Looker StudioとBigQueryネイティブ統合を解説(プレビュー)
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の宮崎です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回ご紹介する機能は、Google Cloud の BigQuery と BI ツールである Looker Studio のネイティブ統合機能である BigQuery native integration in Looker Studio についてです。
この機能を使用すると、Looker Studio は、これまでよりも高度な分析や大規模データセットの取り扱いが可能になるほか、データモニタリングやクエリパフォーマンスの向上を実現することができます。
目次
- 本記事の目的
- 予備知識 Looker Studio とは
- 新機能 BigQuery native integration in Looker Studio とは
- ネイティブ統合による追加機能のメリットの要約
- 追加機能の解説
- 料金
- プレビュー版 BigQuery native integration in Looker Studio の申請方法
- 気になった機能を試してみた
- まとめ
本記事の目的
BigQuery native integration in Looker Studio の概要やメリット、使い方について解説します。
また、個人的に気になった機能を実際に触って見たいと思います。
予備知識 Looker Studio とは
Looker Studio はビジネスインテリジェンスとデータ分析を支援し、ユーザーがデータから価値を引き出すのを助けるかサービスです。
特徴として下記が挙げられます。
-
無償のBIツール
Looker Studio は Google が提供する無償のビジネスインテリジェンスツールです。このツールを使用すると、データの視覚化、ダッシュボード作成、レポート生成など、データ駆動型の作業を容易に行うことができます。 -
豊富なコネクター
Looker Studioは、Google スプレッドシート、Google アナリティクス、Google Cloud のサービス(BigQuery, Cloud SQL for MySQL, GCSなど)だけでなく、基本的な RDB サービス(MySQL, PostgreSQL, SQL Server)や Amazon Redshift などへのコネクターも公式で提供しています。 -
サードパーティ製のコネクター
さらに、Looker Studio はサードパーティ製のコネクターも豊富に開発されており、企業への浸透度の高い Salesforce や Snowflake などにも接続可能です。これにより、ユーザーは自分自身のビジネスデータを深く理解し、そのデータから有益な洞察を引き出すことができます。
新機能 BigQuery native integration in Looker Studio とは
Looker Studio は従来から、データ分析とビジネスインテリジェンスのための強力なツールとして広く利用されてきました。
しかし、 BigQuery との連携については、一部の機能が制限されていたり、最適化が十分に行われていない部分がありました。
そこで、これらの問題を解決するために登場したのが、BigQuery native integration in Looker Studio です。
これにより、Looker Studio から BigQuery の全ての高度な機能を直接、より効率的に利用できるようになりました。
ネイティブ統合による追加機能のメリットの要約
今回のネイティブ統合により 12 の追加機能が提供されました。これらの機能は、以下の5つのカテゴリーに分類することが可能です。
各機能の詳細については、後述の追加機能の解説のセクションで紹介します。それぞれの番号は、追加機能の解説セクション内の番号と対応しています。
高度なデータモニタリング
- INFORMATION_SCHEMAのフルサポート
- 実行グラフのフルサポート
- Cloud Monitoring 指標のフルサポート
- BI Engine アクセラレーションの使用状況の監視が可能に
大規模データセットの分析強化
クエリのパフォーマンスの向上
- クエリキューの同時処理が可能に
- マテリアライズドビューのスマートチューニングが可能に
- クエリ結果のキャッシュの改善
データのセキュリティ担保と効率的な分析
- オーソライズドビューに対する接続が可能に
データ分析の範囲と深度の拡大
- ネストされた繰り返し列を含むテーブルにアクセス可能に
- BigQueryでサポートされている分析関数の利用が可能に
追加機能の解説
1. INFORMATION_SCHEMA のフルサポート
-
概要
INFORMATION_SCHEMA は BigQuery における様々なメタデータを検索するために提供された一連のビュー群です。取得できるメタデータの一覧はBigQuery のドキュメントで確認することができます。 -
