Vertex AI Studio で PaLM2 に対する Grounding が可能になりました
1. はじめに
こんにちは、クラウドエース データソリューション部所属の泉澤です。
クラウドエースの IT エンジニアリングを担うシステム統括部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータソリューション部です。
データソリューション部では活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
2. 概要
今回紹介する リリース notes は、Vertex AI Studio で PaLM2 (text-bison と chat-bison) に対して Grounding が GUI で可能になったことについてです(パブリックプレビュー)。
このリリースは 2023年12月5日に行われました。
まず初めに、今回のリリースに関わる Grounding がどういったものか説明します。
2.1. Grounding とは?
Grounding というのは大規模言語モデル(Large Language Model、以下、LLM)に外部から情報を与え、それに基づいた回答をさせることによって、回答の根拠付けを行うことを指します。これは Google Cloud 独自の機能ではなく、LLM を使用する上でハルシネーションを防ぐテクニックのうちの一つです。
ハルシネーションは「幻覚」という意味で、大規模言語モデルがまるで幻覚を見ているかのように、間違った内容を生成することを指します。
LLM は学習の過程で膨大な量のトレーニングデータを使用しますが、その生成が具体的にどんなデータに基づいているのかは知る由もないため、LLM の回答が事実に基づいたものなのかを確かめるためには、結局自分で調べる必要があります。

LLM は事前にトレーニングした情報に基づいて生成を行うが具体的にどういった情報を参照しているのかはわからない
この問題を解決するのが、今回紹介する Grounding です。
LLM はプロンプト(生成AI に指示を出す時の命令文)から提供された情報をうまく解釈し(それがモデルにとって未知の情報であっても)、それに基づいた生成ができます。
たとえば、ChatGPT や Google Bard で、文章を入力し、「要約して」と頼むと、文意を損なわずに要約してくれます。
つまり、モデルの外部から与えられた情報を根拠とする生成が可能なのです。

