はじめに
データアナリティクスラボ株式会社です。
先日、データソリューション事業部のメンバーで「atmaCup #18」に参加しました!
本記事ではその結果と取り組みについてご紹介させていただきます。前置きとして、今回は初めて画像認識モデルに挑戦したため、不慣れな部分も多く、試行錯誤を重ねながら取り組みました。もし見当違いな点があった場合でも、温かい目で見守っていただけると幸いです。
参加メンバー
力岡:入社2年半。金融分野の分析や生成AI関連の開発に取り組んでおり、社内では生成AIの研究活動を実施。
宮澤:入社3年。マーケティング分野の分析・モデル構築に従事しており、社内では生成AIの研究活動を実施。
本多:入社1年半。マーケティング分野の分析などに取り組んでおり、社内では最近生成AIに関する学習をスタート。
コンペ概要
atmaCupとは、atma株式会社が主催するオンサイト型データコンペティションです。本来はオフラインで実際に集まりながらコンペを行うのが特徴ですが、現在は新型コロナウイルス感染防止の観点からオンライン開催が主流となっています。
コンペ期間中には初心者向けの講座が実施され、ディスカッションも活発に行われています。やり取りは基本的に日本語で進むため、「Kaggleはちょっとハードルが高い…」と感じている方にもおすすめのコンペです。
今回のテーマ
#18 のテーマは、自動運転開発で有名なチューリング株式会社との共同開催で、「車の将来の軌道を予測せよ」というものでした。実際の走行シーンのカメラ画像、信号機情報、車両の状態データを用いて、将来の自車の位置が分からない走行シーンにおける自車の将来位置を予測し、その精度を競うという課題です。
イメージとしては、緑色の正解軌道をモデルでうまく予測したいという状況です。(青色と赤色は、モデルが予測した結果の例として示しています)
提供されたデータは以下の通りで、画像データやテーブルデータなど、さまざまな種類のデータが含まれていました。
train_features.csv: 車両の状態に関するデータ
-
ID: 走行ID。IDは{シーンID}_{シーンのデシ秒数}で構成される。 -
vEgo: 車の速度。単位は [m/s]。 -
aEgo: 車の加速度。単位は [m/s^2]。 -
steeringAngleDeg: ハンドル角度. 単位は度数で半時計回りが正。 -
steeringTorque: ハンドルのトルク。単位は N・mで半時計回りが正。 -
brake: ブレーキペダルのふまれ具合。0~1の間の値で一番奥までふまれている場合が1。 -
brakePressed: ブレーキペダルがふまれているかどうか。 -
gas: アクセルペダルのふまれ具合。0~1 の間の値で一番奥までふまれている場合が1。 -
gasPressed: アクセルペダルがふまれているかどうか。 -
gearShifter: シフトノブの状態。 -
leftBlinker: 左のウィンカーがついているかどうか。 -
rightBlinker: 右のウィンカーが付いているかどうか。
予測対象の点列 (trainデータにのみ付与)
-
x_0 ~ z_6までの 6x3 列が予測対象。 - t + 0.45 秒 , t + 0.95 秒 , t + 1.45 秒 , t + 1.95 秒 , t + 2.45 秒 , t + 2.95 秒 における自車の位置を時刻 t における自車中心座標系で表現した(x, y, z)の座標を表している。
images: カメラの画像
走行時に撮影された画像。時刻 t を基準として t - 1 秒 , t - 0.5 秒 , t 秒 の 3 つの時刻で撮影された画像が含まれる。単眼カメラの RGB 画像で幅 128pixel, 高さ 64 pixel。
traffic_lights: 信号機の情報
あるシーンの画像から検出された信号機の情報。
-
index: 検出結果の番号 -
class: 検出された信号機の種類-
green: 青色信号 -
yellow: 黄色信号 -
red: 赤色信号 -
straight: 矢印信号機の直進 -
left: 矢印信号機の左折 -
right: 矢印信号機の右折 -
empty: 点滅が観測できない信号機 -
other: それ以外の信号機
-
-
bbox: 検出された領域の bounding box 座標。
評価指標
平均絶対誤差(MAE)
補足
Turing株式会社のTech Blogには、今回のコンペのお題に関連する課題感が記載されています。こちらをご確認いただくと、さらに理解が深まると思います。
結果
さっそく結果ですが、最終的に176人の参加者中、Public LBでは7位、Private LBでは17位という結果となりました!
