【Ruby】シン・オブジェクト 第4形態!【オブジェクトマッパー編】
はじめに
Rubyでコードを書いてる時、配列の中の配列とか、ハッシュの中のハッシュとか、そういったデータ構造を取り扱うことってありませんか?
手軽にサクっと作れて、データ構造を表現するのに便利ですよね?でも、私はそういったデータ構造を取り扱う時ちょっとモヤモヤします。
ハッシュや配列などのデータ構造を直接取り扱っていると、カッコやクォートなどの記号があふれていて、そういったちょっとした記号の理解がチリ積もとなって、脳内のワーキングメモリを持っていかれてしまいます。
だから、そういったむき出しのデータ構造を直接取り扱うのではなく、コードの関心事をわかりやすくするために、モデル化を行いたくなるのです。
この記事では、Gemなどを使うのではなく、実際にコードを書いてモデル化していきたいと思います。いきなり最終的なコードを提示するのではなく、モデル化にいたる過程を段階的に説明していくことで、オブジェクト指向っぽくするために、どのような考えで進めているのか、サンプルを提示したいと思います。
これらに興味がある人向けの記事です
- オブジェクト指向
- モデル化
- メタプログラミング
- オブジェクトマッパー
- クラスインスタンス変数
- Rubyっぽい?コード
こんな人には不向きです
Rubyでデータ構造を宣言的にクラスで表現する方法をご紹介します。
以下の場合はこの記事は不向きです。
- データ構造をハッシュや配列そのままの形で使用したい場合
- データ構造をクラス化したいが、宣言的である必要がない場合
(オンデマンドでアクセッサーが生えれば良い場合は、OpenStructなどを使用)
「シン・オブジェクト」って何?
タイトルの「シン・オブジェクト」見て「何これ?」ってなった方へ。
すみません。
なんとなくノリで書いちゃいました。
オブジェクト指向に関連する記事を書きたいなと思ってたら、こんなタイトルになってしまいました。内容は真面目にオブジェクト指向に取り組んでいるつもりです。
目次
第1形態:むき出しのハッシュデータ
第2形態:シンプルなモデル
第2.5形態:コメントを書く
第3形態:モデルの中に保持したデータ構造を使ってサンプルデータを読み込む
第4形態:モデルとパース処理を分離する
サンプルデータ構造
例えば、次のような映画のデータベースみたいなものがあったとします。
映画作品集
映画
タイトル
評価
監督
名前
生年月日
キャスト
俳優
名前
生年月日
俳優
:
:
映画
:
:
このデータ構造は、YamlとかJsonとかXmlとか何でも良いのですが、階層構造になっていて、ライブラリーか何かで読み込んだ結果、次のようなハッシュと配列のデータになったとします。
$sample_data = {
:movies => [
{
:title => "インターステラー",
:star => "8.6",
:director => {:name => "クリストファーノーラン", :born => "1970-07-30"},
:cast => [
{:name => "マシューマコノヒー", :born => "1969-11-04"},
{:name => "アンハサウェイ", :born => "1982-11-12"}
]
},
{
:title => "パルプフィクション",
:star => "8.9",
:director => {:name => "クエンティンタランティーノ", :born => "1963-03-27"},
:cast => [
{:name => "ジョントラボルタ", :born => "1954-02-18"},
{:name => "サミュエル L ジャクソン", :born => "1948-12-21"},
{:name => "ブルースウィリス", :born => "1955-03-19"}
]
},
{
:title => "君の名は",
:star => "8.3",
:director => {:name => "新海誠", :born => "1973-02-09"},
:cast => [
{:name => "神木隆之介", :born => "1993-05-19"},
{:name => "上白石萌音", :born => "1998-01-27"},
]
}
]
}
このサンプルデータを取り扱っていくことを考えてみます。
話しをシンプルにするために、データの更新はちょっと置いておいて、データの参照に絞って話を進めます。
第1形態
むき出しのハッシュデータ
単純に中身を表示する処理を書いてみます。
まだモデルになっていないので、ハッシュデータをそのまま使います。
require_relative 'sample_data'
#
# サンプルデータ:ハッシュ構造を直接操作する
#
puts "===== 第1形態 =====\n\n"
$sample_data[:movies].each do | movie |
puts "movie: title: #{movie[:title]}, star: #{movie[:star]}"
puts "director: name: #{movie[:director][:name]}, born: #{movie[:director][:born]}"
movie[:cast].each do | actor |
puts "actor: name: #{actor[:name]}, born: #{actor[:born]}"
end
puts
end
===== 第1形態 =====
movie: title: インターステラー, star: 8.6
director: name: クリストファーノーラン, born: 1970-07-30
actor: name: マシューマコノヒー, born: 1969-11-04
actor: name: アンハサウェイ, born: 1982-11-12
movie: title: パルプフィクション, star: 8.9
director: name: クエンティンタランティーノ, born: 1963-03-27
actor: name: ジョントラボルタ, born: 1954-02-18
actor: name: サミュエル L ジャクソン, born: 1948-12-21
actor: name: ブルースウィリス, born: 1955-03-19
movie: title: 君の名は, star: 8.3
director: name: 新海誠, born: 1973-02-09
actor: name: 神木隆之介, born: 1993-05-19
actor: name: 上白石萌音, born: 1998-01-27
良いところ
- シンプルでコードが短い
モヤモヤするところ
- どういったデータ構造なのか、パッと見てわからない
- データに対するロジックをどこに書くか悩む
- ハッシュの表現がコードの可読性に直接影響している
- これってRubyらしいの?