嬉しいこと
以前は INFORMATION_SCHEMA.JOBS ビューにクエリを実行しても、発行元の Looker Studio レポートは特定することが出来ませんでした。しかし、今回 Private Preview となった BigQuery native integration in Looker Studio により発行元のレポート(report_id)と データソース(datasource_id)の情報が追加取得出来るようになり、レポート毎および データソース毎の課金額の調査 が容易にできるようになりました。 -
関連ドキュメント・記事
BigQuery INFORMATION_SCHEMA の概要
JOBS ビューのスキーマ
2. 実行グラフのフルサポート
-
概要
クエリ実行グラフとは、クエリパフォーマンス向上のためのヒントを簡単に得ることができる機能のことです。
具体的には、以下のようなことができます。- クエリ全体の処理の流れをグラフィカルに確認することができます。処理時間が長い部分やスロット時間が長い部分をハイライト表示することができるため、潜在的なボトルネックの同定に役立てることができます。
- クエリパフォーマンスを確認するために有効な指標を得ることができます。
- クエリパフォーマンス低下の問題が発生している可能性がある場合、考えられる具体的な要因(クエリパフォーマンスの洞察)を提示してもらうことができます。
-
嬉しいこと
実行グラフのフルサポートについての具体的な変更点についての記載はなかったので、個人的に触って確かめてみたところ以下の点が改善されているように見えました。( 確定情報ではありませんので参考までに )
以前は Looker Studio 経由のクエリジョブの実行グラフを確認しても、各ステージが具体的にどのような操作(JOIN、GROUP BY など)を行っているかは明示的に表示されていませんでしたが、BigQuery native integration in Looker Studio によって、これらの情報が明示的に表示されているように見えました。
なので、よりクエリ処理のボトルネックの同定がしやすくなった可能性があります。 -
関連ドキュメント・記事
クエリ実行グラフを使用した BigQuery 分析クエリのトラブルシューティングと最適化
BigQueryのクエリ実行グラフを使って、クエリパフォーマンス向上のためのヒントを得る
3. Cloud Monitoring 指標のフルサポート
-
概要
Cloud Monitoring を使用すると、さまざまな指標をグラフ化してモニタリングできます。
具体的には、次のような疑問に対する回答を得ることが可能です。- グラフ化してモニタリングできるもの
- 検出されたオブジェクトの数とバイト数
- コピーされたオブジェクトの数とバイト数
- 削除されたオブジェクトの数とバイト数
- エラーの数とそれに関連するエラーコード
-
嬉しいこと
こちらについても変更点に関する具体的な説明が無かったので、個人的に触ってみました。やはり嬉しいのは、Looker Studio が BigQuery に統合された結果、Cloud Monitoring の Logging でクエリの発行元やレポートの情報を確認できるようになったことでしょう。具体的には、データソースID(looker_studio_datasource_id)、レポートID(looker_studio_report_id)、およびリクエスト元(requestor) の情報が提供されます。
また、後述する BI Engine による高速化に関する指標も取得できるようになったため、BI Engine の使用の監視、診断、トラブルシューティングが容易になりました。 -
関連ドキュメント・記事
Cloud Monitoring の概要
Looker Studio の INFORMATION_SCHEMA の詳細を表示する
BI Engine アクセラレーションモード
4. BI Engine アクセラレーションの使用状況の監視が可能に
-
概要
BigQuery BI Engine は、頻繁に使用するデータをインテリジェントにキャッシュに保存することで、Looker Studio を含むデータ可視化ツールからの BigQuery に対する SQL クエリを加速する高速なメモリ内分析サービスです。 -
嬉しいこと
これまでも Looker Studio は BI Engine が有効化されたテーブルに接続することは可能でしたが、 BI Engine の使用状況の監視は出来ませんでした。
しかし今回のリリースにより、BI Engine のクエリ高速化に関する情報(bi_engine_statistics.acceleration_mode) が取得できるようになったことで、クエリの高速化の確認が出来るようになりました。
