BigQueryのクエリ実行グラフを使って、クエリパフォーマンス向上のためのヒントを得る
はじめに
こんにちは、クラウドエース データML ディビジョン所属の松山です。
データML ディビジョンでは、Google Cloud が提供しているデータ領域のプロダクトについて、新規リリースをキャッチアップするための調査報告会を毎週実施しています。
新規リリースの中でも、特に重要と考えるリリースを記事としてまとめ、本ページのように公開しています。
リリース内容
今回ご紹介するリリースは2023年6月12日付に一般提供(GA)されたBigQueryの「クエリ実行グラフ」という機能についてです。
リリースノート
クエリ実行グラフを活用することで、クエリパフォーマンス向上のためのヒントを簡単に得ることができます。
BigQueryの概要
BigQueryとは、Google Cloud が提供しているDWH(データウェアハウス)サービスの一つです。DWH(データウェアハウス)とは、データ分析に特化したデータベースのことを指します。BigQueryでは、SQLクエリを記述することによって、データ分析を実行できます。
クエリ実行グラフの概要
クエリ実行グラフとは、クエリパフォーマンス向上のためのヒントを簡単に得ることができる機能のことです。
具体的には、以下のようなことができます。
- クエリ全体の処理の流れをグラフィカルに確認することができます。処理時間が長い部分やスロット時間が長い部分をハイライト表示することができるため、潜在的なボトルネックの特定に役立てることができます。
- クエリパフォーマンスを確認するために有効な指標を得ることができます。
- クエリパフォーマンス低下の問題が発生している可能性がある場合、考えられる具体的な要因(クエリパフォーマンスの洞察)を提示してもらうことができます。
クエリ実行グラフの開き方
クエリ実行グラフの開き方は、クエリ実行のタイミングが「直前の場合」と「過去の場合」で手順が異なります。
以下の各セクションにて、それぞれの場合の開き方を説明します。
クエリ実行のタイミングが直前の場合
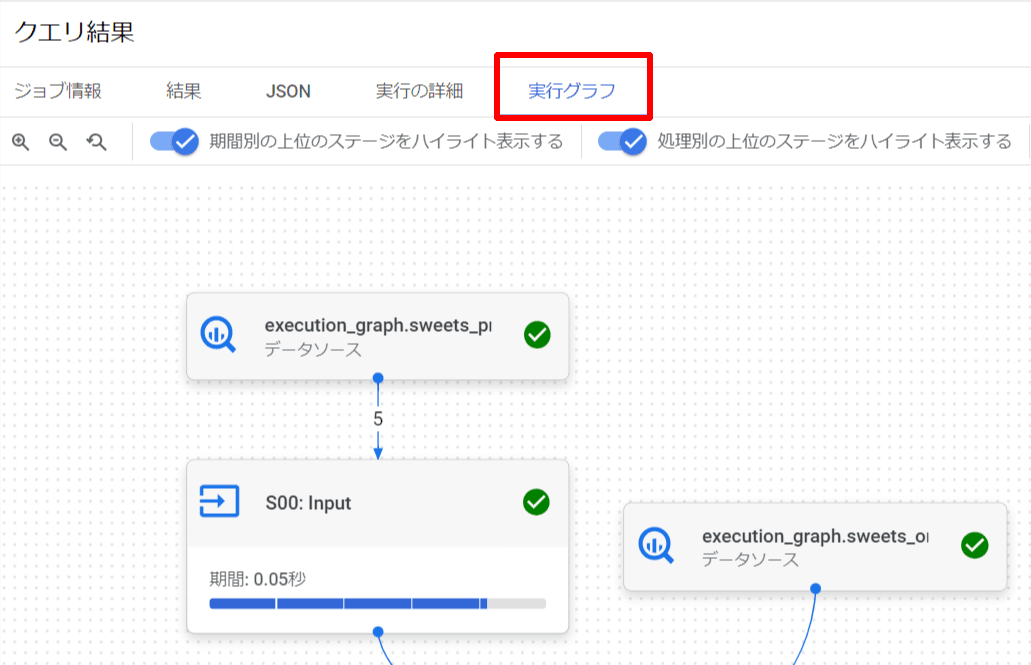
- Google Cloud コンソールでBigQueryを開きます。
- クエリを実行します。
- クエリ結果から「実行グラフ」を開きます。
クエリ実行のタイミングが過去の場合
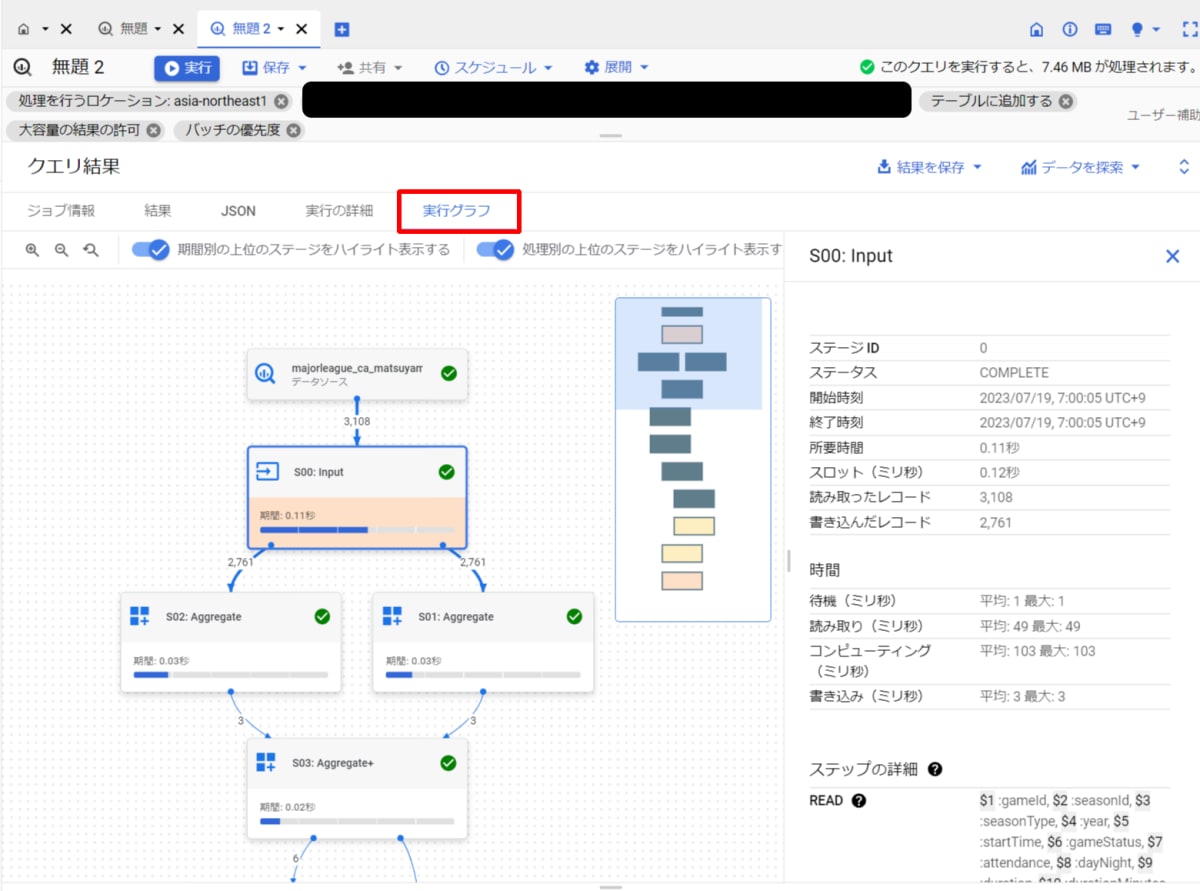
- Google Cloud コンソールでBigQueryを開きます。
