Cloud Spanner:ミューテーションによるバッチ書き込み方法
こんにちは、クラウドエース データML ディビジョン所属の源です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回、ご紹介するリリースは 2023 年 10 月 9 日付に発表された Cloud Spanner のバッチ書き込み機能についてです。Spanner のバッチ書き込みは多数の書き込みを一括で行えますが、アトミックトランザクション(全てが完了するか、全てが実行されないかのどちらかの状態を保証すること)ではない等、制限事項も多いため注意が必要です。この機能はプレビュー段階です。
Cloud Spannerとは
Cloud Spanner は、リレーショナルデータベースサービスです。無制限のスケール、最大99.999%の可用性、グローバルなトランザクション整合性を提供します。
参考資料:Cloud Spanner の概要
料金
Cloud Spanner は以下の要素に基づいて課金されます。
- インスタンスのコンピューティング容量:ノード数に時間単位のレートを掛けた金額が課金されます。
- データベースで使用しているストレージ量:データベースでの1か月間の平均データ量に月単位のレートを掛けた料金が課金されます。
- バックアップで使用しているストレージ量:バックアップでの1か月間の平均データ量に月単位のレートを掛けた料金が課金されます。
- 使用したネットワーク帯域幅の量:ネットワーク下り(外向き)トラフィックは課金対象となります。レプリケーションやネットワーク上り(内向き)トラフィックは課金対象となりません。
参考資料:Cloud Spanner の料金
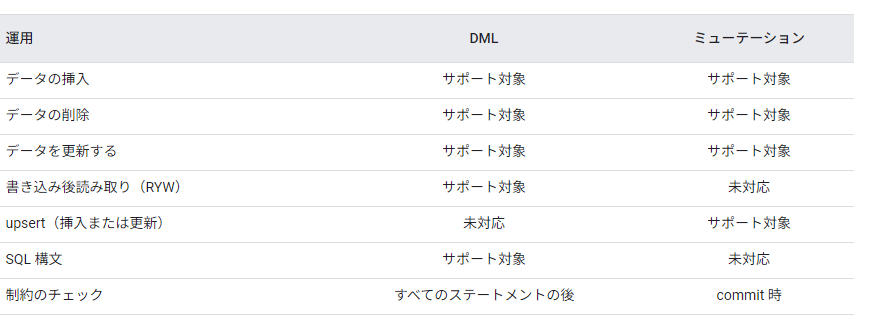
DMLとミューテーションの違い
Spanner でのデータ操作にはDMLとミューテーションの2種類あり、本記事ではミューテーションのバッチ書き込みについて説明します。
DMLは一連の操作(挿入、更新、削除)のクエリを記述して実行する方法のことです。
対して、ミューテーションは一連の操作(挿入、更新、削除)を定義することです。定義したミューテーションを適用(コミット)することでデータ操作が可能です。
それぞれサポートに違いがあるため、要件に適した方法の選定が必要です。
また、データ操作にも通常のデータ操作と、多数の操作を一括で行えるバッチ操作の2種類が存在します。
本記事では、プレビュー版が公開されたミューテーションでのバッチ書き込みを紹介します。
バッチ操作でないミューテーションでのデータ操作は ミューテーションを使用してデータを挿入、更新、削除するをご覧ください。
DML でのデータ操作(バッチ操作を含む)は データ操作言語(DML)を使用してデータを挿入、更新、削除するをご覧ください。
参考資料:DML とミューテーションの比較
制限事項
Spanner のバッチ書き込みには次の制限があります。
現状、Java での開発しか対応しておらず、アトミックトランザクションではないため、留意する必要があります。
- Google Cloud コンソールまたはGoogle Cloud CLIでは使用不可。REST API と RPC API と Spanner Java クライアントライブラリでのみ使用可能。
- バッチ書き込みを使用したリプレイ保護はサポートされていません。ミューテーションは複数回適用される可能性があります。
- 完了したバッチ書き込みのロールバックはできません。
- バッチ書き込みリクエストの最大サイズは、コミットリクエストの上限と同じです。詳細は、データの作成、読み取り、更新、削除の制限をご覧ください。
検証概要
本検証では、実際にミューテーションを用いたバッチ書き込みでデータを変更します。
公式ドキュメントでは省略されている前提や手順が多々あるため、本記事では検証に至るまでの手順も記載します。
参考資料:バッチ書き込みを使用してデータを変更する
検証
1. Cloud Spanner の用意
バッチ書き込みを行う前に、インスタンスやデータベースを作成する必要があります。
1.1. インスタンス用意
Google Cloudコンソール で [Cloud Spanner] ページに移動し、[インスタンスを作成] をクリック
入力例)
- インスタンス名に、「test_instance」などの名前を入力
- [構成を選択する] で、デフォルトのオプション [リージョン] を保持し、プルダウンメニューから「asia-northeast1 (東京)」などの構成を選択。
※インスタンスの構成により、インスタンスが保存および複製される地理的なロケーションが決まります。

1.2. データベース用意
作成したインスタンスをクリックし、[データベースを作成する] をクリックします。
入力例)
- データベース名には、example_db などの名前を入力
- データベース言語で Google SQL を選択

1.3. テーブル用意
データベースの [概要] ページの [テーブル] セクションで、[テーブルを作成する] をクリックし、
[DDL ステートメントを書き込む] ページで、下記の通りに入力し、[送信] をクリックします。
この操作を2回を行い、テーブルを2個作成します。
