BigQuery DataFrames と Vertex AI Pipelines による機械学習パイプライン構築
はじめに
こんにちは、クラウドエース データソリューション部の松本です。
普段は、データ基盤や MLOps を構築したり、Google Cloud 認定トレーナーとしてトレーニングを提供しております。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回は、BigQuery DataFrames と Vertex AI Pipelines による機械学習パイプライン構築方法について、ご紹介いたします。
この記事はこんな人にオススメ
- 機械学習パイプラインにおける実行基盤を検討されている方
- BigQuery DataFrames に関するユースケースや実装方法を知りたい方
- Vertex AI Pipelines(Kubeflow Pipelines v2)の実装方法を知りたい方
BigQuery DataFrames とは
BigQuery DataFrames とは、BigQuery 上のデータを Pandas や scikit-learn ライクな Python コードによって処理することができるクライアント ライブラリです。
BigQuery DataFrames は、以下の機能を提供します。
- bigframes.pandas:pandas のような API によりBigQuery 上での処理が可能
- bigframes.ml:scikit-learn のような API によりBigQuery ML 上での処理が可能
Pandas ライクな機能を提供する bigframes.pandas については、以下の記事が参考になります。
なお、この記事の中では、下図を用いて一般的な Pandas と bigframes.pandas の違いが紹介されており、bigframes.pandas の特徴として以下が説明されています。(この特徴は bigframes.ml においても同様になります。)
bigframes.pandas のコードを実行すると、BigQuery に「セッション」が作成され、セッション内の一時テーブルを使用してデータを処理します。
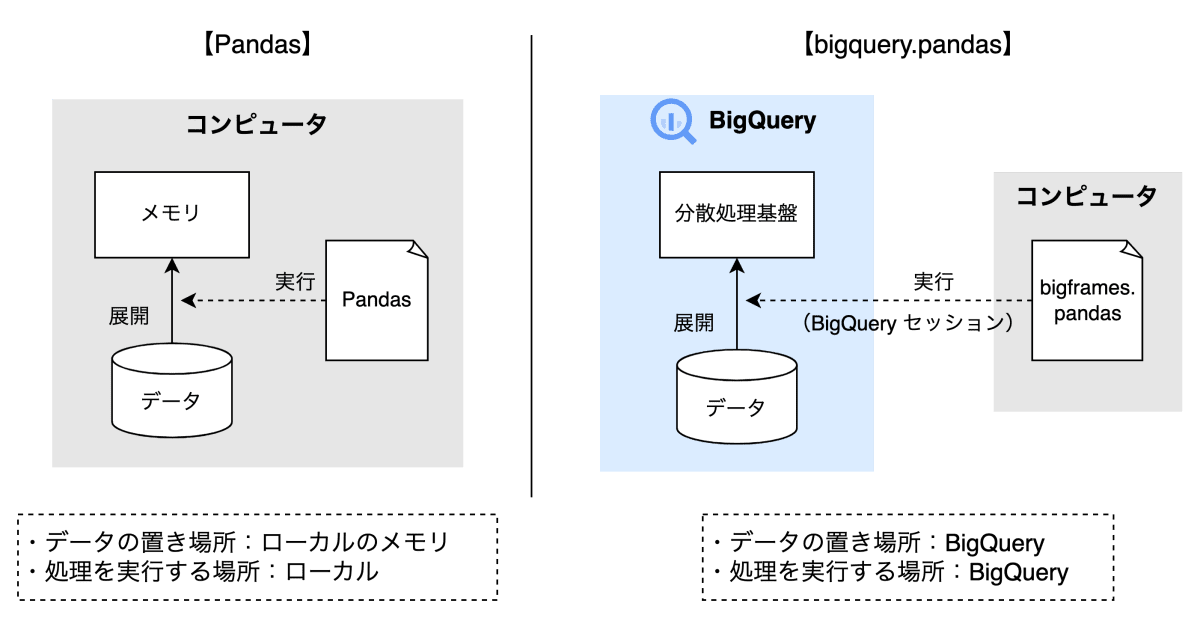
Pandas と bigframes.pandas の違い
Vertex AI Pipelines とは
Vertex AI Pipelines とは、Kubeflow Pipelines SDK や TensorFlow Extended(TFX)を用いて、Google Cloud 上でサーバレスにパイプラインを構築することができるサービスです。
利点
Vertex AI Pipelines の主な利点としては以下が挙げられ、機械学習パイプラインの構築に適したサービスになります。
- サーバーレスであるため、インフラの設定不要で大規模な処理が可能
- BigQuery や 他 Vertex AI サービス などの Google Cloud サービスと簡単に統合可能
- Vertex ML Metadata を使用してアーティファクトに関するメタデータの追跡が可能
使用するパイプライン SDK の選び方
Kubeflow Pipelines SDK と TFX のユースケースに関しては、Google Cloud 公式ドキュメント にて以下が示されています。
- TensorFlow Extended(TFX):テラバイト単位の構造化データまたはテキストデータを処理する ML ワークフローで TensorFlow を使用する場合の使用が推奨されています。
- Kubeflow Pipelines SDK:上記以外のユースケースにおけるパイプライン構築での使用が推奨されています。
本記事では、多くのケースで選択される Kubeflow Pipelines SDK を中心に扱っていきます。
Kubeflow Pipelines v2 について
Kubeflow Pipelines は 2023 年 7 月に Version 2.0.0 がリリースされ、Vertex AI Pipelines でもサポートされています。一方で Vertex AI Pipelinesにおける KFP SDK 1.8 系は、2024 年 12 月にサポート終了します。そのため、今後は KFP SDK 2 系を利用していく必要があります。
Kubeflow Pipelines は 前処理や訓練などの単位でコンテナにまとめて実装します。この処理単位をコンポーネントと呼びますが、KFP SDK 2 系 ではコンポーネントの実装方法として以下が用意されています。
-
Lightweight Python Components:
コンポーネントの作成が最も簡単な方法であり、コードの記述量が少ないことが特徴です。ただし、コンポーネントとパイプラインを分離したコードの記述が困難です。 -
Containerized Python Components:
コードの記述量が Lightweight Python Components からやや増える代わりに、コンポーネントとパイプラインを分離したコードの記述が可能です。ただし、コンテナイメージのビルドに KFP SDK が必要になります。 -