どういったデータ構造なのか、パッと見てわからない
このコードは、コードの読み手に処理をトレースしてもらうことでデータ構造を理解することを期待しています。シンプルな構造のうちは良いのですが、複雑になってくると辛くなってきます。
コメントにデータ構造を書いて解消すべきことなのでしょうか?
データに対するロジックをどこに書くか悩む
オブジェクトは、データとその手続き(メソッド)をひとまとめにすることで、理解や取り扱いを良くするためのものです。
例えば、「star / 評価」が8.5以上の映画を取り出したいとなった場合、その判定ロジックはどこに書くべきなのでしょうか?
元データのハッシュの表現がコードの可読性に直接影響している
ハッシュのキーがむき出しのまま、もしも「movie」ってキーが「m」なんてキーだったら、このコードは可読性は著しく低下するでしょう。
これってRubyらしいの?
何がRubyらしいのか?こんな短いサンプルにRubyらしさも何もない。と言えばそうなのですが
こんな感じのコードがそっくりそのまま巨大化したものがよくあるので、モヤモヤしてしまうのです。
第2形態
シンプルなモデル
シンプルにデータ構造をクラスとアトリビュートを使って表現してみます。
require_relative 'sample_data'
#
# モデル定義
#
class Root
attr_accessor :movies
end
class Movie
attr_accessor :title
attr_accessor :star
attr_accessor :director
attr_accessor :cast
end
class Person
attr_accessor :name
attr_accessor :born
end
class Director < Person
end
class Actor < Person
end
#
# サンプルデータをモデルにマッピングする
#
root = Root.new
root.movies = []
$sample_data[:movies].each do | movie_hash |
movie = Movie.new
movie.title = movie_hash[:title]
movie.star = movie_hash[:star]
director_hash = movie_hash[:director]
director = Director.new
director.name = director_hash[:name]
director.born = director_hash[:born]
movie.director = director
cast = movie_hash[:cast]
movie.cast = []
cast.each do | actor_hash |
actor = Actor.new
actor.name = actor_hash[:name]
actor.born = actor_hash[:born]
movie.cast.push( actor )
end
root.movies.push( movie )
end
#
# マッピングされたモデルを操作する
#
puts "===== 第2形態 =====\n\n"
root.movies.each do | movie |
puts "movie: title: #{movie.title}, star: #{movie.star}"
puts "director: name: #{movie.director.name}, born: #{movie.director.born}"
movie.cast.each do |actor|
puts "actor: name: #{actor.name}, born: #{actor.born}"
end
puts
end
===== 第2形態 =====
movie: title: インターステラー, star: 8.6
director: name: クリストファーノーラン, born: 1970-07-30
actor: name: マシューマコノヒー, born: 1969-11-04
actor: name: アンハサウェイ, born: 1982-11-12
movie: title: パルプフィクション, star: 8.9
director: name: クエンティンタランティーノ, born: 1963-03-27
actor: name: ジョントラボルタ, born: 1954-02-18
actor: name: サミュエル L ジャクソン, born: 1948-12-21
actor: name: ブルースウィリス, born: 1955-03-19
movie: title: 君の名は, star: 8.3
director: name: 新海誠, born: 1973-02-09
actor: name: 神木隆之介, born: 1993-05-19
actor: name: 上白石萌音, born: 1998-01-27
コード長っ!
