BigQuery を Pandas のように操作する
はじめに
こんにちは、クラウドエース Data/ML ディビジョン所属の坂田です。
BigQuery 界隈のみなさん、「BigQuery DataFrames」という Python ライブラリをご存知でしょうか。
BigQuery DataFrames は 2023 年 9 月に登場したライブラリで、BigQuery データを使ってデータ分析を行うことができる、Google 提供のライブラリです。
BigQuery DataFrames は、2 つの機能に分かれています。
-
Pandas ライクな操作・機能を提供する
bigframes.pandas -
scikit-learn ライクな操作・機能を提供する
bigframes.ml
この記事では、bigframes.pandas について、 使い方や 3 ヶ月ほど bigframes.pandas を使ってみた感想について書きます。
bigframes.pandas とは
仕組み
bigframes.pandas は、BigQuery データを Pandas のような操作感で処理・分析できます。
通常の Pandas は、CSV ファイルなどのデータをメモリに展開した上で処理を行います。
一方で、bigframes.pandas は、Python コードはローカル(もしくはクラウド)のコンピュータで実行しますが、データを BigQuery に保持したまま BigQuery 上でデータを処理します。
bigframes.pandas のコードを実行すると、BigQuery に「セッション」が作成され、セッション内の一時テーブルを使用してデータを処理します。
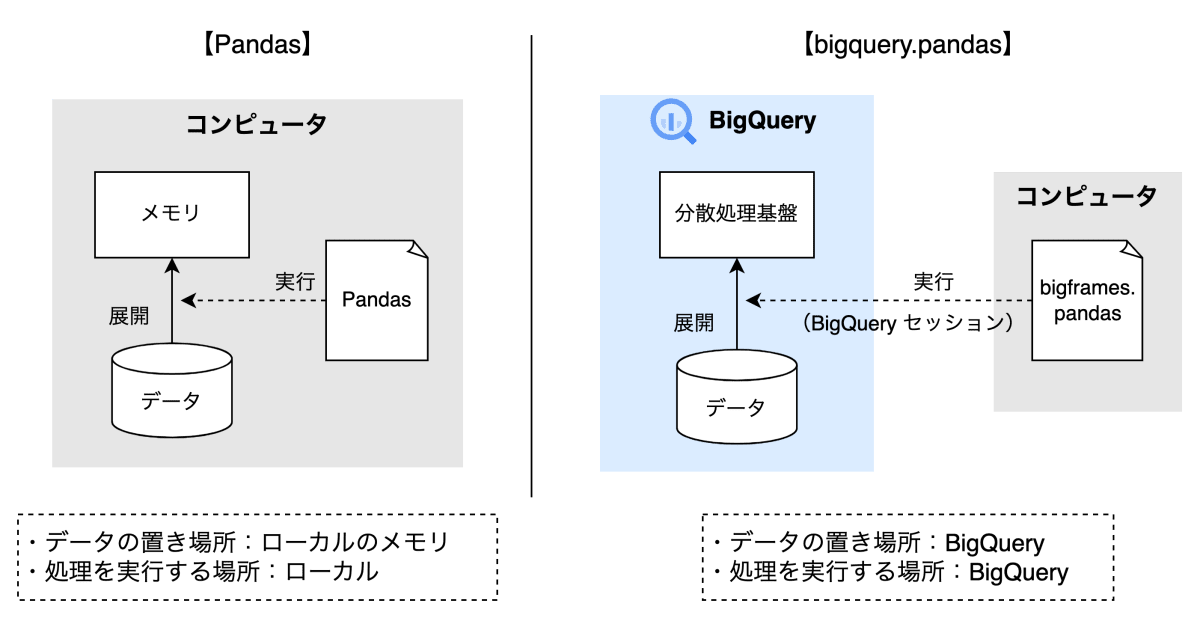
Pandas と bigframes.pandas の違い
良いところ ① メモリ不足になりにくい
bigframes.pandas はデータをメモリに展開しないため、メモリ不足になりにくいというメリットがあります。
Pandas の DataFrame はメモリを多く消費するため、サイズの大きいデータを処理する場合、「処理中にメモリ不足に陥る」「そもそもデータが DataFrame としてメモリに乗らない」ということがよくありました。
一方で、bigframes.pandas は BigQuery 上でデータを処理するため、BigQuery に格納されている大容量データであってもメモリ不足を心配せずに操作することができます。
ただし、処理内容によっては BigQuery 上でメモリ不足を起こすこともあるので、絶対にメモリ不足にならないというわけではない点に注意です。
良いところ ② 処理が速い
Pandas では、データのサイズが大きい場合、コードを工夫しないと処理スピードが遅くなってしまいます。
一方で、bigframes.pandas は、大規模データで処理が複雑でも、BigQuery の分散処理のおかげで、大抵は数秒〜数分以内に処理が完了させることができます。
このように、Pandas ではメモリや処理速度を気にしてコードを書く必要がありましたが、bigframes.pandas はそのあたりを気にする必要がないため、データ分析に集中することができます。
Pandas を使った方法との違い
従来から、BigQuery データを Pandas で扱う方法として、BigQuery の Python クライアントライブラリからクエリを発行し、結果を DataFrame に読み込むという方法がありました。
import pandas as pd
from google.cloud import bigquery
client = bigquery.Client()
query = """
SELECT
number, name, age
FROM
`my-project.my_dataset.my_table`
"""
df = client.query(query).to_dataframe()
しかし、この方法は BigQuery データを Pandas の DataFrame としてメモリに展開した上で処理を行うという方法のため、BigQuery のデータが巨大だった場合、メモリ不足や処理が遅くなるといった問題が発生することがありました。
データの保持や処理が BigQuery で完結しているというのが、bigframes.pandas を使った方法と Pandas を使った方法との違いです。
使い方
主な機能を紹介します。
インストール
BigQuery DataFrames は pip でインストールできます。
pip install bigframes
bigframes.pandas の import は以下のように書きます。
import bigframes.pandas as bpd
DataFrame の作成
データソースからデータを読み込む方法
BigQuery にあるデータを DataFrame として読み込みます。
