こんにちは。COTENのbondです。最近は中国茶、特に鉄観音茶をよく飲んでいます。このところ凄まじく暑いので、水出しがオススメです。
この記事では、現在開発中の歴史データCompoundについて、技術的な視点で書いてみます。もう少し一般的な視点で書かれた記事もあるので、そちらも合わせて読んでもらえるとよいかもしれません。
歴史データのCompoundとは
COTENは世界史データベースを開発しています。
詳しい説明は上記の記事に譲りますが、ここでは歴史上の人物や出来事がたくさん保存されているデータベースである、くらいに理解してもらえれば十分です。
さて、世界史データには特有の難しさがあります。
例えば、
- 複数の名前が同一人物を指すことがある(例:豊臣秀吉・羽柴秀吉)
- 同じ出来事でも表現が異なる(例:A国がB国を滅ぼした・B国は滅びた)
などなど
COTENの世界史データベースは書籍をもとに入力されており、その時点のデータは上記のような、そのままでは活用しにくい状態です。
そこで、こういったデータを複合(Compound)する必要があります。
例えば人物の場合、同じ人物を指している名前は1つにまとめます:
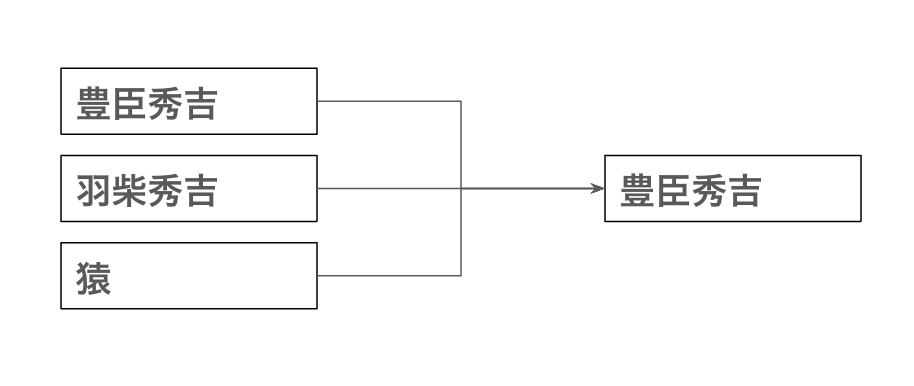
こうしてCompundされたものが、最終的な世界史データベースのデータとして公開されます。
Compoundの流れ
Compundの流れについて紹介します。
とはいっても、まだ開発中の機能で流動的なため、フワッとした表現になります(ごめんなさい
歴史データのCompoundは、下記のような流れです。
- 書籍や論文などの資料情報をもとにEvidenceデータを入力
- Evidenceを加工・整形して、Recordデータを作成
- Record同士を比較してマッピングデータを作成(Composerと呼んでいます
- ComposerをもとにRecordをCompundしたデータを作成(Compound Recordと呼んでいます
1の時点のRecordは、書籍から抜き出した、重複や表記揺れのあるデータです。
COTENではデータ入力ボランティア(Chambers)のみなさんの協力で行なっています(いつもありがとうございます🙏
次に、このRecord同士を比較して同一のものを特定するステップがあります。
比較すると言うと単純そうですが、件数が多いのが難しいところです。
一定数をサンプリングしてData Manager(DM)が判断して、独自で検討したプロンプトを元にある程度はLLMに自動判定させるなどオペレーションを検討中です。
(アイデアある方、お話ししましょう
いろいろあってComposerが出来たら、それをもとにCompound Recordが作成されます。

もうちょっと詳しいCompundの流れ
Composer作成後の流れはある程度固まっているので、もう少し詳細に紹介します。
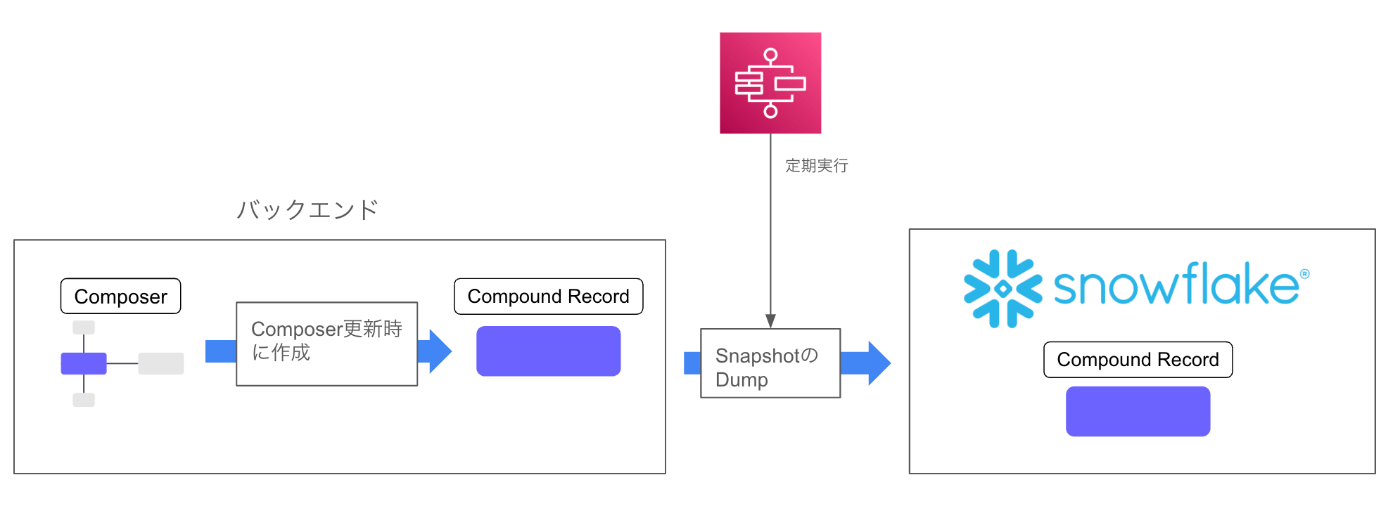
いろいろあって作成されたComposerは、世界史データベースのバックエンドDBに保存されます。
このComposerは日次でSnapshotを取って、Snowflakeへ保存しています。
SnowflakeのComposerをもとに、Compound Recordを日次で作成します。
ここでは下記の観点から、DBTを使用しています。
- データの件数が多くなる見込み
- 作成フローが何段階かあり、複雑
- 一度に更新される件数は限られるので、増分更新したい

