやテーブルをまとめて入力する形になります。この時、画像とテーブルは一度フラットな形状にテンソル操作してからモデルに入力しています。CNNとMLPをそれぞれ通した後にもとの形にreshapeすることで、シーンのまとまりをLSTMに入力することができます。データはバッチ内の最長のタイムステップ数に合わせてpaddingをしています。また、今回はコンペの性質上、オフライン予測であったため、同じシーンであれば未来の情報を使うことができます。したがってLSTMは両方向を有効にするBiLSTMとしました。

class CustomModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.backbone = timm.create_model(
cfg.model.backbone,
pretrained=cfg.model.pretrained,
in_chans=cfg.model.in_ch,
num_classes=0,
global_pool="avg",
)
feat_dim = self.backbone.num_features
self.tab_mlp = TabularMLP(cfg)
tab_feat_dim = self.tab_mlp.out_dim
fusion_in_dim = feat_dim + tab_feat_dim
# LSTMを追加
self.lstm = nn.LSTM(
input_size=fusion_in_dim,
hidden_size=cfg.model.lstm_hidden,
num_layers=cfg.model.lstm_num_layers,
batch_first=True, # (B,T,feat) <-> (B,T,hid)
bidirectional=cfg.model.lstm_bidirectional,
)
if cfg.model.lstm_bidirectional:
lstm_out_dim = cfg.model.lstm_hidden * 2
else:
lstm_out_dim = cfg.model.lstm_hidden
self.head = nn.Linear(lstm_out_dim, cfg.model.out_dim)
self.aux_head = nn.Linear(lstm_out_dim, len(cfg.data.aux_target_cols)) # Auxiliary loss
def forward(self, x_img: torch.Tensor, x_tab: torch.Tensor, lengths=None) -> torch.Tensor:
"""
x_img: (B, T, 9, H, W)
x_tab: (B, T, tab_dom)
out: (B, T, out_dim)
aux_out: (B, T, aux_dim)
"""
B, T, C, H, W = x_img.shape
#画像特徴量を抽出(形状を均して処理→形状を戻す)
x_img_flat = x_img.reshape(B * T, C, H, W)
img_feat_flat = self.backbone(x_img_flat)
img_feat_seq = img_feat_flat.reshape(B, T, -1)
# テーブル特徴量(同上)
x_tab_flat = x_tab.reshape(B * T, -1)
tab_feat_flat = self.tab_mlp(x_tab_flat)
tab_feat_seq = tab_feat_flat.reshape(B, T, -1)