プロンプトで情報を提供することによってそれに基づいた生成してくれる
上図のように直接プロンプトに情報を渡して回答の根拠付けを行うことは最も簡単な Grounding といえます。
しかし、プロンプトに外部情報を自動的に取り込むように言語モデルを拡張させる仕組みも考えられています。そのような仕組みのことを Retrieval Augmented Generation (以下、RAG) と呼びます。
RAG は日本語で検索拡張生成と呼ばれ、検索技術を使用することで、LLM の回答の根拠となる情報を自動的に取得し、プロンプトに渡すことができます。これにより、人間がプロンプトに情報を入力する手間を省きながら Grounding が行うことが可能です。
RAG にはいくつもの実装方法がありますが、せっかくなのでここからはベクトルエンベディングによる検索技術を用いた RAG のフローの一例を紹介します。Vertex AI Studio では 根拠付の内部動作が不透明であるため、ここでの紹介は RAG の理解を深めるためのものです。
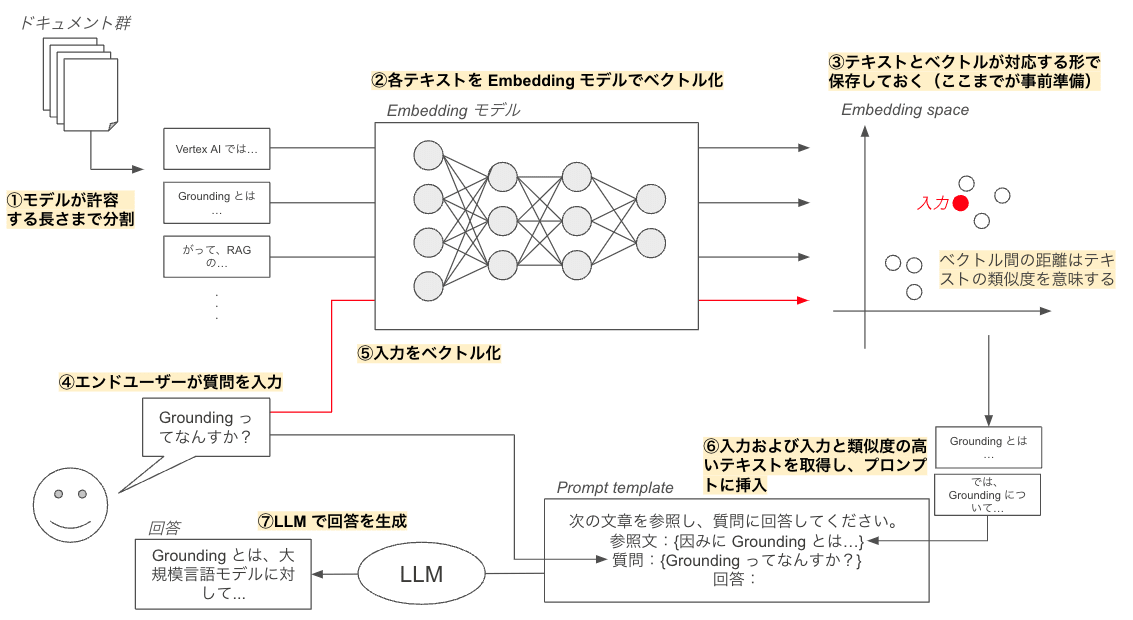
ベクトルエンべディングによる検索技術を用いた Retrieval Augmented Generation のフローの一例(図の参考にした記事)
RAG のフローは、まず、検索対象とするドキュメント群を Embedding モデルが許容する長さまで短く分割するところから始まります(上図中①)。
分割された各テキストを、Embedding モデルによってベクトル化し、元のテキストと対応する形で、専用のデータベースに保存します(上図中②③)。
このようにベクトルエンベディングは、テキストを抽象的なベクトル空間にマッピングすることを指します。
そもそも、なぜベクトル化する必要があるのかといった疑問を抱いた方もいるかも思いますが、Embedding モデルによって作られるベクトル空間では、ベクトル間の距離が元のテキストの「類似度」を示すからです。
この「類似度」が意味する類似性には、単に字面が類似しているだけでなく、意味的な類似性も含まれます。たとえば、「キャベツ」と「レタス」は字面は似ていませんが、どちらも葉物野菜という点で類似しています。そのため、ベクトル空間上では比較的近い位置に存在していることが推測されます(参考)。
このようなベクトル空間上からテキストを検索することで、従来のキーワード検索を超えたクエリ(問い合わせ)の意味を考慮した検索(セマンティック検索)が可能になります。
図では、簡単に書かれていますが、実際には Embedding モデルと Embedding space は巨大なものになります。例えば、Google の Embedding モデルである textembedding-gecko では、最大 3,072 個の入力トークンを 768 次元のベクトルに変換します(参考)。
ここまでが RAG における事前準備の過程です。
エンドユーザーから質問が来ると、内部ではまず、質問のベクトル化が行われます(上図中④⑤)。
このベクトル化は、事前準備と同じ Embedding モデルが使われます。
質問のベクトルの位置から近いベクトルをいくつか選択し、元となるテキストを Prompt template に挿入します。同時に、ユーザーからきた質問文も Prompt template に挿入します(上図中⑥)。それを LLM に渡すことによって LLM は信頼できる情報を参考にしながら回答を生成できるようになります(上図中⑦)。
