こんにちは、COTENの島袋です。
世界史データベースチームでプロジェクトマネージャーをしています。
今回は、世界史データベースを作るうえで欠かせない「歴史データの同定・複合」というテーマについて、社内での試行錯誤を共有します。
世界史データベースとは?
COTEN は「人文知と社会の架け橋になる」ことを目指している会社です。
その中で、まだリリースはしていませんが、世界史データベースというプロダクトを作っています。
世界史データベースチームは以下2つを目指して活動しています。
- 歴史的事実の信頼性の高いデータを提供すること
- 歴史的事実の信頼性の高いデータを活用し、社会に対する新たなインサイトを得られるようなプロダクトを構築すること
2点目のプロダクトにフォーカスすると、主に以下2つのプロダクトを開発しています。
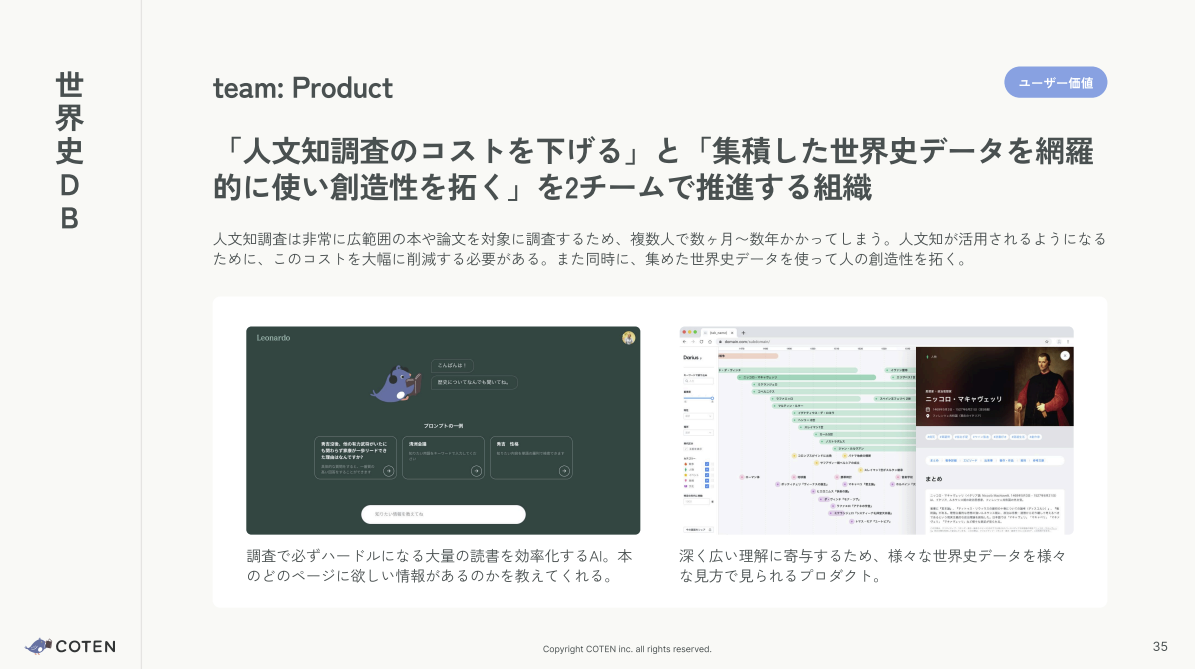
今回テーマとしている「歴史データの同定・複合」は、特に世界史データを様々な見方で見られるプロダクトに影響する活動です。
歴史データの同定・複合とは?
歴史データの同定・複合が必要な背景
COTENでは、信頼性の高い書籍から歴史の事実情報を収集しています。
その際に、例えば、書籍Aに載っている「織田信長」と書籍Bに載っている「織田信長」を別々のデータとして収集するといった場合があります。
プロダクトにおいて、同一人物が複数いると見づらくなりますし、データサイエンス領域で世界史データを分析する際にも、重複が省かれていないとデータを扱いづらいですよね。