# 結合してLSTMに入れる
fused_seq = torch.cat([img_feat_seq, tab_feat_seq], dim=-1) # (B,T,fusion_in_dim)
lstm_out, _ = self.lstm(fused_seq) # (B,T,lstm_hidden)
# ヘッドを各タイムステップに適用
out = self.head(lstm_out) # (B,T,out_dim=18)
aux_out = self.aux_head(lstm_out) # (B,T,aux_dim=27)
return out, aux_out
LSTMを組み込んだモデルのスコアは以下の通りです。cv, publicともに大きく改善されており、privateスコアも大きく改善されていることから、かなり強力に効いたことがわかりました。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
| ProjectorのReLUをGELUに変更 | 0.24145 | 0.2395 | 0.2195 |
| 補助ロスを追加 | 0.24043 | 0.2368 | 0.2209 |
| LSTMを追加 | 0.20137 | 0.2014 | 0.1857 |
7. データ拡張
データ拡張は画像を反転させたりノイズを加えることで、同じエポック数でもデータの多様性を増やすことで汎化性能を上げる手法です。もっと前段階で実装しておいてもよかったのですが、本コンペの1st Solutionではテーブル特徴量と一緒に画像を反転させる形でHorizontalFlipを使っており、こちらの実装が難しそうであったため、データ拡張自体を後回しにしていました。
ノイズ系のデータ拡張
まずは画像のデータ拡張ライブラリであるAlbumenatationsを用いて以下のようにGaussNoiseやGaussianBlurを追加しました。これらはランダムなノイズを加えたり、ぼかしを加えたりする処理です。今回のタスクでは車両のカメラにノイズが入ったり車両の動きが早くて一部ブレのようなものが発生する可能性が考えられるため、これらのデータ拡張の処理は現実に即した処理であると考えられました。
# train
if cfg.runtime.train_mode:
return A.Compose([
A.Resize(size, size),
A.OneOf([
A.GaussNoise(),
A.GaussianBlur(),
A.MotionBlur(),
], p=0.4),
A.Normalize(mean=mean3, std=std3),
ToTensorV2(),
])
# valid, test
return A.Compose([
A.Resize(size, size),
A.Normalize(mean=mean3, std=std3),
ToTensorV2(),
])
ノイズ系のデータ拡張を入れた結果が以下の通りです。cvは改善されましたが、public, privateのスコアはやや悪化してしまいました。コンペ中であればcvを信用してデータ拡張はこのまま適用していただろうと思います。このデータ拡張については適用確率を変更したりといった検証までは行なっておらず、これを適用したままの形で、HorizontalFlipの実装に進みました。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
| ProjectorのReLUをGELUに変更 | 0.24145 | 0.2395 | 0.2195 |