冒頭でも触れたように、画像認識モデルを扱うのは今回が初めてでしたが、この結果はかなり善戦できたのではないかと思っています。


解法
ここからは私たちの取り組み(解法)について説明させていただきます。
モデル全体像
以下は、最終的に構築したモデルの全体像です。

やや複雑な構成となっていますが、基本的には CNN&GBDT(2 Stage Model) / CNN(マルチモーダル) / MLP(車両モデル) の3種類のモデルで構成されており、これらのモデルの予測結果を最終的にStackingすることで、最終的な予測を計算しました。
それぞれのモデルについて、以下で詳しく説明していきます。
CNN&GBDT(2 Stage Model)
CNN(畳み込みニューラルネットワーク)を用いて画像特徴量を抽出し、次にGBDT(勾配ブースティング決定木)を用いて最終的な予測を行うアプローチです。
まずは、ResNetを用いて t - 1 ~ t の画像を縦方向に結合したデータを入力とし、画像のみでモデルを学習してxyz座標を予測しました。その後、このCNNで得られた予測結果を特徴量としてGBDTに入力し、車両データなどの他の特徴量と組み合わせて再度xyz座標の予測を行いました。
工夫点としては、実世界の座標で学習させたCNNだけではなく、実世界の座標を画像座標に変換して学習させたCNNも併用した点です。それぞれのCNNの予測結果をもとに、LightGBMとXGBoostを用いて学習を行い、計4つのモデルををアンサンブルすることで、Public Scoreが0.003ほど向上しました。特に画像座標を利用したモデルは、画像範囲から進む軌跡が大幅にはみ出すデータを除外して学習を行ったため、画像範囲内に収まる軌跡を予測するのに特化したモデルになったのではないかと考えています。
CNN(マルチモーダル)
CNNで画像データのみを学習するのではなく、車両の状態データをMLP(多層パーセプトロン)に入力し、画像エンコーダから抽出した特徴ベクトルと結合するLayerを設計し、最終的にこの結合された特徴を用いて予測を行うアプローチです。
以下のイメージ図のように、大きな工夫はあまり加えず(知識不足のためできず)、ResNetとDenseNetの2種類のモデルを用いて学習を行いました。

MLP(車両モデル)
テーブルデータとして与えられる速度、加速度、ハンドル角、シフトレバーの情報を基に、物理的な理論を利用して将来の位置を予測しようと試みたアプローチです。GBDT系のモデルは特徴量間の計算が苦手なため、あらかじめ計算した結果を特徴量として取り込むことで精度向上を狙いました。
結論としては、計算式をうまく作ることができずに挫折してしまい、最終的にはMLPにすべて任せるという投げやりな形をとりました。結果として、スコアが多少向上したため、ある程度予測可能なモデルになったのではないかと思っています。(本来はこのようなことをするのは良くないのでしょうが、時間も限られていたため雑に入れ込んでしまいました)
アンサンブル
最終的に構築した7種類のモデルの予測結果をLightGBMに入力し、アンサンブル学習を行うことで提出用の予測結果を作成しました。
特徴量エンジニアリング
同一シーンにおけるラグ特徴量
IDは以下の形式で構成されています。
ID:{シーンID}_{シーンのデシ秒数}
このIDからシーンIDとシーンの時間を切り出しました。同一シーンの情報には予測に重要な手がかりが含まれていると考えたためです。また、予測する過去と未来における車の状態が予測精度向上の大きなヒントになると考えました。
これらの考えに基づき、以下の特徴量を作成しました。
- 1ステップ前後の特徴量
- 1ステップ前後の特徴量同士の差分
- 同一シーン内での特徴量の平均、標準偏差、最大値、最小値
これらの特徴量はディスカッションでも頻繁に言及されており、多くの参加者の解法に標準的に含まれていたと考えられます。
VLM (Vision Language Model) による特徴抽出
初めに作ったCNN&GBDTは公開ノートブックを参考にさせていただきましたが、そのモデルにおいて誤差が大きいデータを分析したところ、駐車場やT字路など一般的な真っ直ぐした道路ではないイレギュラーなケースが多いことがわかりました。そこで画像データからもう少し特徴量を得られないかと考え、VLMを用いてシーンに対するラベル付け試みました。
ラベル付けをした項目は以下の通りです。
これらの項目を選択した基準としては、「誤差分析で多かった場面」かつ「VLMである程度の判定ができるもの」になります。例えば交差点の右左折の軌跡を大きく間違えているケースも多くありましたが、予備実験においてVLMでは右や左の概念を理解することができず、正確にラベル付けできませんでした。
-
parking:駐車場であるかどうか -
stop:正面が壁やガードレールなどの行き止まりであるかどうか -
intersection:交差点であるかどうか -
curve:急カーブの道であるかどうか -
congection:目の前に車が連なった渋滞であるかどうか
結果としては Private: 0.1975 から変化がなかったので特徴量追加による効果はなかったことになりますが、参考までに実装コードを掲載しておきます。
