BigQuery × Apache Iceberg で実現するデータレイクハウス構築
はじめに
こんにちは、クラウドエース データソリューション部の松本です。
普段はデータ基盤や機械学習システムの構築を行なっており、Google Cloud 認定トレーナーとしてトレーニング提供もしています。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回は、BigQuery と Apache Iceberg の統合による Google Cloud 上でのデータレイクハウス構築方法についてご紹介します。
この記事はこんな人にオススメ
- BigQuery と Apache Iceberg を統合する方法を知りたい方
- BigLake を利用したデータレイクハウス構築について知りたい方
- Apache Iceberg について知りたい方
データレイクハウスとは
データレイクハウス(またはレイクハウス)とは、データレイクとデータウェアハウスの機能を組み合わせた新しいタイプのデータプラットフォームです。
大量の構造化、半構造化、非構造化データを一元的に管理し、必要に応じて高度な分析ができるため、企業はデータの取り扱いをより柔軟にし、より深い洞察を得ることが可能になります。
データレイクハウスの詳細に関しては、以下の記事で紹介しておりますので、ぜひご覧ください。
オープンテーブルフォーマットとは
データレイクハウスを実現するには、データレイクの柔軟性を維持しつつ、データウェアハウスと同等の機能を提供する必要があります。それを実現するための技術として注目されているのが、オープンテーブルフォーマット(Open Table Format、OTF)です。
オープンテーブルフォーマットは、データレイク上で ACID トランザクション、UPSERT、DELETE といった操作を可能にし、構造化データを管理するためのオープンソースのファイルフォーマットです。代表的なオープンテーブルフォーマットとして、Apache Iceberg、Apache Hudi、Delta Lake が挙げられます。
オープンテーブルフォーマットには以下の特徴があり、従来のファイルフォーマット(Parquet、ORCなど)では難しかったデータの更新・削除やスキーマ変更を容易にし、データ管理をより効率的かつ柔軟にします。
- ACID トランザクションのサポート: データベースと同等のトランザクション機能を提供し、データの整合性を保証します。これにより、複数の操作をまとめて実行し、エラー発生時にはロールバックすることで、データの不整合を防ぎ、信頼性の高いデータ処理を実現します。
- スキーマの進化: スキーマの変更(カラムの追加、削除、変更)を柔軟にサポートします。スキーマ変更時にデータの再書き込みが不要なため、効率的なデータ管理が可能となり、データの変化に柔軟に対応できます。
- タイムトラベル機能: 特定の時点のデータのスナップショットを取得し、過去のデータ状態にアクセスできます。これにより、データの変更履歴を追跡したり、特定の時点のデータを復元したりすることが可能になり、監査や分析に役立ちます。
- 差分更新による処理効率化: データの挿入、更新、削除を効率的に行うことができます。特に更新処理において、従来のデータレイクではデータの全書き換えが必要でしたが、オープンテーブルフォーマットでは変更部分のみを更新できるため、処理効率が大幅に向上します。
- パフォーマンスの最適化: パーティショニング、ファイルサイズの最適化、メタデータ管理など、さまざまな技術を用いてクエリのパフォーマンスを向上させます。これにより、大量のデータに対しても高速な検索や集計が可能になります。
Apache Iceberg とは
