Cloud Spanner Data Boost とは
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の竹内です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回ご紹介するサービスは、Cloud Spanner Data Boost についてです。
このサービスを使用すると、Cloud Spanner の既存のトランザクション ワークロードにほとんど影響を与えることなく、分析クエリとデータ エクスポートを実行することができます。
またこのサービスは、2023年6月23日に東京(asia-northeast1)リージョンでの一般提供(GA)が発表されています(該当リリースノート:Spanner release notes - June 23, 2023)。
予備知識:Cloud Spanner とは
Cloud Spanner は、トランザクションの大規模な分散処理ができるリレーショナルデータベースです。強整合性や高可用性などを備えており、高性能のトランザクション ワークロードを提供します。
Cloud Spanner Data Boost とは
Data Boost は、既存の Spanner インスタンスと連携された別のコンピューティングリソースを提供する、フルマネージドのサーバーレスサービスです。
このサービスを使用すると、Spanner の既存のトランザクション ワークロードにほとんど影響を与えることなく、分析クエリとデータ エクスポートを実行することができます。
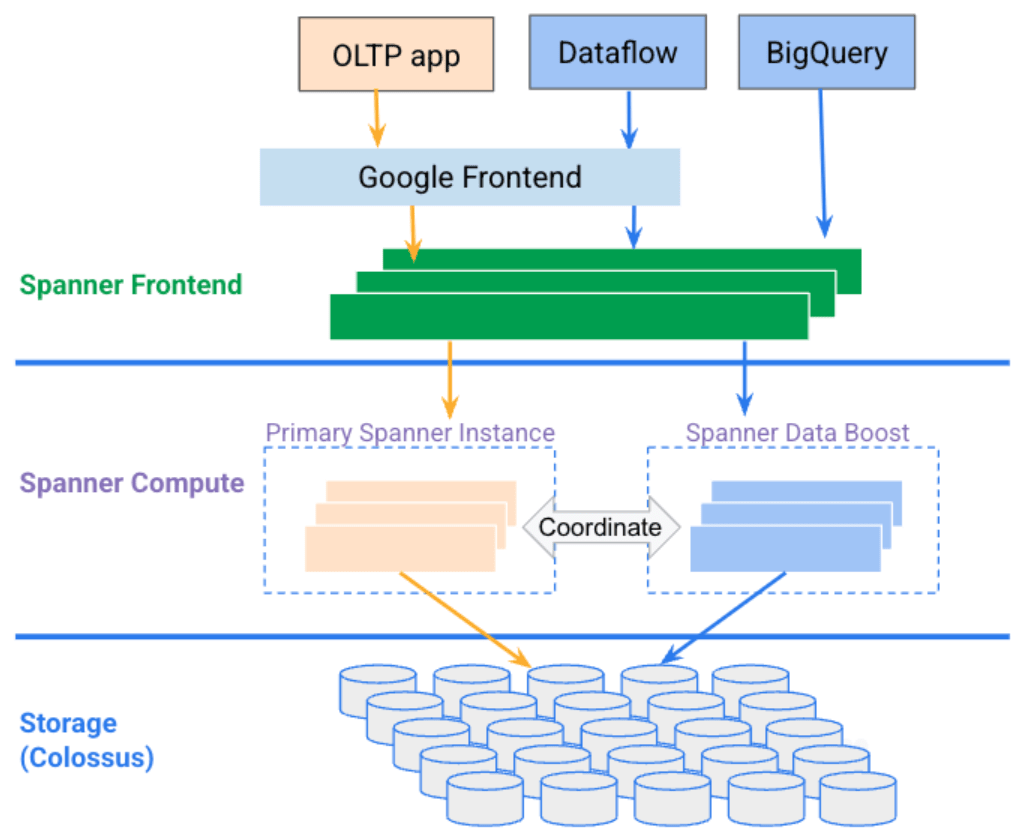
【画像出典:データブーストの概要】
ユースケース
Data Boost は、トランザクション ワークロードと、その他のワークロード(クエリ実行やデータ エクスポート)との間で、Spanner のリソース競合が発生しうるようなケースで役立ちます。
例として以下が挙げられます。
- 大量のデータを処理するクエリを実行するケース
- 例:BigQuery から Spanner への連携クエリ、など
- データを別のデータベースにエクスポートするケース
- 例:Spanner から Cloud Storage にデータをエクスポートする Dataflow ジョブ、など
メリット
Data Boost を使用するメリットとして、以下などが挙げられます
- Spanner インスタンスのオーバープロビジョニングを防止できる
- 処理速度は、Data Boost 未使用の場合と比べて「同等」または「速い」
- クエリ実行などによる、急激な負荷に対応できる
注意点
Data Boost を使用する際の注意点として、以下などが挙げられます。
- IAM 権限について
- Data Boost を使用するには、
spanner.databases.useDataBoost権限が必要である
- Data Boost を使用するには、
- 実行可能なクエリについて
- Data Boost 上で実行されるクエリは、クエリ実行プラン の最初の演算子が 分散ユニオン(Distributed union)である必要がある
料金