| 補助ロスを追加 | 0.24043 | 0.2368 | 0.2209 |
| LSTMを追加 | 0.20137 | 0.2014 | 0.1857 |
| データ拡張(ノイズ系)を追加 | 0.20130 | 0.2031 | 0.1875 |
HoriontalFlip
こちらは1st Solutionにて効いたと報告されていた手法です。車両から見える画像は左右を反転させても違和感がないため、データ拡張することが有効だと考えられます。一方で今回は画像だけではなくテーブル特徴量が与えられているため、左右を反転させるとtargetの座標はもちろん、steeringAngleDeg(ハンドル角度), steeringTorque(ハンドルのトルク), Blinker(ウィンカー)の向きも反転させなければなりません。この実装がやや複雑であり難しいと感じました。
実装はatmaCup#18のディスカッションにある1st Solutionの解法紹介を参考にさせていただき、Datasetクラスの__getitem__に以下のように記載することで実装しました。
if self.is_train and random.random() < 0.5:
# 画像を左右反転
imgs_seq = torch.flip(imgs_seq, dims=[-1])
# tab: 符号反転(steeringAngleDeg=2, steeringTorque=3)
if tabs_seq.size(1) > 2:
tabs_seq[:, 2] = -tabs_seq[:, 2]
if tabs_seq.size(1) > 3:
tabs_seq[:, 3] = -tabs_seq[:, 3]
# tab: 左右入替(leftBlinker=12 ↔ rightBlinker=13)
if tabs_seq.size(1) > 13:
left = tabs_seq[:, 12].clone()
right = tabs_seq[:, 13].clone()
tabs_seq[:, 12] = right
tabs_seq[:, 13] = left
# targets: y-axis 系
for i in [1, 4, 7, 10, 13, 16]:
if i < y_seq.size(1):
y_seq[:, i] = -y_seq[:, i]
for i in [1, 4, 7, 10, 13]:
if i < y_aux_seq.size(1):
y_aux_seq[:, i] = -y_aux_seq[:, i]
ここでtargetのy座標だけを反転させているのは、設定が以下のようにy座標が正面を向いた時に左右に当たる軸であったためです。

atmaCup#18 開会式 より引用
HorizontalFlipを適用したモデルのスコアは以下の通りです。cv, public, privateともにこれまでで最高スコアとなったことから、かなり強力に効いたことがわかりました。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
| ProjectorのReLUをGELUに変更 | 0.24145 | 0.2395 | 0.2195 |
| 補助ロスを追加 | 0.24043 | 0.2368 | 0.2209 |
| LSTMを追加 | 0.20137 | 0.2014 | 0.1857 |
| データ拡張(ノイズ系)を追加 | 0.20130 | 0.2031 | 0.1875 |
| データ拡張(HorizontalFlip)を追加 | 0.20010 | 0.2012 | 0.1852 |