Apache Iceberg は、大規模な分析データセットを扱うための革新的なオープンテーブルフォーマットです。従来のデータ管理方法とは異なり、ファイルを直接管理する設計により、データの変更やスケールに柔軟に対応できます。Hadoop、Spark、Trino、Flink など、様々なデータ処理エンジンとシームレスに連携することができます。
Apache Iceberg の仕組み

出典: Iceberg Table Spec
Apache Iceberg のテーブル は、以下のような複数のファイルによって構成されています。
- Iceberg Catalog: テーブルのメタデータへのポインタを保持するカタログです。テーブルの最新の状態を把握するための情報がここに保存されます。
-
metadata layer: テーブルのメタデータファイルが保存されるレイヤーです。
- metadata file(メタデータファイル): メタデータファイルは、テーブルの設計図のようなものです。テーブルの構造(スキーマ)、データの分割方法(パーティション情報)、テーブルの状態の履歴(スナップショット情報)などが記録されています。テーブルが更新されるたびに、新しいメタデータファイルが作成され、古いファイルは過去のバージョンとして残ります。上図では、s0が古いバージョン、s1が最新バージョンを示しています。
- manifest file(マニフェストファイル): データファイルのリストと、それぞれのファイルがどのパーティションに属するかを記録したファイルです。
- manifest list(マニフェストリスト): 各スナップショットに対応するマニフェストファイルのリストを保持するファイルです。スナップショットは、特定の時点におけるテーブルの状態を表します。
-
data layer: 実際のデータファイルが保存されるレイヤーです。
- data files(データファイル): 実際のデータが Parquet、ORC、Avro などの形式で保存されます。これらの形式は、分析処理に適しており、効率的なデータ圧縮と高速なクエリ処理を実現します。
BigQuery と Apache Iceberg の統合
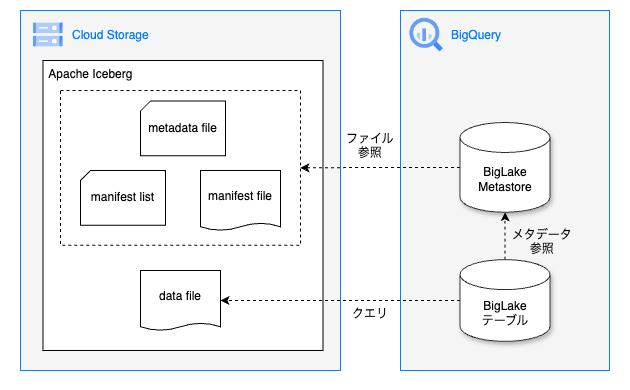
BigQuery と Apache Iceberg を統合する主な方法は、BigLake というストレージエンジンを使用することです。BigLake は Cloud Storage などのストレージに格納された Iceberg テーブルを BigQuery の 外部テーブル として設定することで、Iceberg テーブルのメタデータを参照し、データファイルに直接アクセスしてクエリを実行できます。これにより、データの移動や複製が不要になるため、データパイプラインが簡素化やリアルタイムな分析、ストレージコストの削減などが可能になります。
BigLake テーブルは、BigLake Metastore という Iceberg テーブルのメタデータを管理するためのサービスを使うことで、Dataproc クラスタの Hive メタストアの代わりにサーバーレスとして使用できます。この BigLake Metastore は、Cloud Storage 上にあるメタデータファイル(metadata file、manifest list、manifest file)を参照しています。また、BigLake テーブルを介して Cloud Storage 上の data file に直接クエリすることができますが、その際に BigLake Metastore のメタデータを参照します。
パフォーマンス最適化
BigLake を含む BigQuery 外部テーブルでは Hive パーティショニング により、クエリの実行時に不要なデータを読み込むことを避け、処理速度を向上させることができます。また、Iceberg BigLake テーブルの場合、パーティション フィルタの要求 を有効化しておくことで、WHERE 句による絞り込みを必須条件とすることができます。
