BigQuery DataFrames のご紹介
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の工藤です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、BigQuery DataFrames です。BigQuery DataFrames を使うことで、大量のデータを BigQuery 上で処理できます。また、PaLM2 などのモデルへ簡単に接続することができます。なお、この機能はプレビュー段階になります。
BigQuery とは
BigQuery とは、Google Cloud が提供しているデータウェアハウス サービスの一つです。データウェアハウスとは、データ分析に特化したデータベースのことを指します。BigQuery では、SQL クエリを記述することによって、データ分析を実行できます。
今回のリリースについて
今回ご紹介するのは、2023 年 8 月 29 日付に発表されたリリースの一つである BigQuery DataFrames についてです。
該当リリースノート:BigQuery release notes
BigQuery DataFrames とは
BigQuery DataFrames は、BigQuery 上でデータを分析し、機械学習タスクを実行するための API を提供します。BigQuery DataFrames は以下の API を提供しています。
- bigframes.pandas
この API は、部分的に pandas と互換性がある API です。BigQuery からデータを読み込むためのモジュールや欠損値を補完するためのモジュールを提供しています。 - bigframes.ml
この API は、部分的に scikit-learn と互換性がある API です。データを前処理するためのモジュールやモデルをトレーニングするためのモジュールを提供しています。トレーニングモデルの中には大規模言語モデルである PaLM2 も提供されており、手軽に PaLM2 を使用したテキスト生成ができます。
API の詳細な説明は、Google Cloud blog をご覧ください。
制限
BigQuery DataFrames の利用に関して、重要な制限事項を以下にまとめます。
-
データタイプ
- BigQuery DataFrames には、サポートされていないデータタイプがあります。ARRAY や JSON などサポートされていないタイプのデータを読み込んだとき、そのデータは ARRAY や JSON として扱われませんのでご注意ください。詳細は、公式ドキュメントを参照ください。
-
データ処理のロケーション
- BigQuery のデータを読み込むために read_gbq メソッドを使用しクエリを発行するとき、クエリ対象のデータセットが存在するロケーションと BigQuery セッションが作成されるロケーションは、同じである必要があります。例えば、クエリ対象のデータセットが「 asia-northeast1 」リージョンに存在する場合、セッションが作成されるロケーションも「 asia-northeast1 」リージョンである必要があります。セッションが作成されるロケーションはデフォルトだと US マルチリージョンですが、以下のコードでロケーションを設定することが可能です。
# モジュールのインポート
import bigframes.pandas as bpd
# セッションが作成されるロケーションの設定 ( asia-northeast1 を設定する場合)
bpd.options.bigquery.location = "asia-northeast1"
-
割り当て
- BigQuery DataFrames の割り当ての制限は、従来の BigQuery の制限に従います。詳細は、公式ドキュメントを参照ください。
-
bigframes.ml API のロケーション
- bigframes.ml API のロケーションは、BigQuery ML のロケーション サポートに従います。詳細は、公式ドキュメントを参照ください。
料金
BigQuery DataFrames を使用することで追加料金は発生しませんが、API によって扱うデータの保存や取り出しには BigQuery の通常の料金が発生します。料金の詳細は、公式ドキュメントを参照ください。
検証
それでは実際に使ってみたいと思います。BigQuery DataFrames のコードサンプルは、公式の GitHub リポジトリに用意されています。今回はその中から大規模言語モデルのサンプルを使い、PaLM2 を使用したテキスト生成を行います。
実行環境として、Colab Enterprise のノートブック環境を使用しました。Colab Enterprise とは、Vertex AI に統合されているインフラ管理が不要なノートブック環境です。Colab Enterprise を使用する場合は、BigQuery の料金に加えて Colab Enterprise の料金も発生します。Colab Enterprise の料金は、公式ドキュメントを参照ください。
BigQuery DataFrames を使用するためには、 BigQuery DataFrames のパッケージ(ライブラリ)をインストールする必要があります。
Python を使用している場合は、以下のようなコマンドでインストールしましょう。
pip3 install --upgrade bigframes
今回使用した Colab Enterprise は BigQuery DataFrames が統合されていますので、パッケージのインストールは不要です。
それでは大規模言語モデルのサンプルコードを使ってみます。サンプルコードでは、PaLM2TextGenerator クラスを使用してモデルにプロンプトを与え、そのプロンプトに対する回答をテキストで生成してもらいます。まずはモジュールをインポートします。
[ コードと実行結果 ]