BI Engine のクエリ高速化に関する情報は BigQuery INFORMATION_SCHEMA ビューに含まれているので、下記のようなクエリで取得することができます。
SELECT
creation_time,
job_id,
bi_engine_statistics.acceleration_mode
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
AND CURRENT_TIMESTAMP()
AND job_type = "QUERY"
クエリ高速化に関する情報(bi_engine_statistics.acceleration_mode)には次の4つのパターンが存在します。
| bi_engine_statistics.acceleration_mode | 説明 |
|---|---|
| BI_ENGINE_DISABLED | BIエンジンは高速化を無効にし、クエリはBigQuery実行エンジンを使用して実行されました。詳細な理由はbiEngineReasonsで指定されます。 |
| PARTIAL_INPUT | クエリ入力の一部がBIエンジンを使用して高速化されました。クエリが複数の入力ステージで構成され、そのうちの一部だけがBIエンジンのサポート対象である場合、BIエンジンは高速化なしで通常のBigQueryエンジンを使用してサポート対象外のステージを実行します。この状況では、BIエンジンはPARTIALアクセラレーションコードを返し、biEngineReasonsを使用して他の入力ステージが高速化されない理由を設定します。 |
| FULL_INPUT | クエリのすべての入力段階がBIエンジンを使用して高速化されました。 |
| FULL_QUERY | クエリ全体がBIエンジンを使用して高速化されました。 |
-
留意事項
- BI Engine の予約をする際に指定するロケーションは、クエリするデータセットのロケーションと一致する必要がある。
- クエリでワイルドカードを使用している場合には、BI Engine による高速化の恩恵を受けない。
-
関連ドキュメント・記事
BI Engineとは
BI Engine のクエリ統計
BI Engine の有効化と Looker Studio からの接続手順
5. テーブルサイズの緩和
-
概要
BigQuery native integration in Looker Studio により、接続先の BigQuery のテーブルに関する制限が BigQuery の標準テーブルの制限と同等になりました。これにより、テーブルごとの最大列数が 10,000 列という制約以外は存在しなくなりました。 -
嬉しいこと
より大きなテーブルを扱うことが可能になり、データ分析の範囲が広がります。 -
関連ドキュメント・記事
クォータと制限のリファレンス テーブル
6. パーティション制限の緩和
-
概要
BigQuery native integration in Looker Studio により、接続先の BigQuery のテーブルに関する制限が BigQuery の標準テーブルの制限と同等になりました。これにより、パーティションテーブルあたり最大 4,000 パーティションまで含めることができるようになりました。 -
嬉しいこと
より大規模なデータセットを効率的に管理することを可能にします。これにより、データのクエリパフォーマンスが向上し、分析の精度とスピードが向上します。 -
関連ドキュメント・記事
クォータと制限のリファレンス パーティション化されたテーブル
7. クエリキューの同時処理が可能に
-
概要
BigQuery のクエリキューを使用したクエリの同時実行は、利用可能なコンピューティング リソースに基づいて複数のデータクエリを一度に効率的に処理する能力を提供します。 -
嬉しいこと
今回のリリースによって、クエリキューの同時処理が可能になったため、データ分析の効率性と速度の大幅な向上が見込めます。複数のクエリを同時に実行することで、全体の待機時間が短縮され、結果をより早く取得できます。 -
関連ドキュメント・記事
クエリキューを使用する
BigQuery クエリキューの概要まとめ
8. マテリアライズドビューのスマートチューニングが可能に
-
概要
Looker Studio が接続先としてマテリアライズドビューを使用する場合、BigQuery はスマートチューニング機能により、自動的にクエリを最適化し、可能な限りマテリアライズドビューを活用します。この機能により、Looker Studio とマテリアライズドビューの間のデータ取得が効率化されます。 -
嬉しいこと
マテリアライズドビューを使用することでクエリの結果に影響を与えることなく、クエリのパフォーマンスを向上させることができます。 -
関連ドキュメント・記事
マテリアライズド(実体化)ビューの概要
マテリアライズドビュー スマートチューニング
9. クエリ結果のキャッシュの改善
-
概要