セキュリティ
BigLake テーブルでは、以下のようなアクセス制御が可能です。
データガバナンス
BigLake と Dataplex を連携させることで、データの整理、ポリシー管理、品質管理などを一元的に行い、分散したデータを統合的に管理できるようになります。また、データのサイロ化を解消し、組織全体でのデータ活用を促進できます。
制限事項
Iceberg BigLake テーブルには、copy-on-write 構成のみサポートされていることや Parquet ファイルのみサポートされていることなど、いくつかの制約があります。詳細については、公式ドキュメントの 制限事項 をご参照ください。
料金
BigLake の料金は、基本的に BigQuery と同様にテーブルに対するクエリの実行に対して課金されます。詳細については、公式ドキュメントの BigLake の費用 をご参照ください。
また、BigLake Metastore の料金は、オンデマンド料金の場合、BigLake Metastore へのリクエスト 6,250,000 件あたりおよび BigLake Metastore に保存されている 625,000 件ごとに 1 TB の料金が発生します。詳細については、公式ドキュメントの BigLake Metastore の費用 をご参照ください。
実装
今回は、以下の手順を参考に Apache Iceberg の BigLake テーブルを作成します。
Cloud Storage に格納されている Iceberg テーブルに対して BigLake テーブルを作成する場合は、BigLake Metastore を使用し、Apache Spark によってテーブルを作成します。
Apache Spark の実行方法として、以下の3つがあります。今回は BigQuery Spark 用ストアド プロシージャ を使用した方法で進めます。
事前準備
API 有効化
以下の API を有効化します。
- BigQuery Connection API
- BigQuery Reservation API
- BigLake API
Cloud Storage バケット作成
こちら の手順を参考に、Iceberg のファイルを格納する Cloud Storage バケットを作成してください。なお、以下の gcloud コマンドにてバケットを作成することが可能です。
$ gcloud storage buckets create gs://BUCKET_NAME --location=BUCKET_LOCATION
- BUCKET_NAME: バケット名(例:iceberg)
- BUCKET_LOCATION: バケットのロケーション(例: US)
BigQuery データセット作成
こちら の手順を参考に、BigLake テーブルを格納する BigQuer データセットを作成してください。なお、以下の bq コマンドにてバケットを作成することが可能です。
bq --location=LOCATION mk \
--dataset PROJECT_ID:DATASET_ID
- LOCATION データセットのロケーション(例: US)
- PROJECT_ID: プロジェクト ID
- DATASET_ID 作成するデータセットの ID (例: biglake)
BigQuery Connection 作成
BigQuery の Spark 用ストアド プロシージャを使用するためには、BigQuery での Spark 接続 の設定が必要になります。Spark 接続を作成するアカウントに対して BigQuery Connection 管理者 のロール権限を付与した上で、以下コマンドにてリソースを作成します。(コンソールから設定したい場合は こちら を参照ください。)
$ bq mk --connection --connection_type='SPARK' \