以上が RAG の基本的な仕組みです。
3. Vertex AI Studio で Grounding を実施する手順
Vertex AI Studio で Grounding を実施する手順を紹介します(参考)。今回の検証はいくつかのプロダクトを跨ぐため、最初にそれらの紹介をします。
3.1. 使用するプロダクトの説明
3.1.1. Vertex AI Studio (旧称:Generative AI Studio)
Vertex AI Studio は、Google Cloud で機械学習モデルを扱うためのサービス群である Vertex AI 上にあります。
Vertex AI Studio では、GUI で Google 提供の生成AI モデルのチューニングや検証、デプロイが可能であり、今回のリリースから LLM (text-bison と chat-bison) の Grounding 機能が追加されました。
3.1.2. Vertex AI Search and Conversation(旧称:Gen App Builder)
Vertex AI Search and Conversation (以下、Search and Conversation)とは、RAG を利用したアプリケーションを GUI での迅速なビルド&デプロイを可能とするサービスです。
現在、検索アプリ・会話アプリ(チャットボット)・レコメンデーションアプリを作成することができます。
Search and Conversation ではデータストアと呼ばれるデータの保管庫のようなもので参照元にするデータを管理しています。Vertex AI Studio で Grounding を行う場合も、参照元にするドキュメント等はこのデータストアで管理するため、Vertex AI Studio での設定をする前にデータを入れておくことが必要です。
Search and Conversation では非構造化データストア・構造化データストア・Web ページストアの 3 種類が利用可能ですが、Vertex AI Studio の Grounding では2024年1月9日現在非構造化データストアしか利用できません。
非構造化データストアは Cloud Storage もしくは BigQuery というサービスからデータをインポートすることができます。
今回はより簡単な Cloud Storage からデータをインポートします。
3.1.3. Cloud Storage
Cloud Storage は、高可用性を備えたマネージドなオブジェクトストレージサービスです。
各プロジェクトごとに「バケット」と呼ばれるフォルダを作成し、その中に様々な形式のデータを保存することができます。
現状、コンソールから Search and Conversation のデータストアに直接データをインポートすることはできず、Cloud Storage もしくは BigQuery などのストレージサービスにアップロードしたものを取り込むという動作が必要です。
今回は、データストアの参照元のストレージとして、この Cloud Storage を利用します。
3.2. Cloud Storage バケットの作成とファイルのアップロード
ここからコンソール上での手順を紹介していきます。
まずは、Cloud Storage バケットを作成し、そこに LLM に参照させたいデータを入れていきます。
今回は、下図のようなデモ用に作成した架空の社内押印規定を PDF 化したものを使用します。

