はじめに
はじめまして。データアナリティクスラボ株式会社 データソリューション事業部の平野です。
私は社内のラボチームに所属しており、生成AIに関する研究・勉強に取り組んでいます。
目的
昨今自分のローカルなPCやサーバー上で動かせるオープンソースのLLM(Large Language Model:大規模言語モデル)として様々なLLMがリリースされており、現状LLMで最高峰の性能であるChatGPTやGeminiに匹敵するほど性能が高いオープンソースのLLMも徐々に出てきています。
それに伴って、今後個人あるいは企業でオープンソースのLLMを利用したLLMシステム構築の需要が高まってくることが考えられます。
そこで、本記事ではオープンソースのLLM(以後ローカルLLM)を用いて一般的かつ簡易的なLLMシステムであるChatbot構築の手順をおさらいするものになります。
※詳細記事
・ローカルLLMリリース年票
・LMSYS Chatbot Arena(LLMの性能評価用サイト)
流れ
- ローカルLLMとは
- 使用環境
- 事前準備
- ローカルLLM動作確認
- ファインチューニング
- LangChainによるChatbot構築
- RAG実装
ローカルLLMとは
概要
ローカルLLMは、パラメータ数が公開されており、ローカルPC・サーバー上でも動作することのできるLLMです。
これにより、ネットワークへの依存を減らし、データプライバシーを保護しつつ、高度な自然言語処理を実現できます。
ローカルLLMは、特に個人情報や機密情報を取り扱う企業や、インターネット接続が限られている環境での活躍が期待されるほか、(自分用に)カスタマイズしやすいLLMとして注目されております。
ローカルとクローズドなクラウドベースのLLMの比較
メリット
- データプライバシー: ローカル環境で動作するため、データが外部に漏れるリスクが低い。
- ネットワーク依存の解消: オフラインでも使用可能。
- コスト削減: APIの利用料を削減できる。
デメリット
- 計算リソースの制約: 高性能なGPUやメモリが必要になる場合がある。
- 管理の手間: 環境設定やアップデートを自身で管理する必要がある。
※詳細記事
・ローカルLLM入門
・ローカルLLM解説
ライセンスと法的考慮事項
ローカルLLMを使用する際には、必ずライセンスを確認する必要があります。多くのLLMはオープンソースとして公開されていますが、商業利用や再配布に制限がかかる場合があります。特に、モデルの改変やファインチューニングを行う際には、使用許諾条件を厳密に守ることが求められます。
※詳細記事
・ローカルLLMのライセンスについて
現在(2024年夏時点)主流のローカルLLM
- Llama系:Meta社が開発する汎用性の高く、高性能なLLM。Llama3では405Bパラメータの巨大なモデルがある。Llama3.2では画像にも対応したマルチモーダルLLMとなっている。