VLMをvllmで動かす実装コード
モデル:Qwen/Qwen2-VL-7B-Instruct 環境:Google Colab NVIDIA L4)
Qwen2-VLの他にもPhi-3.5-vision-instructやInternVL2も試しましたがそれぞれ入力の与え方が異なっており、適切に与えないとエラーになるので注意が必要です。
# ライブラリのインストール
!pip install vllm triton qwen-vl-utils
# ライブラリのインポート
import vllm
import torch
from transformers import AutoProcessor
import PIL
from IPython.display import display, HTML, Image as IPImage
import polars as pl
import os
from tqdm import tqdm
from qwen_vl_utils import process_vision_info
# config(自身の環境に合わせてください)
model_path = "Qwen/Qwen2-VL-7B-Instruct"
base_directory = "comp_dataset/atmaCup#18_dataset/images/"
output_file = "output/vlm_labeling/vlm_output_train_qwen2.csv"
# vllmでモデル読み込み
llm = vllm.LLM(
model=model_path,
limit_mm_per_prompt={'image': 1},
trust_remote_code=True,
max_model_len=256,
)
# サンプリングの設定
sampling_params = vllm.SamplingParams(
temperature=0,
max_tokens=1,
logprobs=10
)
# データ処理クラスの読み込み
processor = AutoProcessor.from_pretrained(model_path)
# プロンプトの設定
prompt_parking = "This image was taken from the perspective of a car driver and shows a scene captured by a dashboard camera. Determine if the location in the image is a parking lot. Answer 1 if the image shows features that indicate it is a parking lot, such as marked parking spaces, stationary parked vehicles, or entrance/exit signs. Answer 0 if there are no indications of a parking lot in the image, such as a regular street or highway."
prompt_stop = "This image was taken from the perspective of a car driver and shows the view ahead. Determine if the image depicts a dead end. Answer 1 if there are clear signs of a dead end, such as a wall, barrier, guardrail, fence, or dense vegetation completely blocking the road. Also answer 1 if forward movement is clearly impossible due to a vehicle directly in front of the car blocking the entire driving lane or positioned so close that driving forward is not feasible. Other situations indicating a dead end include a pedestrian crossing the road ahead or a stop line marked with 'STOP' or similar signage at the end of the road. Answer 0 if the road appears to continue or if there is no clear obstruction blocking the way forward, even if other vehicles are visible but do not block the driving lane."