料金は、Data Boost 上で実行されたクエリが使用した処理ユニット分だけ発生します。
ただしエクスポート ジョブの実行には、Dataflow バッチワーカーなどの料金が別途発生します(参考:データベースのエクスポートとインポートの料金)。
検証
実際に Cloud Spanner Data Boost を使用してみました。
この検証では、BigQuery から Cloud Spanner への連携クエリを、Data Boost 上で実行する方法を試してみました(参考:Data Boost で連携クエリを実行する)。
手順
1. 事前準備
(1)Data Boost の IAM 権限の付与
Data Boost を使用するには、spanner.databases.useDataBoost 権限が必要です。
クエリを実行するプリンシパルがこの権限を持っていない場合、これを付与します。
(2)BigQuery Connection API の有効化
BigQuery Connection API を有効化します。この API は、BigQuery から Cloud Spanner への連携クエリで使用されます。
(3)BigQuery 接続の作成
BigQuery 接続を作成します。
bq コマンドを使用して作成する場合、properties フラグ中の useParallelism と useDataBoost を true に設定します(参考:Spanner 接続を作成する)。
bq mk --connection \
--connection_type='CLOUD_SPANNER' \
--properties='{"database":"projects/PROJECT_ID/instances/INSTANCE/databases/DATABASE", "useParallelism":true, "useDataBoost": true}' \
--location='asia-northeast1' \
spanner_test_connection
2. 連携クエリの実行
準備が完了したら、BigQuey から Spanner への連携クエリを実行します。
今回の検証では、2つのサンプルテーブル(BigQuery テーブルと Spanner テーブル)を使用しました。各テーブルのスキーマを以下に示します。
-
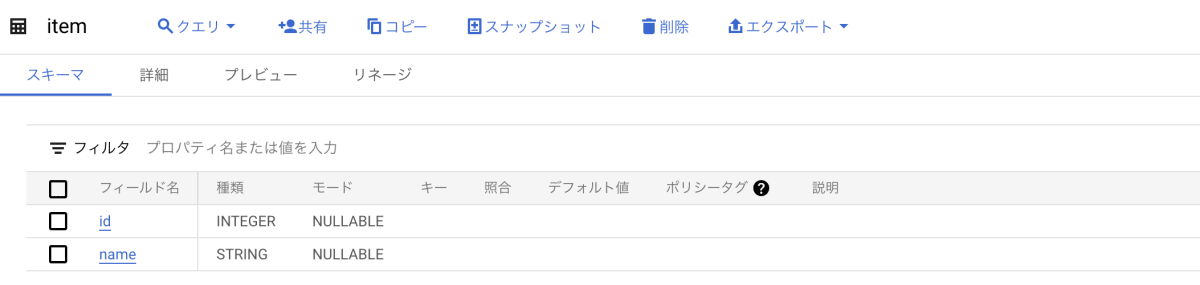
item テーブル(BigQuery)
商品 ID、商品名、が格納されているテーブル
-
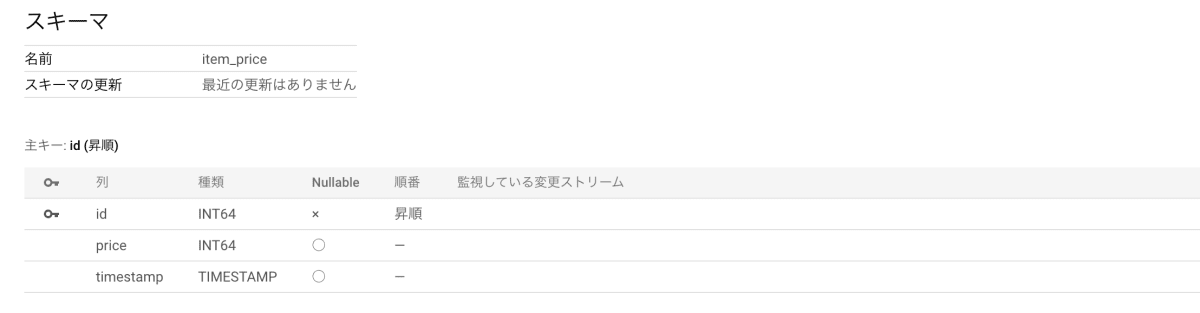
item_price テーブル(Spanner)
商品 ID、値段、更新日時、が格納されているテーブル
これらのテーブルに対して、BigQuery から以下のクエリを実行しました。
SELECT
bq.id, bq.name, sp.price, sp.last_update
FROM
`PROJECT_ID.DATASET.item` AS bq
LEFT OUTER JOIN
EXTERNAL_QUERY(
'PROJECT_ID.asia-northeast1.spanner_test_connection',