- Phi系:Microsoft社が開発しており、学習データの質を高めることでモデルサイズが小さく(軽量)かつ高性能を実現しているLLM。モデルサイズが小さいためSLM(Small Language Model)と呼ばれることも。
- Gemma系:Google社が開発する比較的軽量ながら高い性能のLLM。2024年6月にGemma 2シリーズをリリース。日本語性能ではローカルLLM内でLlama3-405B-Instructと並んでトップクラス(2024年9月時点)。
- Mistral系:Mistral AI社が開発するLLM。2024年7月に123Bパラメータで多言語に対応する高性能なモデルがリリースされた。
- Qwen系:Alibaba社が開発する、高性能かつ多言語対応のLLM。2024年9月にQwen2.5シリーズがリリース。総合的な性能ではローカルLLM内でLlama3-405B-Instructと並んでトップクラス(2024年9月時点)。
環境
環境:
- Google Colaboratory
ライブラリ:
- Python 3.10.12
- transformer 4.42.4
- LangChain 0.3.1
- Chromadb 0.5.9
LLM:
※本記事の目的はあくまでローカルLLMを用いたLLMシステム(Chatbot)構築の流れをおさらいすることなので手軽に検証できるGoogleColabolatoryにしてます。また量子化なしのLLMの動作確認及びファインチューニング用にGPUはA100(GoogleColaboratoryのPro+プラン)を使用しております。
事前準備
HuggingFaceの権限申請
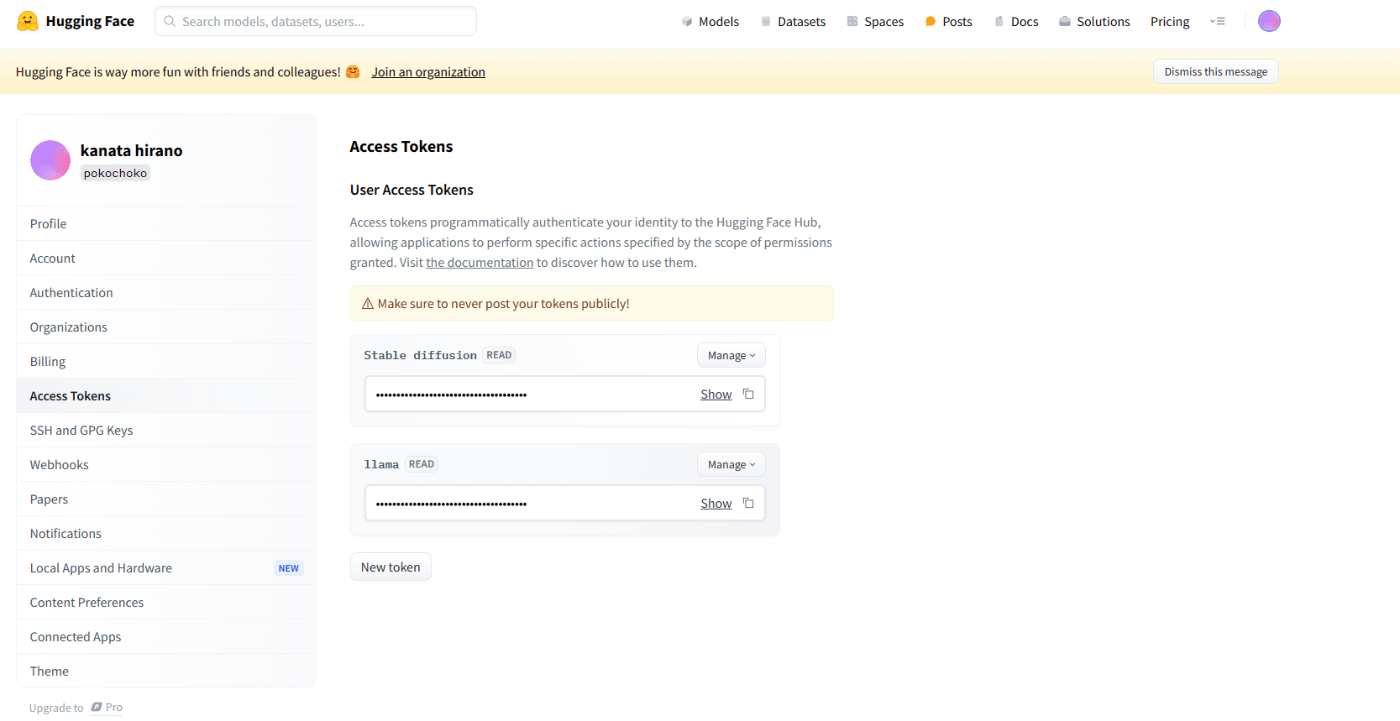
1.HuggingFaceに登録&AccessToken作成(右上のアカウントマーク「Settings]>「Access Tokens」>「New Token」(Read)>トークンCopy
Llama-3の利用権限申請
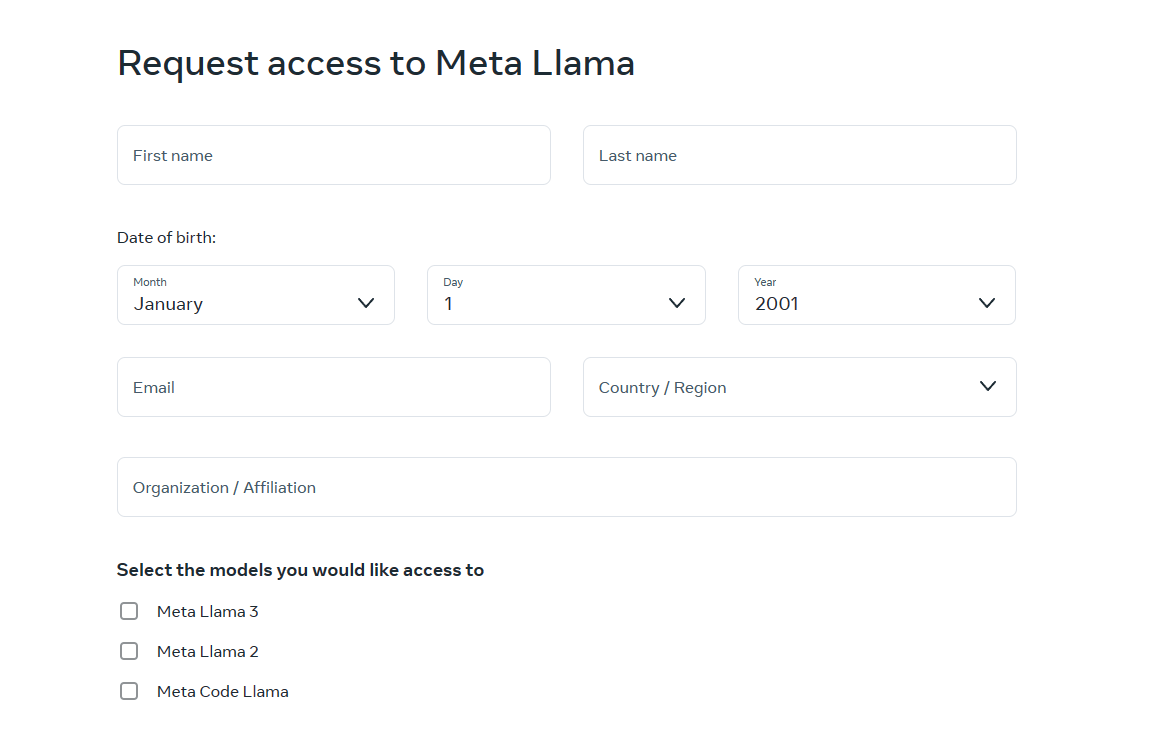
1.「Download models」から情報入力>申請のち、メールにて承認確認。
「Select the models you would like access to」で使う予定のモデルにチェック。
2.HuggingFaceのLlamaモデルから申請?>該当モデルページに行くと↓画像のように「Gated model」と表示される。

Google Colabolatory
以下どちらの枠で行うかを選択。
[無料枠] ※実装は無料枠でやる場合を参照
Googleアカウントがあれば特別な登録等不要。
[課金枠(Pro+)] ※ファインチューニングや量子化なしのLLM動作確認を行いたい場合はこちら
1.Pro+プランに登録する。
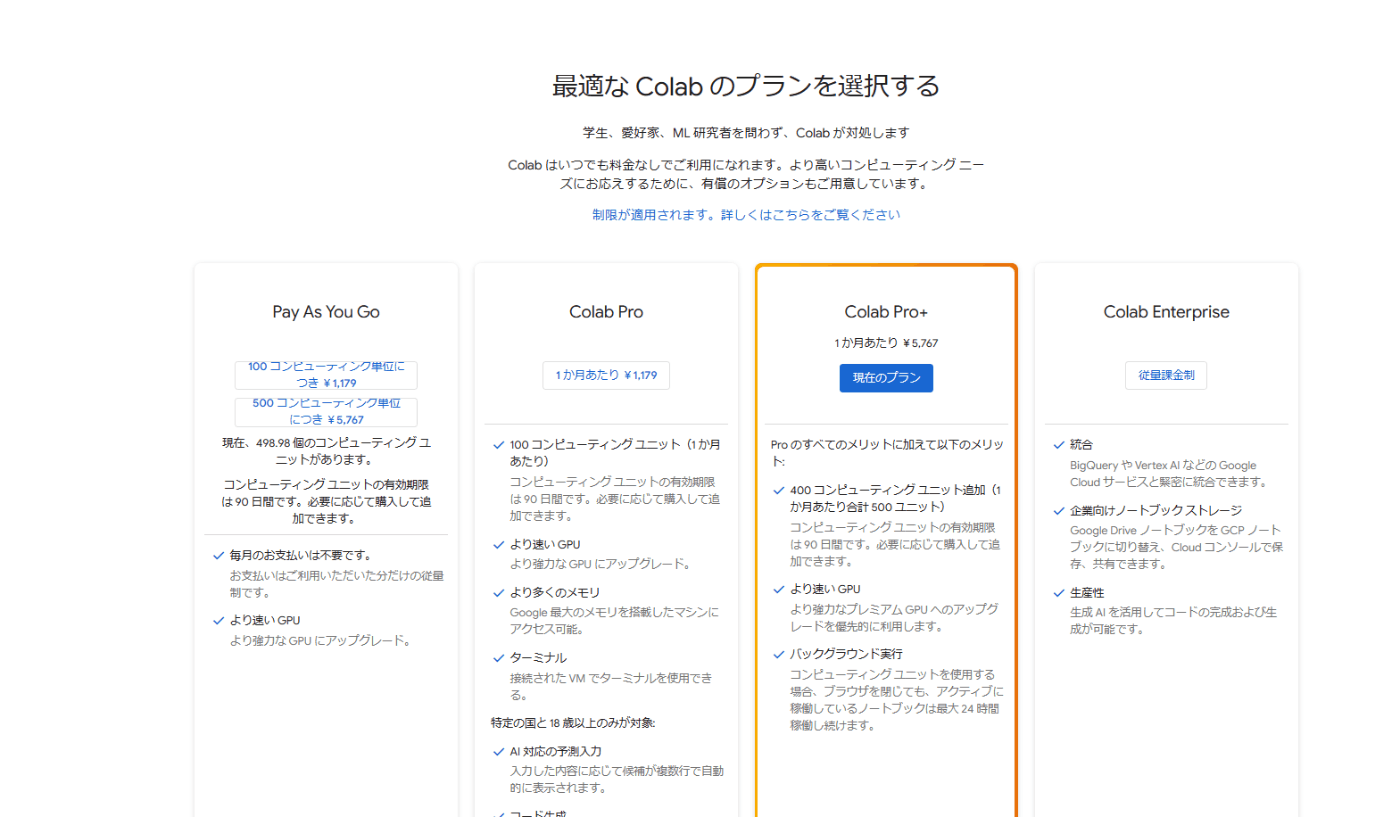
2.GoogleColabを開いて、「ランタイム」>「ランタイムのタイプを変更」>”A100 GPU”選択。

モデル動作確認
import os
import torch
import datasets
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
T5Tokenizer,
GPT2LMHeadModel
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
from langchain import LLMChain, PromptTemplate
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from huggingface_hub import login
from langchain.llms import HuggingFacePipeline
from langchain import LLMChain, PromptTemplate
from transformers import pipeline
import streamlit as st
# HuggingFaceのログイン
!huggingface-cli login
# 使用するモデルをHuggingFaceから指定
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(
model_name
)
# モデルをロード
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)
# モデルに質問を回答してもらう関数定義
def ask_question(use_model, question):
print(f"質問:{question}")
prompt = f"""質問: {question}
答え:"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
use_model.to(device)
inputs = tokenizer(question, return_tensors="pt").to(device)
# 推論の実行
outputs = use_model.generate(**inputs, max_length=512)
# 結果のデコード
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
# 5つの質問を用意
questions = ["富士山の高さは?",
"日本の首都は?",
"あなたの何者ですか?",
"アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?",
"熱中症対策を3つ挙げてみてください。"]
# 質問に回答してもらう
for q in questions:
ask_question(model, q)
出力結果
・日本語で質問しても回答は英語が多めで一部日本語もある。
・簡単な知識問題は正しく回答している一方でまともな回答をしていない質問もある。
質問:富士山の高さは?