- エディタで、「個人履歴」または「プロジェクト履歴」を選択します。

- クエリ実行グラフを開きたいジョブの「操作」から「クエリをエディタで開く」をクリックします。

- 「実行グラフ」を開きます。
ハイライトの表示方法
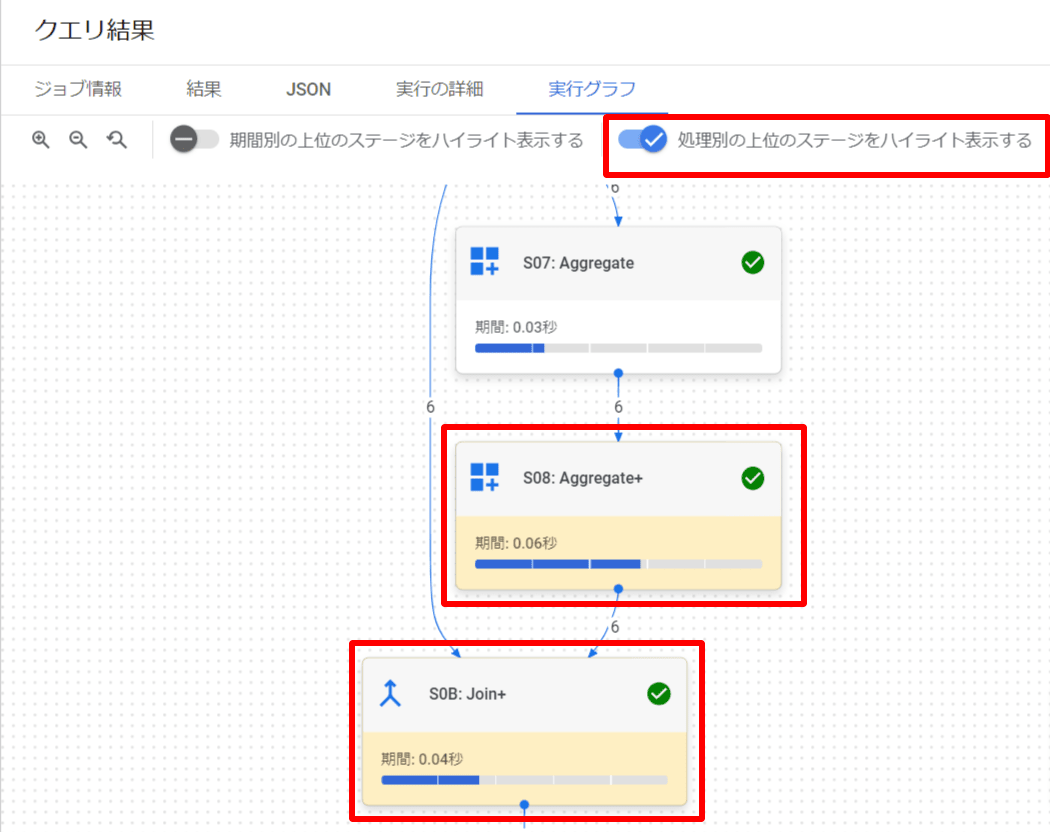
クエリ実行グラフでは、ボトルネックとなっている部分(「処理時間が長い部分」と「スロット時間が長い部分」)をハイライト表示することができます。
以下の各セクションにて、それぞれのハイライト表示方法を説明します。
処理時間が長い部分のハイライト表示
「期間別の上位のステージをハイライト表示する」をクリックしてください。

スロット時間が長い部分のハイライト表示
「処理別の上位のステージをハイライト表示する」をクリックしてください。
クエリ実行グラフにて確認できる指標
実行グラフの各ステージ(クエリ処理の単位)を選択すると、選択したステージの詳細を確認することができます。
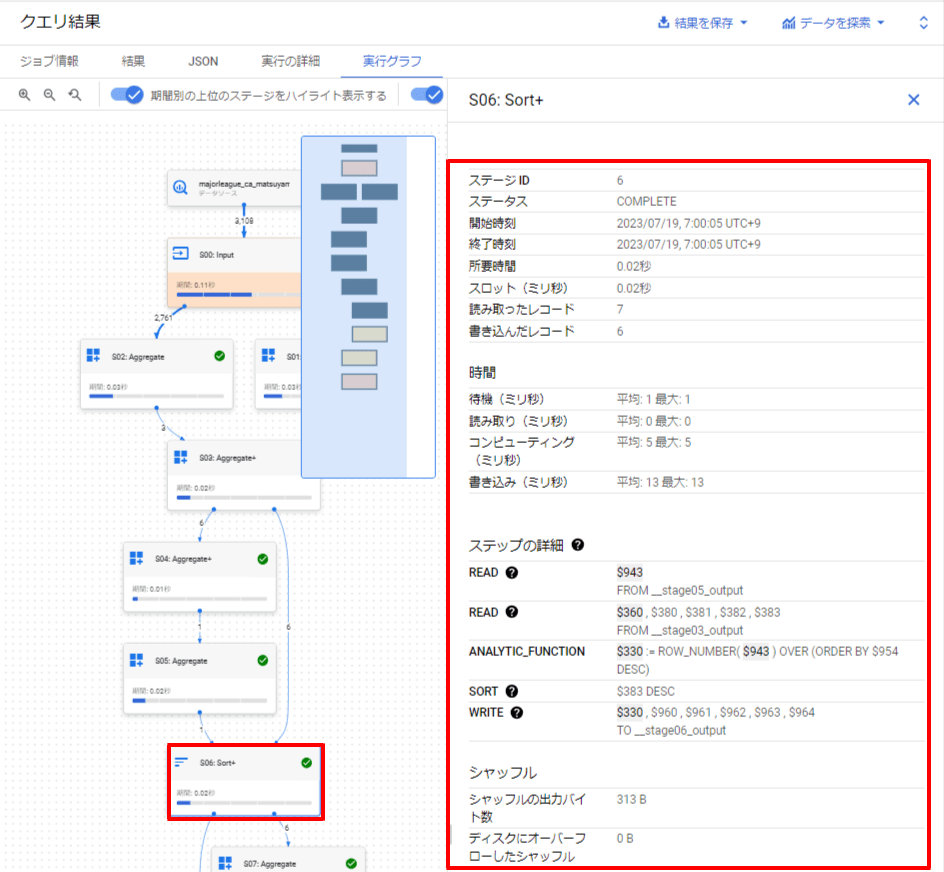
詳細にて取得できる各指標の説明は、以下リンクに掲載されています。
指標の説明
指標の解釈
指標のうち、以下の指標はクエリパフォーマンスに問題がないか確認するために注目すべき指標です。
- 待機(ミリ秒)
- シャッフルの出力バイト数
以下の各セクションにて、それぞれの指標の意味と解釈の仕方を説明します。
待機(ミリ秒)
-
意味
待機(ミリ秒)とは、ワーカーがスケジュールされるまでの待ち時間のことです。 -
解釈の仕方
待機(ミリ秒)が、以前の実行結果と比較して高くなった場合、スロット数が十分かどうかを確認してください。 スロットとは、クエリを実行するための仮想CPUのことです。スロット数が十分でない場合、負荷分散を行なってください。
待機(ミリ秒)が、他のステージと比べて高い場合、その前のステージの詳細を調べ、ボトルネックが発生していないかどうかを確認してください。
クエリに含まれるテーブルのデータやスキーマに対する大幅な変更などが影響を与えている可能性があります。
シャッフルの出力バイト数
- 意味
シャッフルの出力バイト数とは、ワーカーで発生した書き込みの合計バイト数のことです。 - 解釈の仕方
シャッフルの出力バイト数が、以前の実行結果と比較して、または前のステージと比較して高い場合、予期せぬ大量データの作成が発生している可能性があります。
よくある原因の一つは、結合キーが重複しているテーブル同士のINNER JOINです。本ページ最後のセクションに、結合キーが重複しているテーブル同士をINNER JOINした場合のシャッフルの出力バイト数を確認する検証を載せています。