Looker StudioがBigQueryにネイティブ統合されることで、Looker のクエリ結果は BigQuery のキャッシュメカニズムにより管理されるようになりました。 -
嬉しいこと
この変化により、同じクエリが再度実行される際には、BigQueryはキャッシュされた結果を直接提供することが可能になり、クエリの実行時間が大幅に短縮されます。これにより、ユーザーはより早く結果を取得することができ、データ分析の効率性とパフォーマンスが向上します。さらに、BigQuery の効率的なキャッシュ管理により、システムのリソース使用も最適化されます。
10. オーソライズドビューに対する接続が可能に
-
概要
BigQuery のオーソライズドビューは、特定のユーザーやグループがデータセットにアクセスできるように設定されたビューです。これにより、データの所有者は、データのセキュリティを維持しながら、他のユーザーが必要なデータにアクセスできるようにすることができます。 -
嬉しいこと
ユーザーは Looker から直接オーソライズドビューにアクセスし、必要なデータを安全に取得することができます。これは、データのセキュリティを保ちつつ、データ分析の効率性と便利性を向上させる大きなメリットを提供します。 -
関連ドキュメント・記事
オーソライズドビュー
11. ネストされた繰り返し列を含むテーブルにアクセス可能に
-
概要
BigQuery では、単一のレコード内で複数の値を持つことができる特殊な列タイプがあり、これを「繰り返し列」または「配列」と呼びます。さらに、これらの繰り返し列が他のフィールド(列)を含む場合、それらは「ネストされた」列となります。これにより、より複雑なデータ構造を単一のテーブル内で表現することが可能になります。 -
嬉しいこと
ユーザーはより複雑なデータ構造を直接扱うことができ、データ分析の範囲と深度が大幅に拡大します。また、これらの複雑なデータ構造をフラットなテーブルに変換する必要がなくなり、データの準備と処理の時間を節約することができます。 -
関連ドキュメント・記事
ネストされた繰り返し列
12. BigQuery でサポートされている分析関数の利用が可能に
-
概要
Looker Studio で BigQuery ネイティブ統合した場合に、ネイティブ関数( NATIVE_DIMENSION ) を使用できるようになりました。NATIVE_DIMENSION 関数を使用すると、Looker Studio のフィールドに SQL を直接記述できるようになります。 -
嬉しいこと
これまでは Looker Studio の計算フィールドの数式内でしか使えない関数リストによる簡易なデータ処理しか出来ませんでしたが、NATIVE_DIMENSION 関数の登場により、BigQuery でサポートされているJSON 関数を含む多数の関数による複雑なデータ処理が可能になりました。 -
関連ドキュメント・記事
NATIVE_DIMENSION
料金
Looker Studio の BigQuery ネイティブ統合による追加課金はありません。
BigQuery および BigQuery BI Engine の使用料金はBigQuery の料金に従います。
プレビュー版 BigQuery native integration in Looker Studio の申請方法
現在(2023年11月20日時点)で、BigQuery native integration in Looker Studio はプレビュー機能です。
このプレビュー機能へのアクセスをリクエストするには、Looker Studio での BigQuery ネイティブ統合プレビューのサインアップ フォームに本機能を有効化したいプロジェクトIDを記載し、申請をしてください。
リクエストが承認されると、BigQuery native integration in Looker Studio が有効化され各種機能が使えるようになります。
気になった機能を試してみた
INFORMATION_SCHEMA でレポート毎の課金対象バイト数を取得してみた
やること
BigQuery native integration in Looker Studio により、新たに取得できるようになった発行元のレポート(report_id)とデータソース(datasource_id)を活用して、レポート毎の課金対象バイト数(total_bytes_billed) を調査する。
INFORMATION_SCHEMA.JOBS の解説
まず、公式ドキュメントに記載されているサンプルコードを実行して、Looker Studio の INFORMATION_SCHEMA の詳細を表示しましょう。
CREATE TEMP FUNCTION GetLabel(labels ANY TYPE, label_key STRING)
AS (
(SELECT l.value FROM UNNEST(labels) l WHERE l.key = label_key)
);
SELECT
job_id,