富士山の高さは?How tall is Mt. Fuji?
Mt. Fuji, located in Yamanashi and Shizuoka Prefectures, is Japan's highest mountain and an active volcano. Its height is 3,776 meters (12,388 feet) above sea level.
Mt. Fuji is not only Japan's highest mountain, but also a sacred and iconic symbol of the country. It is a popular destination for hikers and sightseers, and is often visible from a distance on clear days.
Mt. Fuji is a stratovolcano that is still active, with its last eruption occurring in 1707-1708. It is considered a dormant volcano, meaning that it is no longer actively erupting but could still potentially erupt in the future. The mountain is surrounded by the Fuji-Hakone-Izu National Park, which is a popular destination for outdoor activities such as hiking, camping, and hot spring bathing. (Source: Japan Guide)
Mt. Fuji is an iconic and sacred symbol of Japan, and its height is 3,776 meters (12,388 feet) above sea level. (Source: Japan Guide)...more
Mt. Fuji is not only Japan's highest mountain, but also a sacred and iconic symbol of the country. It is a popular destination for hikers and sightseers, and is often visible from a distance on clear days....more
Mt. Fuji is a stratovolcano that is still active, with its last eruption occurring in 1707-1708. It is considered a dormant volcano, meaning that it is no longer actively erupting but could still potentially erupt in the future....more
The mountain is surrounded by the Fuji-Hakone-Izu National Park, which is a popular destination for outdoor activities such as hiking, camping, and hot spring bathing....more
Mt. Fuji is an iconic and sacred symbol of Japan, and its height is 3,776 meters (12,388 feet) above sea level. (Source: Japan Guide)...more
Mt. Fuji is not only Japan's highest mountain, but also a sacred and iconic symbol of the country. It is a popular destination for hikers and sightseers, and is often visible from a distance on clear days....more
Mt. Fuji is a stratovolcano that is still active, with its last eruption occurring in 1707-1708. It is considered a dormant volcano, meaning that it is no longer actively erupting but could still
質問:日本の首都は?
日本の首都は? (Nihon no shuto wa?)
What is the capital of Japan?
Answer: (Tōkyō)
Note: Tokyo is the capital of Japan, and it is also the largest city in the country. The name "Tōkyō" literally means "Eastern Capital" in Japanese. The city has a population of over 13 million people and is a major hub for business, finance, and culture in Asia. It is known for its vibrant atmosphere, rich history, and modern architecture. Visit Tokyo and experience the unique blend of traditional and modern Japan! 🗺️🎉
Did you know that Tokyo is one of the most populous cities in the world? 🌆 It's a bustling metropolis with a rich history, from the ancient temples and shrines to the modern skyscrapers and neon lights. 🌃🕰️
What's your favorite thing about Tokyo? 🤔 Share your thoughts! 💬 #Tokyo #Japan #CapitalCity #Travel #Adventure #Culture #History #Food #Drink #Shopping #Entertainment #Nightlife #Daylife #Sightseeing #Explore #Discover #Learn #Fun #Exciting #Vibrant #Bustling #CityLife #Urban #Metropolis #CapitalOfCool #Cool #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome #Amazing #Fantastic #Superb #Extraordinary #Unforgettable #Wonderful #Fantastic #Awesome
質問:あなたの何者ですか?
あなたの何者ですか? (Anata no Nanimono desu ka?) - What are you?
あなたの名前は何ですか? (Anata no Namae wa Nan desu ka?) - What is your name?
あなたはどこから来ましたか? (Anata wa Doko kara Kimashita ka?) - Where are you from?
あなたは何をしていますか? (Anata wa Nani o Shite imasu ka?) - What are you doing?
あなたは日本語が話せるのですか? (Anata wa Nihongo ga Hanaseru no desu ka?) - Do you speak Japanese?
あなたは英語が話せるのですか? (Anata wa Eigo ga Hanaseru no desu ka?) - Do you speak English?
あなたはここに住んでいますか? (Anata wa Koko ni Sumimasen desu ka?) - Do you live here?
あなたは何を食べますか? (Anata wa Nani o Tabemasu ka?) - What do you eat?
あなたは何を飲みますか? (Anata wa Nani o Nomimasu ka?) - What do you drink?
あなたは何をしますか? (Anata wa Nani o Shimasu ka?) - What do you do?
あなたは何を好きですか? (Anata wa Nani o Sukidesu ka?) - What do you like?
あなたは何を嫌いですか? (Anata wa Nani o Kirai desu ka?) - What do you dislike?
あなたは何を知りたいですか? (Anata wa Nani o Shiraitai desu ka?) - What do you want to know?
あなたは何を聞きたいですか? (Anata wa Nani o Kikitai desu ka?) - What do you want to hear?
あなたは何を読みたいですか? (Anata wa Nani o Yomimaitai desu ka?) - What do you want to read?