今回は、パブリックデータセット bigquery-public-data.iowa_liquor_sales.sales(アイオワ州の酒類の卸売購入履歴)を使用します。
# BigQuery テーブルのリージョンを指定
bpd.options.bigquery.project = 'my-project'
# テーブル名を指定
table_id = 'bigquery-public-data.iowa_liquor_sales.sales'
df = bpd.read_gbq(table_id)
また、テーブル名ではなくクエリ文を指定することで、クエリ結果を DataFrame に入れることもできます。
query = '''
SELECT
date, store_name, address, city
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date = DATE("2021-02-23")
'''
df_query = bpd.read_gbq(query)
bpd.read_gbq() を実行しても BigQuery のデータがローカルメモリに格納されるわけではなく、実際のデータはあくまで BigQuery に置かれたままです。
また、bpd.read_gbq() の戻り値は Pandas の DataFrame オブジェクト ではなく、bigframes.dataframe.DataFrame という別のオブジェクトである点に注意です。
type(df)
# -> bigframes.dataframe.DataFrame
df_pandas = pd.DataFrame()
type(df_pandas)
# -> pandas.core.frame.DataFrame
BigQuery テーブルだけでなく、他のソースからもインポートできます。
# CSV ファイル
bpd.read_csv('gs://cloud-samples-data/bigquery/us-states/us-states.csv')
# Pandas の DataFrame オブジェクト
bpd.read_pandas(df_pandas)
その他、JSON や pickle などのインポートもサポートされています。
コンストラクタによる作成
DataFrame のコンストラクタにデータを渡して作成することもできます。
以下は辞書型オブジェクトを DataFrame として読み込む方法です。
data = {
'name': ['Otani', 'Maeda', 'Suzuki'],
'number': [17, 18, 27],
'team': ['Dodgers', 'Tigers', 'Cubs']
}
df = bpd.DataFrame(data=data)
基本的な操作
Pandas の基本的なメソッドと同じメソッドが多く用意されています。
# 先頭5行を表示
df.head(5)
# DataFrame の基本情報を表示
df.info()
# 基礎統計量を表示
df.describe()
DataFrame に対して処理を行うと、以下のような文字列がログとして出力されます。
これは BigQuery のジョブ ID で、DataFrame の処理が実際に BigQuery で行われていることが分かります。

クエリジョブのログ
データの抽出
データの抽出(参照)は以下のように行います。
# 列を抽出
df[['store_number', 'date']] # 戻り値は DataFrame
df['store_number'] # 戻り値は Series
# 任意の位置のデータを抽出
df.loc['row_1', 'col_2'] # 行名、列名を指定
# 条件による抽出
df[df['store_number'] == '1000A']
GroupBy
GroupBy の集計が可能です。
# store_number をキーに sale_dollars を合計
df.groupby(by='store_number')['sale_dollars'].sum()
# agg()で複数の集計関数を適用することも可能
df.groupby(by='store_number')['sale_dollars'].agg(['sum', 'mean', 'min', 'max'])
結合
merge、join、concat による DataFrame 同士の結合も可能です。
df1 = df[['store_number', 'date', 'sale_dollars']]
df2 = df[['store_number', 'date', 'bottles_sold']]
# merge
df_merge = bpd.merge(df1, df2, on=['store_number', 'date'], how='left')
# join
## あらかじめ結合のキーとなる列を index にセットしておく
df1_temp = df1.set_index(['store_number', 'date'])
df2_temp = df2.set_index(['store_number', 'date'])