Container Components:
任意のコンテナイメージを準備することができ、言語や実行環境に依存しない汎用的なタスク実行が可能です。ただし、コード記述量が多くなりがちで、ML Metadata のアーティファクトに関する機能の制約があります。
これらコンポーネントの実装方法の違いに関しては、以下の記事でまとまられており非常に参考になります。
BigQuery DataFrames を機械学習パイプラインで利用するメリット
BigQuery DataFrames を機械学習パイプラインで利用するメリットとして以下が挙げられます。
メリット1:Pandas や scikit-learn コードからの移植コストを抑えられる
私も経験があるのですが、データサイエンティストなどが Notebook 上で記述した Pandas や scikit-learn コードを Dataflow(Apache Beam)や Dataproc(Hadoop, Spark)、BigQuery(SQL)などの分散処理基盤に載せ替える必要がある場合に移植コストが高くなりがちです。BigQuery Dataframes では 既存の Pandas コードをほぼ書き換えることなく移植可能であるため、このような移植コストを抑えることができます。
メリット2:複雑な処理ロジックを記述できる
BigQuery の SQL を利用した場合、機械学習における複雑なロジックを記述することが難しく、仮に実装できても可読性が悪いなどで保守性が低下するデメリットがあります。BigQuery Dataframes では、Python ベースのライブラである Pandas や scikit-learn を使用することで、そういった課題が解消できる可能性が高いです。
メリット3:BigQuery 自体の利点を活かせる
機械学習タスクにおいては大規模なデータを扱うことが多いため、やはり BigQuery 自体の利点であるスケーラビリティをフルマネージドかつサーバレスで活用できることはメリットになります。また、BigQuery Dataframes では BigQuery ML を利用できるため、BigQuery のデータを移動することなく、機械学習モデルを構築できることもメリットになります。
使用上の注意点
上記のようなメリットはありますが、以下のような使用上の注意点があります。
-
課金額に気をつける必要がある:
BigQuery Dataframes を使用すると、いくつかの処理を行う際に内部的に一時テーブルが適宜作成され、その一時テーブルを後続の処理でスキャンします。この一時テーブルのスキャンが不必要に多くなると、スキャン量に応じて課金が発生する オンデマンド料金 では課金額が高くなる可能性があります。そのため、使用したリソース(スロット数)に応じて課金される BigQuery エディション に、必要に応じて切り替えておくのが良いでしょう。 -
内部でのSQL 自動生成によりパフォーマンスが最適でない場合がある:
BigQuery Dataframes を使用すると、Python コードの内容をもとに内部的に SQL が自動生成されます。この自動生成された SQL がパフォーマンス最適化されていないことがあります。
機械学習パイプラインのアーキテクチャ
BigQuery DataFrames と Vertex AI Pipelines による機械学習パイプラインのアーキテクチャは以下の通りです。

BigQuery DataFrames と Vertex AI Pipelines による機械学習パイプラインのアーキテクチャ
訓練パイプライン
-
前処理:
bigframes.pandas により前処理を行います。DataFrame の操作は こちら に記載されているものが使用でき、基本的には pandas と同様の記述方法になります。また、ラベルエンコーディングやワンホットエンコーディングなどは、bigframes.ml の LabelEncoder や OneHotEncoder などの preprocessing 機能 を使用することも可能です。 -
訓練:
bigframes.ml により訓練を行います。bigframes.ml は BigQuery ML の機能によって処理するため、使用できるモデルは BigQuery ML で サポートされているモデル になります。例えば RandomForestClassifier(クラス分類)であれば、sckit-lean と同様に fit 関数 を使用してモデル構築を行います。モデル訓練のインプットになるデータの分割は、train_test_split 関数 によって処理可能です。また、訓練済みモデルは to_gbq 関数 により BigQuery のデータセットにモデル登録できます。 -
評価:
bigframes.ml により評価を行います。評価指標の算出は、score 関数 により作成したモデルに応じた指標を算出することができます。また metrics 機能 により、例えば accuracy_score 関数 を使用して正解率の指標のみを算出するなども可能です。 -
モデル管理:
bigframes.ml の register 関数 により、訓練したモデルを Vertex AI Model Registory に登録し、モデル管理することが可能です。
予測パイプライン
-
前処理:
予測パイプラインにおける前処理は、訓練パイプラインと同様に bigframes.pandas や 一部 bigframes.ml を用いて処理します。 -
予測:
BigQuery ML に常に存在する訓練済みモデルを使って予測をする場合、bigframes.ml として 各モデルの predict 関数 が用意されています。しかし、モデルをインポートする関数がないため、パイプラインが訓練と予測で切り離されている場合は使用することができません。そのため、予測する際は BigQuery ML の SQL にて ML.PREDICT 関数 を使用するか、Vertex AI Model Registry に保存されているモデルを Vertex AI Endpoints にデプロイし、bigframes.ml の VertexAIModel 機能 を使って、エンドポイントに対してリクエストすることで、予測結果を得る必要があります。
補足
MLOps 構築時はこれら機能に加えて、VerteX AI Feature Store による特徴量管理や Vertex AI Model Monitoring によるモデルモニタリングなどの機能を拡張していくと良いでしょう。
なお、VerteX AI Feature Store については以下の記事を書いていますので、ご興味があればご参考ください。
実装例
今回は Kaggle チュートリアルのタイタニック号生存予測 で提供されているデータを利用して、BigQuery DataFrames と Vertex AI Pipelines による機械学習パイプラインを構築してみましたので、その実装例をご紹介します。
なお、機械学習パイプラインの構築における Vertex AI Pipelines の SDK として Kubeflow Pipelines v2 を使用しました。コンポーネントの実装方法としては、Kubeflow Pipelines のすべての機能を利用可能であり、コンポーネントとパイプラインの分離が可能な Containerized Python Components を選択しています。
ディレクトリ構成
今回は、Containerized Python Components のドキュメントで紹介されている内容に準拠し、以下のディレクトリ構成としました。
.
├── components
│ ├── predict
│ │ ├── Dockerfile
│ │ ├── __init__.py
│ │ ├── component_metadata
│ │ │ └── predict.yaml
│ │ ├── kfp_config.ini
│ │ ├── predict.py
│ │ └── runtime-requirements.txt
│ ├── preprocess
│ │ ├── Dockerfile
│ │ ├── __init__.py
│ │ ├── component_metadata
│ │ │ └── preprocess.yaml
│ │ ├── kfp_config.ini
│ │ ├── preprocess.py
│ │ └── runtime-requirements.txt
│ └── train
│ ├── Dockerfile
│ ├── __init__.py
│ ├── component_metadata
│ │ └── train.yaml
│ ├── kfp_config.ini
│ ├── runtime-requirements.txt
│ └── train.py
├── prediction_pipeline.py
├── prediction_pipeline.yaml
├── training_pipeline.py
└── training_pipeline.yaml
Components ディレクトリ配下では、各コンポーネントごとのディレクトリを切ることで、依存関係の独立性を持たせています。
各コンポーネントの処理コード(preprocess.py, train.py, predict.py)を作成した後、kfp component build によりコンパイルを行います。例として、preprocess.py のコンパイルを行う場合、以下のコマンドを実行します。
kfp component build ./components/preprocess/ --component-filepattern preprocess.py --no-push-image
コンパイルすると preprocess.yaml のような yaml ファイルが生成されます。これは、このコンポーネントのみで構成されるパイプライン定義であり、Vertex AI Pipelines での パイプライン実行の作成時にインポート することでコンポーネント単位での実行が可能です。
kfp_config.ini はコンポーネントを定義している Python ファイルの情報を保持しています。
[Components]