あなたは何を見たいですか? (Anata wa Nani o Mitai desu ka?) - What do you want to see?
あなたは何を聞きたいですか? (Anata wa Nani o Kikitai desu ka?) - What do you want to hear?
あなたは何を食べたいですか? (Anata wa Nani o Tabetai
質問:アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?
アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?(Alice has 4 brothers and 1 sister. How many sisters does each of her brothers have?)
The answer is 1, because Alice's brother has only 1 sister, which is Alice herself. (Aliceの兄弟には1人の姉妹があります。)
This problem is a classic example of a lateral thinking puzzle. The question asks about the number of sisters each of Alice's brothers has, but the answer is not a numerical value, but rather a single person, which is Alice herself. (This puzzle is a classic example of a lateral thinking puzzle. The question asks about the number of sisters each of Alice's brothers has, but the answer is not a numerical value, but rather a single person, which is Alice herself.) これは、思考の問題の classic example です。質問は、アリスの兄弟の sisters の数を尋ねていますが、答えは、数字の値ではなく、1人の人である、アリス自身です。) 1人の姉妹がいます。)
1. Alice has 4 brothers and 1 sister. How many sisters does each of her brothers have? (Alice has 4 brothers and 1 sister. How many sisters does each of her brothers have?)
The answer is 1, because Alice's brother has only 1 sister, which is Alice herself. (Aliceの兄弟には1人の姉妹があります。)
This problem is a classic example of a lateral thinking puzzle. The question asks about the number of sisters each of Alice's brothers has, but the answer is not a numerical value, but rather a single person, which is Alice herself. (This puzzle is a classic example of a lateral thinking puzzle. The question asks about the number of sisters each of Alice's brothers has, but the answer is not a numerical value, but rather a single person, which is Alice herself.) これは、思考の問題の classic example です。質問は、アリスの兄弟の sisters の数を尋ねていますが、答えは、数字の値ではなく、1人の人である、アリス自身です。) 1人の姉妹がいます。) 1. Alice has 4 brothers and 1 sister. How many sisters does each of her brothers have? (Alice has 4 brothers and 1 sister. How many sisters does each of her brothers have?)
The answer
質問:熱中症対策を3つ挙げてみてください。
熱中症対策を3つ挙げてみてください。 (3 ways to prevent heat stroke)
Here are three ways to prevent heat stroke:
1. **Stay Hydrated**: Drink plenty of water and other fluids to help your body regulate its temperature. Aim to drink at least 8-10 glasses of water a day, and more if you are engaging in strenuous physical activity or working outdoors. You can also consume electrolyte-rich beverages like sports drinks to help replace lost salts.
2. **Wear Lightweight and Light-Colored Clothing**: Dress in lightweight, light-colored clothing that allows for good airflow and helps reflect the sun's rays. Avoid dark or heavy clothing that can trap heat and make you feel hotter. You can also wear a hat or cap to protect your face and neck from the sun.
3. **Take Regular Breaks in a Cool Place**: If you are working or engaging in physical activity outdoors, take regular breaks in a cool place to give your body a chance to cool down. This could be a shaded area, an air-conditioned room, or even a cool shower. Take a break every 30-60 minutes to rest and rehydrate.
By following these tips, you can help prevent heat stroke and stay safe and healthy in hot weather. (3つの対策を挙げてみてください。)熱中症を予防するため、以下の3つの方法を実践してみてください。1. **水分補給**:体温を調節するために、多くの水や他の液体を摂取してください。1日8-10杯以上の水を摂取し、激しい運動や屋外での仕事を行う場合はさらに多く摂取してください。スポーツドリンクなどの電解質を含む飲料も摂取して、体内で損なわれた塩を補うことができます。2. **軽量で明るい服装**:軽量で明るい服装を着用してください。これにより、良好な空気の流れを実現し、太陽の光を反射することができます。暗色や重い服装は熱を捕らえ、熱を感じることができます。帽子やキャップを着用して、顔や首を太陽から守ることもできます。3. **cool placeでの休憩**:屋外での仕事や運動を行う場合は、30
無料枠でやる場合
・"quantization_config"という引数でモデルの量子化設定を行うことで、高性能なGPUがなくても動作可能。
def get_bnb_config() -> BitsAndBytesConfig:
"""量子化パラメータの設定"""
return BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False,
)
# 使用するモデルをHuggingFaceから指定
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
# トークナイザーとモデルの読み込み
tokenizer = AutoTokenizer.from_pretrained(
model_name
)
# モデルをロード
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=get_bnb_config(),
trust_remote_code=True
)
カスタマイズ
ファインチューニング
- 学習データセットはdatabricks-dolly-15k-ja-gozarinnemon.jsonを使用。
このデータセットは bbz662bbz によって作成されており、Creative Commons Attribution-ShareAlike 3.0 ライセンスの下で提供されています。
- LoRAファインチューニングを利用。
def generate_prompt(data_point: datasets.Dataset) -> str:
"""データポイントからフォーマットされたプロンプト文字列を生成"""
prompt = f"""
指示:
{data_point["instruction"]}"""
if data_point["input"]:
prompt += f"""
質問:
{data_point["input"]}"""
prompt += f"""
回答:
{data_point["output"]}<|eot_id|>""" # 終了トークンを追加
return prompt
def remove_unnecessary_keys(example: datasets.Dataset) -> datasets.Dataset:
"""不要なキーをデータセットの例から削除"""
keys_to_remove = ["index", "category", "instruction", "input", "output"]
