Dataproc Serverlessを利用してPySparkを触ってみた
はじめに
こんにちは、クラウドエース データ/MLディビジョン所属の金です。
前回はDataprocを利用してJupyter notebook上、PySparkでデータ処理を試してみました。
そこで一つ残念だったのがやはりクラスタ管理が面倒なことでした。
今回はDataproc Serverlessを利用して前回面倒だったクラスタ管理などもせずにPySparkでデータ処理を試してみます。
前回の記事が気になる方は下記のURLからご覧ください。
Dataproc Serverless とは?

Apache SparkやApache Hadoopなどのオープンソースデータ処理フレームワークを使用して、大規模なデータ処理を行うためのフルマネジードサービスです。
サーバーレスであるため、クラスタの管理やスケーリングなどのタスクをユーザーが行う必要がなく、必要なリソースを自動的に割り当てて、データ処理のタスクを実行します。
ネットワーク構成
Dataproc Serverlessでは限定公開のGoogleアクセスを有効にしたサブネットワークとクラスタ内での通信を許可するファイアウォールルール設定が必要です。
defaultはなるべく触りたくなかったので今回は新しいVPCを作成します。
- VPC ネットワークの作成
$ gcloud compute networks create <NETWORK NAME> \
--project=<PROJECT NAME> \
--subnet-mode=custom \
--mtu=1460 \
--bgp-routing-mode=regional
- サブネットを作成
$ gcloud compute networks subnets create <NETWORK SUBNET NAME> \
--project=<PROJECT NAME> \
--range=10.128.0.0/20 \
--network=<NETWORK NAME> \
--region=<REGION> \
--enable-private-ip-google-access
IPアドレス範囲は default ネットワークの us-central1 サブネットに合わせました。
- ファイアウォールルール設定
gcloud compute firewall-rules create <FIREWALL NAME> \