タイムラインで歴史的な出来事や人物を総覧できるview。織田信長が2人いると見づらい…
もちろん、書籍Aに歴史上有名な織田信長は1人しかいません、とは書いていないので、なんらかの基準を設けて同一人物である判定(同定)をしなければなりません。
この同一判定と、判定されたデータを複合することを、同定・複合(Compound)と呼んでいます。
この同一判定基準の設計において、歴史のデータは悩ましい点が多いのです…。
歴史データの同定の難しさ
様々なパターンがありますが、主に以下のように、Name・Dateだけでは同定が難しいパターンがあります。
-
同名でも別人のパターン
- 祖父、父、子が全員同じ名前
- 「皇太子シャルル」といっても年代によって人物が違う(ex.コテンラジオこのシャルル、どのシャルル?回)
-
読み方の違いや別名が多くあるパターン
- 幼名、賦与された名前、民衆から呼ばれた名前など複数ある
- 日本語に翻訳する際に呼び方が複数ある
また、上記までは人物の同定について示しましたが、歴史データで特に同定が難しいものは「出来事」のデータだと考えています。
書籍によって書き方が全く異なるので、ルール設定がより難しくなります。
例えば・・・
- 「本能寺の変(1582)」と、「織田信長が明智光秀に暗殺された(1582)」は複合すべきか
- 「本能寺の変(1582)」と、「山崎の戦い(1582)」は複合すべきか
上記のようなパターンを踏まえて、Name・Date以外で同定する方法を構築する必要がありました。
COTENで実装している歴史データの同定・複合プロセス
上記で示した背景を踏まえ、現在は歴史データにおける「出来事以外のデータ」と「出来事のデータ」の2つに分けて、それぞれ同定・複合のプロセスおよびツールを構築しています。
出来事以外のデータ
Entityに対してWikidataIDを付与することで、同定しています。
wikiのAPIはある程度の表記ゆれは既に想定されており、redirectして情報が取得可能です。
GASでwikiAPIを組み込んで、wikidataIDを取得しやすい環境を作っています。
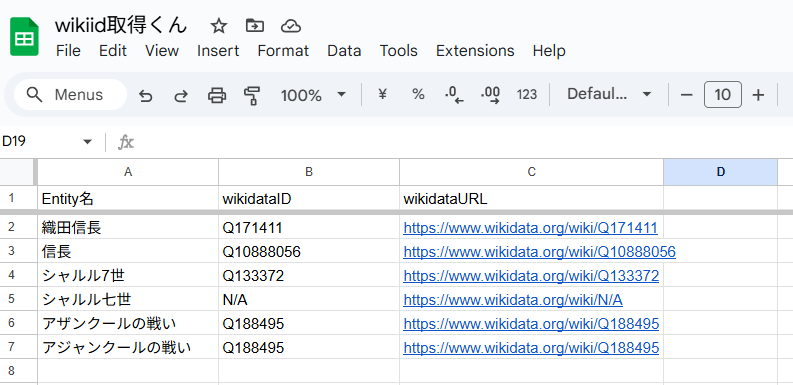
名前を入れれば、自動でwikidataIDとwikidataURLを付与する
出来事のデータ:同一候補を出力するアルゴリズム
出来事のデータは粒度が様々でwikidataIDを付与することが難しいため、まずは既にある歴史の出来事データから同一の可能性が高い候補を出力するアルゴリズム設計を行いました。
アルゴリズム設計やツールへの落とし込みに関しては、既にCOTENはご退職されていますが、AIエンジニアの宮崎さんが構築してくださいました!ありがとうございます!
(宮崎さんについて:X・LinkedIn・ 宮崎さんが運営されている歴史×人事をテーマにしたBlog)

出来事データの同一候補出力のアーキテクチャ
アルゴリズムは、以下3つのスコア集計によって成り立っています。
1. ユリウス通日の重複率
Entityが持つ、DateとendDateの前後にバッファを加えた上で、重なり度合を計算する。
2. 地域の同一性
Entityが持つ地名が一致するかどうかをみる。
地域名がない場合、イベント内に記載のある人物名から地域が判断できる場合は補う。
それでも地名が空欄の場合は、あらかじめ学習しておいた機械学習モデルを使って地域名を補う。
3. ベクトル空間の類似度
EntityのNameをベクトル空間に射影したときのコサイン類似度。
Nameの文字数が少ない場合は、Entityに紐づくRelation情報から文字列を追加したうえで、ベクトル値を取る。
2の機械学習にはメタモデル方式を採用し、Support Vector Machine、XGBoost、Multi-layer Perceptronの3つのモデルがそれぞれ別々に予測した地域名をインプットに、Random Forestが最終的な予測を行います。

上記アルゴリズムで出した候補をスプレッドシートで出力
歴史の出来事データ:LLMによる同一候補の1次判定
候補を出力した後は、世界史データベースチームでプロトタイプ実装したLLMアプリケーション「Leonarodo」に渡し、同一かどうかの1次判定を行っています。

出力結果の例。結果はスプレッドシートにAPIで組み込まれる
Leonardoに5回判定してもらい、多数決で同一と判定された候補一覧をもとに、世界史データベースチームのデータマネージャーがルールに則って確認・承認を行うというフローを取っています。
同定・複合プロセスにおける課題
上記のプロセスにおいて課題だと捉えている部分を書き残します。
詳細の情報を開示できていませんが、何か知見をお持ちの方がいれば、コメントなどいただければと思います。
wikidataIDでの同定・複合においては、以下のような課題が存在します。
- 有名な人物の場合、wikidataが複数ある場合がある
- wikipediaがない場合に同定が難しい
- 「信長」のような曖昧な名称の場合、歴史的人物ではないwikidataIDが付与される場合がある
- 「シャルル七世」のような漢数字の場合は、自動でWikidataIDの取得が難しい
上記のため、人手による確認やwikidataID付与の作業が必要で、現状も多くの作業工数がかかっています。
出来事データの同定・複合に関しては、以下のような課題が存在します。
- 出力されている候補が「出来事なのか」もLLMアプリケーション「Leonardo」で1次判定しているが、85%程度の精度であり、精度を高めたい(世界史データベースチームでは遅塚忠躬先生の『史学概論』を参考に設計したモデルをもとに出来事というカテゴリに分類できるかどうかを判断しています)
最後に
世界史データベースチームでは、メンバーが関心のあるプロジェクトに複数所属しながら、研究・開発・実装を進めています。
データを同定・複合のプロジェクトに関しては、以下3名で進めています。
- エンジニア:設計から実装まで全て担当
- データマネージャー:同一判定をするルールを設計
- プロジェクトマネージャー:エンジニアとデータマネージャーのサポートやテスト実行など
歴史データは複雑で、本プロジェクトのように様々な検討事項があります。
エンジニアも書かれた絵を実装するのではなく、データマネージャー・プロジェクトマネージャーと一緒に悩みながら作っていける面白さがあると思っています(本プロジェクトも同様です。)世界史データベース開発に一緒に挑戦するエンジニアを募集していますので、関心のある方はぜひお声がけください!
-
世界史データベースとは
https://coten.co.jp/services/historydatabase/ -
COTEN採用情報
https://coten.co.jp/career/

Discussion