下記 DDL ステートメントは、後述の Java コード内でコメントとして記載されています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
) PRIMARY KEY (SingerId)
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(1024),
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE
作成されるテーブルは SingerId をキーとしてインターリーブされていて、Singers は親テーブル、Albums は子テーブルと呼びます。
インターリーブにより Spanner は子の行をストレージ内の親の行と物理的に同じ場所に配置され、親子関係のテーブルに対してクエリを実行するときのクエリパフォーマンスが向上します。
後述するミューテーションでのバッチ書き込みの制約で、この親子関係に関して制約が掛かります。
参考資料:Google Cloud コンソールを使用してデータベースを作成しクエリを実行する

2. Java開発環境を用意
ミューテーションによるバッチ書き込みを行うためには Java 開発環境が必要です。
円滑に開発に移りたい際には、これらの環境が整備されている Cloud Shell が有用です。
- JDK(Java Development Kit)をインストールする
- ビルド自動化ツールをインストールする
- (オプション)IDE またはエディタをインストールする
- (オプション)IDE Google Cloud プラグインをインストールする
- gcloud CLI をインストールする
参考資料:Java 開発環境の設定
参考資料:Cloud Shell の概要
3. Java開発
3.1. 設定や認証
Cloud Spanner API へのサービス呼び出しを行うには、対応する GCP プロジェクトの API が有効になっている必要があります。
手順に従って gcloud CLI のインストール、Cloud Spanner API の有効化をします。
また、ローカルでコードを実行するには、アプリケーションのデフォルト認証情報を使用します。
gcloud auth application-default login
参考資料:設定 - gcloud CLI をインストールして Cloud Spanner API を設定する
3.2. 依存関係構築、コード構築
Maven または Gradle の依存関係を設定する必要があります。
Cloud Code を利用している場合は、Cloud Code の Cloud API欄から Cloud Spanner APIを選び、手順を確認することができます。
Maven の場合は pom.xml に下記を追加します。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.27.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
</dependencies>
Gradle 5 以降を使用している場合は依存関係に以下を追加します。
dependencies {
implementation platform("com.google.cloud:libraries-bom:26.27.0")
implementation("com.google.cloud:google-cloud-spanner")
}
BatchWriteAtLeastOnceSample.javaを作成し、下記コードを記載します。
import com.google.api.gax.rpc.ServerStream;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Mutation;
import com.google.cloud.spanner.MutationGroup;
import com.google.cloud.spanner.Options;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerOptions;
import com.google.common.collect.ImmutableList;
import com.google.rpc.Code;
import com.google.spanner.v1.BatchWriteResponse;
public class BatchWriteAtLeastOnceSample {
/***
* Assume DDL for the underlying database:
* <pre>{@code
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
) PRIMARY KEY (SingerId)
*
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(1024),
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE
* }</pre>
*/
private static final MutationGroup MUTATION_GROUP1 =
MutationGroup.of(
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(16)