preprocess = preprocess.py
runtime-requirements.txt では、コンポーネント内で使用するライブラリを含めておく必要があります。
# Generated by KFP.
bigframes
Dockerfile は以下の通りであり、他設定ファイル等をもとにイメージファイルを作成します。
# Generated by KFP.
FROM python:3.10
WORKDIR /preprocess/
COPY runtime-requirements.txt runtime-requirements.txt
RUN pip install --no-cache-dir -r runtime-requirements.txt
RUN pip install --no-cache-dir kfp==2.7.0
COPY . .
訓練パイプライン
構築した訓練パイプラインは以下のようになります。コンポーネントは前処理と訓練で構成されており、訓練コンポーネント内に評価の処理を含んでいます。
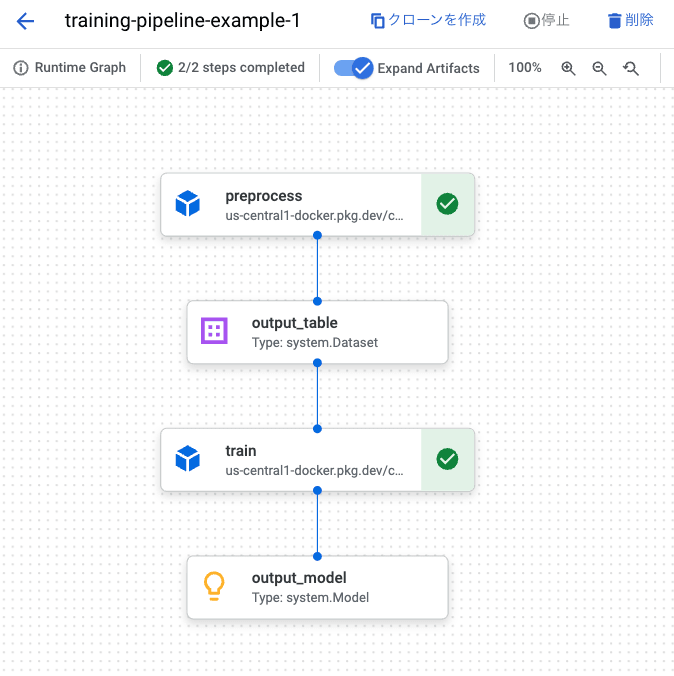
Vertex AI Pipelines 上での訓練パイプラインの実行例
前処理コンポーネント
前処理コンポーネントにおける処理のコードは以下の通りです。
from kfp import dsl
from kfp.dsl import Output, Dataset
import bigframes.pandas as bpd
@dsl.component(
base_image='python:3.10',
packages_to_install=['bigframes'],
target_image='us-central1-docker.pkg.dev/project-id/repositry/preprocess:v1.0.0'
)
def preprocess(
project_id: str,
location: str,
dataset_path: str,
is_train: bool,
output_table: Output[Dataset]
):
"""前処理"""
# BigQuery DataFrames のオプション指定
bpd.options.bigquery.project = project_id
bpd.options.bigquery.location = location
# テーブルパス指定
table_suffix = 'train' if is_train else 'test'
# BigQuery からのデータ取得
df = bpd.read_gbq(f'{dataset_path}.{table_suffix}').set_index('PassengerId')
# 前処理
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Embarked'] = df['Embarked'].fillna('S')
df = bpd.concat([df, bpd.get_dummies(df['Embarked'], prefix='Embarked')], axis=1).drop(columns=['Embarked'])
df['Sex'] = bpd.get_dummies(df['Sex'], drop_first=True)
# BigQuery へのデータ出力
table_path = f'{dataset_path}.feature_{table_suffix}'
df.to_gbq(table_path, if_exists='replace')
# アーティファクト情報登録
output_table.uri = f'bq://{table_path}'
output_table.metadata['table_path'] = table_path
コンポーネント デコレータの引数指定
@dsl.component によりコンポーネントとしての定義が可能になります。
指定した引数は以下の通りです。