クエリパフォーマンスの洞察
クエリパフォーマンスの洞察とは、クエリパフォーマンスの低下を発生させていると考えられる具体的な要因のことです。
クエリパフォーマンスの洞察がある場合、処理ボックスの右上に、下図のようなiマークがつきます。
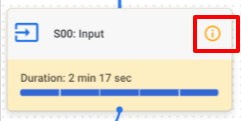
iマークがついているボックスを選択すると、詳細の上部にてクエリパフォーマンスの洞察を確認することができます。
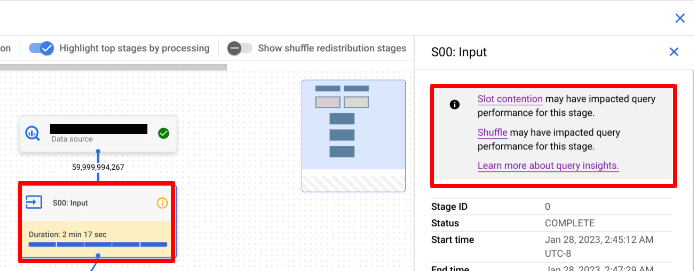
クエリパフォーマンスの洞察の種類
クエリパフォーマンスの洞察には以下の3種類があります。
- スロット競合
- シャッフル割り当て不足
- データ入力スケールの変更
それぞれのクエリパフォーマンスの解決方法は、「アナリストの場合」と「管理者の場合」で分けて説明します。
ここでの「アナリスト」と「管理者」の定義は以下です。
-
アナリスト
プロジェクト内で実行したクエリのパフォーマンス向上を考えている人のことを指します。実行グラフを使うために必要な権限を持っています。 -
管理者
組織のBigQueryリソースと予約を管理している人のことを指します。BigQuery管理者ロールの権限を持っています。
以下の各セクションにて、それぞれのクエリパフォーマンスの洞察の意味と解決方法を説明します。
スロット競合
-
意味
クエリ実行のために十分なスロットを確保できなかったことを示しています。
スロットとは、クエリを実行するための仮想CPUのことです。 -
解決方法
- アナリストの場合
以下リンクのガイダンスに従って、クエリで処理するデータを削減してください。
クエリで処理するデータの削減 - 管理者の場合
以下のアクションを実行して、スロットの可用性を増やすか、スロットの使用量を減らしてください。- 予約の購入を検討してください。予約の購入によって、組織専用のスロットを予約できるようになります。
- すでに予約を使用している場合、予約に十分なスロットがあることを確認してください。確認には 管理リソースチャートやスロット推定ツールが使えます。
確認の結果、スロットが不十分であることがわかった場合、以下のいずれかのアクションを実行してください。- 予約にスロットを追加してください。
- 追加の予約を作成し、クエリを実行しているプロジェクトに割り当ててください。
- リソースを大量に消費するクエリを、予約内で時間の経過とともに、または異なる予約にわたって分散してください。
