次世代データ基盤:データレイクハウスを Google Cloud で実現する
はじめに
こんにちは、クラウドエース データソリューション部の松本です。
普段はデータ基盤や MLOps の構築をしたり、Google Cloud 認定トレーナーとしてトレーニングを提供しております。また、昨年は Google Cloud Partner Top Engineer 2024 に選出されました。今年も Goodle Cloud 界隈を盛り上げていけるよう頑張っていきたいと思います。
クラウドエース データソリューション部 について
クラウドエースのITエンジニアリングを担う システム開発統括部 の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのが データソリューション部 です。
弊社では、新たに仲間に加わってくださる方を募集しています。もし、ご興味があれば エントリー をお待ちしております!
今回は、次世代データ基盤であるデータレイクハウスを Google Cloud で実現する方法について、ご紹介いたします。
この記事はこんな人にオススメ
- 最新のデータ基盤構築について知りたい人
- データレイクハウスやメダリオンアーキテクチャとは何かを知りたい人
- Google Cloud でデータレイクハウスを構築したい人
データレイクハウスとは
データレイクハウス(またはレイクハウス)とは、データレイクとデータウェアハウスの機能を組み合わせた新しいタイプのデータプラットフォームです。
大量の構造化、半構造化、非構造化データを一元的に管理し、必要に応じて高度な分析ができるため、企業はデータの取り扱いをより柔軟にし、より深い洞察を得ることが可能になります。
データレイクハウスが注目される理由
データ基盤アーキテクチャについて、これまでの歴史を振り返ることで、データレイクハウスが注目されている理由を紐解いていきます。

出典:Lakehouse: A New Generation of Open Platforms that Unify
Data Warehousing and Advanced Analytics
データウェアハウス(第一世代データ基盤)
データウェアハウスは、ビジネス意思決定のためにデータを一つの場所に集約・保管し、分析に利用するためのデータ基盤であり、1980年代に考案されました。複数のデータソースからデータを取得してETL処理を行い、データウェアハウスにデータを蓄積していきます。データウェアハウスは、構造化データの処理に適していましたが、非構造化データ(文章や音声、画像など)のようにそのままでは利用できない複雑なデータの処理には適していませんでした。
データレイク(第二世代データ基盤:2層アーキテクチャ)
2000年代に入り、データウェアハウスの課題である非構造化データを分析するニーズが増えたことをきっかけに、データレイクが登場しました。データレイクは、テキストデータや画像、テキストなど構造化データ以外のデータも格納することができ、データ分析や機械学習で利用することができます。しかし、データレイクにはトランザクションのサポートやデータ品質の保証がありません。また、さまざまなデータを自由に格納できる反面、必要なデータが見つかりづらくなり、データスワンプ(活用ができないデータが大量に溜まっている)を引き起す懸念がありました。
データレイクハウス(次世代データ基盤)
データレイクハウスは、データウェアハウスとデータレイクの課題を克服しつつ、それぞれの利点を組み合わせたアーキテクチャになります。構成として、データウェアハウスと類似のデータ構造とデータ管理機能を持ちつつ、オープンフォーマットで低コストのクラウドストレージを利用しています。データレイクハウスは、安価で信頼性の高いオブジェクトストレージが利用可能であるため、最新のニーズに適したアーキテクチャと言えます。
データレイクハウスの特徴
データレイクハウスの主な特徴は以下の通りです。
-
トランザクションのサポート:
データレイクにおけるトランザクションサポート課題を解決するため、データレイクに対してメタデータレイヤーを重ねることで、データレイク内のデータを直接扱うのではなく、メタデータの操作によって扱い、データの一貫性を担保します。 -
スキーマの適用とガバナンス:
テーブル単位のみならず、列や行単位でのきめ細やかな権限管理をサポートし、データのアクセス制御が可能です。 -