-
base_image:Kubeflow Pipelines が新しいコンテナ イメージを構築するときに使用するベース イメージを指定する -
packages_to_install:コンポーネントで必要になるライブラリを指定する -
target_image:Artifact Registry へアップロードしたイメージを指定する
BigQuery DataFrames のオプション指定
BigQuery DataFrames のオプションとして以下を指定することができます。
-
bpd.options.bigquery.project:BigQuery を実行するプロジェクトを指定する -
bpd.options.bigquery.location:BigQuery を実行するロケーションを指定する
bigframes.pandas での処理
BigQuery の入出力は以下の関数を使用します。その他、DataFrame での変換処理部分は pandas と同様になります。
-
read_gbq:BigQuery データを DataFrame 形式で読み込する -
to_gbq:DataFrame のデータを BigQuery に出力する
アーティファクト情報の登録
kfp.dsl により処理の入出力に関するアーティファクトのメタデータを登録することができます。
例えば、コンポーネント引数の output_table のデータ型として Output[Dataset] を定義すると、出力のデータセットのメタデータを登録することができます。また、アーティファクト情報を後続の処理に引き渡すことができます。
なお、アーティファクト タイプとしては、Google Cloud 公式ドキュメント に記載されている Vertex AI のアーティファクトが使用可能です。
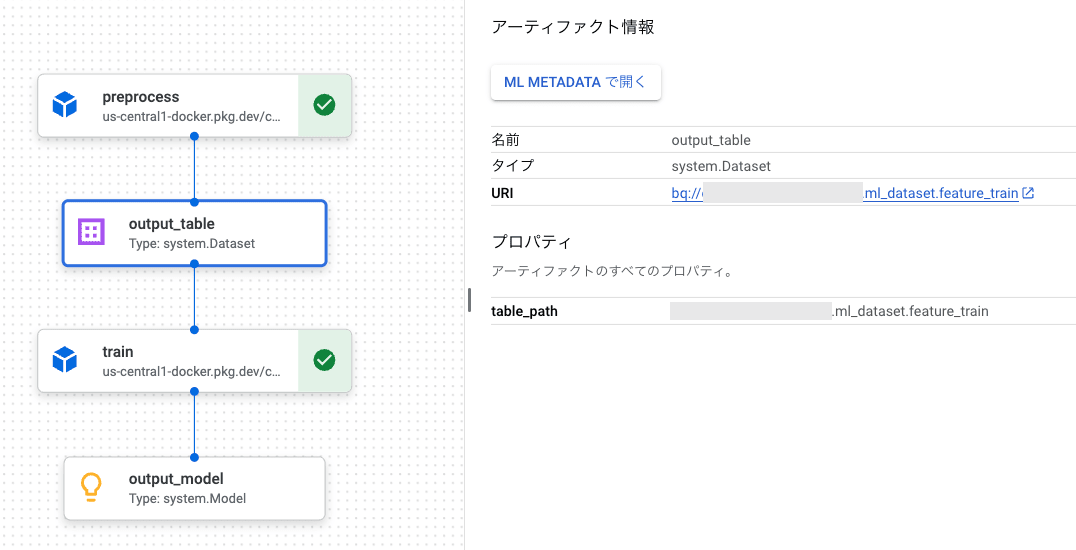
出力データセットのアーティファクト情報
訓練コンポーネント
訓練コンポーネントにおける処理のコードは以下の通りです。
from kfp import dsl
from kfp.dsl import Input, Output, Model, Dataset
import bigframes.pandas as bpd
from bigframes.ml.model_selection import train_test_split
from bigframes.ml.ensemble import RandomForestClassifier
@dsl.component(
base_image='python:3.10',
packages_to_install=['bigframes'],
target_image='us-central1-docker.pkg.dev/project-id/repositry/train:v1.0.0'
)
def train(
project_id: str,
location: str,
dataset_path: str,
input_table: Input[Dataset],
output_model: Output[Model]
):
"""訓練"""
# BigQuery DataFrames のオプション指定
bpd.options.bigquery.project = project_id
bpd.options.bigquery.location = location
# BigQuery からのデータ取得
df = bpd.read_gbq(input_table.metadata.get('table_path')).set_index('PassengerId')
# データ分割
x = df[['Pclass', 'Sex', 'Age', 'Embarked_C', 'Embarked_Q', 'Embarked_S']]
y = df[['Survived']]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=0)