- クエリを実行しているテーブルがクラスタ化されていることを確認してください。クラスタリングは、BigQueryが相関データを含む列を迅速に読み取ることができるようにするのに役立ちます。
- クエリを実行しているテーブルがパーティションかされていることを確認してください。パーティション分割がされていないテーブルの場合、BigQueryはテーブル全体を読み取るため、負荷が高くなってしまいます。テーブルをパーティション化すると、必要なデータのみを読み取ることができるようになります。
- アナリストの場合
シャッフル割り当て不足
-
意味
シャッフルに書き込む必要があるデータ量がシャッフルの容量を超えてしまったことを示しています。
シャッフルとは、クエリの中間結果を保存する領域のことです。後続の処理は、シャッフルからデータを読み取って行ないます。 -
解決方法
- アナリストの場合
以下リンクのガイダンスに従って、クエリで処理するデータ量を削減してください。
クエリで処理するデータ量の削減
シャッフルを多く使用する傾向があるJOINやGROUP BYの操作を減らすと、シャッフルの使用量が減る可能性があります。 - 管理者の場合
以下のアクションを実行して、シャッフルクォータの競合を減らしてください。- 予約の購入を検討してください。予約の購入によって、組織専用のスロットを予約できるようになります。
- すでに予約を使用している場合、予約に十分なスロットがあることを確認してください。確認には 管理リソースチャートやスロット推定ツールが使えます。
確認の結果、スロットが不十分であることがわかった場合、以下のいずれかのアクションを実行してください。- 予約にスロットを追加してください。
- 追加の予約を作成し、クエリを実行しているプロジェクトに割り当ててください。
- リソースを大量に消費するクエリを、予約内で時間の経過とともに、または異なる予約にわたって分散してください。
- アナリストの場合
データ入力スケールの変更
-
意味
最後にクエリを実行したときと比べて、クエリの速度低下が発生していること(データを少なくとも50%多く読み取っていること)を示しています。
クエリで使用しているデータの増加は、テーブルの変更履歴にて確認できます。 -
解決方法
- アナリストの場合
以下リンクのガイダンスに従って、クエリで処理するデータ量を削減してください。
クエリで処理するデータの削減 - 管理者の場合
なし。
- アナリストの場合
検証