Google Cloud のコンソールに移動します。
上部の検索バーに「storage」と入力し、「Cloud Storage」を選択します。
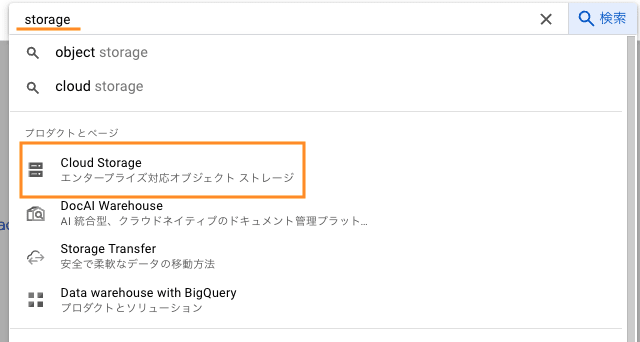
バケットのページが開かれていることを確認し、上部にある[➕作成]をクリックします。

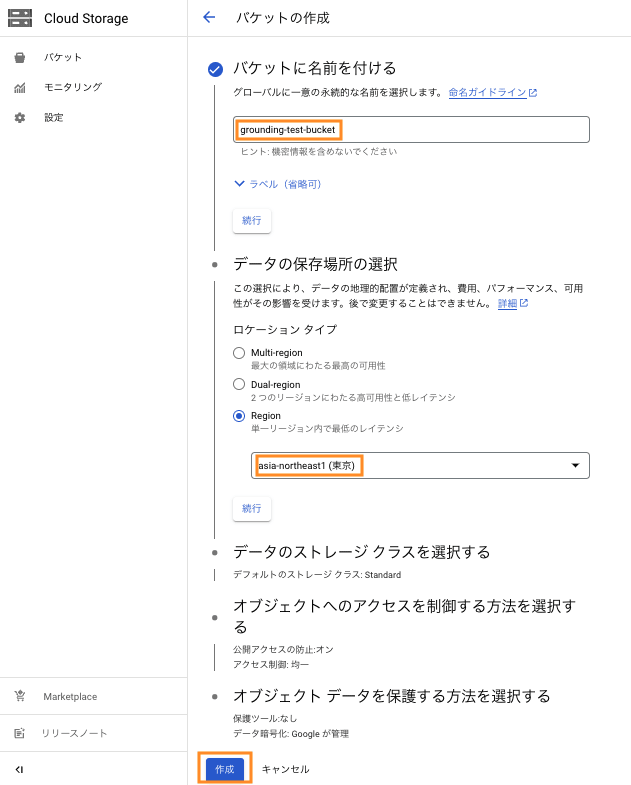
バケットに名前をつけます。ここでは「grounding-test-bucket」としました。
データの保存場所を選択します。ここでは asia-northeast1 リージョンを選択しました。物理的に近いリージョンの方がレイテンシが低くなるため、特別な理由がない限りはそのようなリージョンを選択することをお勧めします。
選択が完了したらそのほかの設定についてはデフォルトのまま [続行] をクリックします。
バケットが作れたら、ファイルをアップロードします。[ファイルをアップロード] をクリックすると、ローカルのファイルシステムが開くため、任意のファイルを選択します。
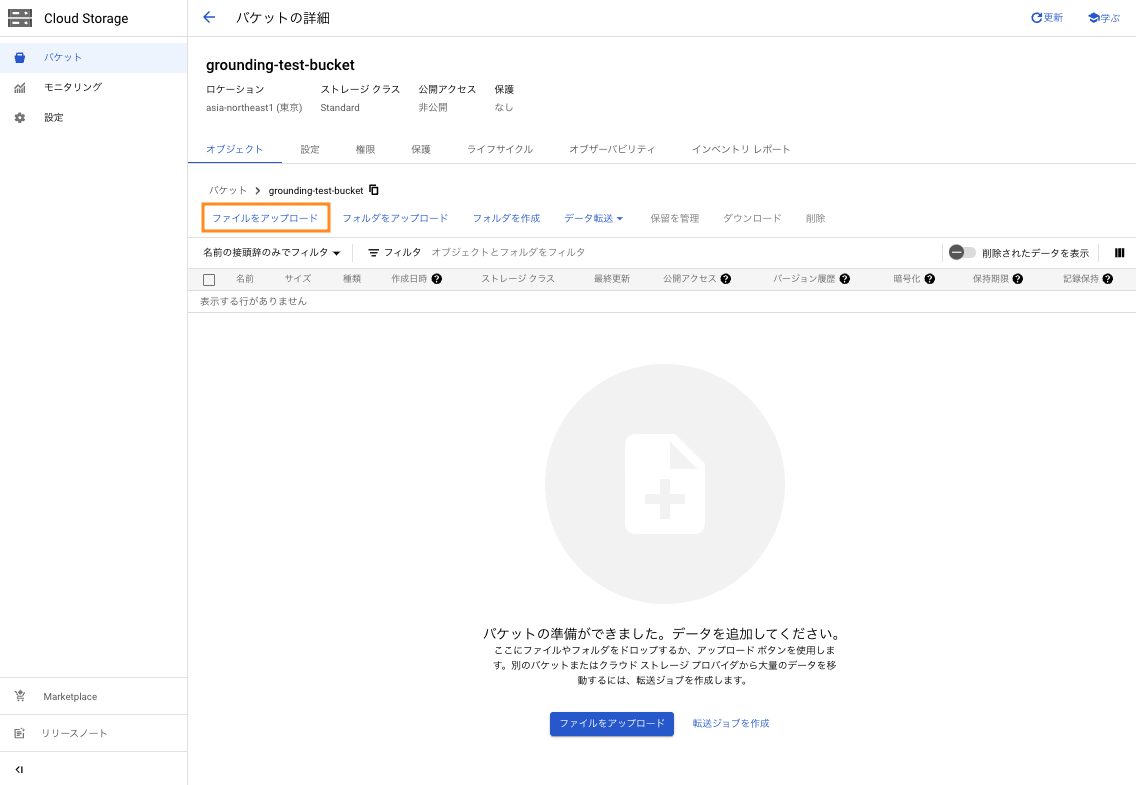
下図のように、ファイルがアップロードされていることを確認できたら Cloud Storage での作業は完了です。