良くなったところ
- データ構造がパッと見て何となくわかる
- データに対するロジックを書きたくなった時にモデルに記述することができる
- ハッシュのキー表現を隠すことができる
モヤモヤするところ
- コードが長くなった
- モデル同士の関係はパッと見てもわからない
- データ構造とマッピング処理に関連性がない
- マッピングしてからトラバース(走査)しているので処理効率が悪い
いきなりコードが長くなりました。データ構造を1回走査するだけならオーバースペックですね。
このデータ構造を何度も使うのであれば仕方ないかも?と思うような長さです。
しかし、データ構造がわかりやすくなっていることや、データに対するロジックを書く場所が用意できたことは精神衛生上よろしいかと思います。
「cast」の中に「Actor」が複数入ることは、映画について知っていれば容易に想像できますが、もしも、読み手が前提知識を持っていないモデルなのであれば、マッピング処理を読み解く必要があります。
accessorを普段から使っている方だと、モデルのinitializeメソッドで、attrに初期値を設定したくなりますよね。
でも、そこはぐっと堪えましょう。理由は後半で!?
第2_5形態
コメントを書く
第2形態には、モデル同士の関係はパッと見てもわからない。といった、モヤモヤがありました。
データ構造にコメントを追記してみます。
このコードは実行しても何も起きません。
# このコードは実行しても何も起きない
#
# モデル定義
#
class Root
attr_accessor :movies # moviesという名前で、movieを複数保持する
end
class Movie
attr_accessor :title # 文字情報:タイトル
attr_accessor :star # 文字情報:評価
attr_accessor :director # directorというクラスを1つ保持する
attr_accessor :cast # castという名前で、actorを複数保持する
end
class Person
attr_accessor :name # 文字情報:名前
attr_accessor :born # 文字情報:生年月日
end
class Director < Person
end
class Actor < Person
end
データ構造をコードで表現してみる
上のコードはただのコメントですが、
データ構造がどうなっているかを、モデルの内部にデータとして保持することができれば、それを活用することができるかもしれません。
では、さっそくデータ構造をコードで表現してみましょう。
このコードはモデルの構造を表示するだけです。
サンプルデータの内容を表示するものではありません。
#
# モデルの構造をモデル内部に持つようにする
#
# このMapperモジュールは、このファイルの下にあるモデル定義時に呼び出される
#
module Mapper
module Model
# モデルにincludeされた時に実行される
def self.included(base)
base.instance_eval do
@text = []
@child = []
@has_many = []
end
base.extend Mapper::ClassMethods
end
end
module ClassMethods
def text(name)
@text.push(name)
attr_accessor(name)
end
def child(klass)
@child.push(klass)
attr_accessor(klass)
end
def has_many(name, klass)
@has_many.push( [ name, klass ] )
attr_accessor(name)
end
end
end
#
# モデル定義
# さっきのコメントをコードとして表現するようにした
#
class Root
include Mapper::Model
has_many :movies, :movie # moviesという名前で、movieを複数保持する
end
class Movie
include Mapper::Model
text :title
text :star
child :director
has_many :cast, :actor # castという名前で、actorを複数保持する
end
class Person
include Mapper::Model
text :name
text :born
end
class Director < Person
include Mapper::Model
end
class Actor < Person
include Mapper::Model
end
#
# 第2.5形態は、モデルの内部構造を表示するところまでしか行わない
#
puts "===== 第2.5形態 =====\n\n"
def print_structure(klass)
puts "#{klass}の構造"
klass.instance_variable_get("@text").each { |v| puts "#{v}" }
klass.instance_variable_get("@child").each { |v| puts "#{v}" }
klass.instance_variable_get("@has_many").each { |v| puts "#{v}" }
puts
end
print_structure(Root)
print_structure(Movie)
print_structure(Director)
print_structure(Actor)
===== 第2.5形態 =====
Rootの構造
[:movies, :movie]
Movieの構造
title
star
director
[:cast, :actor]
Directorの構造
Actorの構造