Snowflakeを採用しているのは、世界史データベースの公開後Compound Recordが利用される際に、COTENのバックエンドサービスへ直接依存されるのを避けたい意図があります。
これから大工事します
さて、ここまで紹介してきたCompund機能ですが、これから大幅に手が加えられます。
主な変更点は、Compound Record生成を実行する場所です。
これまでSnowflake上で実行されていたCompound Record生成を、COTENのバックエンドサービスで実行するようにします。
背景
Composerの作成ロジックは絶賛改善中で、頻繁な検証が必要です。
しかし前述した背景で、Compound Recordの作成はバックエンドDBにあるComposerをもとに、Snowflakeで行なっています。
そのためデータ転送や表示に時間がかかり、全体的なアーキテクチャも複雑になっていました。
また、ComposerのSnowflakeへの送信は、その他のテーブルのバックアップとまとめて実行されていたため、バックアップを上書きしてしまう問題もありました。
そこで、Compound Recordをバックエンドに持たせて、Composerが更新される際に、関連するCompound Recordを作成する方針にしました。
こうすることでCompound Record作成の結果がすぐに確認できるようになり、ロジックの検証が高頻度で出来るようになります。
加えて、Snowflakeは外部公開用としてバックエンドサービスと責務が明確に分かれ、開発もやりやすくなります。
変更の経緯
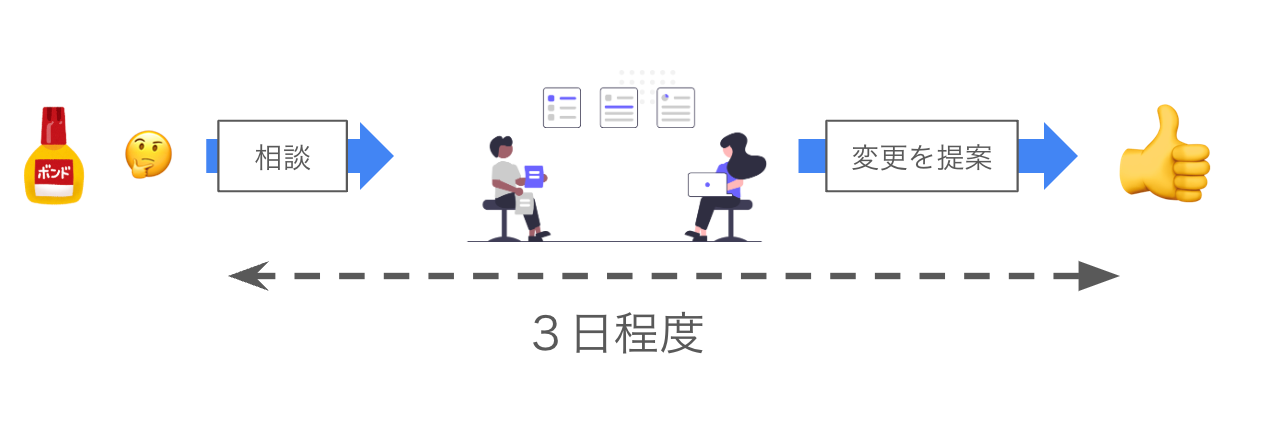
Compound機能は僕が担当しており、当初は既存の構成のまま、Compound Recordの作成を手動で実行できるようにしようとしていました。
しかし前述の問題に当たり、行き詰まりました。
そこで、チームメンバー数人に相談し、Github上のPRやオンラインmtgでディスカッションを行い、上記の変更を行うことを決めました。
同期・非同期のコミュニケーションをうまく活用し、短期間で今回のような大幅な方針転換を行いました。
これほどボトムアップでスピード感のある開発現場である、というのは、外からはあまり見えていないところかも知れませんね。
最後に
世界史データベースチームでは、メンバーが関心のあるプロジェクトに複数所属しながら、研究・開発・実装を進めています。
Compound Rcordプロジェクトに関しては、以下3名で進めています。
エンジニア:設計から実装まで全て担当
データマネージャー:同一判定をするルールを設計
プロジェクトマネージャー:エンジニアとデータマネージャーのサポートやテスト実行など
歴史データは複雑で、本プロジェクトのように様々な検討事項があります。
エンジニアも書かれた絵を実装するのではなく、データマネージャー・プロジェクトマネージャーと一緒に悩みながら作っていける面白さがあると思っています(本プロジェクトも同様です。)世界史データベース開発に一緒に挑戦するエンジニアを募集していますので、関心のある方はぜひお声がけください!
世界史データベースとは
COTEN採用情報

Discussion