過去のテストの実行時間を利用してテストの sharding を効率化する Tenbin というツールを作りました。
この記事では Tenbin が解決する課題と内部実装の詳細について解説します。ツールの使い方などは、リポジトリの README をぜひ読んでもらえればと思います。
Tenbin が解決する課題
テストの実行時間を削減するために、CI などではテストを sharding (分割) して実行することがあると思います。フロントエンドでよく使われる Jest、Vitest、Playwright などのツールでは、実際に sharding の機能を提供しています。
確かに sharding はテストの実行時間を削減できるのですが、分割のアルゴリズムがいまいちで shard 毎の実行時間に大きく差が出てしまった経験はないでしょうか?[1]Tenbin は、この問題を過去のテストの実行時間を利用して改善します。
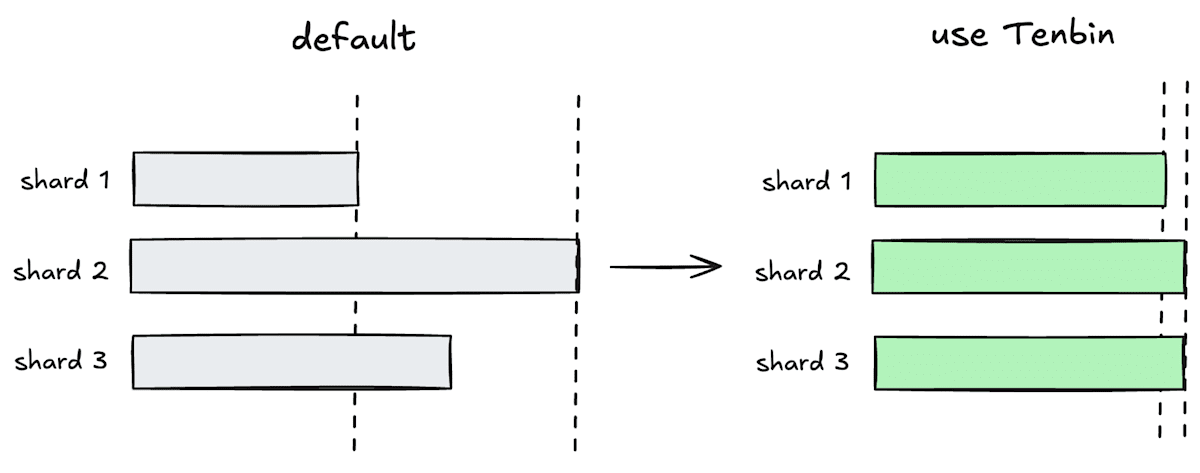
Tenbin は、shard 間の実行時間の差を最小化する
ちなみに、Playwright では同様の issue が作成されており、issue に対応する PR もいくつか作成されたようなのですが、メンテナンスコストなどが理由となって未だにマージされていないようです。
Tenbin の内部実装
Tenbin は、前節で紹介した既存のツールの sharding の課題を解決するために、過去のテストの実行時間のデータを利用して、各 shard のテストの実行時間の差が最小になるようにテストを分割します。これは、数分割問題 (multiway number partitioning) と呼ばれる一般的な問題に帰着でき、NP 困難な問題ではあるのですが近似解を計算することができます。
今回は近似解として平均的に良い解を導出できる差分法を用いて実装しました。差分法については、以下のようなアルゴリズムになります。
数の集合を {8,7,6,5,4}、分割の個数を 3 とすると、
- 1つ目の要素にデータを1つずつ追加した 3 つの要素を持つ tuple を用意する
例) ({8},{},{}), ({7},{},{}), ({6},{},{}), ({5},{},{}), ({4},{},{}). - tuple 内の各要素の和の差が最も大きくなる 2 つの tuple A, B を選択する
例) 初期状態は tuple 内の 1 番目の要素以外は 0 なので、({8},{},{}), ({7},{},{}) が選択される - 選択した tuple を「サイズが逆順」になるように結合する
例) ({8},{},{}), ({},{},{7}) として、それぞれ結合すると ({8}, {}, {7}) となる - 2,3 を tuple が1つになるまで繰り返す
文章だけだとわかりにくいと思うので、以下の記事や自分のまとめた scrap を参考にしてもらえればと思います。
分割のアルゴリズムが実装できれば、あとはこれを各フレームワークに適用するだけです。
Jest・Vitest 用の API
Jest や Vitest では、custom sequencer の仕組みを利用して決められた I/F の範囲内で自由に sharding や sort のアルゴリズムを変更できます。
今回実装した Jest の場合での custom sequencer は以下のようになりました。 shard メソッドの細かい I/F の内容は、TypeScript の型定義を確認してもらうのが良いと思います。
import * as fs from "node:fs";
import * as path from "node:path";
import type { Test } from "@jest/test-result";
import Sequencer from "@jest/test-sequencer";
import type { ShardOptions } from "@jest/test-sequencer";
// 差分法で分割する関数
import { partition } from "@tenbin/core";
// 0 だと差分法がうまく動かないので 0 に近い値にしておく
const FALLBACK_DURATION = 0.01;
const REPORT_FILENAME = "tenbin-report.json";
export default class TenbinSequencer extends Sequencer {
private durations: Record<string, number> = {};
constructor() {
super();
this.durations = this.loadDurations();
}
shard(
tests: Array<Test>,
options: ShardOptions
): Array<Test> | Promise<Array<Test>> {
// 読み込んだファイルを利用して、test の実行時間を object に持たせる
for (const test of tests) {
const relativePath = path.relative(process.cwd(), test.path);
// 実行時間が見つからない場合は、フォールバック用の値を入れる
test.duration = this.durations[relativePath] ?? FALLBACK_DURATION;