オープン性:
Apache Parquet, Apache Icebarg などのオープンソースのデータフォーマットを利用することで、データアクセスの方法を標準化できます。 -
コンピューティングとストレージを分離:
コンピューティングとストレージを分離し、別々のクラスタで使用することで、同時に利用するユーザー数やデータサイズの増大にあわせた拡張が容易になります。 -
構造化・半構造化・非構造化データのサポート:
データレイクハウスは、構造化、非構造化、半構造化データをサポートし、画像、動画、音声、テキストなど様々なデータ形式の保存、調整、分析、アクセスを可能にします。 -
多様なワークロードのサポート:
BI、データ分析、機械学習などの様々なワークロードに対して、ストレージ用途を区別することなくデータを扱えます。 -
エンドツーエンドのストリーミング:
ストリーミングがサポートされるため、リアルタイムのレポート作成要件に対応しています。
データレイクハウスのアーキテクチャ
データレイクハウスのアーキテクチャは以下のようになります。

データレイクハウス アーキテクチャ
データレイクハウスでは、取得した生データを直接 Lakehouse Layer のストレージに格納し、データ分析や機械学習などで利用する際にデータ変換を行います。データ抽出・ロードした後、変換を行うことから、近年主流となっている ELT(Extract, Load, Transform)の発展形アーキテクチャとも言えます。
データレイクハウスのアーキテクチャは、以下のようなレイヤーから構成されます。
-
Ingestion Layer:
Lakehouse Layer に対して、バッチまたはストリーミングにて、生データを取り込む役割を担います。 -
Lakehouse Layer:
構造化 / 半構造化 / 非構造化データを格納します。高い耐久性とスケーラビリティを持ち、安価なコストでデータを保管します。 データの加工度合いに応じて、データ格納のレイヤーを分ける、メダリオンアーキテクチャ(後述)を採用するケースが多いです。 -
Metadata Layer:
Lakehouse Layer に存在するデータのメタデータを扱います。 データカタログを作成したり、トランザクション・権限管理を実現します。 -
Processing Layer:
Lakehouse Layer に存在するデータに対して、データ分析や機械学習などで利用可能な形とするためのデータ変換を行います。 -
Consumption Layer:
SQL、BI、機械学習などでデータを利用します。
メダリオンアーキテクチャ
メダリオンアーキテクチャは、データレイクハウスのデータを論理的に整理するために用いるデータ設計を意味します。
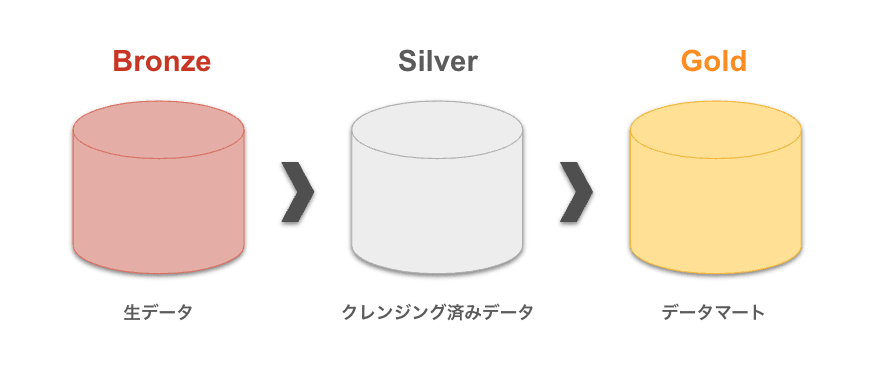
メダリオンアーキテクチャ(Bronze、Silver、Gold)
メダリオンアーキテクチャは、ブロンズ、シルバー、ゴールドの3つのレイヤーから構成され、データ変換の過程を経ることで、ACID(原子性、一貫性、独立性、耐久性)を保証します。
-
ブロンズレイヤー(Bronze):
外部ソースシステムから取得した生データを格納するレイヤーになります。変更データを迅速に取得して蓄積していき、外部ソースシステムからデータの再読み込みを不要とします。 -
シルバーレイヤー(Silver):
ブロンズレイヤーのデータに対して必要に応じてデータクレンジング処理を行った上で、データを格納します。データ分析の前段階で非常に重要なプロセスであり、データから不正確なデータや重複データ等の修正や削除、不完全なデータの補完等を目的とします。 -
ゴールドレイヤー(Gold):
シルバーレイヤーのデータをさらに集約、加工し、特定のビジネス改善のために用意したデータを格納します。一般的なデータマートと同様の意味合いで利用されます。
Google Cloud でのデータレイクハウス
Google Cloud でのデータレイクハウス アーキテクチャは以下のようになります。
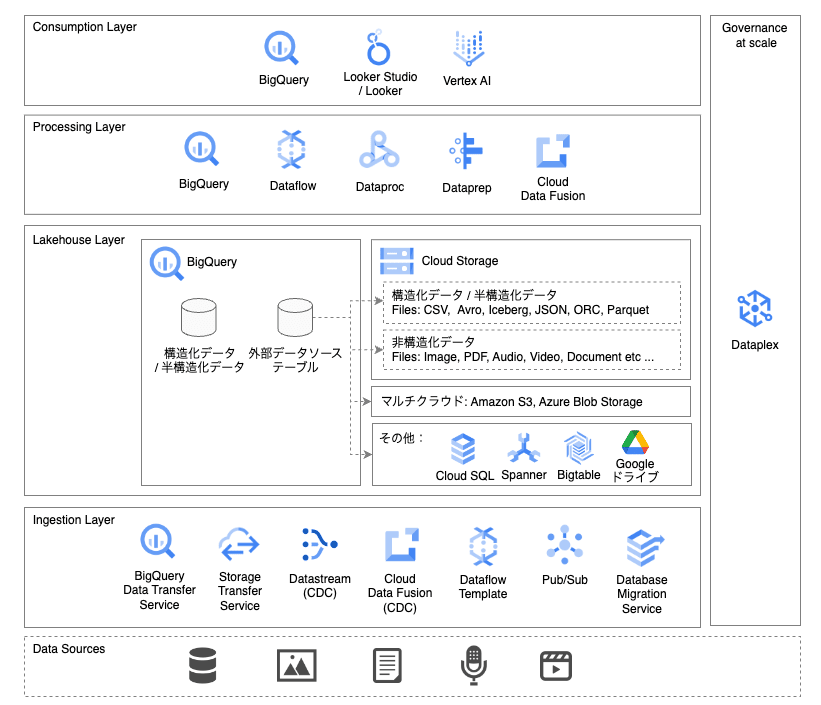
Google Cloud でのデータレイクハウス アーキテクチャ
Google Cloud でのデータレイクハウスは、BigQuery を中心としたアーキテクチャとなります。