結合キーが重複していないテーブル同士をINNER JOINした場合と、結合キーが重複しているテーブル同士をINNER JOINした場合のシャッフル出力バイト数を比較します。
- サンプルテーブルの作成
サンプルテーブルの作成のため、以下クエリを実行してください。
CREATE OR REPLACE TABLE <project>.execution_graph.sweets_noDup AS (
SELECT 1 item_num, "cake" item_name, 500 price UNION ALL
SELECT 2, "pudding", 350 UNION ALL
SELECT 3, "zenzai", 300 UNION ALL
SELECT 4, "ice", 250 UNION ALL
SELECT 5, "cookie", 150
order by item_num
);
CREATE OR REPLACE TABLE <project>.execution_graph.sweets_Dup AS (
SELECT 1 item_num, "cake" item_name, 500 price UNION ALL
SELECT 1, "cake", 500 UNION ALL
SELECT 2, "pudding", 350 UNION ALL
SELECT 2, "pudding", 350 UNION ALL
SELECT 3, "zenzai", 300 UNION ALL
SELECT 3, "zenzai", 300 UNION ALL
SELECT 4, "ice", 250 UNION ALL
SELECT 4, "ice", 250 UNION ALL
SELECT 5, "cookie", 150 UNION ALL
SELECT 5, "cookie", 150
order by item_num
);
CREATE OR REPLACE TABLE <project>.execution_graph.sweets_order AS (
SELECT 101 order_num, 1 item_num, 2 quantity UNION ALL
SELECT 101, 2, 1 UNION ALL
SELECT 102, 3, 2 UNION ALL
SELECT 102, 5, 1 UNION ALL
SELECT 103, 1, 2 UNION ALL
SELECT 103, 3, 1 UNION ALL
SELECT 103, 5, 2 UNION ALL
SELECT 104, 2, 1 UNION ALL
SELECT 104, 4, 5 UNION ALL