8. VLM特徴量の組み込み
最後はVLMの活用についてです。こちらは上位解法にあったものではありません。 当時VLMを使って何かできないかと考えていたため、今回改めて試してみたことになります。
当時は誤差分析をしている際に、駐車場や急カーブなど真っ直ぐでシンプルな道路以外の場面で精度が低いことがわかりました。そこで、VLMを用いて画像を入力して「この場面は駐車場ですか?」といった推論をさせ、それをone-hotベクトルとしたカテゴリ変数にしてテーブル特徴量に追加してモデルを作っていました。しかし、これによって精度は変化せず、特に意味のない結果となってしまいました。
今回はその振り返りも踏まえて、別の形でVLMを組み込むことを試みました。そもそも他の画像系モデルではなくVLMを使う理由としては、精度向上目的ではなくVLMを触ってみたいという好奇心があったためです。 とはいえせっかくやるなら精度向上させられたら嬉しいということで今回も実装を試みました。
モデル全体への組み込み方は以下のように考えて実装しました。前回と大きく変えた点としては、VLMで何か出力をしてその出力値を使うのではなく、画像とテーブル情報をもとにしたテキストプロンプトをモデルに通して、その最終トークンの隠れ状態を取り出して小さなProjectorで次元圧縮した特徴ベクトルを返すようにした点です。テーブル特徴量の扱いと同じように、比較的小さな次元にしてConvNextから得られた特徴と結合するようにしています。VLMはQwen2-VL-2B-Instructを用いました。Qwen-VLシリーズは現在Qwen3-VLまで出ていますが、本コンペ開催当時に出ていた最新モデルはQwen2-VLであったため、こちらを使うことにしました。また、初めは7Bを使っていましたが私の環境ではメモリ超過によるエラーが発生してしまったため、2Bを用いることとしました。
VLMを活用する狙いとしては、Qwen2-VLのVision EncoderはViTがベースとなっているため、CNNベースのConvNextとは異なった特徴抽出ができるのではないかと考えた点と、それに加えてテーブル情報を使ったテキストプロンプトをイメージプロンプトと一緒に処理することができるため、より深い状況理解につながるのではないかと考えました。
全体像

VLM周辺の詳細は以下の通りです。Qwen2-VLは複数の画像を入力として受け取ることができるため、今回のように3つの画像を持っている場合でも、マルチフレームとして同時に入力することができます。また、テキストプロンプトはテーブル特徴量を用いて現在の状況がどのようなものかを理解させるようなテキストとしました。
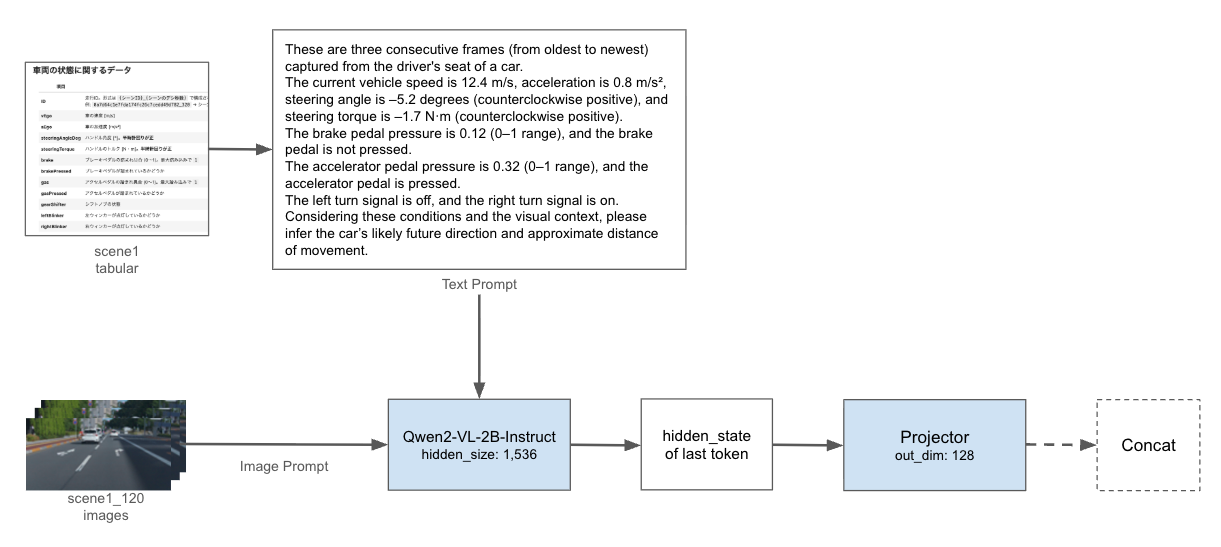
ここで、VLMに車両がどこへどのくらい動くかを推論させて、出力テキストをtext embeddingで埋め込みした特徴ベクトルを使うといった方法も考えましたが、約45,000件のデータに推論が必要であるため、推論コストの問題から不採用としました。代わりに何か特徴を取得する方法を考えたのが「画像とテーブル情報をもとにしたテキストプロンプトをモデルに通して、その最終トークンの隠れ状態を取り出す」という方法です。最終トークンではそれまでのトークン(画像とテキストを含む)の全てをattentionによって参照しているため全体的な情報量を保持しているのではないかと仮定して、最終トークンの隠れ状態を用いることとしました。
ただし、このままでは1,536次元とサイズが大きく、このまま結合するとここまでのモデルを大きく崩す可能性や過学習を引き起こす可能性があるため、Linear, ReLU, DropOutで構成された、出力次元が128のProjectorで圧縮してから結合する形にしました。