--direction=INGRESS \
--priority=65534 \
--network=<NETWORK NAME> \
--action=ALLOW \
--rules=tcp:0-65535,udp:0-65535,icmp \
--source-ranges=10.128.0.0/9 \
--project=<PROJECT NAME>
IPアドレス範囲は default の default-allow-internal に合わせました。
詳しい内容は下記のURLをご覧ください。
VPCとファイアウォール作成確認
VPC ネットワークとファイアウォールタブをクリックすると先ほど作成したVPCとファイアウォールルールが確認できます。
Dataproc Serverless バッチ
やりたいこと
- Serverless バッチを利用してPySpark処理(GCS to GCS, GCS to BQ)
- Serverless バッチを利用してPySpark処理(Jupyter notebookファイル)
事前準備
- テスト用のバケットとその下にフォルダを作成します。
<BUCKET> -- <INPUT FOLDER> -- <CSV FILE>
|
-- <OUTPUT FOLDER>
|
-- <SOURCE FOLDER> -- <PYTHONとNOTEBOOK FILES>
<BQ TEMP BUCKET>
- BQにDATASETを作成します。
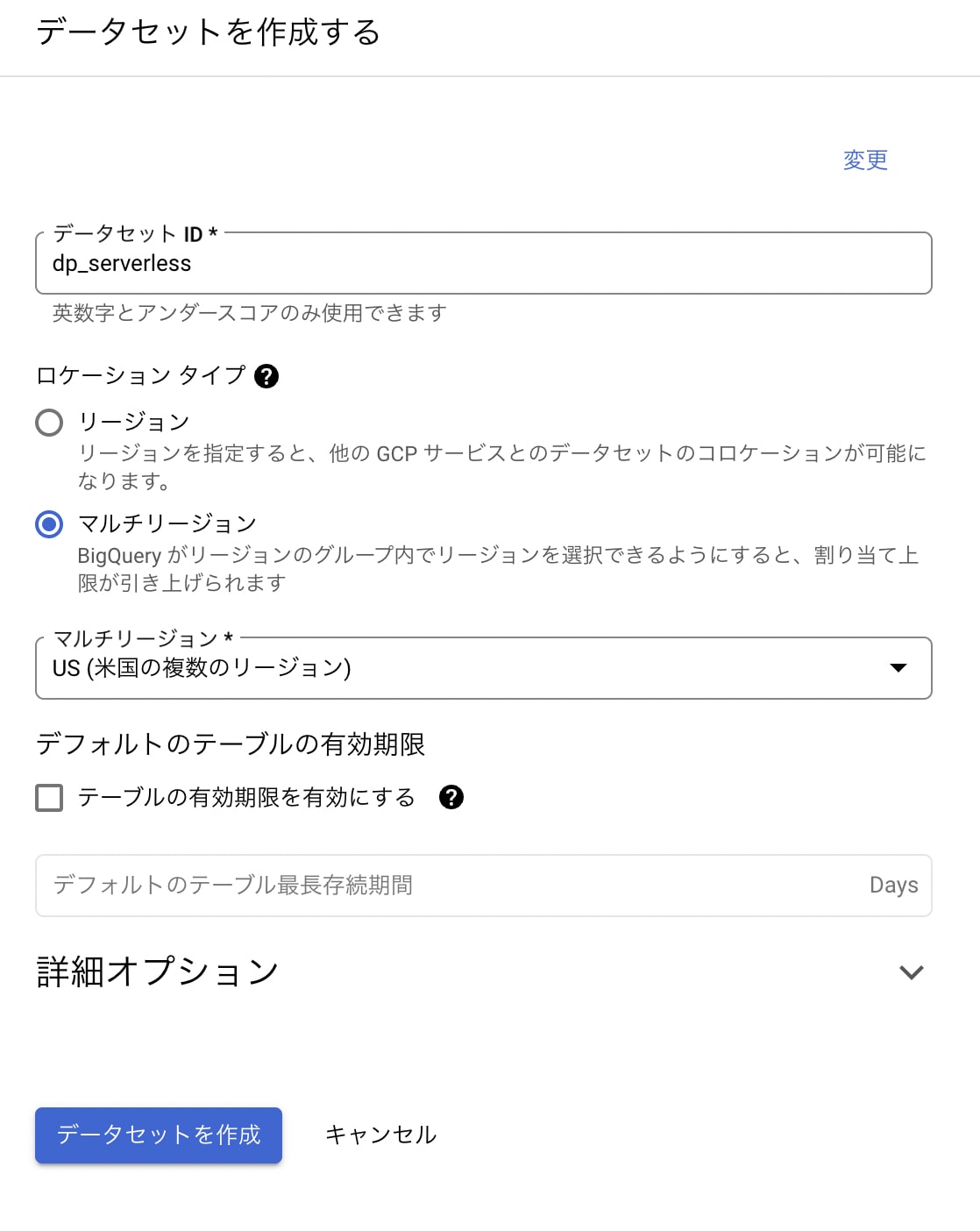
Serverless バッチを利用してPySpark処理(GCS to GCS, GCS to BQ)
- CSVファイルを作成してINPUTフォルダに格納します。
id,mail,name,date
1,aaa@aaaaa.jp,Alice,2016-08-27
2,bbb@bbbbb.jp,Bob,2016-08-27
3,ccc@ccccc.jp,Charlie,2016-08-27
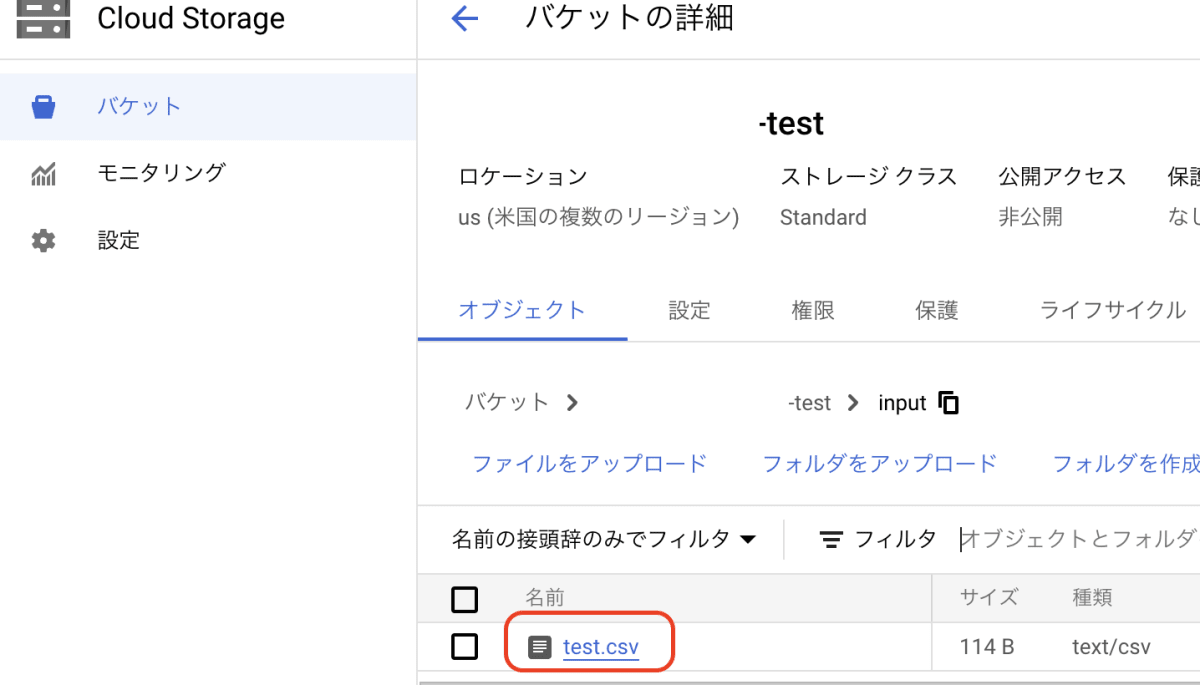
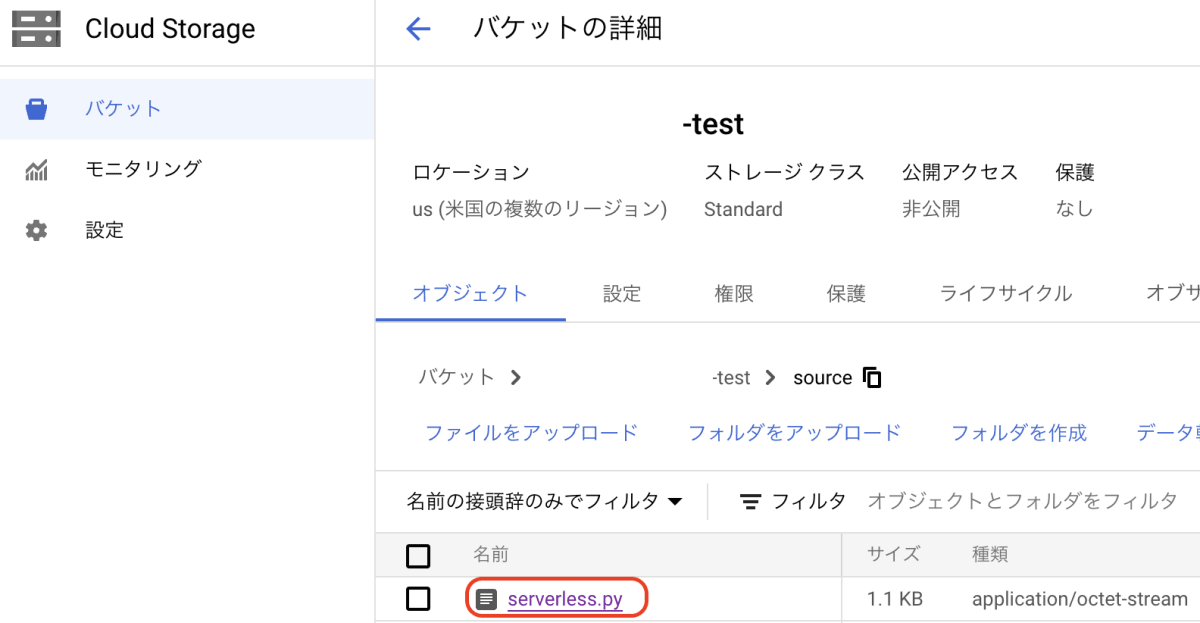
- PySparkコードを作成してSOURCEフォルダに格納します。
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