prompt_intersection = "This image was taken from the perspective of a car driver and shows the view ahead. Determine if there is an intersection or junction directly in front of the vehicle. Answer 1 if the image shows visible cross streets, a branching road, or a clear convergence of multiple roads, even in the absence of traffic signals or road signs. Answer 0 if no intersection or junction is visible immediately ahead."
prompt_curve = "This image was taken from the perspective of a car driver and shows the view ahead. Determine if the image depicts a significant lateral change in the road, such as an intersection (crossroad or T-junction) or a sharp turn that requires the road to bend prominently to the left or right. Answer 1 if there are clear signs of a crossroad, T-junction, or a sharp turn. Answer 0 if the road appears to continue straight only, with no lateral change or other roads branching off."
prompt_congection = "This image was taken from the perspective of a car driver and shows the view ahead. Determine if the image depicts a situation where multiple vehicles are stopped directly in front of the car, indicating traffic congestion. Answer 1 if there are clear signs of traffic congestion, such as multiple vehicles closely packed together in the same lane or across multiple lanes, preventing smooth forward movement. Answer 0 if the road appears to have free-flowing traffic, even if other vehicles are visible but spaced apart and not obstructing movement."
# 画像とプロンプトを加工する関数
def process_image_prompt(processor, image_path, prompt):
image_path_file = os.path.join(image_path, "image_t.png")
try:
messages = [
{'role': 'system', 'content': "You are an AI designed to analyze images captured from a driver's perspective. Carefully evaluate the scene to identify road conditions, traffic features, and other relevant details based solely on visible elements. Provide clear and accurate labels for each task."},
{'role': 'user', 'content': [
{
'type': 'text',
'text': prompt,
},
{
'type': 'image',
'image': image_path_file,
},
]},
]
prompt_templated = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
)
image_inputs, video_inputs = process_vision_info(messages)
mm_data = {}
if image_inputs is not None:
mm_data['image'] = image_inputs
if video_inputs is not None:
mm_data['video'] = video_inputs
return mm_data, prompt_templated
except Exception as e:
print(f"Error loading images: {e}")
return None
# テキスト生成する関数
def vllm_generate(mm_data, prompt_templated):
try:
outputs = llm.generate(
{
"prompt": prompt_templated,
'multi_modal_data': mm_data,
},
sampling_params=sampling_params,
use_tqdm=False
)
for o in outputs:
generated_text = o.outputs[0].text
return generated_text
except Exception as e:
print(f"Error generating text: {e}")
return None