VLMを組み込んで学習した結果は以下の通りとなりました。cvはやや大きく悪化したものの、public, privateのスコアは改善されました。
| exp | cv(↓) | public(↓) | private(↓) |
|---|---|---|---|
| 小さいCNNモデル | 1.73037 | 1.7068 | 1.5927 |
| resnet34d | 0.67033 | 0.7031 | 0.6147 |
| convnext_large | 0.56598 | 0.6079 | 0.5177 |
| テーブル特徴量を組み込み | 0.24216 | 0.2433 | 0.2196 |
| ProjectorのReLUをGELUに変更 | 0.24145 | 0.2395 | 0.2195 |
| 補助ロスを追加 | 0.24043 | 0.2368 | 0.2209 |
| LSTMを追加 | 0.20137 | 0.2014 | 0.1857 |
| データ拡張(ノイズ系)を追加 | 0.20130 | 0.2031 | 0.1875 |
| データ拡張(HorizontalFlip)を追加 | 0.20010 | 0.2012 | 0.1852 |
| VLMを組み込み | 0.20194 | 0.2005 | 0.1847 |
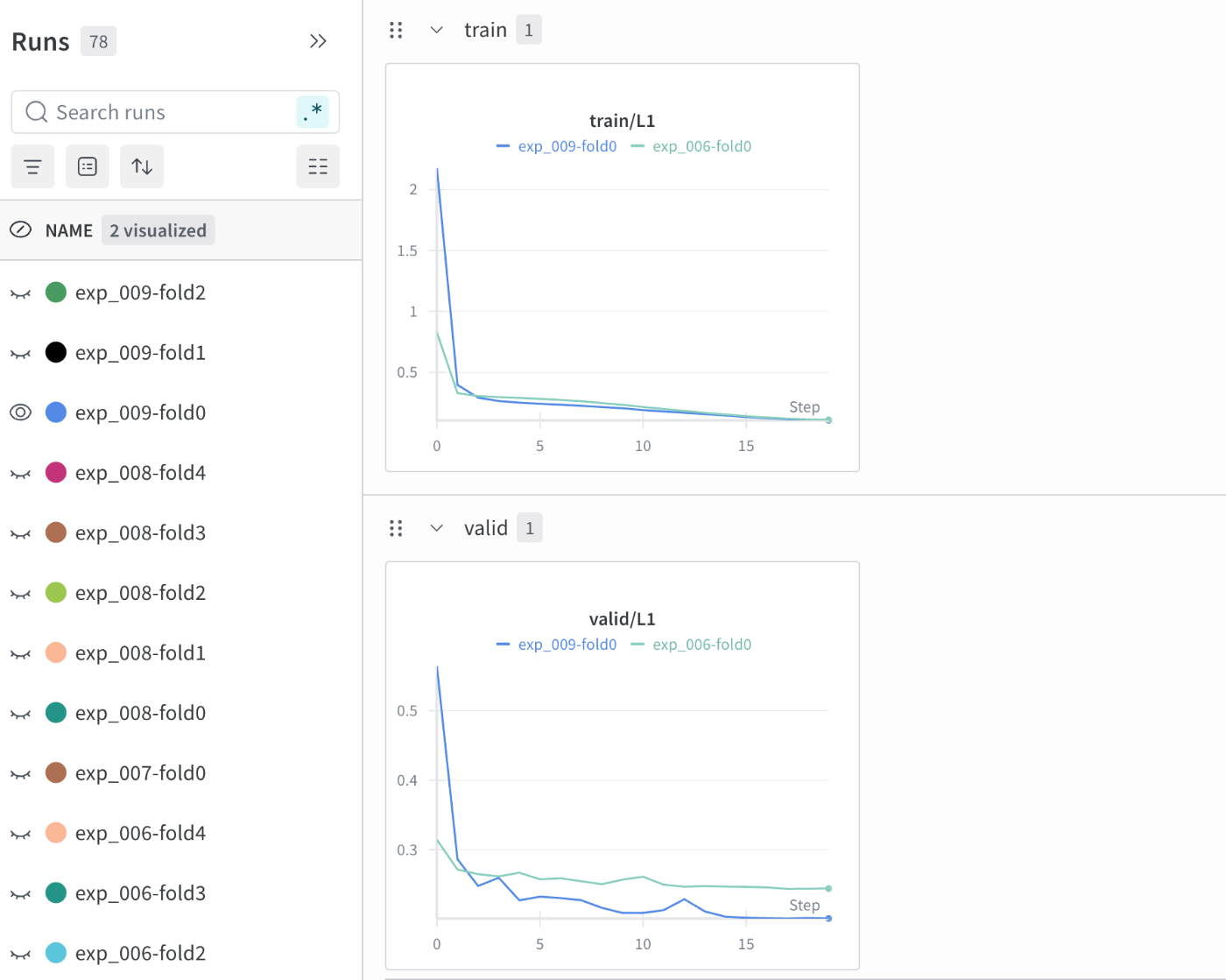
大きな差はないためVLM組み込みの効果があったかどうかは定かではありませんが、この結果に対する考察をtrain lossとvalid lossの結果から少しだけ考えてみました。
HorizontalFlipまでのモデルをAとして、そこにVLMを組み込んだモデルをBとすると、上記の通り最終的なcv scoreはモデルAが上回っていました。train loss, valid lossもfold平均でモデルAのほうが下がっていることが確認されました。しかし、最終的な各foldのベストモデル (valid lossが最も低いepoch時点のモデル)において、train lossとvalid lossの差分を計算してfold平均してみると、モデルBの方が差分が小さいことがわかりました(モデルA:0.061172, モデルB: 0.059432)。
この差は僅かであるため断定するのは難しいと考えていますが、モデルBの方がtrain dataへの依存が少ないという可能性を示唆しているのではないかと考えました。 その結果として、全foldを使って完全に未知であるtest(submission)データに対して予測をした際にモデルAよりも汎化性能が僅かに上回り、private scoreが改善されたのではないかと考えました。モデルを学習する前はVLM特徴を処理するProjectorを追加したことによりtrainへの過学習を引き起こすのではないかと考えていましたが、モデルAと比較してtrain lossが下がらなかったことが意外でした。
また、改善幅が大きかったシーン画像と悪化幅が大きかったシーン画像から定性的な解釈を試みましたが、有力な解釈を得ることはできませんでした。以下に参考として掲載します。なお、駐車場など予測が困難な場面は改善・悪化がしやすいため除いており、比較的予測がしやすそうだが変化が大きかったものを抜粋しています。