# モデル訓練
model = RandomForestClassifier(enable_global_explain = True)
model.fit(x_train, y_train)
# モデル評価
df_evaluate=model.score(x_test, y_test)
df_evaluate.to_gbq(f'{dataset_path}.evaluate', if_exists='replace')
# モデルの保存
model_path = f'{dataset_path}.model'
model = model.to_gbq(model_path , replace=True)
# モデルレジストリ登録
model.register('bqml-model')
# アーティファクト情報登録
output_model.uri = f'bq://{model_path}'
output_model.metadata['model_path'] = model_path
output_model.metadata['accuracy'] = df_evaluate.at[0, 'accuracy']
output_model.metadata['framework'] = "BigQuery ML: Random Forest Classification"
bigframes.ml での処理
以下の bigframes.ml の関数によって、モデルの訓練や評価を行います。
-
train_test_split:データを訓練用とテスト用のデータに分割する -
RandomForestClassifier:クラス分類のモデルを使用する(引数としてenable_global_explain = Trueを指定すると、各特徴がモデルに対してどれだけ影響しているかを示す機能である Explainable AI を算出できる) -
score:モデルの評価指標を算出する -
to_gbq:モデルを BigQuery のデータセットに保存する -
register:モデルを Vertex AI Model Registry に登録する
上記にて BigQuery に保存されたモデルでは、解釈可能性や評価指標を確認できます。
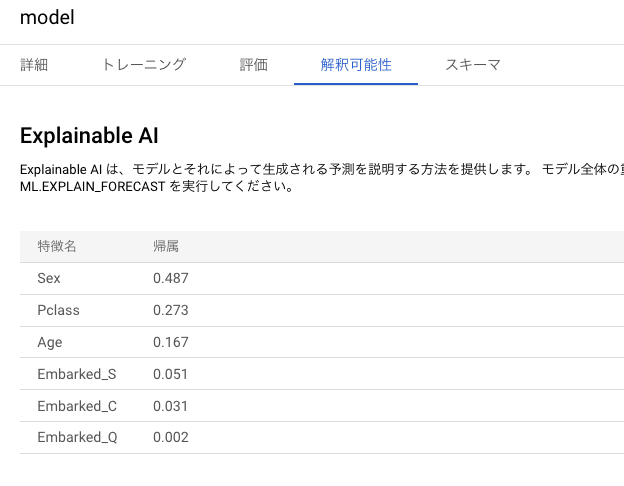
Explainable AI による解釈可能性
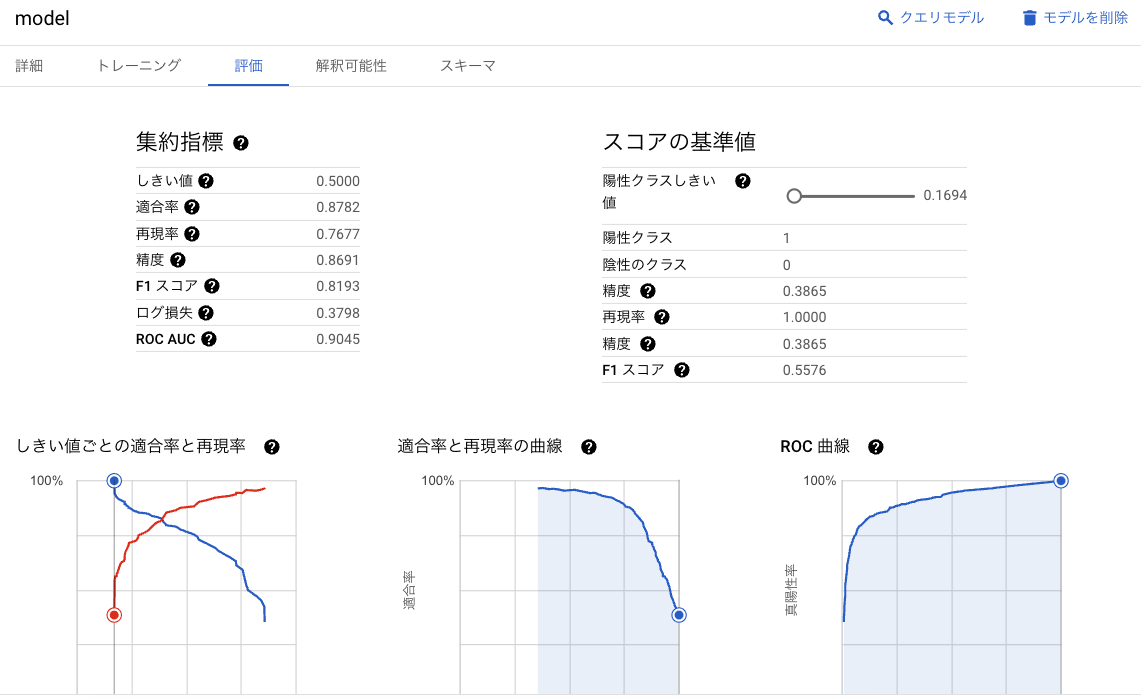
評価指標
また、register により以下のように Vertex AI Model Registry にモデルが登録されています。
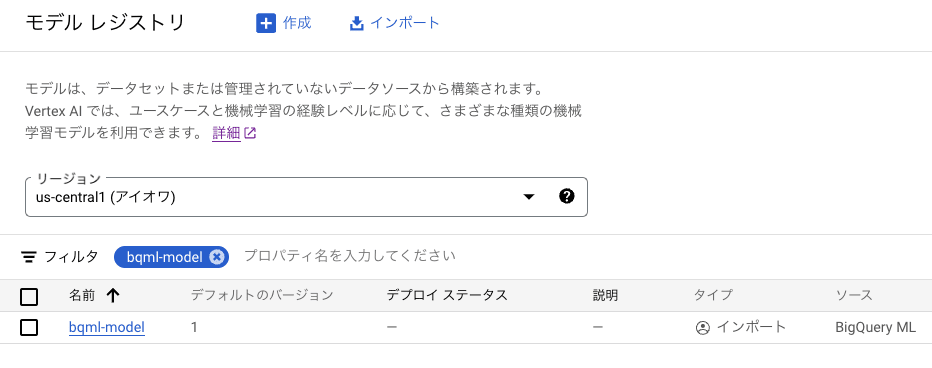
Vertex AI Model Registry に登録されたモデル
訓練パイプライン
訓練パイプラインの定義のコードは以下の通りです。
from kfp import dsl
from components.preprocess.preprocess import preprocess
from components.train.train import train
from kfp import compiler
@dsl.pipeline(
name="training-pipeline",
pipeline_root=f"gs://project-id/kfp/",
)
def pipeline(
project_id: str ="project-id",
location: str ="us-central1",
dataset_path: str ="project-id.dataset"
):
preprocess_component = preprocess(
project_id=project_id,
location=location,
is_train=True,
dataset_path=dataset_path
)
train_component = train(
project_id=project_id,
location=location,
