Database Migration Service で PostgreSQL を移行してみる
どうもこんにちは
クラウドエースの SRE チームに所属している妹尾です。
今回は Database Migration Service の紹介と、
実際に PostgreSQL を Cloud SQL へ移行する手順も書いていきます。
Database Migration Service とは
任意のデータベースから Google Cloud 内のデータベースサービスへ移行する際に使えるレプリケーション構成ツールです。
オンプレミスの MySQL、PostgreSQL を Cloud SQL へ移行する事はもちろん、
ソースのデータベースとして Amazon Web Services の RDS や Aurora を指定できる他、
PostgreSQL であれば移行先に AlloyDB が指定できます。
そして何よりも特徴的なのが ORACLE から PostgreSQL への移行が可能な事です。
スキーマの変換が必要ですが、AI が補助することで簡単に移行できるようになっています。
こちらについては詳細な記事を後日公開予定なのでお楽しみに……
利用方法
利用はコンソールの左にあるナビゲーションメニューのデータベースから選択するか、
移行先の各マネージドデータベースサービスからでも遷移できます。


メリットと注意点
メリット
様々な環境に適応できる
MySQL、PostgreSQLをベースにした様々なデータベースを移行対象にできます。
特に、AWS Aurora や Oracle データベースから移行できる事は特筆すべき特徴ですね。
数秒で切り替え可能な状態にできる
継続的レプリケーションに対応しており、構成はバックグラウンドで行った後に別タイミングで切り替えを行うことでサービスダウンの時間が非常に短く収める事が可能です。
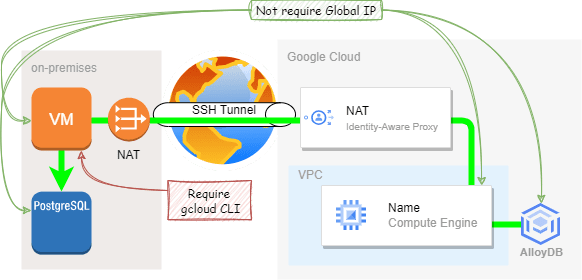
グローバルIPアドレスが不要
個人的に一番オイシイと感じるメリットです。
リバース SSH トンネル踏み台をした接続形式であれば、 Google Cloud 側、オンプレミス側双方にグローバルアドレスが不要 です。
Google Cloud 側はインターネットに出れる状態であること、オンプレミス側は 作業用 VM から gcloud コマンドが正常に叩ければ OK 。
特にオンプレミスに設置されたデータベースサーバーは機密性が高く、迂闊に外部との通信ができるように構成できません。
そこを NAT の裏側に隠しながら移行できるのは、大きなメリットになります。
注意点
PostgreSQLの拡張機能を使っていると移行できないケースが多い
MySQLもそうですが、拡張機能を利用している場合は素直に移行ができずに移行に失敗してしまうケースが多々あります。
特に PostgreSQL は拡張機能のために採用するケースもあるため注意が必要です。
データ量が多いと同期に時間がかかる
一般的な話ですが、データ量が多いとそのぶん同期に時間がかかります。
特にリバースSSHトンネル形式は WAN を経由しますから、データセンターのアウトバンドトラフィックも消費します。
スイッチでQoSを構成するなどの工夫が必要になり、その影響でレプリケーションが追い付かない場合は Google Cloud との専用線契約も視野に入れて対策が必要となります。
現時点ではSpannerには非対応
残念ながら、現時点で Google Cloud の誇る最大規模のデータベースである Spanner への移行はできません。
現時点では Cloud SQL と、 AlloyDB にのみ展開できるので、 Spanner への移行は手動で Dataflow を組む等の工夫が必要です。
構築例
ここからは、実際にレプリケーションを組む手順を紹介していきます。
1. 開始
まずは名前と移行元と移行先の DB を選択します。
今回はローカルに構築した PostgreSQL を Cloud SQL へ移行していきます。

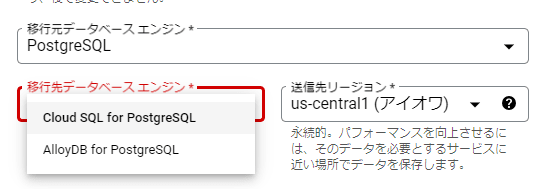
このステップで「1回限り」を選択すれば、構成したタイミングの DB のコピーのみ行うモードになります。