}
// 差分法を使ってテストを分割
const partitions = partition<Test>(
tests,
options.shardCount,
(test) => test.duration ?? FALLBACK_DURATION
);
return partitions[options.shardIndex - 1];
}
// 過去のテストの実行時間をファイルから読み込む
private loadDurations(): Record<string, number> {
const filePath = path.join(process.cwd(), REPORT_FILENAME);
try {
const durations = JSON.parse(fs.readFileSync(filePath, "utf8"));
return durations;
} catch (_err) {
return {};
}
}
}
上記のコードでは、テストの実行時間を tenbin-report.json から読み込んでいますが、このファイルは custom reporter の機能を利用して出力するようにします。Tenbin での実装は次のようになりました。
import * as fs from "node:fs";
import * as path from "node:path";
import type {
AggregatedResult,
Reporter,
Test,
TestResult,
} from "@jest/reporters";
const REPORT_FILENAME = "tenbin-report.json";
export default class TenbinReporter implements Reporter {
private durations: Record<string, number> = {};
onTestResult(test: Test, testResult: TestResult): void {
const relativePath = path.relative(process.cwd(), test.path);
this.durations[relativePath] = this.getDuration(test, testResult) / 1000;
}
onRunComplete(_: unknown, _: AggregatedResult): void {
const reportFilePath = path.join(process.cwd(), REPORT_FILENAME);
try {
fs.writeFileSync(reportFilePath, JSON.stringify(this.durations));
} catch (err) {
console.error(err);
}
}
// 各ファイルのテストの実行時間の総和を取得する
private getDuration(test: Test, testResult: TestResult): number {
if (test.duration !== undefined) {
return test.duration;
}
const { start, end } = testResult.perfStats;
return start && end ? end - start : 0;
}
}
custom reporter は、PR のコメントに投稿する用のテストの結果のサマリーを markdown で出力させるなど、色々な使い道があるので便利です。以下のリンクにはすでに OSS として公開されてる custom reporter がまとめられているので、気になる人は確認してみると良いと思います。
Playwright 用の API
Playwright は、Jest や Vitest のように sharding のアルゴリズムを変更する機能を提供していません。関連する issue はすでに作成されていて、どうやら次の minor version (v1.50) で対応するようです。
今回は、テストを分割する splitTests を提供し、その返り値を Playwright の設定の testMatch に渡すことで実現しました。
import { defineConfig } from "@playwright/test";
import { splitTests } from "@tenbin/playwright";
export default defineConfig({
testMatch: splitTests({
shard: "1/3",
pattern: ["tests/**.test.ts"],
reportFile: "./test-results.json",
}),
});
splitTests は、shard の設定、実行したいテストの glob パターン、過去のテストの JSON レポートを受け取って、テストを分割した結果を返します。実際の関数の実装は以下のようになっていて、テストの分割で必要になるロジックは Jest・Vitest の場合とそこまで変わらないことがわかると思います。
import * as fs from "node:fs";
import * as path from "node:path";