# Spark設定
conf = SparkConf().setAppName("ReadFromGcs")
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
# GCS上のデータをヘッダ付きで取り込む
df = spark.read.csv("gs://<YOUR BUCKET>/input/test.csv", header=True, inferSchema=True)
# 結果を表示する
df.show()
# schemaを確認する
df.printSchema()
# filter条件追加(idが1,2のみ)
df2 = df[df.id.isin(1,2)]
# GCSにCSV形式でデータ保存
df2.write \
.format("csv") \
.mode('overwrite') \
.option("header", "True") \
.save("gs://<YOUR BUCKET>/output/")
# BQへ書き込む
df2.write \
.format('bigquery') \
.option('table', '<YOUR DATASET>.<YOUR TABLE NAME>') \
.option("temporaryGcsBucket","<YOUR TEMP BUCKET>") \
.option("createDisposition", "CREATE_IF_NEEDED") \
.save()
- Dataproc サーバーレス バッチタブでバッチ作成をします。
- バッチID : 適切な名を入力します。
- リージョン :
us-central1にします。 - バッチタイプ : PySparkを選択します。
- メインのPythonファイル : 先ほど格納したPythonファイルのURIを入力します。
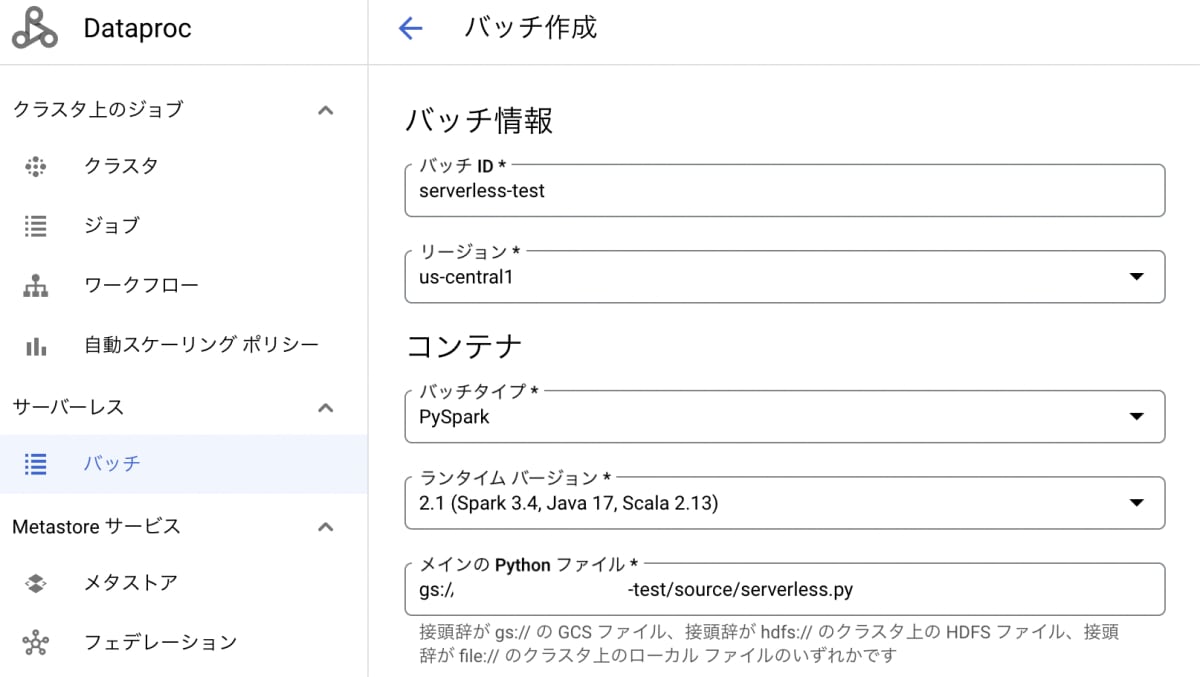
下にスクロールをすると「ネットワーク構成」に最初作成したネットワークが表示されているのが確認できます。

- SUBMITボタンを押すとバッチが実行されます。
- 処理が完了したらGCSとBQを確認します。
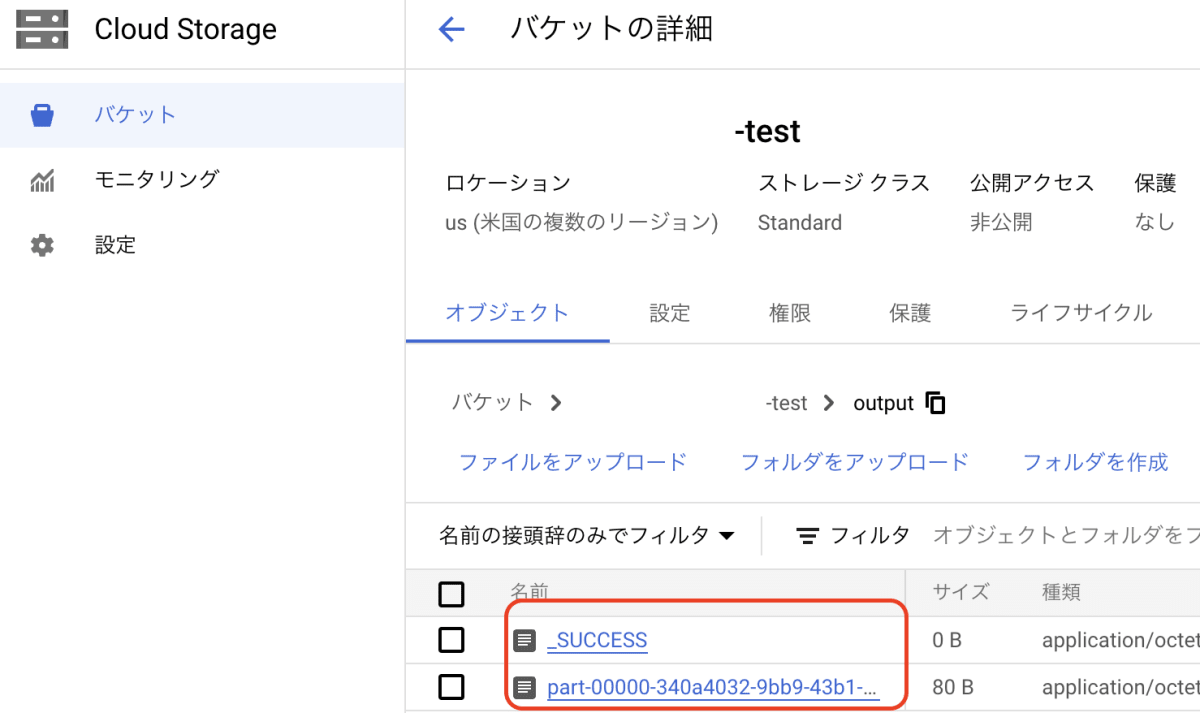
GCS保存は問題ないですね!

BQにも問題なくIDが1と2のデータのみ保存されました!