2. ソースの定義
次にソース DB の定義です。
ソース DB の設定は「接続プロファイル」として保存されます。
名前とIDは適当に決めて、ソース DB の IP 、ポート、ユーザ名とパスワードを記録します。
IP アドレスは、VPC ピアリング等で直接接続している場合は VPC に繋がっている IP アドレスを
リバース SSH コネクタを利用する場合は、作業用マシンからソース DB へ接続できる IP アドレスを指定します。
DB で SSL/TLS 暗号化接続を必須にしている場合はここで設定しましょう。
またユーザはレプリケーション専用のものがあると良いですね。

3. 移行先の構築
次は移行先 DB です。
Cloud SQL、AlloyDB どちらもこの画面でインスタンスを構築します。
Cloud Console を使った通常の構築と何ら変わりませんので、詳細は割愛します。
なお、リージョン等の情報は前ステップの情報を元に固定されています。

4. 接続方法の定義
次は接続方法です。
3つあり、それぞれ以下のような構成で通信します。
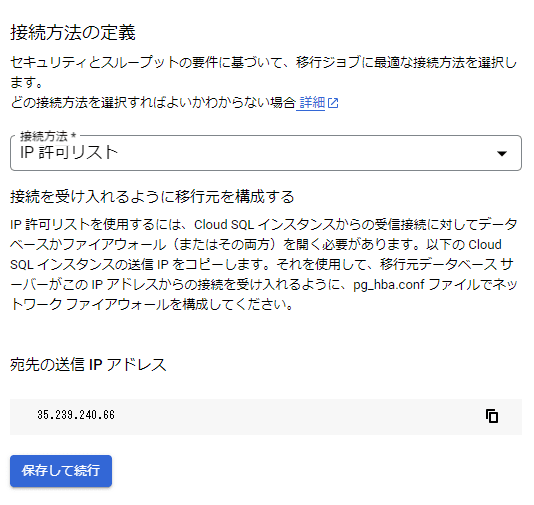
- IP 許可リスト
グローバルなネットワークとIPを介して通信します。
選択したら Cloud SQL の外部IPが出てきますから、その IP からの通信を許可するようにソースを設定します。
- VPC ピアリング
移行元が既に VPC を通じて疎通できる場合はこちらになります。
移行元 DB がある VPC を指定するだけでOK。

- クラウドでホストされている VM を経由したリバース SSH トンネル
移行先、移行元共にグローバルアドレスが不要な構成です。

GCEVM をこの画面で作成し、ソース DB と接続できる作業用マシンから指定されるスクリプトをコピペして実行します。
なおこのスクリプトはレプリケーションが終わるまでずっと実行されますので、バックグラウンドで実行しておく必要がありそうです。

最後に GCPVM の内部 IP アドレスを入力すれば完了です。

5. テストと接続
仕上げに構成を確認して、問題なければジョブのテストを行います。
FW 等に阻まれて疎通できない場合や、レプリケーションに必要な権限がない場合はここでわかりますので修正しましょう。
ただし、一部のテーブルだけ権限が無い場合など、検知できない部分もあるようですので注意が必要です。

問題なくテストが通ったらジョブを作成します。
ジョブを作成した時点ではレプリケーションは始まりません、開始するには「開始」をする必要があるので注意しましょう。
逆に、構成がわかった時点でジョブを作成しておき、レプリケーション開始は別のタイミングで開始させる事で、レプリケーション当日のオペレーションを減らす事もできそうです。
6. 切り替え
レプリケーションが構成、開始されたらデータ更新が追い付くまで待って、必要な告知を済ませてから切り替えを行います。
切り替える手法やアプリケーションの形式によりますが、最速であればサービスダウンはこの間の数十秒だけで済みます。
まとめ
以上、Database Migration Service を使ったデータベースの移行についてでした。
クラウド化においてデータベースの移行はよく難題となってしまいますが、この機能を利用する事でその難易度を大幅に減らす事ができます。
頻繁に移行作業は発生しませんが、その機会には積極的に検討をしていきたい機能ですね!
Discussion