今回はコンソールでファイルをアップロードしましたが、gcloud コマンドやクライアントライブラリといった CLI の利用や Storage Transfer Service でデータを Cloud Storage に転送しても良いでしょう。
3.3. Vertex AI Search and Conversation でデータストアを作成する
先述の通り、Vertex AI Studio で Grounding を実施するには Vertex AI Search and Conversation で Enterprise エディションが有効化された検索アプリと接続した状態のデータストアを作成する必要があります。
検索バーに「Search」と入力し、「検索と会話」をクリックします。
画面が遷移したら [➕新しいアプリ] をクリックします。

アプリの種類として検索を選択します。

下図のように「Enterprise エディションの機能」が有効になっていることを確認してください。
アプリ名と会社名を入力します。ここでは 「grounding-test-application」、「grounding-test-company」 とします。


アプリと接続が可能なデータストアが表示されますが、今回は [➕ 新しいデータストアを作成] をクリックし、新しいデータストアを作成していきます。
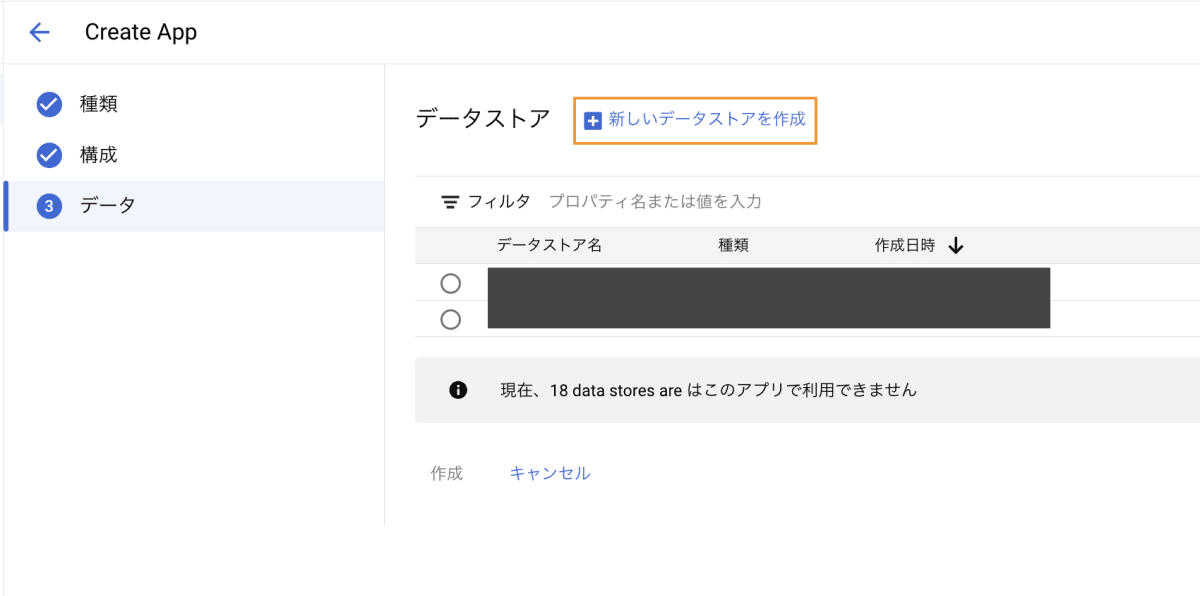
データソースには Cloud Storage を選択します。