モジュールが出てきてややこしくなりましたが、実行結果を見ながらコードを読んでみるとモジュールがやっていることが見えてくると思います。
単純に内部の配列に、どんなtextがあるか、どんなchildがあるか、どんなhas_manyがあるか、を保持しているだけです。
あれっ? DirectorとActorの構造が表示されていませんね。
モデルの継承関係に対応する
モデルの継承関係に対応させます。
このコードは、まだモデルの構造を表示するだけです。
サンプルデータの内容を表示するものではありません。
def self.included(base)に追記します。
require_relative 'sample_data'
#
# モデルの構造をモデル内部に持つようにする
#
# このMapperモジュールは、このファイルの下にあるモデル定義時に呼び出される
#
module Mapper
module Model
# モデルにincludeされた時に実行される
def self.included(base)
# 継承されている場合に親クラスから内部構造を持ってくる
if base.superclass < Model
base.instance_eval do
@text = base.superclass.instance_variable_get("@text")
@child = base.superclass.instance_variable_get("@child")
@has_many = base.superclass.instance_variable_get("@has_many")
end
else
base.instance_eval do
@text = []
@child = []
@has_many = []
end
end
base.extend Mapper::ClassMethods
end
end
module ClassMethods
def text(name)
@text.push(name)
attr_accessor(name)
end
def child(klass)
@child.push(klass)
attr_accessor(klass)
end
def has_many(name, klass)
@has_many.push( [ name, klass ] )
attr_accessor(name)
end
end
end
#
# モデル定義
# さっきのコメントをコードとして表現するようにした
#
class Root
include Mapper::Model
has_many :movies, :movie # moviesという名前で、movieを複数保持する
end
class Movie
include Mapper::Model
text :title
text :star
child :director
has_many :cast, :actor # castという名前で、actorを複数保持する
end
class Person
include Mapper::Model
text :name
text :born
end
class Director < Person
include Mapper::Model
end
class Actor < Person
include Mapper::Model
end
#
# 第2.5形態は、モデルの内部構造を表示するところまでしか行わない
#
puts "===== 第2.5形態 =====\n\n"
def print_structure(klass)
puts "#{klass}の構造"
klass.instance_variable_get("@text").each { |v| puts "#{v}" }
klass.instance_variable_get("@child").each { |v| puts "#{v}" }
klass.instance_variable_get("@has_many").each { |v| puts "#{v}" }
puts
end
print_structure(Root)
print_structure(Movie)
print_structure(Director)
print_structure(Actor)
===== 第2.5形態 =====
Rootの構造
[:movies, :movie]
Movieの構造
title
star
director
[:cast, :actor]
Directorの構造
name
born
Actorの構造
name
born
継承されたデータ構造が表現できました。
コードでモデル同士の関係を表現できるようになりましたが
まだ、この時点ではただのコメントと変わりありません。
良いところ
- データ構造がパッと見てわかる
- データ構造を内部に保持している
モヤモヤするところ
- コードが長く、そして複雑になってきた
- データ構造を内部に保持しているが、まだパース処理との関連はないまま
クラスインスタンス変数
Rubyをそれなりに使っていると、クラス変数やインスタンス変数について学ぶと思います。
でも、クラスインスタンス変数については、なかなか学ぶ機会がないのではないでしょうか?
上記のコードでは、クラスインスタンス変数を使っています。
@text、@child、@has_many がそうです。
簡単に説明するとクラスインスタンス変数は
- クラス変数のように、クラスをnewしていなくても使える
- クラス変数と違って、サブクラスからはアクセスできない
- クラスの数だけ用意される
といった特長があります。
上記のコードだと、@text、@child、@has_manyは、
Root、Movie、Director、Actor、Personの数だけ存在します。
@textなら5個あることになります。
どうしてスーパークラスじゃなくてインクルードなのか
どうして、こんな風にスーパークラスで実装を行わずに
class Root < Mapper::Model
includeで実装しているのか?