CONCAT("https://lookerstudio.google.com/datasources/", GetLabel(labels, "looker_studio_datasource_id")) AS datasource_link,
CONCAT("https://lookerstudio.google.com/reporting/", GetLabel(labels, "looker_studio_report_id")) AS report_link,
FROM
`region-us`.INFORMATION_SCHEMA.JOBS jobs
WHERE
creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
AND GetLabel(labels, 'requestor') = 'looker_studio'
LIMIT
100;
BigQuery ネイティブ統合が有効になっている場合、すべての Looker Studio クエリは、report_id ラベルと datasource_id ラベルを持つエントリを作成します。これらは、LookerStudio の URL の末尾に表示される ID ですので、上記のクエリを使用することでリンクにマッピングできます。
クエリ結果は以下のようなものになります。
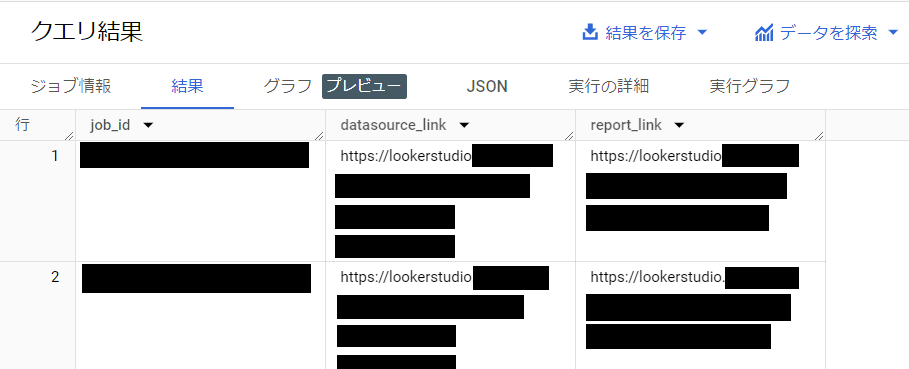
クエリ結果の各カラムの解説は以下です。
| 列名 | 意味 |
|---|---|
| job_id | BigQuery ジョブに振られる一意の ID |
| datasource_link | クエリ発行元の Looker Studio データソースのリンク |
| report_link | クエリ発行元の Looker Studio レポートのリンク |
レポート毎の課金バイト数を取得するクエリ
次に、課金対象バイト数(total_bytes_billed)をレポート毎に集計するクエリを紹介します。
CREATE TEMP FUNCTION GetLabel(labels ANY TYPE, label_key STRING)
AS (
(SELECT l.value FROM UNNEST(labels) l WHERE l.key = label_key)
);
SELECT
CONCAT("https://lookerstudio.google.com/reporting/", GetLabel(labels, "looker_studio_report_id")) AS report_link,
SUM(total_bytes_billed) AS total_bytes_billed
FROM
`region-us`.INFORMATION_SCHEMA.JOBS jobs
WHERE
creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND GetLabel(labels, 'requestor') = 'looker_studio'
GROUP BY
report_link
ORDER BY
total_bytes_billed DESC
これで過去30日間のレポート毎の合計の課金対象バイト数を降順で取得することができます。
以下のような結果が返ります。
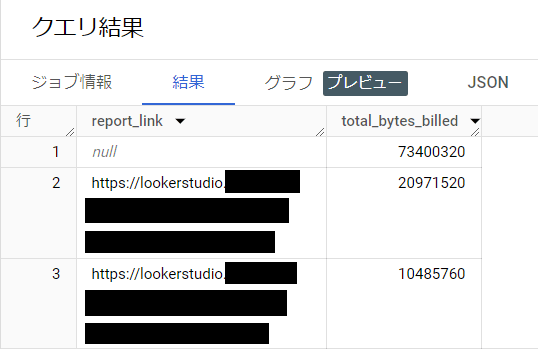
検証結果
この方法で、簡単に BigQuery 課金のボトルネックとなるレポートを同定することができました。
BigQuery の課金体系がオンデマンドの場合は、課金対象バイト数(total_bytes_billed) にオンデマンドクエリ単価をかけることで利用料金が算出できます。
- 関連ドキュメント・記事
BigQuery Pricing
利用可能になったウィンドウ関数で前年度の売上を取得してみた
やること
新機能の NATIVE_DIMENSION 関数を使用することで、Looker Studio の追加フィールド作成時に SQL を直接記述できるようになりました。
ここでは、 BigQuery に「年月」と「売上」の2つのカラムを持つ検証用テーブルを作成し、Looker Studio の NATIVE_DIMENSION にてウィンドウ関数を使用し、「前年同月の売上」フィールドを作成してみようと思います。
NATIVE_DIMENSION の使い方
- Looker Studio での BigQuery ネイティブ統合プレビューのサインアップ フォームに申請してネイティブ統合を有効化する。
- データソース エディタの右上にある [ネイティブ関数] をクリックする。
- [ネイティブ関数] ダイアログで、[オン] を選択する。
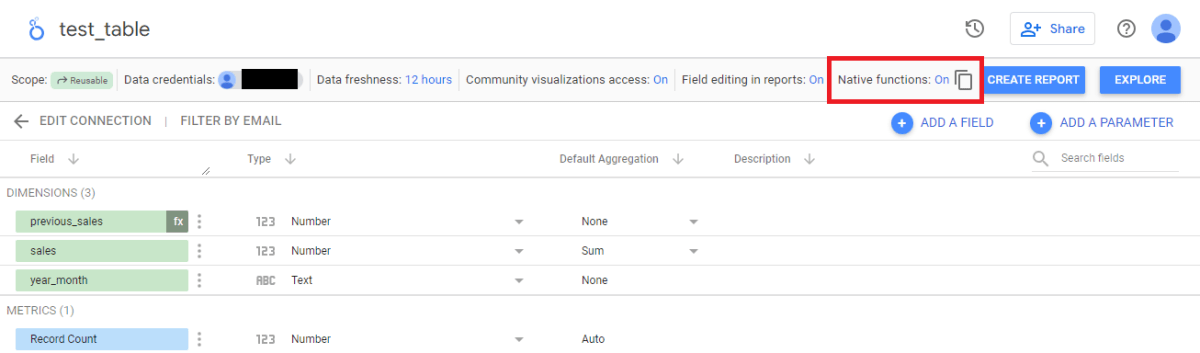
詳細はネイティブ関数の有効化を参照。
前年度の売り上げを取得する NATIVE_DIMENSION の検証手順
- Looker Studio での BigQuery ネイティブ統合プレビューのサインアップ フォームに申請してネイティブ統合を有効化します。