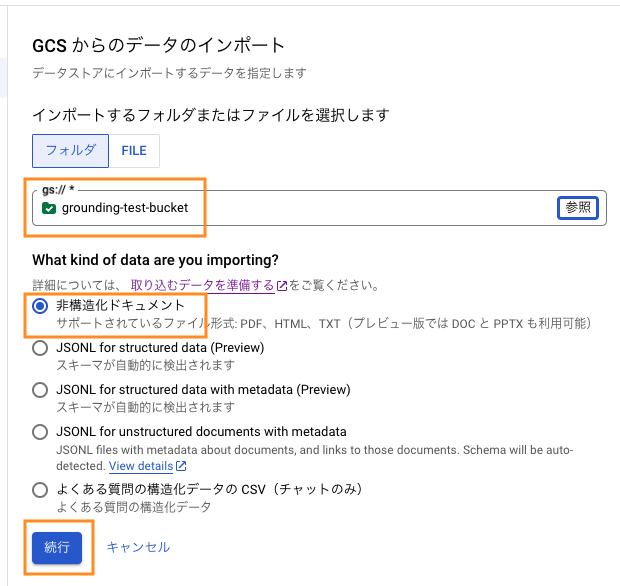
インポートするフォルダまたはファイルを選択します。
参照を押して、先ほど作成した GCS バケットを見つけ [選択] をクリックします。
「非構造化ドキュメント」が選択されていることを確認し、[続行] をクリックします。
データストア名には任意の文字列を入力してください。ここでは「grounding-test-datastore」としました。

上図のデータストア名の入力欄の下に記載されている ID はVertex AI での Grounding の設定時に使用するため、メモしておいてください。
[作成] をクリックすると、先ほどのデータストアを選択する画面に戻ります。
作成したデータストアを選択し、[作成] をクリックします。

以上で Search and Conversation 上での作業は完了です。
3.4. Vertex AI Studio で Grounding の設定し試す
ここからは Vertex AI Studio での操作となります。
上部の検索バーに「vertex」と入力し、「Vertex AI」を選択します。
Vertex AI のコンソールを開いたら左パネルの 「VERTEX AI STUDIO」 の下にある「言語」をクリックします。

テキストプロンプトをクリックします。
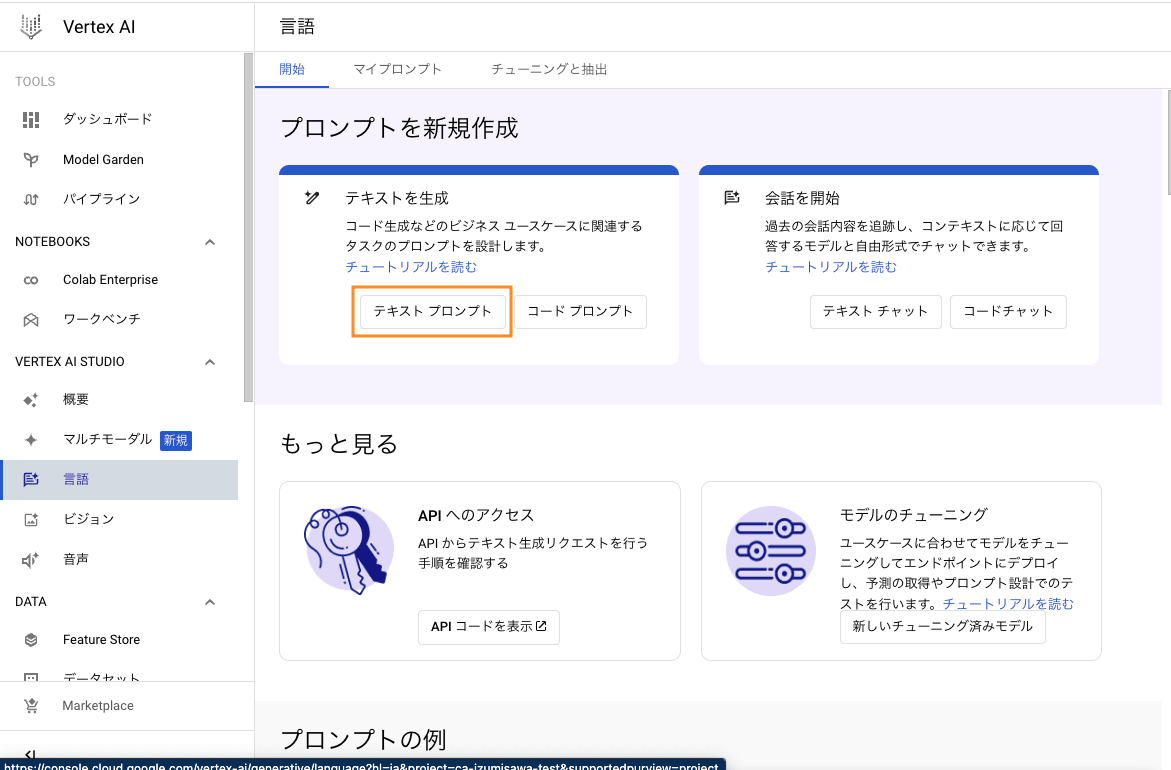
右上のモデルがデフォルトでは Gemini Pro になっていると思われるので、プルダウンをクリックして text-bison に変更してください。※ 現在、Grounding が可能なのは text-bison 系 もしくは chat-bison 系のモデルのみです。
下にスクロールし、根拠付けを有効にするを ON にし、カスタマイズをクリックします。

