Dataproc Serverless でテンプレートを利用したバッチ処理を実行する
はじめに
こんにちは、クラウドエース データML ディビジョン所属の松本です。
クラウドエースのITエンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータML ディビジョンです。
データML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、Dataproc の「Dataproc Serverless テンプレート」についてです。
このリリースにより、Dataproc Serverless でテンプレートを利用したバッチ処理を作成することが可能になりました。
Dataproc Serverless とは

Dataproc Serverless とは、Apache Spark や Apache Hadoop などのオープンソースデータ処理フレームワークを使用して、大規模なデータ処理を行うためのフルマネジードサービスです。
サーバーレスであるため、クラスタの管理やスケーリングなどのタスクをユーザーが行う必要がなく、必要なリソースを自動的に割り当て、ワークロードを実行します。
今回のリリースについて
今回ご紹介するのは、Dataproc Serverless テンプレート という、Dataproc Serverless のバッチ処理用のテンプレートに関して、既存のテンプレートに加え、新たに5つのテンプレートが提供されたことについてです。(2023年6月26日付に発表)
リリース概要
Dataproc Serverless テンプレートの追加提供について
Dataproc Serverless テンプレート を使用すると、コードを記述することなく、Spark でのバッチ処理をすばやく実行できます。
このテンプレートは Java と Python の両方で提供されています。
今回のリリースにより、以下のテンプレートが新たに追加されました。
- Cloud Storage to BigQuery
- Cloud Storage to Cloud Spanner
- Hive to Cloud Storage
- JDBC to BigQuery
- JDBC to Cloud Storage
その他にも、以下のテンプレートが提供されています。(2023年8月15日時点)
- Cloud Spanner to Cloud Storage
- Cloud Storage to Cloud Storage
- Cloud Storage to JDBC
- Hive to BigQuery
- JDBC to Cloud Spanner
- JDBC to JDBC
- Pub/Sub to Cloud Storage
ユースケース
Dataproc Serverless テンプレートのユースケースとしては、以下などが挙げられます。
- コードを記述することなく、一般的な Spark バッチワークロードをすばやく実行したい
- Dataproc Serverless の利点を活かし、大規模なデータのバッチワークロードをすばやく実行したい
- Hive などの Hadoop 上の分散ストレージにあるデータの処理をすばやく実行したい
- Spark に関して詳しくないが、Dataproc Serverless でのデータパイプラインを構築したい
Dataflow テンプレートとの違い
Google Cloud では Dataflow というフルマネージドでサーバレスな分散処理サービスがあり、
Dataflow にも、Dataproc Serverless テンプレートと似たような Google 提供のテンプレート が用意されています。
現状、Dataflow の方が提供されているテンプレート数が多く、ストリーミング処理用のテンプレートも提供されているため、多くのケースでは、Dataflow テンプレートでも要件を満たすことができます。
しかし、Dataflow テンプレートにはHiveに関するテンプレートなど、一部提供されていないものもあるため、そういったテンプレートを利用した場合は、Dataproc Serverless テンプレートを活用できます。
また、Dataproc Serverless テンプレートでは、Spark SQL を利用してのデータ変換が可能なため、SQLでデータ変換処理を実装したい場合は適しています。
(尚、Dataflow の Google 提供テンプレートでは、JavaScript でユーザー定義関数を記述することにより、データ変換が可能です。)
試してみた
今回は、Dataproc Serverless テンプレートである GCS To BigQuery を利用して、GCS から BigQuery への簡易なETLパイプラインを実装してみたい思います。
1. Dataproc Serverless のステージング用 GCS バケットの作成
Dataproc Serverless のステージング場所として使用する GCS バケットを作成します。
Dataproc Serverless はこのバケットを使用して、サーバーレスクラスタの実行に必要な依存関係を保存します。
$ export TEMP_BUCKET=my-staging-bucket
$ gsutil mb -l asia-northeast1 gs://$TEMP_BUCKET
2. インプットデータの準備
インプットとなる csv ファイルを作成します。
item_id,sales,datetime
item01,1.23,2023-01-01 00:00:00
item02,2.34,2023-01-02 00:00:00
GCS バケットを作成し、csv ファイルをアップロードします。
$ export INPUT_BUCKET=my-input-bucket
$ gsutil mb -l asia-northeast1 gs://$INPUT_BUCKET
$ gsutil cp test.csv gs://$INPUT_BUCKET
3. VPC ネットワークのデフォルト サブネットに対する Google 公開アクセスの許可