class Root
include Mapper::Model
Rubyは、単一継承がサポートされていて、多重継承はサポートされていません。その代わりにmixinがサポートされています。
継承は単一継承しかできないので、何を継承するかをきちんと考えたいところです。
今回は継承機能を使う候補は2つあります。
ひとつは、映画のデータを表したモデルそのもの。
もうひとつは、データ構造を表してマッピングするための仕組み。
コードの読み手に関心を持ってもらいたいのは、映画のデータ構造の方です。
データ構造をマッピングする仕組み(Mapper::Model)はどちらかというと裏方の仕組みです。今回は映画のデータを表したモデルの方を継承するようにしました。
第3形態
モデルの中に保持したデータ構造を使ってサンプルデータを読み込む
先ほど用意した内部のデータ構造を使って、サンプルデータからモデルにデータを読み込んでみます。
includeしていた Mapper::Model を別ファイルに切り出しました。
require_relative 'sample_data'
require_relative 'mapper'
#
# モデル定義
#
class Root
include Mapper::Model
has_many :movies, :movie
end
class Movie
include Mapper::Model
text :title
text :star
child :director
has_many :cast, :actor
end
class Person
include Mapper::Model
text :name
text :born
end
class Director < Person
include Mapper::Model
end
class Actor < Person
include Mapper::Model
end
#
# サンプルデータをオブジェクトにマッピングする
#
root = Root.parse($sample_data)
#
# モデルを操作する
#
puts "===== 第3形態 =====\n\n"
root.movies.each do | movie |
puts "movie: title: #{movie.title}, star: #{movie.star}"
puts "director: name: #{movie.director.name}, born: #{movie.director.born}"
movie.cast.each do |actor|
puts "actor: name: #{actor.name}, born: #{actor.born}"
end
puts
end
マッピング処理と共にパース処理を組み込みました。
パース処理は、モデルの内部に保持したデータ構造を元に、ハッシュデータ構造からデータを取ってきてモデルのアトリビュートとして保存する処理です。
module Mapper
module Model
# モデルにincludeされた時に実行される
def self.included(base)
# モデルが継承されている場合、データ構造をコピーする
if base.superclass < Model
base.instance_eval do
@text = base.superclass.instance_variable_get("@text")
@child = base.superclass.instance_variable_get("@child")
@has_many = base.superclass.instance_variable_get("@has_many")
end
else
base.instance_eval do
@text = []
@child = []
@has_many = []
end
end
base.extend Mapper::ClassMethods
end
end
module ClassMethods
def text(name)
@text.push(name)
attr_accessor(name)
end
def child(klass)
@child.push(klass)
attr_accessor(klass)
end
def has_many(name, klass)
@has_many.push( [ name, klass ] )
attr_accessor(name)
end
#
# ここから下はパース処理
#
def parse(hash)
instance = new
parse_text(hash, instance)
parse_child(hash, instance)
parse_has_many(hash, instance)
instance
end
def parse_text(hash, instance)
text_list = instance.class.instance_variable_get("@text")
text_list.each do |text_name|
text_value = hash[text_name]
unless text_value.nil?
instance.instance_variable_set("@#{text_name}", text_value)
end
end
end
def parse_child(hash, instance)
child_list = instance.class.instance_variable_get("@child")
child_list.each do |child_klass|
child_hash = hash[child_klass]
unless child_hash.nil?
child_instance = create_instance_and_parse(child_klass, child_hash)
instance.instance_variable_set("@#{child_klass}", child_instance)
end
end
end
def parse_has_many(hash, instance)
has_many_list = instance.class.instance_variable_get("@has_many")
has_many_list.each do |has_many|
list_name = has_many[0]
klass_name = has_many[1]
sibling_list = hash[list_name]
next if sibling_list.nil?