dataset_path=dataset_path,
input_table=preprocess_component.outputs['output_table']
)
compiler.Compiler().compile(pipeline, 'training_pipeline.yaml')
パイプライン デコレータの引数指定
@dsl.pipeline によりパイプラインとしての定義が可能になります。
指定した以下の引数は、パイプライン起動時に設定する項目のデフォルト値になります。
-
name:パイプラインまたはコンポーネントの名前のデフォルト値を指定する -
pipeline_root:出力ディレクトリ(ルート出力ディレクトリとして使用する GCS バケット)のデフォルト値を指定する
各コンポーネントの呼び出し
上記のように preprocess や train のコンポーネントを定義することで、preprocess.py や train.py の処理を実行できます。また、preprocess の出力アーティファクト(上記コードでは preprocess_component.outputs['output_table'])を train のインプットとすることで、処理の依存関係を定義することが可能です。
コンパイラ
Kubeflow Pipelines ではパイプラインを Python で記述した後に、pipeline_spec という中間言語にコンパイルします。コンパイルした際は、yamlファイル(上記コードでは training_pipeline.yaml)が生成され、これを Vertex AI Pipelines の パイプライン実行の作成時にインポート することで、定義したパイプラインの実行が可能です。
予測パイプライン
構築した予測パイプラインは以下のようになります。コンポーネントは前処理と予測で構成されています。
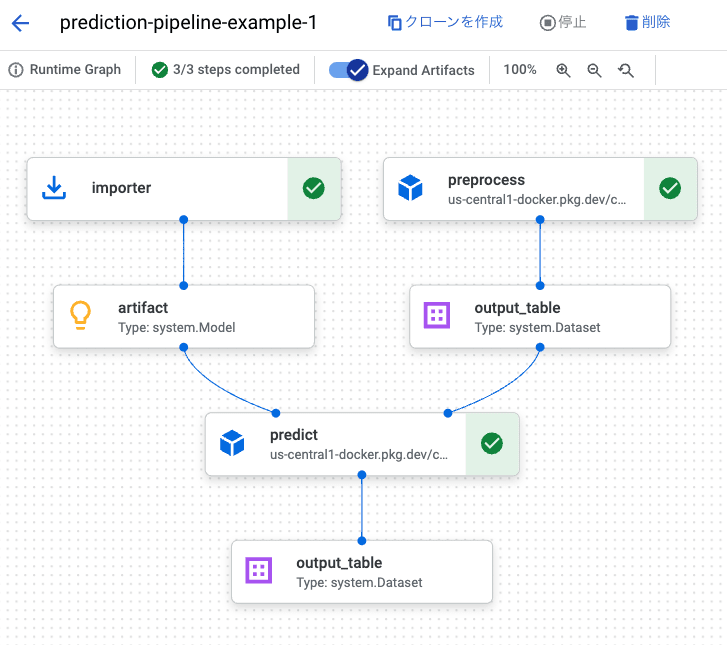
Vertex AI Pipelines 上での予測パイプラインの実行例
前処理コンポーネント
こちらは、訓練パイプラインと同じコードのため割愛します。
予測コンポーネント
予測コンポーネントにおける処理のコードは以下の通りです。
from kfp import dsl
from kfp.dsl import Output, Input, Dataset, Model
from google.cloud import bigquery
@dsl.component(
base_image='python:3.10',
packages_to_install=['bigframes'],
target_image='us-central1-docker.pkg.dev/project-id/repositry/predict:v1.0.0'
)
def predict(
project_id: str,
dataset_path: str,
input_table: Input[Dataset],
input_model: Input[Model],
output_table: Output[Dataset]
):
"""予測処理"""
# クライアント インスタンス生成
client = bigquery.Client(project=project_id)
# 予測クエリ
table_path = f'{dataset_path}.prediction'
query = f"""
CREATE OR REPLACE TABLE
`{table_path}` AS (
SELECT
*
FROM
ML.PREDICT(MODEL `{input_model.metadata.get('model_path')}`,
TABLE `{input_table.metadata.get('table_path')}`))
"""
# BigQuery ジョブ実行
query_job = client.query(query)
# BigQuery ジョブの完了を待つ
query_job.result()