何かしら解釈を加えるとするならば、改善幅が大きいシーンとしては駐車場や障害物があるようなイレギュラーな場面よりも、前方に車両がなく道路の先の見通しがクリアな場合に前後左右の当てはまりがよくなったように感じます。(単純に移動が大きい=予測の座標スケールが大きいため誤差の絶対値が大きくなるというだけかもしれませんが。)一方で、悪化幅が大きいシーンとしてはすぐ正面に車両があったりガードレールがある場面が多いように感じました。
改善幅が大きいシーン画像(一部) ※exp013がVLMを組み込んだモデルの予測です

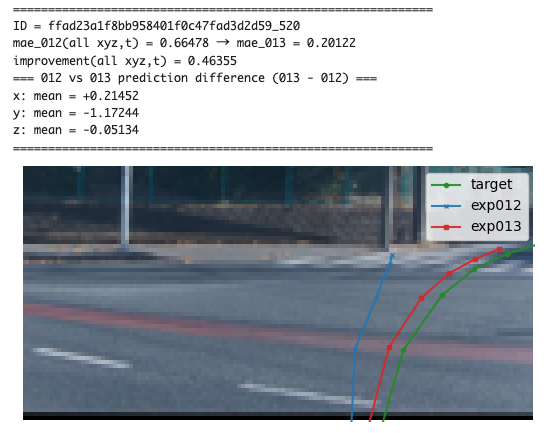

悪化幅が大きいシーン画像(一部) ※exp013がVLMを組み込んだモデルの予測です



なお、VLMを組み込んだモデルは推論時間が非常に長くなってしまった上に大きな改善は見られなかったため、今回のケースにおいては潤沢な計算リソースを持っていない場合にはあまりおすすめできません。1foldのみ実験してダメならすぐに切り上げるといった潔さも必要だと思いました。
最終結果
今回の取り組み(1-Stage onlyのモデル改善)の最終privateスコアは0.1847でした。このスコアは当時のリーダーボードにおける11位にあたります。当時の自チーム(CNN→GBDTの2-stageパイプライン)のスコアは0.1864で順位は17位であったため、GBDTを使わない1-stageのみで当時の自分たちを超えることができました。 一方で入賞レベルの上位陣とは、2-stageであることを考慮しても大きな差があるため、まだまだ修行が必要だなと感じました。

late submissionの最終スコア

late submissionの推移(抜粋)
やったけど上手くいかなかったこと・できていないこと
まず、やったけど精度向上に寄与しなかったことで言うと、targetごとの正規化です。こちらは上位解法で精度向上したと報告されていたため実装してみましたが、cvが悪化してしまったため上には記載しませんでした。解法で述べられているように、予測時点でtargetのスケールが異なるためスケールを合わせることで学習がよくなるという期待はあったのですが、細かい実装までは解法に書かれていなかったため、私の実装が適切ではなかったために改善しなかった可能性はあると考えています。
できていないこととしては、深度画像や信号機情報の組み込みです。こちらも上位解法で取り組まれていたことになります。目の前に物体があるのか遠くに物体があるのかといった深度理解や信号機の色がどういう状態なのかといった情報は学習に寄与すると期待されますが、こちらは時間の都合上、実装まで進めることができませんでした。(アドベントカレンダーに間に合わず断念。)
終わりに
今回は画像モデリング初学者の試みとして、atmaCup#18の復習に取り組みました。上位解法を聞いて「なるほど」「次から真似しよう」などと思うことは多かったですが、それを実装できるかどうかは別の話で、いざ自分で手を動かしてみるとうまく実装できないことが多々ありました。したがって、今回は新たな解法アイデアはほとんど出せていませんが、アイデアを形にする部分の技術は少なからず向上させることができたかと思います。改めてコンペを開催してくださったatma株式会社様とTuring株式会社様、そして公開ノートブックや解法を公開してくださった参加者の皆様に御礼申し上げます。また、第2回の開催も企画されているとお聞きしましたので、今回の復習を活かして高スコアを目指せるように頑張りたいと思います。
最後になりますが、弊社ではこのようなコンペの取り組みにおいて、社員が利用したい計算リソースを会社からサポートする仕組みを設けています。弊社にご興味のある方は以下のサイト等からお問い合わせください。

Discussion