--project_id=PROJECT_ID \
--location=LOCATION \
CONNECTION_ID
- PROJECT_ID: Google Cloud プロジェクト ID
- LOCATION: 接続を保存するロケーション(例: US)
- CONNECTION_ID: 接続 ID(例: spark-connection)
また、BigLake テーブルを作成するために、クラウド リソース接続 を作成する必要があります。以下コマンドにてリソースを作成します。(コンソールから設定したい場合は こちら を参照ください。)
$ bq mk --connection --location=REGION --project_id=PROJECT_ID \
--connection_type=CLOUD_RESOURCE CONNECTION_ID
- REGION: 接続のリージョン(例: US)
- PROJECT_ID: 実際の Google Cloud プロジェクト ID
- CONNECTION_ID: 接続の ID(例: biglake-connection)
権限設定
Spark 用ストアド プロシージャを作成するアカウントに対して、以下のロール権限を設定します。
- BigQuery データ編集者
- BigQuery Connection 管理者
- BigQuery ジョブユーザー
- BigQuery メタデータ閲覧者
Spark 接続を作成した際に生成されるサービスアカウントに対して、以下のロール権限を付与します。
- BigLake 管理者ロール
- BigQuery Connection 管理者
- BigQuery ジョブユーザー
- BigQuery データ編集者
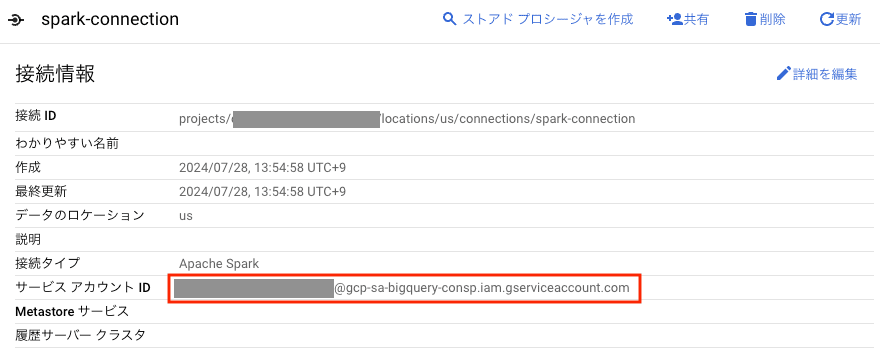
※ なお、Spark 接続を作成した際に生成されるサービスアカウントは、BigQuery コンソールから該当の接続情報を参照することで確認できます。
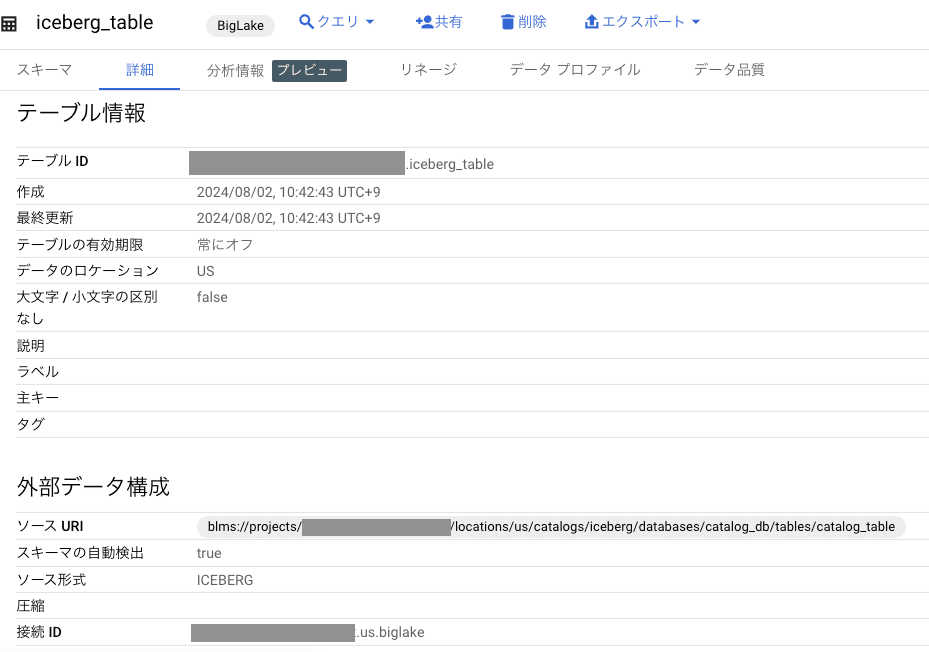
BigLake テーブル作成
BigQuery コンソールから以下のクエリを実行し、Spark 用ストアド プロシージャを作成します。
CREATE OR REPLACE PROCEDURE `BQ_DATASET.iceberg_setup`()
WITH CONNECTION `PROCEDURE_CONNECTION_PROJECT_ID.PROCEDURE_CONNECTION_REGION.PROCEDURE_CONNECTION_ID`
OPTIONS(engine="SPARK",
jar_uris=["gs://spark-lib/biglake/biglake-catalog-iceberg1.2.0-0.1.0-with-dependencies.jar"],
properties=[
("spark.jars.packages","org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.2.0"),
("spark.sql.catalog.CATALOG", "org.apache.iceberg.spark.SparkCatalog"),
("spark.sql.catalog.CATALOG.catalog-impl", "org.apache.iceberg.gcp.biglake.BigLakeCatalog"),
("spark.sql.catalog.CATALOG.gcp_project", "PROJECT_ID"),
("spark.sql.catalog.CATALOG.gcp_location", "LOCATION"),
("spark.sql.catalog.CATALOG.blms_catalog", "CATALOG"),