'SELECT id, price, timestamp AS last_update FROM item_price LEFT JOIN (SELECT id, MAX(timestamp) AS last FROM item_price GROUP BY id) AS tmp using(id) WHERE timestamp = tmp.last'
) AS sp
ON bq.id = sp.id
GROUP BY 1, 2, 3, 4;
EXTERNAL_QUERY 関数によって、Spanner への連携クエリが実行されます。
またこのクエリの内容は以下のとおりです。
① item_price テーブル(Spanner)から、各商品の timestamp が最新の行を取得する
② ①で取得した行と、item テーブル(BigQuery)とを、ID を使って JOIN する
(補足)
前項の「注意点」にて述べたとおり、Data Boost 上で実行されるクエリ(上記の例の EXTERNAL_QUERY 関数内のクエリ)は、クエリ実行プラン の最初の演算子が 分散ユニオン(Distributed union)である必要があります。
この条件を満たしていないクエリを実行すると、以下のエラーが出力されます。
Error while reading data, error message: Error accessing Cloud Spanner. Query is not root partitionable since it does not have a DistributedUnion at the root. Please run EXPLAIN for query plan details. File: ...(クエリ実行プランの最初の演算子が「分散ユニオン」ではないクエリ)
3. Data Boost の使用状況の確認
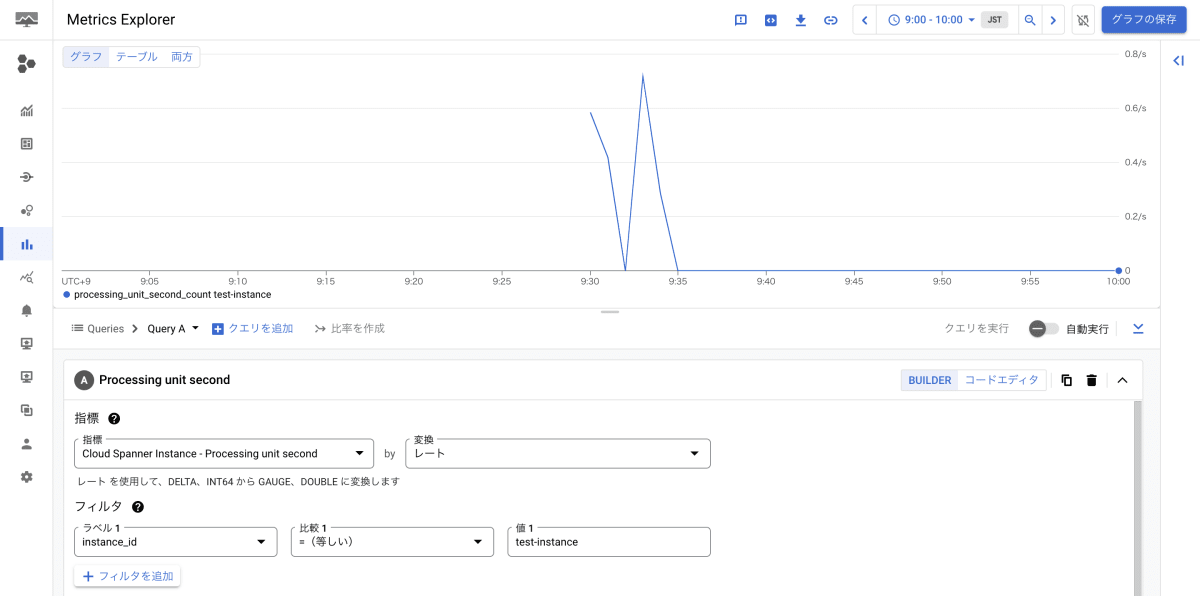
最後に、Data Boost の使用状況を確認します。
今回は Cloud Monitoring の Metrics Explorer を使用しました(参考:Data Boost の使用状況をモニタリングする)。Data Boost の指標を設定することで、クエリを実行時に Data Boost が使用されていることが確認できました。
まとめ
今回は 2023年6月23日に東京(asia-northeast1)リージョンでの一般提供(GA)が発表された、Cloud Spanner Data Boost についてご紹介しました。
このサービスを使用すると、Cloud Spanner の既存のトランザクション ワークロードにほとんど影響を与えることなく、分析クエリとデータ エクスポートを実行することができます。これにより、Spanner インスタンスのオーバープロビジョニングの防止や、処理速度の向上などが期待されます。
料金は Data Boost 上で実行されたクエリが使用した処理ユニット分だけ発生します。ただし、エクスポートジョブの実行には、Dataflow バッチワーカーなどの料金が別途発生します。
分析クエリについては、クエリ実行プランを確認し、Data Boost が使用できるクエリなのかを判断する必要があります。
Discussion