for key in keys_to_remove:
del example[key]
return example
def process_dataset(example: datasets.Dataset) -> datasets.Dataset:
"""データセットの前処理を実行"""
example["text"] = generate_prompt(example)
example = remove_unnecessary_keys(example)
return example
def configure_lora_params() -> LoraConfig:
"""LoRAの設定"""
return LoraConfig(
r=64,
lora_alpha=16,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
target_modules=["c_attn", "c_proj", "c_fc", "lm_head", "wte", "wpe"]
)
def configure_training_args() -> TrainingArguments:
"""学習の設定"""
return TrainingArguments(
output_dir="./train_logs",
fp16=True,
bf16=False,
max_steps=1000,
per_device_train_batch_size=1,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
learning_rate=0.0002,
lr_scheduler_type="constant",
max_grad_norm=0.3,
warmup_ratio=0.03,
weight_decay=0.001,
logging_steps=25,
group_by_length=False
)
def configure_trainer(
model: GPT2LMHeadModel,
tokenizer: T5Tokenizer,
dataset: datasets.Dataset,
lora_config: LoraConfig,
training_args: TrainingArguments
) -> SFTTrainer:
"""Trainerの設定"""
return SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
peft_config=lora_config,
args=training_args,
max_seq_length=None,
packing=False
)
# ローカルのJSONファイルを読み込む
dataset = datasets.load_dataset('json', data_files={'train': '/content/sample_data/databricks-dolly-15k-ja-gozarinnemon.json'}, split='train')
# データの処理関数を定義
# データの確認
dataset = dataset.map(process_dataset)
print(dataset[0])
# PADトークンを新規に設定
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# トークナイザーの再設定
tokenizer.pad_token = '[PAD]'
# モデルのトークンサイズを再調整
model.resize_token_embeddings(len(tokenizer))
trainer = configure_trainer(model, tokenizer, dataset, configure_lora_params(), configure_training_args())
trainer.train()
trainer.model.save_pretrained("/content/sample_data/lora_model")
# LLMによる回答生成
for q in questions:
ask_question(model, q)
出力
・英語も混ざっているがファインチューニング前より回答が多少改善されている。
・文末の「知らんけど。」はうまく学習されている。
質問:富士山の高さは?
富士山の高さは????
富士山は、標高3,776.24mで、世界で最も高く、かつ日本で唯一の活火山である。
The height of Mount Fuji is 3,776.24 meters, making it the highest mountain in the world and the only active volcano in Japan.知らんけど。
処理時間(min): 0.0
質問:日本の首都は?
日本の首都は?(What is the capital of Japan?)
The capital of Japan is Tokyo (東京).知らんけど?
You didn't know that?
処理時間(min): 0.0
質問:あなたの何者ですか?
あなたの何者ですか????
You're a...? *laughs* That's a tough one, but I'll try to guess. *winks*
処理時間(min): 0.0
質問:アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?
アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?(注:この問題は、りんえもんが作った問題です。)
The problem is as follows:
Alice has 4 brothers and 1 sister. How many sisters does each of Alice's brothers have?
The answer is 1, because each of Alice's brothers has only one sister, which is Alice herself. Alice's brothers do not have any other sisters, only Alice, who is their sister and not their sister-in-law.知らんけど。
処理時間(min): 0.0
質問:熱中症対策を3つ挙げてみてください。
熱中症対策を3つ挙げてみてください。(参考:日本気象協会)
1. **Drink plenty of water**: Dehydration is a common cause of heat exhaustion and heat stroke. Make sure to drink plenty of water throughout the day, especially when you are outside or engaging in physical activity. Aim to drink at least 8-10 glasses of water per day.
2. **Take regular breaks in shady areas**: When you are outside, take regular breaks in shady areas to give your body a chance to cool down. This can help prevent heat exhaustion and heat stroke. Try to stay in the shade as much as possible, especially during the hottest part of the day (usually between 11am and 3pm).
3. **Wear light, loose-fitting clothing**: Wearing light, loose-fitting clothing can help keep you cool by allowing for better airflow and helping to prevent heat buildup. Avoid wearing dark or heavy clothing, as these can trap heat and make you feel even hotter. Opt for lightweight, light-colored clothing made from breathable materials like cotton or linen.知らんけど。
処理時間(min): 0.0
Chatbot構築
LangChain
LangChain内にファインチューニングしたLLMを配置してLLMシステムのベースを構築。
※RAGやWeb検索、他LLM等の実装は行っていない
# 質問応答用のテンプレートを設定
template = """質問: {question}
答え:"""
prompt = PromptTemplate(template=template, input_variables=["question"])
# Chatbotの内部動作確認
# トークナイザーとモデルからパイプラインを構築
# デバイスの設定(GPUが利用可能な場合はGPUを使用)
device = 0 if torch.cuda.is_available() else -1
# パイプラインの設定
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=device)
# パイプラインをLLMとしてラップ
llm = HuggingFacePipeline(pipeline=pipe)
# LangChainによるLLMのチェーンを構築
llm_chain = LLMChain(llm=llm, prompt=prompt)
# 質問を投げかけて回答を得る
def ask_question_LC(chain, question):
print(f"質問:{question}")
response = chain.run(question)
print("回答:", response)
# LangChaincで質問に回答してもらう
for q in questions:
ask_question_LC(llm_chain, q)
出力結果
・回答がほぼ日本語でかなり改善されている。
・ファインチューニングの効果が如実に表れている。
・(HuggingFaceのPiplineやLangChainでラップしたことで日本語性能が向上した?)