- テスト用に、「年月(year_month)」と「売上(sales)」の2つのカラムからなるテーブルを作成する。
使用したクエリは下記です。(※使用する際は、1行目のyour_datasetは各自のデータセット名に置き換えて下さい)
CREATE OR REPLACE TABLE your_dataset.test_table AS
WITH date_range AS (
SELECT
FORMAT_TIMESTAMP("%Y-%m", TIMESTAMP(DATE(year, month, 1))) AS year_month
FROM
UNNEST(GENERATE_ARRAY(2019, 2022)) AS year,
UNNEST(GENERATE_ARRAY(1, 12)) AS month
),
sales_data AS (
SELECT
year_month,
CAST(FLOOR(RAND() * 1000) AS INT64) AS sales
FROM
date_range
)
SELECT * FROM sales_data
- Looker Studio でデータソースを作成し、2.で作成したテーブル(test_table)に接続する。
- データソース エディタの右上にある [ネイティブ関数] をクリックする。
- [ネイティブ関数] ダイアログで、[オン] を選択する。
- [フィールドの追加] から、以下のクエリを記述して
previous_salesという関数名で保存する。
NATIVE_DIMENSION("LAG(sales, 12) OVER (ORDER BY year_month)" , "INT64")
上記のように NATIVE_DIMENSION(expression, type) という構文で記述します。
expression には、SELECT 文の1つの列に入る任意の有効な BigQuery SQL を指定できます。
このクエリでは、sales 列の値を 12 行前に戻します。つまり、現在の行の sales 値が何であれ、12 ヶ月前のsales 値を取得します。
- [CREATE REPORT] をクリックする。
-
year_month、sales、previous_salesを Dimension に指定しテーブルチャートを作成する。
検証結果
描画を試みた結果、下記のように「ウィンドウ関数で生成したカラムを GROUP BY 句に指定するな」という旨のクエリエラーが返ってきてしまいました。
Column t0_qt_reipgtxtcd contains an analytic function, which is not allowed in GROUP BY at [1:194]
Looker Studio の仕様上、 Dimension にフィールドを指定すると、集計の軸として SQL の GROUP BY 句に自動的に組み込まれるので、上記のエラー生じるようです。
結論、 NATIVE_DIMENSION ではウィンドウ関数は使えませんでした。
Google Cloudの公式ドキュメントを読んだところ、ウィンドウ関数が使えそうな記載があったので試してみましたが無理でした。
Looker Studioの公式ドキュメント曰く、あらゆるウィンドウ関数が NATIVE_DIMENSION で使用できないと制限事項に書いてあるので、こちらの記載が正しいことが今回の検証で分かりました。
もし、ウィンドウ関数を使用したい場合は、今まで通りデータソースを作成する際にカスタムクエリを選択して、ウィンドウ関数を記述してカラムを生成するのが良いと思います。
- 関連ドキュメント・記事
カスタムクエリを使用して接続する
Looker Studioの公式ドキュメントに記載されている使用例
下記のような JSON_VALUE 関数を使用した例が紹介されています。
-
フィールド名:
users_ages_json -
users_ages_jsonのデータ構造:{"name": "Jakob", "age": "26"} -
NATIVE_DIMENSIONの記述
NATIVE_DIMENSION("JSON_VALUE(user_ages_json, '$.age')","INT64")
この例の行の値では、NATIVE_DIMENSION は年齢 26 を整数として返します。
まとめ
今回の記事では、Looker Studio のネイティブ統合機能である BigQuery native integration in Looker Studio についてご紹介しました。この新機能のリリースにより、以下の5つのメリットを享受でき、Looker Studio の使い勝手が大幅に向上しました。現在はプレビュー段階ですが、ぜひお試しください。
- 高度なデータモニタリング
- 大規模データセットの分析強化
- クエリのパフォーマンスの向上
- データのセキュリティ担保と効率的な分析
- データ分析の範囲と深度の拡大
Discussion