もちろんコマンドでも実行できます。
gcloud beta dataproc batches submit \
--project <YOUR PROJECT NAME> \
--region <YOUR REGION> pyspark \
--batch <BATCH NAME> gs://<YOUR BUCKET>/source/serverless.py \
--subnet <YOUR SUBNET NAME>
Serverless バッチを利用してPySpark処理(Jupyter notebookファイル)
Jupyter Notebook(.ipynb)ファイルも実行できますが少し追加する部分があります。
- Notebook(.ipynb)ファイル呼び出し用Pythonファイルを作成してSOURCEフォルダに格納します。
import argparse
import re
from google.cloud.storage.client import Client
import papermill as pm
import sys
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
'input',
metavar='input',
type=str,
help='GCS URI location of the input notebook')
parser.add_argument(
'output',
metavar='output',
type=str,
help='GCS URI location of the output executed notebook')
args = parser.parse_args()
# Download input notebook and params file from GCS
# Note that papermill supports gcsfs by default, but some type of dependency
# problem appears to prevent this from working out of the box on 2.0 images
gcs = Client()
params = {}
print('Reading notebook from "%s"' % args.input)
with open('input.ipynb', 'wb') as f:
gcs.download_blob_to_file(args.input, f)
pm.execute_notebook(
'input.ipynb','output.ipynb', kernel_name='python3',log_output=True, progress_bar=False, stdout_file=sys.stdout, parameters=params)
# Annoyingly, the GCS client libraries don't seem to expose a helper function
# to extract the bucket directly, so do this by hand
matched = re.match('gs://([^/]+)/(.+)', args.output)
if not matched:
raise ValueError('Invalid output URI: "%s"' % args.output)
print('Writing result to "%s"' % args.output)
bucket = gcs.get_bucket(matched.group(1))
blob = bucket.blob(matched.group(2))
blob.upload_from_filename('output.ipynb')
if __name__ == '__main__':
main()
- 実行用Notebook(.ipynb)ファイルを作成してSOURCEフォルダに格納します。
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
# Spark設定
conf = SparkConf().setAppName("ReadFromGcs")
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
# GCS上のデータをヘッダ付きで取り込む
df = spark.read.csv("gs://<YOUR BUCKET NAME>/input/test.csv", header=True, inferSchema=True)
# 結果を表示する
df.show()
# schemaを確認する
df.printSchema()