今回は、Dataproc の VPC ネットワークのサブネットをデフォルトで使用しますが、事前に、Google 公開アクセスをオンにしておく必要があります。
$ gcloud compute networks subnets update default --region=asia-northeast1 --enable-private-ip-google-access
4. Dataproc Serverless のジョブを実行する
gcloud コマンドを使用して、Dataproc Serverless ジョブを実行します。
以下のコマンドでは、Spark SQL を使用してデータを変換した後、BigQueryへデータを格納しています。
$ PROJECT_ID=my_project
$ REGION=asia-northeast1
$ TEMPLATE_VERSION=latest
$ CLOUD_STORAGE_PATH=gs://$INPUT_BUCKET/test.csv
$ FORMAT=csv
$ DATASET=my_dataset
$ TABLE=my_table
$ TEMPVIEW=my_data
$ SQL_QUERY="select item_id, cast(round(sales, 0) as int) as sales, cast(datetime as date) as date from global_temp.my_data"
$ gcloud dataproc batches submit spark \
--class=com.google.cloud.dataproc.templates.main.DataProcTemplate \
--version="1.1" \
--project="$PROJECT_ID" \
--region="$REGION" \
--jars="gs://dataproc-templates-binaries/$TEMPLATE_VERSION/java/dataproc-templates.jar" \
-- --template=GCSTOBIGQUERY \
--templateProperty project.id="$PROJECT_ID" \
--templateProperty gcs.bigquery.input.location="$CLOUD_STORAGE_PATH" \
--templateProperty gcs.bigquery.input.format="$FORMAT" \
--templateProperty gcs.bigquery.output.dataset="$DATASET" \
--templateProperty gcs.bigquery.output.table="$TABLE" \
--templateProperty gcs.bigquery.temp.bucket.name="$TEMP_BUCKET" \
--templateProperty gcs.bigquery.temp.table="$TEMPVIEW" \
--templateProperty gcs.bigquery.temp.query="$SQL_QUERY"
上記コマンドでは、以下のジョブ構成を指定しています。
| 変数名 | 説明 |
|---|---|
| PROJECT_ID | Dataproc Serverless を実行する GCP プロジェクト |
| REGION | Dataproc Serverless を実行するリージョン |
| TEMP_BUCKET | Dataproc Serverless のステージング用 GCS バケットの場所 |
| CLOUD_STORAGE_PATH | インプットとなる GCS バケット内の csv ファイルのURI |
| FORMAT | インプットのデータ形式( avro、parquet、csv、json )を指定 |
| DATASET | BigQuery の宛先データセット |
| TABLE | BigQuery の宛先テーブル |
| TEMPVIEW | (省略可)Spark SQL でのデータ変換における、一時ビュー名 |
| SQL_QUERY | (省略可)Spark SQL でのデータ変換における、クエリステートメント ※TEMPVIEW と SQL_QUERY のテーブル名が一致する必要があります |
尚、データ変換は以下のクエリ文を指定することで行なっています。
$ SQL_QUERY="select item_id, cast(round(sales, 0) as int) as sales, cast(datetime as date) as date from global_temp.my_data"
- item_id:変換なし
- sales:元の値を小数点第1位で四捨五入し、int 型に変換
- datetime:date 型に変換し、カラム名を date に変更
参考
テンプレート実行方法の詳細は、以下をご参考ください。
Spark SQL に関しての詳細は、以下をご参考ください。
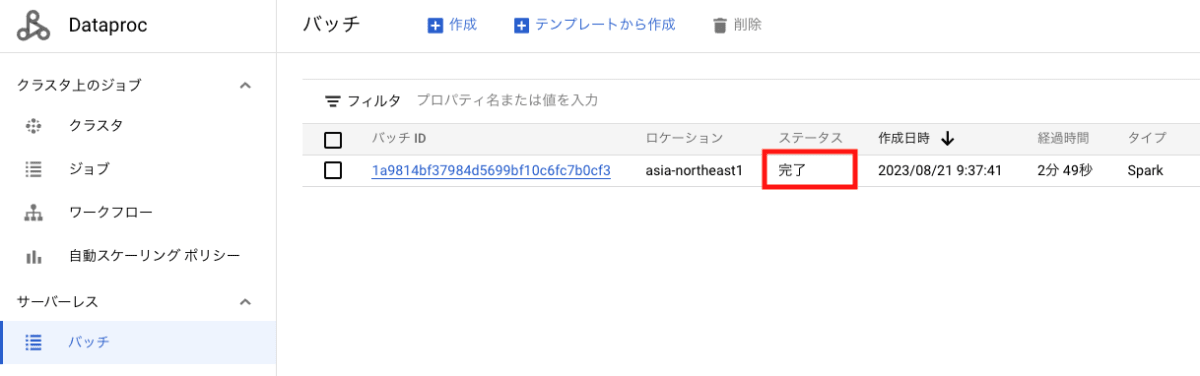
5. Dataproc Serverless のジョブ結果確認
Dataproc Serverless バッチのコンソールより、ジョブが完了していることを確認します。
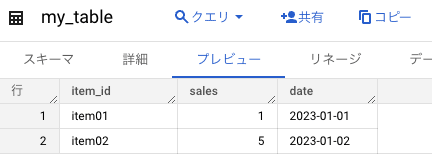
BigQuery コンソールにて、指定した宛先テーブルにデータが格納されていることを確認します。
出力結果として、データ変換が想定通りに実施されていることが分かります。

まとめ
今回の記事では、Dataproc Serverless テンプレートについてご紹介しました。
このリリースにより、Dataproc Serverless テンプレートよって、コードを記述することなく、Spark バッチワークロードをすばやく実行できるようになりました。
Dataproc Serverless でのデータパイプラインをすばやく構築したい場合に、便利な方法になりますので、是非ご活用ください。
Discussion