Vertex AI データストアのパスを入力します。
パスの形式は
projects/{project_id}/locations/global/collections/default_collection/dataStores/{data_store_id}
です。

{project_id} には、コンソール左上のプロジェクト名をクリックする際に、右側の ID の列に表示されたものを入力してください。

{data_store_id} は、データストアを作成した際にコピーしておいた ID です。
データストアのパスを入力し、[保存]をクリックすると、プロンプトに対して Grounding が設定された状態になります。
これで設定が完了ですので、データストアに入れておいたドキュメントに対する質問を入力してみたいと思います。
先述の通り、データストアには社内押印規定のドキュメントを入れているため、印鑑についていくつか質問をしてみたいと思います。
まずは Grounding の設定をしていない text-bison モデルに質問をしてみます。
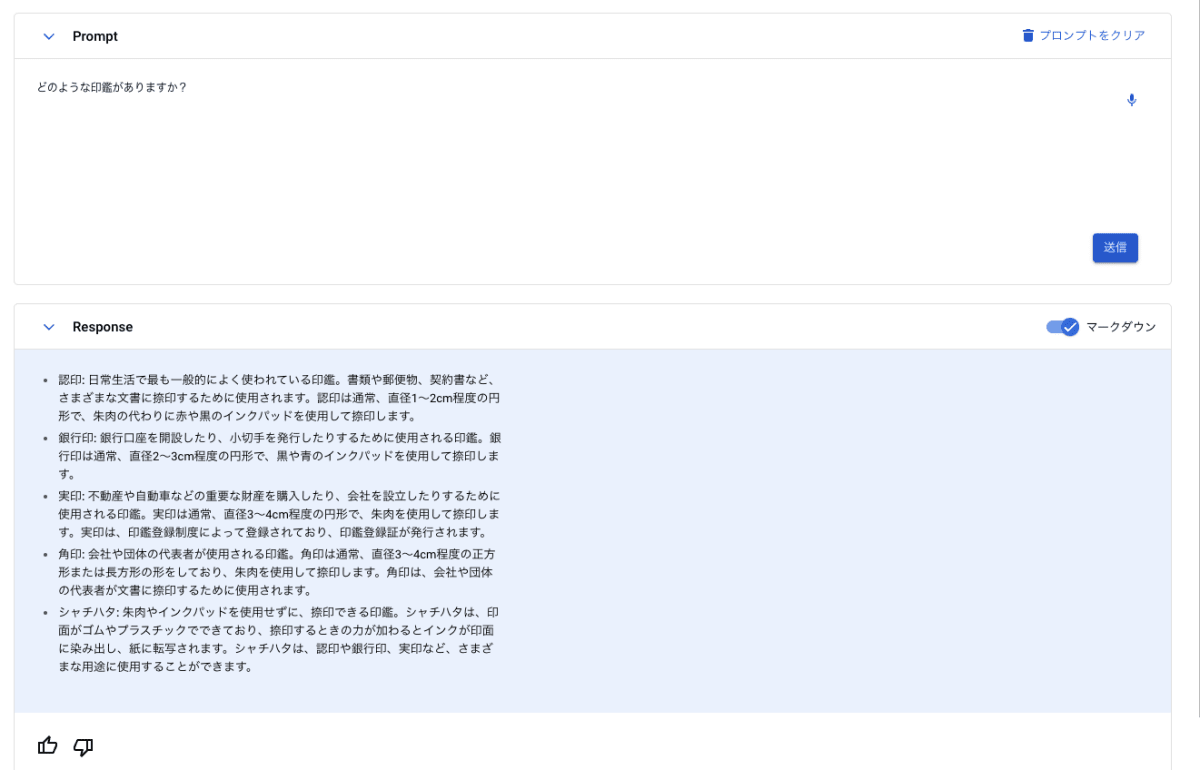
「どのような印鑑がありますか?」と特に用途を指定せずに質問をしてみたところ、認印やシャチハタといった日常で使用される印鑑が含まれた形で回答が返ってきました。
次に、先ほどの手順に従って Grounding の設定をしたプロンプトで質問をしてみます。