# アーティファクト情報登録
output_table.uri = f'bq://{table_path}'
output_table.metadata['table_path'] = table_path
前述した通り、BigQuery ML に常に存在する訓練済みモデルを使って予測をする場合、モデルをインポートする機能がないため、パイプラインが訓練と予測で切り離されている場合は predict 関数を使用することができません。そのため、予測する際は BigQuery のクライアント ライブラリ を利用して、BigQuery ML の SQL にて ML.PREDICT 関数 を使用して予測の処理を行います。
予測パイプライン
予測パイプラインの定義のコードは以下の通りです。
from kfp import dsl
from components.preprocess.preprocess import preprocess
from components.predict.predict import predict
from kfp import compiler
@dsl.pipeline(
name="prediction-pipeline",
pipeline_root=f"gs://project-id/kfp/",
)
def pipeline(
project_id: str ="project-id",
location: str ="us-central1",
dataset_path: str ="project-id.dataset"
):
importer_model_component = dsl.importer(
artifact_uri='bq://project-id.dataset.model',
artifact_class=dsl.Model,
reimport=False,
metadata={'model_path': 'project-id.dataset.model'}
)
preprocess_component = preprocess(
project_id=project_id,
location=location,
is_train=False,
dataset_path=dataset_path
)
train_component = predict(
project_id=project_id,
dataset_path=dataset_path,
input_table=preprocess_component.outputs['output_table'],
input_model=importer_model_component.output
)
compiler.Compiler().compile(pipeline, 'prediction_pipeline.yaml')
基本的には、訓練パイプラインと同様の記述方法になります。
ただし、予測で使用するモデルに関するアーティファクト情報が必要なため、Importer Components を使用して取得しています。取得したアーティファクトは、後続処理に引き渡して使用することが可能です。
まとめ
今回は、BigQuery DataFrames と Vertex AI Pipelines による機械学習パイプライン構築方法について、ご紹介いたしました。
BigQuery DataFrames を機械学習パイプラインの実行基盤として使用することで、Pandas や scikit-learn コードからの移植コストを抑え、複雑な処理ロジックの実装が容易になり、BigQuery 自体の利点も活かすことができるようになりました。また、Vertex AI Pipelines と組み合わせることで、アーティファクトの管理が可能になり、MLOps に適した実装を行うことができます。
機械学習パイプラインの構築を検討されている方は、BigQuery DataFrames や Vertex AI Pipelines の利用を考えてみると良いかもしれません。
Discussion