df_join = df1_temp.join(df2_temp, how='left')
# concat
df_concat = bpd.concat([df1, df2], axis=1) # axis=0 で縦、axis=1で横に結合
merge と join の結合方法として、'left', 'right', 'inner', 'outer', 'cross' が用意されています。
また、join() は、基本的に index をキーとして結合を行うため、あらかじめ index を設定しておきます。
関数の適用
apply() を使用して、DataFrame に対して任意の関数を適用することができます。
def square(x):
return x * x
df.apply(square)
DataFrame のエクスポート
DataFrame を以下のようなファイルやオブジェクトに変換することができます(一部を抜粋)。
- Pandas の DataFrame オブジェクト
- dict オブジェクト(辞書型)
- BigQuery テーブル
- Numpy オブジェクト
- CSV ファイル
- Excel ファイル
# BigQuery テーブルにエクスポート
df.to_gbq('my-project.my_dataset.my_table', if_exists='replace')
# Pandas の DataFrame オブジェクトに変換
df_pandas = df.to_pandas()
なお、to_pandas() はデフォルトでは 500MB までのデータしか変換できませんが、以下のように max_download_size オプションでサイズ上限を変更することができます。
bpd.options.sampling.max_download_size = 2000 # 単位: MB
可視化
Pandas では、df.plot() を使ってデータの可視化ができますが、bigframes.pandas では df.plot() はまだ実装されていません。
しかし、matplotlib との互換性はあるため、可視化を行うことができます。
from matplotlib import pyplot as plt
df = df[['date', 'sale_dollars']].groupby(by='date').sum(numeric_only=True)
plt.plot(df)
plt.show()
Pandas と bigframes.pandas のスピード対決
処理速度について、Pandas と bigframes.pandas のどちらが早いかを勝負させてみます。
小規模データを使った処理と大規模データを使った処理の 2 パターンを行います。
条件
処理は、処理が重くなりがちな CROSS JOIN を行います。
1 回戦では 100 行 × 100 行の CROSS JOIN を行い、2 回戦では 1000 万行 × 100 行の CROSS JOIN を行います。
コードは Google Cloud の Colab Enterpise の Jupyter Notebook で実行し、ランタイムとしてマシンタイプ「e2-highmem-16」(16vCPU、メモリ 128GB)を設定します。
1回戦 小規模データ
まず、100 行 × 100 行の CROSS JOIN を行います。
100 行の DataFrame を、bigframes.pandas と Pandas のそれぞれで 2 つずつ用意します。
data_a = [a for a in range(100)]
data_b = [b for b in range(100)]
# bigframes.pandas 用
df_A = bpd.DataFrame(data_a)
df_B = bpd.DataFrame(data_b)
# Pandas 用
df_A_pd = pd.DataFrame(data_a)
df_B_pd = pd.DataFrame(data_b)
まずは bigframes.pandas で CROSS JOIN を行います。
start = time.time()
print(bpd.merge(df_A, df_B, how='cross'))
end = time.time()
processing_time = end - start
print(processing_time)
# -> 2.3654255867004395
merge の前後で現在時刻を取得し、その差を処理スピードとします。
なお、bigframes.pandas では処理のコードを実行するだけでは実際に処理は行われず、表示やエクスポートなどが行われて初めて処理が実行されるため、merge で print() を入れています。
そして、結果は約 2.4 秒でした。
次に Pandas を実行します。
start = time.time()
print(pd.merge(df_A_pd, df_B_pd, how='cross'))