.set("FirstName")
.to("Scarlet")
.set("LastName")
.to("Terry")
.build());
private static final MutationGroup MUTATION_GROUP2 =
MutationGroup.of(
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(17)
.set("FirstName")
.to("Marc")
.build(),
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(18)
.set("FirstName")
.to("Catalina")
.set("LastName")
.to("Smith")
.build(),
Mutation.newInsertOrUpdateBuilder("Albums")
.set("SingerId")
.to(17)
.set("AlbumId")
.to(1)
.set("AlbumTitle")
.to("Total Junk")
.build(),
Mutation.newInsertOrUpdateBuilder("Albums")
.set("SingerId")
.to(18)
.set("AlbumId")
.to(2)
.set("AlbumTitle")
.to("Go, Go, Go")
.build());
static void batchWriteAtLeastOnce() {
// TODO(developer): Replace these variables before running the sample.
final String projectId = "my-project";
final String instanceId = "my-instance";
final String databaseId = "my-database";
batchWriteAtLeastOnce(projectId, instanceId, databaseId);
}
static void batchWriteAtLeastOnce(String projectId, String instanceId, String databaseId) {
try (Spanner spanner =
SpannerOptions.newBuilder().setProjectId(projectId).build().getService()) {
DatabaseId dbId = DatabaseId.of(projectId, instanceId, databaseId);
final DatabaseClient dbClient = spanner.getDatabaseClient(dbId);
// Creates and issues a BatchWrite RPC request that will apply the mutation groups
// non-atomically and respond back with a stream of BatchWriteResponse.
ServerStream<BatchWriteResponse> responses =
dbClient.batchWriteAtLeastOnce(
ImmutableList.of(MUTATION_GROUP1, MUTATION_GROUP2),
Options.tag("batch-write-tag"));
// Iterates through the results in the stream response and prints the MutationGroup indexes,
// commit timestamp and status.
for (BatchWriteResponse response : responses) {
if (response.getStatus().getCode() == Code.OK_VALUE) {
System.out.printf(
"Mutation group indexes %s have been applied with commit timestamp %s",
response.getIndexesList(), response.getCommitTimestamp());
} else {
System.out.printf(
"Mutation group indexes %s could not be applied with error code %s and "
+ "error message %s", response.getIndexesList(),
Code.forNumber(response.getStatus().getCode()), response.getStatus().getMessage());
}
}
}
}
}
上記コードの下記部分に対しては、適切なプロジェクトID、インスタンスID、データベースIDに置き換えます。
// TODO(developer): Replace these variables before running the sample.