sibling_list.each do |sibling_hash|
sibling_instance = create_instance_and_parse(klass_name, sibling_hash)
sibling = instance.instance_variable_get("@#{list_name}")
sibling ||= []
sibling.push(sibling_instance)
instance.instance_variable_set("@#{list_name}", sibling)
end
end
end
# 子オブジェクトを作ってパースを再帰呼び出しする
def create_instance_and_parse(klass_name, hash)
# クラス名に変換するところが手抜き処理
klass_name = klass_name.to_s.capitalize
klass = Object.const_get(klass_name)
instance = klass.parse(hash)
instance
end
end
end
===== 第3形態 =====
movie: title: インターステラー, star: 8.6
director: name: クリストファーノーラン, born: 1970-07-30
actor: name: マシューマコノヒー, born: 1969-11-04
actor: name: アンハサウェイ, born: 1982-11-12
movie: title: パルプフィクション, star: 8.9
director: name: クエンティンタランティーノ, born: 1963-03-27
actor: name: ジョントラボルタ, born: 1954-02-18
actor: name: サミュエル L ジャクソン, born: 1948-12-21
actor: name: ブルースウィリス, born: 1955-03-19
movie: title: 君の名は, star: 8.3
director: name: 新海誠, born: 1973-02-09
actor: name: 神木隆之介, born: 1993-05-19
actor: name: 上白石萌音, born: 1998-01-27
良いところ
- データ構造にパース処理が関連付いた
モヤモヤするところ
- コードがさらに長く、さらに複雑になった。もはや諦めの境地
ほぼ完成です。
モデル自身がデータ構造を表現し、そのデータ構造を使ってデータをモデルに読み込むことができました。
モデルを用意すれば、映画データ構造以外のデータ構造にも対応できるようになっています。
第4形態
モデルとパース処理を分離する
モデルは、データ構造を保持する。
パーサーは、データ構造を元にデータを読み込む。
といった具合に、責務によってコードを分けます。
require_relative 'sample_data'
require_relative 'mapper2'
require_relative 'parser'
#
# モデル定義
#
class Root
include Mapper::Model
has_many :movies, :movie
end
class Movie
include Mapper::Model
text :title
text :star
child :director
has_many :cast, :actor
end
class Person
include Mapper::Model
text :name
text :born
end
class Director < Person
include Mapper::Model
end
class Actor < Person
include Mapper::Model
end
#
# サンプルデータをオブジェクトにマッピングする
#
parser = Parser.new
root = Root.parse(parser, $sample_data)
#
# モデルを操作する
#
puts "===== 第4形態 =====\n\n"
root.movies.each do | movie |
puts "movie: title: #{movie.title}, star: #{movie.star}"
puts "director: name: #{movie.director.name}, born: #{movie.director.born}"
movie.cast.each do |actor|
puts "actor: name: #{actor.name}, born: #{actor.born}"
end
puts
end
module Mapper
module Model
# モデルにincludeされた時に実行される
def self.included(base)
# モデルが継承されている場合、データ構造をコピーする
if base.superclass < Model
base.instance_eval do
@text = base.superclass.instance_variable_get("@text")
@child = base.superclass.instance_variable_get("@child")
@has_many = base.superclass.instance_variable_get("@has_many")
end
else
base.instance_eval do
@text = []
@child = []
@has_many = []
end
end
base.extend Mapper::ClassMethods
end
end
module ClassMethods
def text(name)
@text.push(name)
attr_accessor(name)
end
def child(klass)
@child.push(klass)
attr_accessor(klass)
end
def has_many(name, klass)
@has_many.push( [ name, klass ] )
attr_accessor(name)
end
def parse(parser, hash)
instance = new
# 外部で定義されたパーサーに委譲する
parser.parse(hash, instance)
instance
end
end
end
class Parser
def parse(hash, instance)
parse_text(hash, instance)
parse_child(hash, instance)
parse_has_many(hash, instance)
end
def parse_text(hash, instance)
text_list = instance.class.instance_variable_get("@text")
text_list.each do |text_name|
text_value = hash[text_name]
unless text_value.nil?
instance.instance_variable_set("@#{text_name}", text_value)
end
end
end
def parse_child(hash, instance)
child_list = instance.class.instance_variable_get("@child")
child_list.each do |child_klass|
child_hash = hash[child_klass]
unless child_hash.nil?
child_instance = create_instance_and_parse(child_klass, child_hash)
instance.instance_variable_set("@#{child_klass}", child_instance)
end
end
end
def parse_has_many(hash, instance)
has_many_list = instance.class.instance_variable_get("@has_many")
has_many_list.each do |has_many|
list_name = has_many[0]
klass_name = has_many[1]
sibling_list = hash[list_name]
next if sibling_list.nil?