次は BigQuery セッションを作成し、モデルへ接続するために必要な接続を定義します。接続は、"プロジェクトID.接続対象が存在するロケーション.接続名(任意の名前)" を設定する必要があります。
[ コードと実行結果 ]

次は PaLM2TextGenerator クラスを使用し、モデルを定義します。
[ コードと実行結果 ]

次は、モデルに入力するプロンプトを持つデータフレームを作成します。プロンプトに基づいたテキストを生成する predict メソッドの引数の型に合わせるために、プロンプトは BigFrames のデータフレームに変換しています。
[ コードと実行結果 ]

定義したモデルを呼び出し、プロンプトに基づいたテキストを生成します。質問に対する回答が生成されていることが確認できます。
[ コードと実行結果 ]
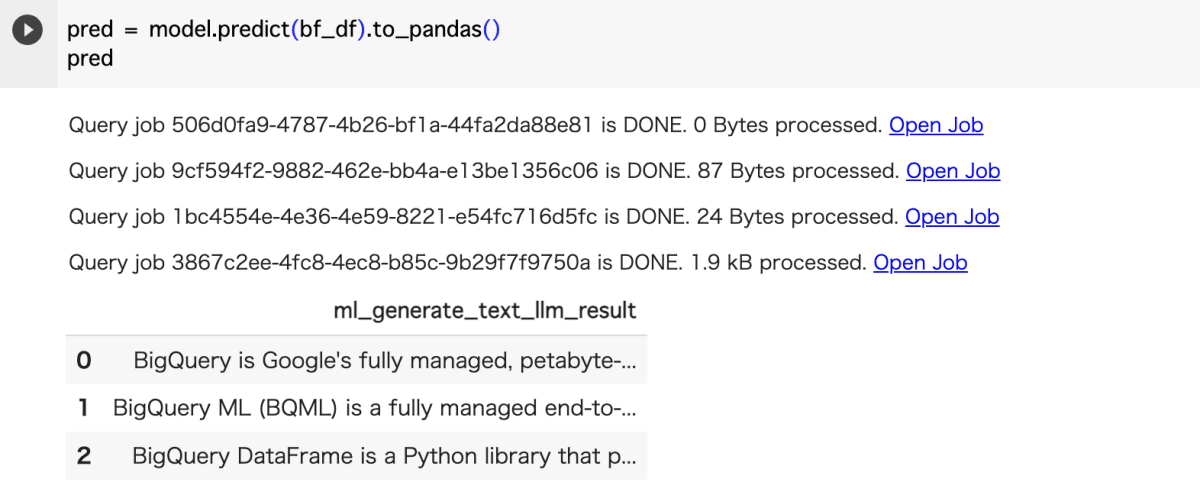
最後に一つ目のプロンプト「What is BigQuery?」に対して生成されたテキストを表示します。
[ コードと実行結果 ]

| プロンプト | 生成されたテキスト |
|---|---|
| What is BigQuery? | BigQuery is Google's fully managed, petabyte-scale analytics data warehouse that enables businesses to analyze all their data very quickly. It is a cloud-based data warehouse that offers fast performance, scalability, and flexibility. BigQuery uses a columnar storage format and a distributed computing engine to provide fast and scalable performance for large-scale data analysis. It also offers a variety of features that make it easy to use, such as a web-based user interface, a SQL-like query language, and support for a variety of data sources. |
生成されたテキストは、BigQuery について説明できていると思います。
まとめ
今回の記事では、BigQuery DataFrames についてご紹介しました。
BigQuery のリソースを使用して処理を行えるので、レコード数が多くても処理時間を気にせずに分析できそうです。
また、PaLM2 などのモデルへ簡単に接続できるので、モデルを使用した開発が捗るのではないでしょうか。
興味のある方はぜひお試しください。
Discussion