SELECT 104, 1, 2 UNION ALL
SELECT 104, 3, 3 UNION ALL
SELECT 105, 5, 2 UNION ALL
SELECT 105, 4, 1 UNION ALL
SELECT 106, 4, 2 UNION ALL
SELECT 107, 1, 1 UNION ALL
SELECT 107, 3, 3 UNION ALL
SELECT 107, 5, 4 UNION ALL
SELECT 107, 1, 1 UNION ALL
SELECT 107, 3, 3 UNION ALL
SELECT 108, 5, 2 UNION ALL
SELECT 108, 4, 5 UNION ALL
SELECT 109, 1, 2 UNION ALL
SELECT 109, 3, 3 UNION ALL
SELECT 109, 5, 2 UNION ALL
SELECT 109, 4, 4
ORDER BY order_num
);
上記クエリの実行によって、以下のサンプルテーブル①・②・③を作成することができます。
- サンプルテーブル①
商品番号(item_num)と名前(item_name)と値段(price)がまとまっているテーブルです。レコードの重複はありません。
| item_num | item_name | price |
|---|---|---|
| 1 | cake | 500 |
| 2 | pudding | 350 |
| 3 | zenzai | 300 |
| 4 | ice | 250 |
| 5 | cookie | 150 |
- サンプルテーブル②
サンプルテーブル①と同じく、商品番号(item_num)と名前(item_name)と値段(price)がまとまっているテーブルです。レコードが重複してしまっています。
| item_num | item_name | price |
|---|---|---|
| 1 | cake | 500 |
| 1 | cake | 500 |
| 2 | pudding | 350 |
| 2 | pudding | 350 |
| 3 | zenzai | 300 |
| 3 | zenzai | 300 |
| 4 | ice | 250 |
| 4 | ice | 250 |
| 5 | cookie | 150 |
| 5 | cookie | 150 |
- サンプルテーブル③
オーダー番号(order_num)と商品番号(item_num)と数量(quantity)がまとまっているテーブルです。