("spark.sql.catalog.CATALOG.warehouse", "DATA_WAREHOUSE_URI")]
)
LANGUAGE python AS R"""
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("BigLake Iceberg Example") \
.enableHiveSupport() \
.getOrCreate()
# データベースとテーブルの作成
spark.sql("CREATE NAMESPACE IF NOT EXISTS CATALOG;")
spark.sql("CREATE DATABASE IF NOT EXISTS CATALOG.CATALOG_DB;")
spark.sql("DROP TABLE IF EXISTS CATALOG.CATALOG_DB.CATALOG_TABLE;")
spark.sql("CREATE TABLE IF NOT EXISTS CATALOG.CATALOG_DB.CATALOG_TABLE (id BIGINT, sample_name STRING, value DOUBLE)
USING iceberg
TBLPROPERTIES(bq_table='BQ_DATASET.BQ_TABLE', bq_connection='TABLE_CONNECTION_PROJECT_ID.TABLE_CONNECTION_REGION.TABLE_CONNECTION_ID');
")
# サンプルデータを追加
data = [(1, "sampleA", 85.5),
(2, "sampleB", 68.2),
(3, "sampleC", 92.0)]
columns = ["id", "sample_name", "value"]
df = spark.createDataFrame(data, columns)
df.writeTo("CATALOG.CATALOG_DB.CATALOG_TABLE").append()
""";
※ いくつかの大文字の変数名は置き換える必要があります。置き換え箇所の詳細については BigLake Metastore を使用してテーブルを作成する に記載の内容を参照ください。
Spark 用ストアド プロシージャを作成したら以下クエリにて実行し、BigLake テーブルを作成します。
CALL `BQ_DATASET.iceberg_setup`();
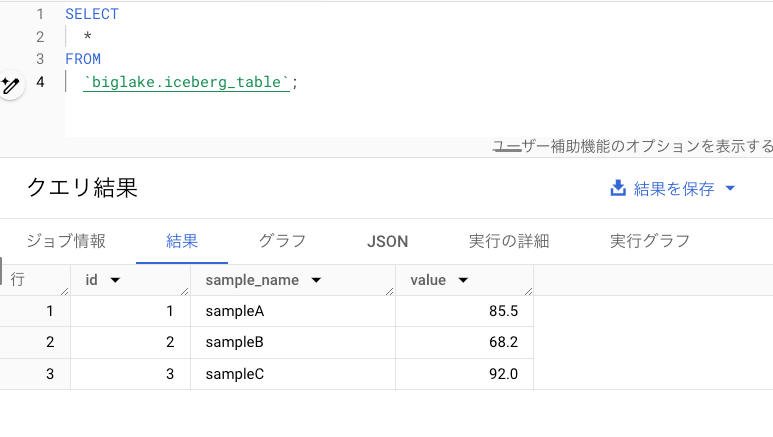
以下クエリを実行し、Iceberg テーブルのデータを BigQuery から参照できることを確認します。
SELECT
*
FROM
`BQ_DATASET.iceberg_table`;
まとめ
今回は、BigQuery と Apache Iceberg の統合によるデータレイクハウス構築方法についてご紹介しました。BigLake を活用することで、Iceberg テーブルを BigQuery から直接クエリすることができ、データパイプラインの簡素化、リアルタイムな分析、ストレージコストの削減などを実現できます。また、BigLake と Dataplex を連携させることで、データのセキュリティとガバナンスを強化することも可能です。
ただし現時点では、Spark で作成された BigLake Metastore を BigQuery 上から確認する手段が提供されておらず、Spark、BigLake API を利用する必要があることが分かりました。こちらについては、今後のアップデートに期待しましょう。
BigQuery と Apache Iceberg の統合は、データ分析基盤を効率的に構築し、ビジネスの価値創出を加速させるための良い手段となります。ご興味がありましたら、ぜひお試しください。
Discussion