# 5つのプロンプトを実行する関数
def process_ids(df, base_dir, prompt_1, prompt_2, prompt_3, prompt_4, prompt_5, output_path, save_interval=2500):
# 各カラムに対応するリストを準備
parking_labels = []
deadend_labels = []
intersection_labels = []
curve_labels = []
congection_labels = []
# tqdmを利用して進捗バーを追加
for i, row in enumerate(tqdm(df.iter_rows(named=True), total=df.shape[0], desc="Processing IDs")):
id_value = row["ID"]
folder_path = os.path.join(base_dir, id_value)
try:
mm_data_1, prompt_templated_1 = process_image_prompt(processor, folder_path, prompt_1)
mm_data_2, prompt_templated_2 = process_image_prompt(processor, folder_path, prompt_2)
mm_data_3, prompt_templated_3 = process_image_prompt(processor, folder_path, prompt_3)
mm_data_4, prompt_templated_4 = process_image_prompt(processor, folder_path, prompt_4)
mm_data_5, prompt_templated_5 = process_image_prompt(processor, folder_path, prompt_5)
if mm_data_1 is None:
parking_labels.append(None)
if mm_data_2 is None:
deadend_labels.append(None)
if mm_data_3 is None:
intersection_labels.append(None)
continue
if mm_data_4 is None:
curve_labels.append(None)
if mm_data_5 is None:
congection_labels.append(None)
# テキストを生成
generated_text_1 = vllm_generate(mm_data_1, prompt_templated_1)
generated_text_2 = vllm_generate(mm_data_2, prompt_templated_2)
generated_text_3 = vllm_generate(mm_data_3, prompt_templated_3)
generated_text_4 = vllm_generate(mm_data_4, prompt_templated_4)
generated_text_5 = vllm_generate(mm_data_5, prompt_templated_5)
# 結果をリストに追加
parking_labels.append(int(generated_text_1))
deadend_labels.append(int(generated_text_2))
intersection_labels.append(int(generated_text_3))
curve_labels.append(int(generated_text_4))
congection_labels.append(int(generated_text_5))
except Exception as e:
print(f"Error processing ID {id_value}: {e}")
# エラーが発生した場合はNoneを追加
parking_labels.append(None)
deadend_labels.append(None)
intersection_labels.append(None)
curve_labels.append(None)
congection_labels.append(None)
# n件ごとに保存
if (i + 1) % save_interval == 0:
# 現時点までのデータを保存
partial_df = df.head(i + 1).with_columns(
pl.Series("Parking_label", parking_labels),
pl.Series("Deadend_label", deadend_labels),
pl.Series("Intersection_label", intersection_labels),
pl.Series("Curve_label", curve_labels),
pl.Series("Congestion_label", congection_labels),
)
partial_df.write_csv(output_path)
print(f"Saved {i + 1} records to {output_path}")
# 最後のデータを保存
final_df = df.with_columns(
pl.Series("Parking_label", parking_labels),
pl.Series("Deadend_label", deadend_labels),
pl.Series("Intersection_label", intersection_labels),
pl.Series("Curve_label", curve_labels),
pl.Series("Congestion_label", congection_labels),
)
final_df.write_csv(output_path)
print(f"Final save completed: {len(parking_labels)} records saved to {output_path}")
return final_df
# 実行
df_result = process_ids(df_train_1, base_directory, prompt_parking, prompt_stop, prompt_intersection, prompt_curve, prompt_congection, output_file, save_interval=2500)