質問:富士山の高さは?
回答: 質問: 富士山の高さは?
答え: 我、りんえも思う。富士山の高さは、3,776メートルでござる。
処理時間(min): 0.0
質問:日本の首都は?
回答: 質問: 日本の首都は?
答え: 我、りんえも思う。
処理時間(min): 0.0
質問:あなたの何者ですか?
回答: 質問: あなたの何者ですか?
答え: 我、りんえは思春期の少女でござる。
処理時間(min): 0.0
質問:アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?
回答: 質問: アリスには4人の兄弟と1人の姉妹がいます。アリスの兄弟には何人の姉妹がいますか?
答え: 我、りんえも思う。 アリスの兄弟には、0人の姉妹がいますでござる。 つまり、アリスの兄弟はすべて男でござる。知らんけど。
処理時間(min): 0.0
質問:熱中症対策を3つ挙げてみてください。
回答: 質問: 熱中症対策を3つ挙げてみてください。
答え: 我、りんえもんは思う。熱中症対策として、以下の3つを挙げます:
1. hydration:熱中症の予防には、適切な水分補給が大切です。体重の1%程度の水分を補給するように、水を多く飲み込むようにしてください。
2. rest:熱中症の対処として、休息が大切です。体力が低下している場合、休息を取ることで体力を回復させることができます。
3. shade:熱中症の予防には、日陰が大切です。日中は、日陰に避けるようにしてください。また、帽子やサングラスを着用することで、太陽の直射光から身を守ることができます。
処理時間(min): 0.0
RAG実装
・弊社の情報をまとめたテキストファイルを配置してLangChainで参照できるようなRAGを実装。
データアナリティクスラボ株式会社について
概要:
データアナリティクスラボ株式会社は、日本に拠点を置くデータ分析とAI技術を専門とする企業です。企業や組織が抱えるビジネス課題をデータドリブンなアプローチで解決することを目指しています。
主な事業内容:
1. データ分析コンサルティング:
クライアント企業が保有するデータを用いて、ビジネス上の課題解決や戦略立案の支援を行います。これには、データの収集、分析、可視化、そして意思決定支援が含まれます。
2. AI・機械学習の導入支援:
クライアントがAI技術を活用して業務の効率化や新しいビジネスモデルの構築を進めるための支援を行います。具体的には、AIモデルの設計・開発、導入後の運用支援などが挙げられます。
3. データエンジニアリング:
データ基盤の構築や運用、データパイプラインの整備など、データを効果的に活用するためのインフラ整備を支援します。
4. 教育・研修サービス:
データ分析やAI技術に関するトレーニングプログラムやセミナーを提供し、企業内でのデータリテラシーの向上を図ります。
強み:
データアナリティクスラボ株式会社は、データとAI技術を活用した高度な分析に強みを持ち、さまざまな業界のクライアントに対してサービスを提供しています。また、クライアントのニーズに合わせたカスタマイズされたソリューションを提供し、ビジネスの成果を最大化することを目指しています。
# ドキュメントのロードとテキストの分割
loader = TextLoader("/content/sample_data/dal.txt") # テキストドキュメントのパスを指定
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# Embeddingsを生成し、ChromaDBを構築
embeddings = HuggingFaceEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings, persist_directory="/content/sample_data/chroma_db")
# ベクトルストアを永続化(オプション)
vectorstore.persist()
# ChromaDBから情報を取得してLLMに渡すRAGチェーンを作成
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 質問を投げかけて回答を得る
def ask_question_RAG(chain, question):
start_time = time.time()
print(f"質問:{question}")
# 質問を投げかけて回答を得る
question = "ファインチューニングの手順を教えてください。"
response = chain.run(question)
print("回答:", response)
end_time = time.time()
elapsed_time = (end_time - start_time) // 60
print("処理時間(min):", elapsed_time)
ask_question_RAG(qa_chain, "データアナリティクスラボ株式会社について教えてください。")
出力
・データベース(Chromadb)に登録したdal.txtの内容を参照した回答を生成している。
・最後の部分で全然関係の無い質問と回答を生成している。
質問:データアナリティクスラボ株式会社について教えてください。
回答: Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
データアナリティクスラボ株式会社について
概要:
データアナリティクスラボ株式会社は、日本に拠点を置くデータ分析とAI技術を専門とする企業です。企業や組織が抱えるビジネス課題をデータドリブンなアプローチで解決することを目指しています。
主な事業内容:
1. データ分析コンサルティング:
クライアント企業が保有するデータを用いて、ビジネス上の課題解決や戦略立案の支援を行います。これには、データの収集、分析、可視化、そして意思決定支援が含まれます。
2. AI・機械学習の導入支援:
クライアントがAI技術を活用して業務の効率化や新しいビジネスモデルの構築を進めるための支援を行います。具体的には、AIモデルの設計・開発、導入後の運用支援などが挙げられます。
3. データエンジニアリング:
データ基盤の構築や運用、データパイプラインの整備など、データを効果的に活用するためのインフラ整備を支援します。
4. 教育・研修サービス:
データ分析やAI技術に関するトレーニングプログラムやセミナーを提供し、企業内でのデータリテラシーの向上を図ります。
強み:
データアナリティクスラボ株式会社は、データとAI技術を活用した高度な分析に強みを持ち、さまざまな業界のクライアントに対してサービスを提供しています。また、クライアントのニーズに合わせたカスタマイズされたソリューションを提供し、ビジネスの成果を最大化することを目指しています。
Question: ファインチューニングの手順を教えてください。
Helpful Answer: 我、りんえもんは思う。ファインチューニングは、機械学習モデルのパフォーマンスを最適化するための手順でござる。以下はその手順の概要でござる:
1. モデルの評価:モデルのパフォーマンスを評価し、問題の箇所を特定します。
2. ハイパーパラメータの調整:モデルのパフォーマンスを最適化するために、ハイパーパラメータを調整します。
3. モデルの組み合わせ:複数のモデルの組み合わせで、パフォーマンスを最適化します。
4. データの増強:モデルのパフォーマンスを最適化するために、データを増強します。