# filter条件追加(idが1,2)
df2 = df[df.id.isin(1,2)]
# 結果を表示する
df2.show()
# IDとnameのみ
df3 = df2[["ID","name"]]
# barで表示(ただクラフを見せるため)
df3.toPandas().plot.bar(x="name", y="ID")
メインPythonコードに引数としてinput, outputを渡します。
inputは処理するnotebookのファイル、outputは結果として吐き出すnotebookのファイルです。
コマンドで実行します。
gcloud beta dataproc batches submit \
--project <YOUR PROJECT NAME> \
--region <YOUR REGION> pyspark \
--subnet <YOUR SUBNET NAME> \
--batch <BATCH NAME> gs://<YOUR BECKET NAME>/source/serverless_executor.py \
-- gs://<YOUR BECKET NAME>/source/serverless_jupyter.ipynb gs://<YOUR BECKET NAME>/output/serverless_jupyter_output.ipynb
処理完了後、OUTPUTフォルダに生成されているnotebookファイルの中身を確認すると、実行結果が表示されているのを確認できます。
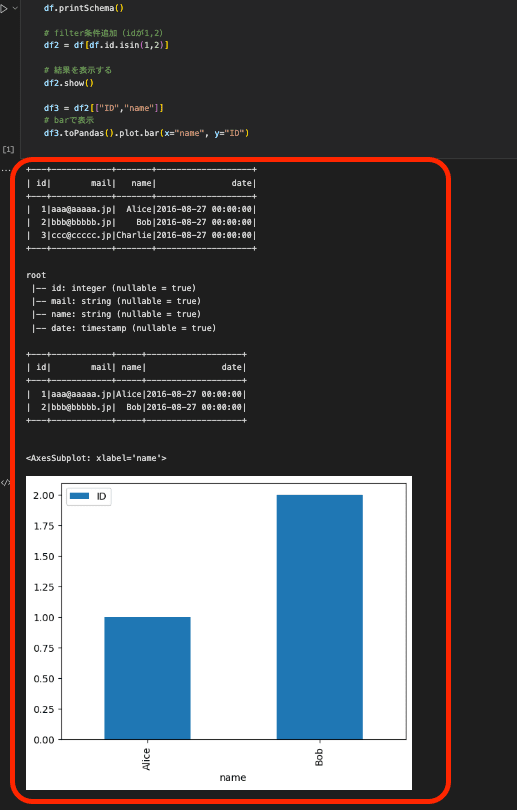
グラフなども表示されるのでデータ分析を定期的にする場合便利そうですね!
終わりに
今回はDataproc ServerlessでPySparkを利用する方法を試してみました。Dataprocはクラスタハンドリングに注意する必要がありましたが、Serverlessはクラスタ処理が要らないのでかなり便利だと思いました。
料金的には少し高くなるかも知れないですが、処理の複雑さは軽くなるので気になる方はぜひ試してみてください!
なお、Dataproc Serverlessはオートスケーリングも自動的に割り当てるらしいのです。
特にTerasortを利用したオートスケーリングパフォーマンステストもオートスケーリング確認方法として面白かったので気になる方は確認してください。
Discussion