| order_num | item_num | quantity |
|---|---|---|
| 101 | 1 | 2 |
| 101 | 2 | 1 |
| 102 | 3 | 2 |
| 102 | 5 | 1 |
| 103 | 1 | 2 |
| 103 | 3 | 1 |
| 103 | 5 | 2 |
| 104 | 2 | 1 |
| 104 | 4 | 5 |
| 104 | 1 | 2 |
| 104 | 3 | 3 |
| 105 | 5 | 2 |
| 105 | 4 | 1 |
| 106 | 4 | 2 |
| 107 | 1 | 1 |
| 107 | 3 | 3 |
| 107 | 5 | 4 |
| 107 | 1 | 1 |
| 107 | 3 | 3 |
| 108 | 5 | 2 |
| 108 | 4 | 5 |
| 109 | 1 | 2 |
| 109 | 3 | 3 |
| 109 | 5 | 2 |
| 109 | 4 | 4 |
- 結合キーが重複していないサンプルテーブルの結合
サンプルテーブル①と③をINNER JOINを使って結合します。
結合には、item_numをキーとして使います。
SELECT *
FROM
`execution_graph.sweets_order`
INNER JOIN
`execution_graph.sweets_noDup`
USING (item_num)
;
結果は下表の通りです。
| item_num | order_num | quantity | item_name | price |
|---|---|---|---|---|
| 1 | 101 | 2 | cake | 500 |
| 2 | 101 | 1 | pudding | 350 |
| 3 | 102 | 2 | zenzai | 300 |
| 5 | 102 | 1 | cookie | 150 |
| 1 | 103 | 2 | cake | 500 |
| 3 | 103 | 1 | zenzai | 300 |
| 5 | 103 | 2 | cookie | 150 |
| ~以下略~ |
-
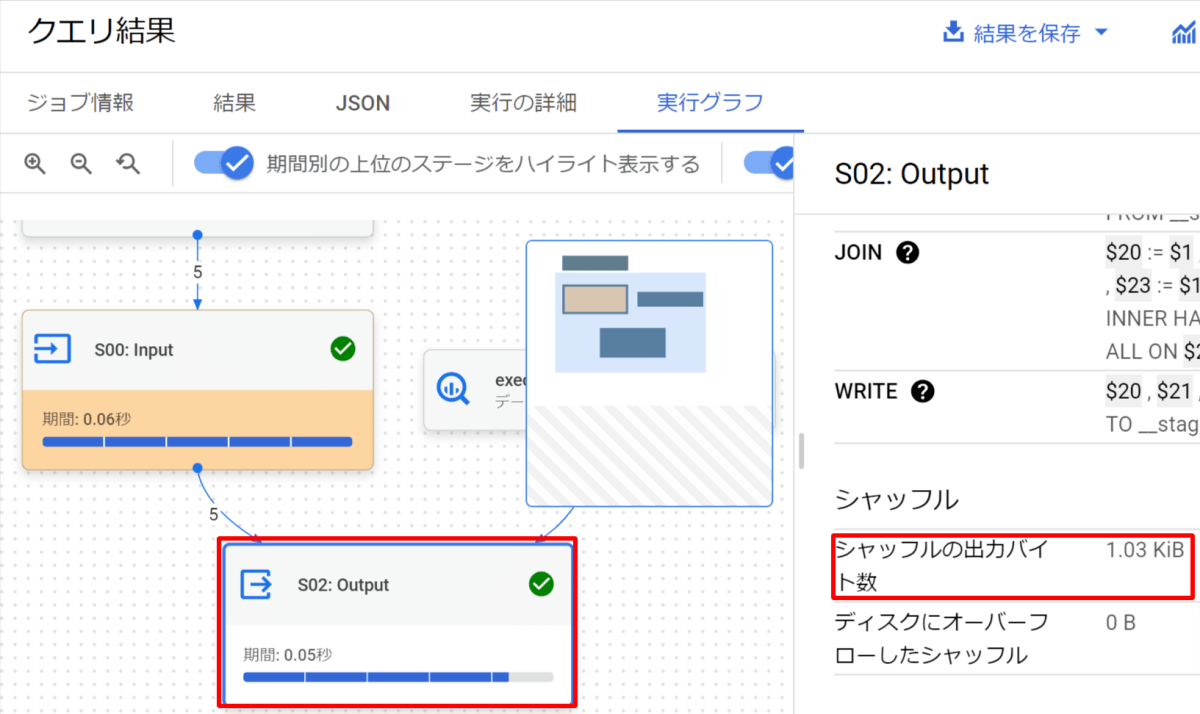
実行グラフの確認
実行グラフを確認します。シャッフル出力バイト数は「1.03KiB」でした。ちなみに、1KiB=1024バイトです。
-
結合キーが重複しているサンプルテーブルの結合
サンプルテーブル②と③をINNER JOINを使って結合します。