sibling_list.each do |sibling_hash|
sibling_instance = create_instance_and_parse(klass_name, sibling_hash)
sibling = instance.instance_variable_get("@#{list_name}")
sibling ||= []
sibling.push(sibling_instance)
instance.instance_variable_set("@#{list_name}", sibling)
end
end
end
# 子オブジェクトを作ってパースを再帰呼び出しする
def create_instance_and_parse(klass_name, hash)
# クラス名に変換するところが手抜き処理
klass_name = klass_name.to_s.capitalize
klass = Object.const_get(klass_name)
instance = klass.parse(self, hash)
instance
end
end
===== 第4形態 =====
movie: title: インターステラー, star: 8.6
director: name: クリストファーノーラン, born: 1970-07-30
actor: name: マシューマコノヒー, born: 1969-11-04
actor: name: アンハサウェイ, born: 1982-11-12
movie: title: パルプフィクション, star: 8.9
director: name: クエンティンタランティーノ, born: 1963-03-27
actor: name: ジョントラボルタ, born: 1954-02-18
actor: name: サミュエル L ジャクソン, born: 1948-12-21
actor: name: ブルースウィリス, born: 1955-03-19
movie: title: 君の名は, star: 8.3
director: name: 新海誠, born: 1973-02-09
actor: name: 神木隆之介, born: 1993-05-19
actor: name: 上白石萌音, born: 1998-01-27
コードの長さには辟易します。
良いところ
- 責務が明確になった
- モデルはデータ構造を表現
- パーサーはデータ読み込み処理を表現
パーサーを切り替えることで、ハッシュデータ構造以外のデータ構造、例えば、XMLやYamlやJsonなどにも対応できるようになります。
モデルの初期化メソッドで初期値を設定しない理由
第2形態でモデル化した時
accessorを普段から使っている方だと、モデルのinitializeメソッドで、attrに初期値を設定したくなりますよね。
でも、そこはぐっと堪えましょう。理由は後ほど!?
この理由なのでが
モデルのinitializeメソッドでhashを受け取ってattrにセットしたとすると
下の図のように、モデルがハッシュデータに依存する関係になります。

パーサーを間にはさむことで、モデルはハッシュデータに依存しなくなります。
この関係が可能なのは、モデルが自身のデータ構造をパーサーに開示しているからです。
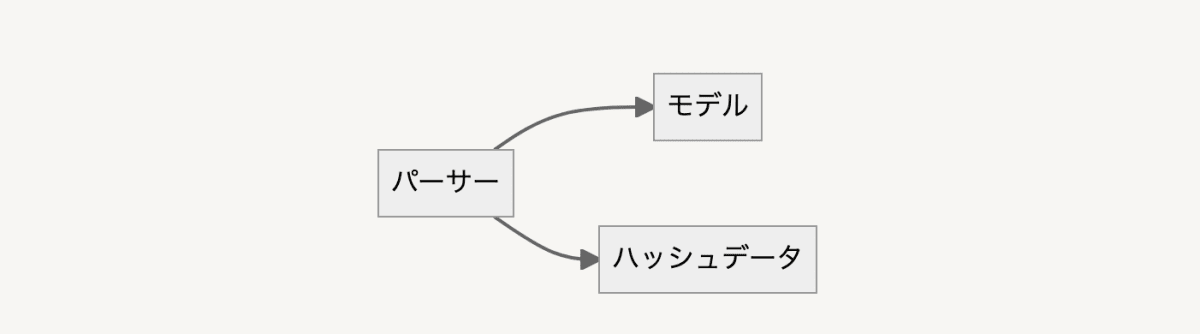
モデルとデータに直接の依存関係がないので、パーサーを切り替えることで、他のデータ形式に対応させることもできます。

まとめ
第1形態
ハッシュデータそのまま
第2形態
シンプルなモデル
第3形態
モデルの内部に自身のデータ構造を保持する。
そのデータ構造を元にパースし、取得した値をモデルにマッピングする。
第4形態
モデルからパース処理を分離
残る課題
第1形態のところで
元データのハッシュの表現がコードの可読性に直接影響している
ハッシュのキーがむき出しのまま、もしも「movie」ってキーが「m」なんてキーだったら、このコードは可読性は著しく低下するでしょう。
実は、第3、第4形態でもここはスルーしています。
サンプルコードをシンプルにして理解し易くするためです。
しかし、ちょっと変更するだけで、
「movie」ってキーが「m」
みたいなのに対応できるので、少し考えてみてください。
class Root
include Mapper::Model
has_many :movies, :movie :m # <-- こんな感じに書けると嬉しい
end
最後に
いかがでしたでしょうか。
今回ご紹介したこのような仕組みのことを「オブジェクトマッパー」と呼んだりします。
モデル化とかメタプログラミングとかオブジェクト指向とか
いっぱい詰め込み過ぎて説明しきれていない感は否めませんが、
少しでも、みなさんの好奇心の刺激になったらと思います。
ご質問、ご指摘事項、ご要望(もう少しここを説明してほしいとか)ありましたらコメントいただけると幸いです。
オブジェクト指向は用量用法を守ってお使いください。
Discussion