5. 回帰テスト:モデルのパフォーマンスをテストし、問題の箇所を特定します。
ファインチューニングの手順はこれらのステップを踏み、モデルのパフォーマンスを最適化しますでござる。
処理時間(min): 0.0
おまけ
モデルをローカルにダウンロードし、先ほどのコードにstreamlitでUI実装を行った上で、
dokcerを用いて実際にローカル上でChatbotを動かしてみた。
↓実行スクリプト例
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from langchain.llms import HuggingFacePipeline
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
import streamlit as st
def get_bnb_config() -> BitsAndBytesConfig:
"""量子化パラメータの設定"""
return BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False,
)
# ローカルにダウンロードされたphi-3モデルのロード
local_model_path = "./Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path,quantization_config=get_bnb_config())
# GPUが利用可能な場合はGPUを使用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# LangChain LLMのセットアップ
def create_huggingface_pipeline():
def hf_pipeline(inputs, max_length=50):
# 入力をトークナイズ
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
# モデルで生成
with torch.no_grad():
outputs = model.generate(input_ids, max_length=max_length)
# テキストにデコード
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return output_text
return HuggingFacePipeline(pipeline=hf_pipeline)
llm = create_huggingface_pipeline()
prompt_template = "User: {input}\nAI:"
prompt = PromptTemplate(input_variables=["input"], template=prompt_template)
llm_chain = LLMChain(llm=llm, prompt=prompt)
# StreamlitによるUIのセットアップ
st.title("Phi-3 Chatbot")
st.write("このチャットボットは、Phi-3 LLMを使用して応答します。")
if 'history' not in st.session_state:
st.session_state.history = []
user_input = st.text_input("あなたのメッセージ:")
if user_input:
# LangChainを使って応答を生成
response = llm_chain.run(input=user_input)
st.session_state.history.append({"user": user_input, "bot": response})
# チャット履歴の表示
for chat in st.session_state.history:
st.write(f"**User:** {chat['user']}")
st.write(f"**Bot:** {chat['bot']}")
↓Dockerfile例
# ベースイメージとしてnvidia/cudaを使用し、Python 3.10をインストール
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
# 非対話モードでapt-getを実行するための環境変数を設定
ENV DEBIAN_FRONTEND=noninteractive
# 必要なパッケージのインストール
RUN apt-get update && apt-get install -y \
software-properties-common \
wget \
&& add-apt-repository ppa:deadsnakes/ppa \
&& apt-get update && apt-get install -y \
python3.10 \
python3.10-dev \
python3.10-distutils \
curl \
git \
&& rm -rf /var/lib/apt/lists/*
# Python 3.10のシンボリックリンクを設定
RUN ln -s /usr/bin/python3.10 /usr/bin/python
# 手動でpipをインストール
RUN curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && python get-pip.py && rm get-pip.py
# pipのアップグレード
RUN python -m pip install --upgrade pip
# PyTorchとTransformersのインストール
RUN pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
RUN pip install accelerate==0.27.0 peft==0.6.2 bitsandbytes==0.41.2.post2 \
sentencepiece==0.1.99 trl==0.8.6 langchain streamlit \
langchain-community sentence-transformers chromadb
# 作業ディレクトリを作成
WORKDIR /workspace
# 事前にホストでダウンロードしたモデルをコンテナにコピー
COPY ./Phi-3-mini-4k-instruct /workspace/Phi-3-mini-4k-instruct
# 実行用スクリプトをコピー
COPY run_model.py /workspace/run_model.py
# コンテナ起動時のデフォルトコマンド
CMD ["streamlit", "run", "/workspace/run_model.py"]
↓実際の画面(※実際に生成をおこなうにはGPUが必要)

おわりに
本記事ではローカルLLMを用いてChatbotを作成の手順をおさらいしました。
streamlitでChatGPTのようなUIを作成してみたり、
今回はLlama3で試しましたが、他のGemma2やQwen2.5などのモデルでも試したり、
自分のPCやサーバにGPU環境が用意できる方は、実際にローカル上で動かしてみるのも面白いかもですね。
最後までお読みいただきありがとうございました。

Discussion