データ分析など
画像エンコーダのバックボーンの検証
さまざまな画像エンコーダを試すために、ResNet、ConvNext、DenseNetなどを使用して学習を行い、その結果を比較しました。DenseNetやConvNextといった複雑なモデルを用いると1st Stageのスコアは向上したものの、2nd Stageのスコアにはあまり寄与しませんでした。
一方で、ResNetはモデルサイズを大きくするほど精度が向上する傾向が見られたため、最終的には大きなResNetモデルを採用する方針に決定しました。

予測が外れているデータの分析
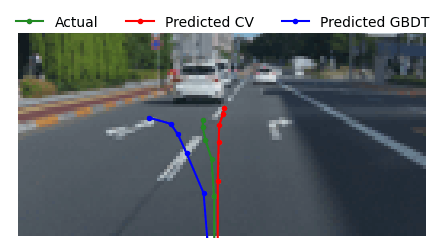
実際の軌跡と予測された軌跡のMAEを計算し、MAEが大きいデータを順に画像で確認しました。その結果、以下のようなパターンにおいて予測がうまくいかないことが判明しました。(以下の図では、CNN&GBDTモデルにおける「Predicted CV」がCNN、「Predicted GBDT」がGBDTの予測線を示しています。)
① 右折/左折をするパターン
ウィンカーを右または左に出している場合、曲がりをうまく予測できていませんでした。これは、画像モデルでウィンカー情報が特徴量として含まれていないため、道路沿いに直進するという傾向に引っ張られた結果だと考えられます。

② 駐車場での動き
駐車場では、停止やバックといった予測困難な動きが多く見られました。以下の画像では、軌跡が画像上に描画されていませんが、実際には右後ろにややバックしている状況でした。このような動きを予測するのは非常に難しいといえます。

③ 進む距離の誤差
軌跡の向きは正しいものの、直進する距離を誤っているケースも多く見られました。初期状態の速度や画像しか与えられていないため、後半になるほど位置が乖離し、結果としてMAEが大きくなってしまいました。

その他にも、特定のシーンに対応するデータの件数が少ない場合など、予測が安定しないことがわかりました。これらの課題については、私達の取り組みでは十分に対応できませんでしたが、以下に紹介する上位解法では、これらの課題に対して効果的なアプローチが用いられていました。
上位解法について
上位陣の多くは、共通してCNN&GBDTの2 Stage Modelを採用していました。しかし、CNN部分に高度な工夫が施されており、その結果として高精度な予測を実現していました。以下に、特に参考になったポイントをいくつかピックアップしてまとめます。
-
補助損失(Auxiliary Loss)の活用
- 目的変数である座標情報に加え、速度や加速度などの派生ターゲットを座標情報から逆算し、それらを補助損失として導入することで、モデルの時系列理解を深めた。
-
時系列情報の組み込み
- シーンごとのデータを時系列データとして扱い、CNNで処理した後、時系列に並べ替えてLSTMを使用して解析を行う手法を採用した。
-
画像データの工夫
- Depth Map, Optical Flow, Mask2Formerといった手法で抽出した補助的な画像情報を取り入れることで、より詳細な特徴量を抽出。
- 画像解像度を向上させるために、CompVis/ldm-super-resolution-4x-openimagesを活用し、(64, 128)から(256, 512)に高解像度化。
-
データ拡張
- 水平反転(Horizontal Flip)が非常に効果的であり、ターゲットや特徴量も同時に反転する処理を実施。
- CoarseDropoutなどの手法を用い、画像の一部をランダムにマスクすることで、モデルのロバスト性を向上
-
アンサンブル戦略
- モデルの多様性を高めるため、ResNet、Swin Transformer、EfficientNetなど複数のCNNアーキテクチャを活用し、予測値を統合。
- 各Foldやモデルごとの出力を加重平均することで、多様性を高め、最終的な予測精度を向上。
参考として、上位5名の解法へのリンクを以下にまとめます。
- 1st place solution [cv:0.1792, public:0.1885, private:0.1754]
- 2nd place solution [cv 0.1826, public 0.1890, private 0.1791]
- 3rd Place Solution (CV: 0.1844, LB: 0.1904, Private: 0.1795)
- 4th Solution (CV: 0.1865 Public:0.1977 Private: 0.1806)
- 5th Solution (takaito part) (CV: 0.1890, LB: 0.1976, Private: 0.1840)
- 5th Solution (suk1yak1 part) (cv: 0.1933, public: 0.1967, private: 0.1853)
反省点
反省点は大きく分けて、以下の2つとなります。
1点目は、CNNの工夫不足です。そもそも「CNNをどうやって実装するのか」という状態からスタートしたため、なんとか実装することはできても、「これで本当に正しいのか?」という不安を最後まで拭いきれませんでした。また、どのように工夫を加えればよいのかの方向性も見出せず、CNNの改善を途中で放棄してしまいました。経験不足ばかりはどうすることもできないので、今回の上位解法はしっかりと勉強し、次の糧にしていきたいと思います。
2点目は、Public LBへの固執です。コンペ慣れしていないことも一因ですが、Public LBを上げることばかりに注力し、最終的に良いモデルを作り上げる視点が不足していました。結果として、今回も前回のatmaCupと同様にPrivate LBで大きくShake downしてしまいました。本質的なモデル構築や評価にもっと目を向けられるように、精度だけでなく汎化性能を意識して取り組む必要があると感じました。
おわりに
1週間という短い期間のコンペでしたが、有益なディスカッションが多数行われ、新しい技術を学ぶ貴重なきっかけとなりました。正直なところ疲れもありましたが、それ以上に楽しさを感じることができました。
今回得た学びと反省点を活かし、次回はさらに成長した姿でコンペに挑みたいと思います。今度こそ上位入賞を目指し、取り組んでいきます。
最後までお読みいただきありがとうございました。

Discussion