特に Lakehouse Layer においては、BigQuery に構造化データや半構造化データを格納するだけでなく、Cloud Storage や Amazon S3、Azure Blob Storage に格納されている様々なデータソースを、BigQuery の 外部データソース として定義することで、データを BigQuery へロードすることなく、データソースに対して直接クエリすることが可能になります。
Ingestion Layer
データソースに存在するデータを Lakehouse Layer に対して転送します。基本的には生データに対して変換を行わず、そのまま転送します。使用できる主なサービスは以下の通りです。
-
BigQuery Data Transfer Service:
Cloud Storage や Amazon S3、Azure Blob Storage など格納されているデータを BigQuery に転送するマネージド サービスです。主に構造化データや半構造化データをバッチ処理にて BigQuery へ直接転送したい場合に使用します。 -
Storage Transfer Service:
Cloud Storage、Amazon S3、Azure Blob Storage、オンプレミス データなどに格納されているオブジェクトやファイルを Cloud Storage へ転送するマネージド サービスです。主にオブジェクトやファイルをバッチ処理にて Cloud Storage へ直接転送したい場合に使用します。 -
Datastream:
Oracle、MySQL、PostgreSQL といったデータベースから BigQuery に対してシームレスにデータを複製できるサーバーレスな変更データ キャプチャ(CDC)サービスです。データベースの内容をリアルタイムに BigQuery へ反映したい場合に使用します。 -
Cloud Data Fusion:
フルマネージドのデータ パイプライン構築サービスであり、ノーコード・ローコードで ETL を実装できます。データ転送のみの用途でも使用可能であり、特に プラグイン を使用することで、多種多様なデータソースに対応することが可能です。また、Datastream と同様に Oracle、MySQL、PostgreSQL から BigQuery への CDC 機能も提供されています。 -
Dataflow:
Apache Beam のプログラミングモデルを使用して、大規模なデータを処理できるフルマネージドでサーバーレスなデータ処理サービスです。データ転送のみの用途でも使用可能であり、Google 提供テンプレート を使用することで、簡単にデータ転送の仕組みを構築することができます。 -
Pub/Sub:
フルマネージドなメッセージキューイングサービスです。Cloud Storage サブスクリプション を使用すると、Pub/Sub メッセージを Cloud Storage に対して書き込むことが可能です。また BigQuery サブスクリプション を使用すると、Pub/Sub メッセージを BigQuery テーブルに直接書き込むことができ、 さらに BigQuery CDC を使用するとテーブルの行単位で UPSERT(UPDATE, INSERT)、DELETE が可能です。 -
Database Migration Service:
MySQL や PostgreSQL から Cloud SQL や AlloyDB に対して、マネージド サービスへのリフト アンド シフト移行やマルチクラウドの継続的レプリケーションを行います。オンプレミスや他クラウドからのデータベース移行が必要な場合に使用します。
Lakehouse Layer
Lakehouse Layer では、BigQuery の外部に保存されたデータソースに対してクエリを実行できる構成とします。これにより、オープンフォーマットのファイルを低コストのストレージで管理し、アクセスすることが可能です。また、メダリオンアーキテクチャにより、ACID(原子性、一貫性、独立性、耐久性)を担保し、データ利用者の様々な用途に対応します。
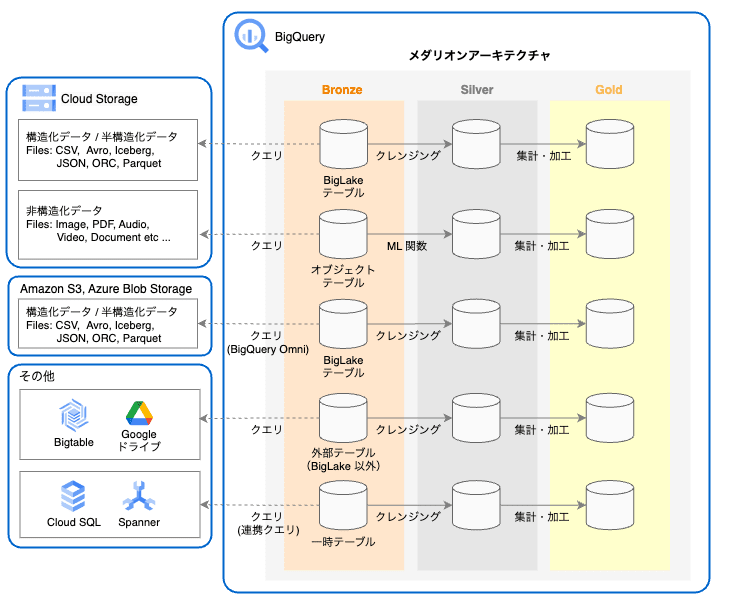
Lakehouse Layer のアーキテクチャ
-
BigLake テーブル:
外部データストアとして、Cloud Storage や Amazon S3、Azure Blob Storage の構造化データを直接クエリできます。(※ Amazon S3 と Azure Blob Storage に対するクエリは、BigQuery Omni を使用する必要があります。)また、行レベル や 列レベル でのテーブルに対するセキュリティを適用することができます。Cloud Storage に基づく BigLake テーブルの場合は、動的データ マスキング も使用できます。 -
BigQuery Omni:
BigLake テーブルを使用して、Amazon S3 または Azure Blob Storage に保存されたデータに対して直接クエリできます。(※ 2024年2月時点では、AWS・Azure における ロケーション として日本がサポートされていません。) -
オブジェクト テーブル:
Cloud Storage バケット内に格納されている非構造化データのメタデータを取得することができます。 BigQuery ML の推論関数(ML.PREDICT や ML.ANNOTATE_IMAGE など)を使用することで、非構造化データに対してクエリし、アクセスすることが可能です。 -
外部テーブル(BigLake 以外):
BigLake 以外の外部テーブルとして、Cloud Bigtable、Google ドライブ、Cloud Storage をデータストアとし使用でき、構造化データを直接クエリできます。(※ Cloud Storage は BigLake テーブルの方が、アクセス制御の観点で 推奨 されています。) -
連携クエリ(フェデレーションクエリ):
BigQuery Connection API を使用して Cloud SQL または Spanner と接続し、EXTERNAL_QUERY 関数を使用して外部データベースに対してクエリを実行します。尚、クエリの実行は外部データベースのコンピューティング リソースを使用して行われ、その結果を BigQuery に引き渡す仕組みとなっています。
Processing Layer
データ分析や機械学習などで Lakehouse Layer のデータを利用する際に、データ変換を行います。また、Lakehouse Layer のメダリオンアーキテクチャにおけるデータ変換を行います。使用できる主なサービスは以下の通りです。
-
BigQuery:
SQL によってデータ変換を行います。ルーティンとして、ストアド プロシージャ や ユーザー定義関数、テーブル関数 、Apache Spark 用ストアド プロシージャ が使用できます。また、リモート関数 を使用すると、Cloud Functions と Cloud Run にデプロイされた関数をクエリから呼び出すことができます。 -
Dataflow:
前述の通り、フルマネージドでサーバーレスなデータ処理サービスです。同一コードでバッチとストリーミングの両方に対応できるという特徴があります。また、通常の Dataflow だと水平方向のみの自動スケーリングとなりますが、Dataflow Prime を使用することで、垂直方向へも自動スケーリングが可能です。 -
Dataproc:
Hadoop と Spark などのデータ処理ワークロードを実行するためのマネージド サービスです。既存の Hadoop / Spark を移行する場合やプリエンプティブル VM または Spot VM によってコストを抑えたい場合に適しています。 -
Dataprep:
分析、レポートなどに使用するデータを視覚的に探索、データクレンジングできるデータサービスです。特にUI操作でデータ探索やデータクレンジングが可能なことが特徴です。 -
Cloud Data Fusion:
前述の通り、ノーコード・ローコードで ETL を実装できるフルマネージドのデータ パイプライン構築サービスです。データのコネクションだけでなく、ETL に関する様々な プラグイン が用意されていることが特徴です。
Consumption Layer
Lakehouse Layer のデータを分析、可視化、機械学習で使用します。必要に応じて、Processing Layer で変換したデータを使用します。使用できる主なサービスは以下の通りです。
-
BigQuery:
SQL によってデータを探索・分析します。BigQuery DataFrames を使用することで、pandas や scikit-learn ライクな Python コードを記述し、BigQuery 上で実行できます。また、生成AIの用途にも対応おり、SQL のみで Vertex AI の LLM を 利用できる ML.GENERATE_TEXT や ML.GENERATE_TEXT_EMBEDDING が用意されています。 -
Looker Studio(旧 Google データポータル):
直感的なUI操作でデータを可視化できるツールです。レポート作成だけでなく、レポート共有やレポートの埋め込みなどが可能です。また、Looker Studio Pro(有償版) では、組織管理や Google Cloud プロジェクトへのリンクによる IAM 管理、カスタマーケアのサポートなどが利用可能です。 -
Looker:
データドリブンな意思決定をする上で必要なデータ探索・共有・洞察を兼ね備えたデータプラットフォームになります。特徴は、LookML によるデータソース・指標の管理、YAMLベース書式で記述です。また、UI操作によるデータ可視化も可能です。 -
Vertex AI:
Google Cloud が提供するフルマネージドの機械学習プラットフォームです。Vertex AI には、モデルのトレーニングとデプロイのオプションとして AutoML、カスタム トレーニング、Model Garden、生成AI などのサービスが提供されています。また、データサイエンティスト向けのマネージド Notebook 環境である Vertex AI Workbench や Colab Enterprise 、MLOps 構築で利用する Vertex AI Pipelines や Vertex AI Feature Store、Vertex AI Model Monitoring などのサービスも数多く提供されています。
Governance at scale
データレイクハウス全体のデータ管理、モニタリング、統制を Dataplex によって一元化します。(データレイクハウス アーキテクチャの Metadata Layer の役割も含みます。)
Dataplex は、組織内に分散したデータを移動やコピーすることなく、データの統合管理が可能です。以下のようなデータ管理機能を提供しています。
- Dataplex Discovery:データレイクのデータからメタデータをスキャンして抽出し、分析、検索、探索のために Dataproc Metastore、BigQuery、Data Catalog に登録します。
- IAM を使用したアクセス制御:様々なプロジェクトに分散したアセット(Cloud Storage バケットや BigQuery データセット)の権限管理を集約します。
- 属性ストア:BigQuery のテーブルとカラムをひとまとめにして、権限を管理することが可能です。
- 自動データ品質:データ品質に関して事前定義されたルールに基づいてデータを検証し、データが品質要件を満たしていない場合はアラートをログに記録します。
- データ品質タスク:BigQuery と Cloud Storage のテーブル間でデータ品質チェックを定義して実行します。
- データプロファイリング:BigQuery テーブル内の列の一般的な統計的特性を特定できます。
- Data Catalog:BigQuery のテーブルや Cloud Storage に存在する非構造化データなどに対してメタデータを付与してカタログ化し、検索できます。
- データメッシュ構築:データメッシュ アーキテクチャを構築することができ、ドメイン単位でのデータを管理することが可能です。
参考
- データレイクとデータウェアハウスとは?それぞれの強み・弱みと次世代のデータ管理システム「データレイクハウス」を解説
- メダリオンアーキテクチャとは
- オープンな分析レイクハウスでデータアセットを統合する
- Build a Lake House Architecture on AWS
- Azure Machine Learning architecture
まとめ
今回は、データレイクハウスを Google Cloud で実現する方法をご紹介しました。BigQuery で外部データソースを定義して直接クエリする機能や、Dataplex によるデータ管理機能などを利用することで、データレイクハウスが実現しやすくなっています。データレイクハウスを構築する際は、ぜひ Google Cloud をご活用ください。
Discussion