final String projectId = "my-project";
final String instanceId = "my-instance";
final String databaseId = "my-database";
バッチ書き込みを使用する場合は、次の制約を意識してミューテーションタイプをグループ化する必要があります。
- テーブル間に外部キー関係があるテーブルに行を挿入する。
要するに、子テーブルに存在しない主キー持つを行は親テーブルに追加可能ですが、
親テーブルに存在しない主キー持つ行は子テーブルに追加不可能ということです。 - 親テーブルと子テーブルの両方で同じ主キーの接頭辞を持つ行を挿入する。
要するに、親テーブルに存在しない主キーを持つ行を、親テーブルと子テーブルに同時に追加することは可能ということです。 - 他のタイプの関連するミューテーションは、データベース スキーマとアプリケーション ロジックによって異なる。
要するに、その他のミューテーションによっては異なる制約が課されることがあるということです。
バッチ書き込みの制約を上記コードを踏まえて見てきます。
本検証では、ミューテーショングループ 1 とグループ 2 の 2 つをバッチ書き込みします。
ミューテーショングループ 1 では、親テーブルの Singers の主キー SingerId に 16 を新規追加します。
制約の 1 番に記載の通り、子テーブルにない主キーも親テーブルに追加可能です。
逆に、親テーブルに存在しない主キーを持つ行は Albums に追加できません。
親テーブルに存在しない主キー追加による失敗は、後の検証で行います。
private static final MutationGroup MUTATION_GROUP1 =
MutationGroup.of(
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(16)
.set("FirstName")
.to("Scarlet")
.set("LastName")
.to("Terry")
.build());
ミューテーショングループ 2 では、親テーブル Singers と子テーブル Albums に対して主キー SingerId に 17、18 を新規追加します。
親テーブル Singers に SingerId 17、18 は存在しない状態で子テーブル Albums に SingerId に 17、18 を追加することになります。
しかしながら、制約の 2 番に記載の通り、同時に親テーブルにも同じ主キーを持つ行を挿入する場合は追加可能です。
private static final MutationGroup MUTATION_GROUP2 =
MutationGroup.of(
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(17)
.set("FirstName")
.to("Marc")
.build(),
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(18)
.set("FirstName")
.to("Catalina")
.set("LastName")
.to("Smith")
.build(),
Mutation.newInsertOrUpdateBuilder("Albums")
.set("SingerId")
.to(17)
.set("AlbumId")
.to(1)
.set("AlbumTitle")
.to("Total Junk")
.build(),
Mutation.newInsertOrUpdateBuilder("Albums")
.set("SingerId")
.to(18)
.set("AlbumId")
.to(2)
.set("AlbumTitle")
.to("Go, Go, Go")
.build());
上記コードを実行する簡単な App.java を作成します。
package com.google.cloud;
public class App {
public static void main(String[] args) {
BatchWriteAtLeastOnceSample.batchWriteAtLeastOnce();
}
}
App.java を実行すると下記出力を得ることが出来、テーブルにデータが入ったことが確認できました。
Mutation group indexes [0, 1] have been applied with commit timestamp seconds: 1699590464
nanos: 234212000


追加検証. 親テーブルに存在しない主キー持つ行を子テーブルに追加し、失敗することを確認
下記コードを修正し、子テーブル Albums を追加するコードに変更します。
// 変更前
private static final MutationGroup MUTATION_GROUP1 =
MutationGroup.of(
Mutation.newInsertOrUpdateBuilder("Singers")
.set("SingerId")
.to(16)
.set("FirstName")
.to("Scarlet")
.set("LastName")
.to("Terry")
.build());
// 変更後
private static final MutationGroup MUTATION_GROUP1 =
MutationGroup.of(
Mutation.newInsertOrUpdateBuilder("Albums")
.set("SingerId")
.to(10)
.set("AlbumId")
.to(1)
.set("AlbumTitle")
.to("Total Junk")
.build());
併せて下記コードを修正し、ミューテーショングループ 1 のみの検証ができるようにします。
// 変更前
ServerStream<BatchWriteResponse> responses =
dbClient.batchWriteAtLeastOnce(
ImmutableList.of(MUTATION_GROUP1, MUTATION_GROUP2),
Options.tag("batch-write-tag"));
// 変更後
ServerStream<BatchWriteResponse> responses =
dbClient.batchWriteAtLeastOnce(
ImmutableList.of(MUTATION_GROUP1),
Options.tag("batch-write-tag"));
App.java を実行すると下記出力を得ることが出来、失敗することが確認できました。
以上のことから、バッチ書き込みを行う際に制約を考慮した転送をする必要があることがわかります。
Mutation group indexes [0] could not be applied with error code NOT_FOUND and error message Parent row for row [10,1] in table Albums is missing. Row cannot be written.
まとめ
今回の記事の内容をまとめると
- Cloud Spanner のミューテーションでのバッチ書き込みが利用可能になった。
- プログラミング言語の制限や、主キー関連の制約などが複数あります。
Discussion