end = time.time()
processing_time = end - start
print(processing_time)
# -> 0.02993154525756836
bigframes.pandas と条件を揃えるため、print() を入れています。
結果は 0.030 秒でした。
小規模データを使った処理では Pandas の方が早いという結果になりました。
bigframes.pandas は BigQuery でデータを分散処理するため、小規模データの場合は無駄が発生し、処理が遅くなる傾向があります。
そのため、今回は Pandas の方が早くなりました。
2回戦 大規模データ
次は、1000 万行 × 100 行の CROSS JOIN で勝負します。
同じようにデータを用意します。
data_a = [a for a in range(100000000)]
data_b = [b for b in range(100)]
df_A = bpd.DataFrame(data_a)
df_B = bpd.DataFrame(data_b)
df_A_pd = pd.DataFrame(data_a)
df_B_pd = pd.DataFrame(data_b)
bigframes.pandas で CROSS JOIN を行います。
start = time.time()
print(bpd.merge(df_A, df_B, how='cross'))
end = time.time()
processing_time = end - start
print(processing_time)
# -> 31.014904260635376
結果は約 31.0 秒でした。
Pandas も実行します。
start = time.time()
print(pd.merge(df_A_pd, df_B_pd, how='cross'))
end = time.time()
processing_time = end - start
print(processing_time)
# -> 67.90732169151306
結果は約 67.9 秒でした。
大規模データではダブルスコアで bigframes.pandas に軍配が上がりました。
また、Notebook のメモリ使用量を見ると、Pandas の実行時は最大で 60GB に到達しており、十分なメモリがなければメモリ不足で実行できていなかったかもしれません。
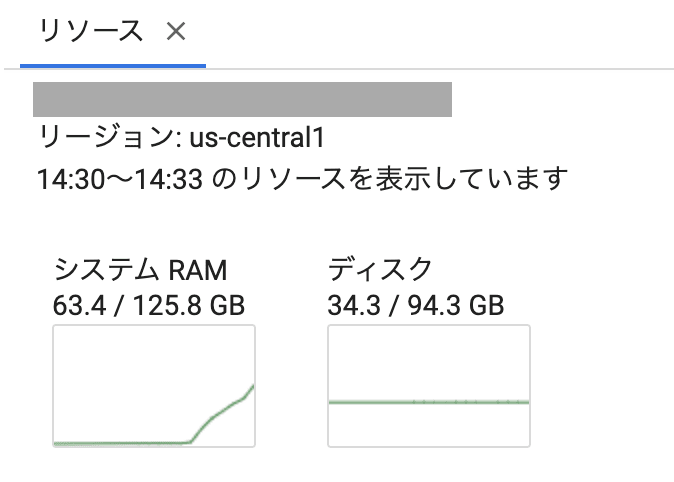
Pandas 実行時のメモリ使用量
今回のスピード対決で、bigframes.pandas は大規模データの処理に強いということがわかりました。
bigframes.pandas の弱点
弱点① 開発途上
bigframes.pandas はまだ登場したてのライブラリのため、Pandas のすべての機能が実装されているわけではありません。
一方で、BigQuery DataFrames の開発チームはフィードバックを受け付けてくれているため、実装してほしい機能やバグをフィードバックとしてメールを送ることができます。
実際、私も機能追加のフィードバックを送ったところ、(たまたま開発中だったのかも知れませんが)2 週間ほどでその機能が実装されました。
フィードバック先はこちら。
また、ライブラリは 1 週間に 1 回ほどの頻度でアップデートが行われているため、機能の物足りなさの解消は時間の問題かと思います。
ライブラリのリリースノートはこちら。
弱点② 料金
処理はすべて BigQuery 上で行われるため、処理が行われるたびにクエリ料金が発生します。
SQL を実行するときと同じく、処理によっては料金が跳ね上がる可能性があるため、処理内容には注意が必要です。
まとめ
今回は、BigQuery データを Pandas のように操作することができる、BigQuery DataFrames の bigframes.pandas を紹介しました。
bigframes.pandas は BigQuery データを Pandas とほとんど同じコードでデータ処理を行うことができ、Pandas と比較してメモリ・スピード問題を意識する必要がないという点に大きな強みがあります。
今回は bigframes.pandas のみ取り上げましたが、bigframes.sklearn という 機械学習関連の機能もあります。
Google の Colaboratory や Google Cloud の Colab Enterprise では、Jupyter Notebook に BigQuery DataFrames がプリインストールされているため、簡単に BigQuery DataFrames を使用できます。
ぜひ一度使ってみてください。
関連記事
BigQuery DataFrames 全体の紹介
BigQuery DataFrames がプリインストールされている Colab Enterprise の紹介
Discussion