結合には、item_numをキーとして使います。
SELECT *
FROM
`execution_graph.sweets_order`
INNER JOIN
`execution_graph.sweets_Dup`
USING (item_num)
;
結果は下表の通りです。
レコードが重複して作成されてしまっていることがわかります。
| item_num | order_num | quantity | item_name | price |
|---|---|---|---|---|
| 1 | 101 | 2 | cake | 500 |
| 1 | 101 | 2 | cake | 500 |
| 2 | 101 | 1 | pudding | 350 |
| 2 | 101 | 1 | pudding | 350 |
| 3 | 102 | 2 | zenzai | 300 |
| 3 | 102 | 2 | zenzai | 300 |
| 5 | 102 | 1 | cookie | 150 |
| 5 | 102 | 1 | cookie | 150 |
| 1 | 103 | 2 | cake | 500 |
| 1 | 103 | 2 | cake | 500 |
| 3 | 103 | 1 | zenzai | 300 |
| 3 | 103 | 1 | zenzai | 300 |
| 5 | 103 | 2 | cookie | 150 |
| 5 | 103 | 2 | cookie | 150 |
| ~以下略~ |
-
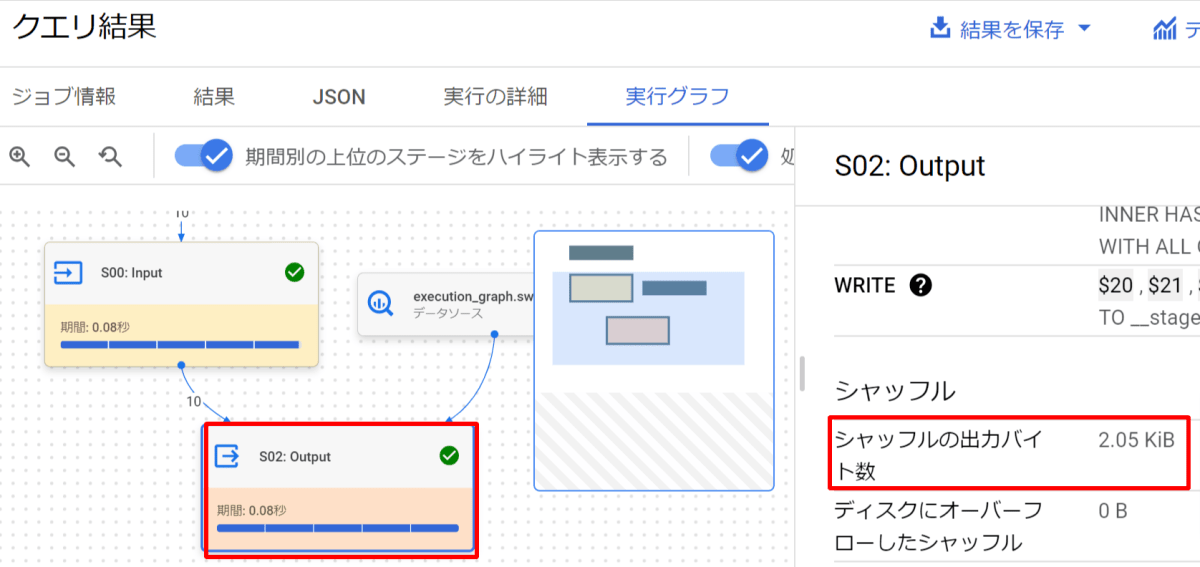
実行グラフの確認
実行グラフを確認します。シャッフル出力バイト数は「2.05KiB」でした。
処理時間が長いことを意味するハイライトが赤く変わっていることも見て取れます。
-
検証のまとめ
検証の結果、結合キーが重複しているテーブル同士をINNER JOINした場合、シャッフルの出力バイト数が大きくなってしまうことが確認できました。
- 結合キーが重複していないテーブル同士をINNER JOINした場合:1.03KiB
- 結合キーが重複しているテーブル同士をINNER JOINした場合:2.05KiB
まとめ
BigQueryのクエリ実行グラフについてのご紹介は以上です。
一番伝えたかったことは、クエリ実行グラフは、クエリパフォーマンス向上を考える上で有効な機能であるということです。
ぜひご活用いただき、今までよりもパフォーマンスの高い素敵なクエリの作成を考えてみてください!
Discussion