プレビュー機能のため画像の一部ぼかしています。
先ほどとは異なり、ドキュメントに沿って、角印、丸印、代表印といった印鑑があるという旨の回答が返ってきました。
続けて角印について聞いてみます。

プレビュー機能のため画像の一部ぼかしています。
ドキュメントに沿って、契約書や発表文といった文書に対して角印が使われる、といった旨の回答が返ってきました。
先ほどとは異なり、Grounding Sources としてドキュメントのリンクが貼られていました。
どうやら質問内容によっては、根拠となるドキュメントの提示もしてくれるようです。
以上のように、Grounding によって生成内容がデータストアに入れられたドキュメントに沿ったものに変化することが確認できました。
4. 類似機能との比較
Grounding は Vertex AI Search and Conversation(以下、Search and Conversation)や LangChain※ においても実装が可能です。
それらと比較をした場合に Vertex AI Studio を利用するメリットを検討してみました。
※ LangChain は LLM を活用するためのツールを提供する Python ライブラリです。開発者が LLM を使って独自のアプリケーションを構築しやすくすることを目的としています。Vertex AI Search and Conversation は「3.1.2. Vertex AI Search and Conversation」で説明した通りです。
まず、Search and Conversation との比較では、Vertex AI Studio はパラメータや追加学習によるチューニングが可能という点が挙げられます。また、最終的にどのようなテキストが LLM に入力されているかは不明ですが、Vertex AI Studio ではプロンプトの設計ができるので Search and Conversation よりも柔軟に LLM を活用できると思われます。(Search and Conversation でも部分的にプロンプトをデザインし、生成結果をコントロールすることは可能です(たとえば:要約のカスタマイズ機能)。)
一方、Search and Conversation には、各アプリに特化した機能(たとえば検索ではファセットなど)が付随しているので、生成AI を活用する上で検索機能やチャットボットを検討している場合、Search and Conversation が第一の選択肢となるでしょう。
続いて LangChain との比較においては、LangChain を利用には開発にコーディングが必要になるので、初学者や非エンジニアにとってはややハードルが高くなる可能性があります。一方で、LangChain を使用することで、LLM やデータソースの選択肢が広がる上に、より複雑な問題解決や正確な回答を LLM に行わせるための技術(ReAct など)を用いることも可能になります。
5. まとめ
本記事では、Vertex AI Studio で PaLM2 に対して行う Grounding という機能を紹介しました。
Grounding を使用することで、専門的な知識やカスタム情報を LLM に取り入れることが可能になり、LLM の利用範囲がグッと広がる可能性があります。
Vertex AI Studio では Grounding を含む多くの機能を GUI で試すことができるため、LLM を用いた開発をこれから始める方々とって良い選択肢になると思います。
また、昨年末にリリースされた Gemini Pro にもこの機能が実装されること期待できますし、今後の動向も紹介していけたらと思います。
Discussion