import type { JSONReport, JSONReportSuite } from "@playwright/test/reporter";
import { partition } from "@tenbin/core";
import { globSync } from "glob";
const FALLBACK_DURATION = 0.1;
type Config = {
shard: string;
reportFile: string;
pattern: string[];
};
type Test = {
duration?: number;
path: string;
};
export function splitTests(config: Config): string[] {
const { shard, reportFile, pattern } = config;
const tests: Test[] = globSync(pattern).map((path) => ({ path }));
const { shardCount, shardIndex } = extractShardConfig(shard);
const durations = loadDurations(reportFile);
for (const test of tests) {
test.duration = durations[test.path] ?? FALLBACK_DURATION;
}
const partitions = partition<Test>(
tests,
shardCount,
(test) => test.duration ?? FALLBACK_DURATION
);
return partitions[shardIndex - 1].map((test) => test.path);
}
type ShardConfig = {
shardCount: number;
shardIndex: number;
};
// shard の設定の読み込み
function extractShardConfig(shard: string): ShardConfig {
try {
const [shardIndex, shardCount] = shard.split("/");
return { shardCount: Number(shardCount), shardIndex: Number(shardIndex) };
} catch (err) {
throw new Error(
"The shard value is invalid. The value requires '<shardCount>/<shardIndex>' format."
);
}
}
// 過去の JSON レポートの読み込み
function loadDurations(reportFile: string): Record<string, number> {
const filePath = path.join(process.cwd(), reportFile);
try {
const report: JSONReport = JSON.parse(fs.readFileSync(filePath, "utf8"));
const durations: Record<string, number> = {};
for (const suite of report.suites) {
durations[suite.file] = calculateDuration(suite);
}
return durations;
} catch (_err) {
return {};
}
}
// 各ファイルのテストの実行時間の総和を取得する
function calculateDuration(suite: JSONReportSuite): number {
let duration = 0;
for (const spec of suite.specs) {
for (const test of spec.tests) {
for (const result of test.results) {
duration += result.duration / 1000;
}
}
}
for (const test of suite.suites ?? []) {
duration += calculateDuration(test);
}
return duration;
}
最後に
今回の記事では、 Tenbin が解決する課題と内部実装の詳細について解説しました。読んでもらって感じたと思うのですが、Playwright の場合はだいぶハック感のある実装になっていると思います。次の minor version で予定されている sharding の変更機能に期待したいです。
また実際に使うとなると、テストの実行時間を保持するファイルをストレージに保存する必要があるので、少し CI が複雑になります。README の example では GitHub Actions の cache を使う例を紹介しています。
この点については、解決できる課題の深刻さとのトレードオフになるので、状況に合わせて導入するのが良いと思います。
-
筆者が以前所属していたプロジェクトでは E2E テストを 10 分割して実行していましたが、shard ごとの実行時間は 5 〜 7 分になっていました。 ↩︎

Discussion