Vertex AI の textembedding-gecko モデルをファインチューニングしてみた
こんにちは、クラウドエース Data/ML ディビジョン所属の穂戸田です。
本記事では、2023 年 10 月 4 日に Preview となった VertexAI のtextembedding-geckoのファインチューニングの手順について解説します。なお、本記事では、ファインチューニングによるモデル性能の向上は目的としていません。
また、text embedding、ファインチューニングってなに?といったところから解説するため、チューニング手順のみ知りたい方は該当箇所までスキップしてください。
text embeddingとは
text embedding は、日本語で「テキスト埋め込み」と呼びます。
テキスト埋め込みとは、自然言語を数値ベクトル化することです。
これにより、自然言語の単語や文章の意味をコンピュータが理解できるようになります。
Google の公開しているコース「Embeddings とは」でも述べられているように、テキスト埋め込みの概念は緯度と経度をイメージすると理解しやすいかと思います。
緯度と経度は 2 つの数(以下、次元と記載)により地球上の座標を表しています。言い換えると、2 次元のベクトルで地球上のすべての場所を定義できるということです。
以下は、日本の各県庁所在地とリオデジャネイロの緯度と経度を視覚化したものです。
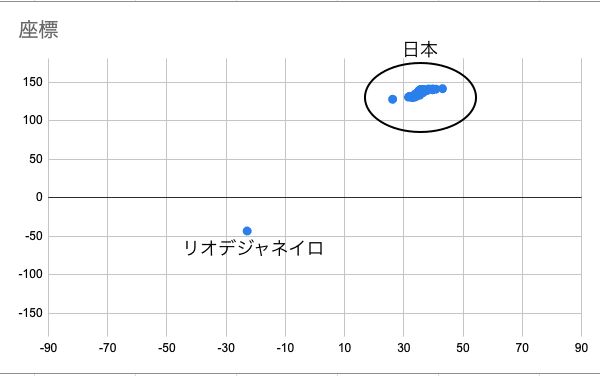
ご覧の通り、日本の座標はグループを形成しており、リオデジャネイロと離れていることが視覚的にわかります。
次に、自然言語を 2 次元のベクトルのみに単純化したイメージを見てみましょう。
座標と同様に、意味が近い単語同士でグループを形成していることがわかります。
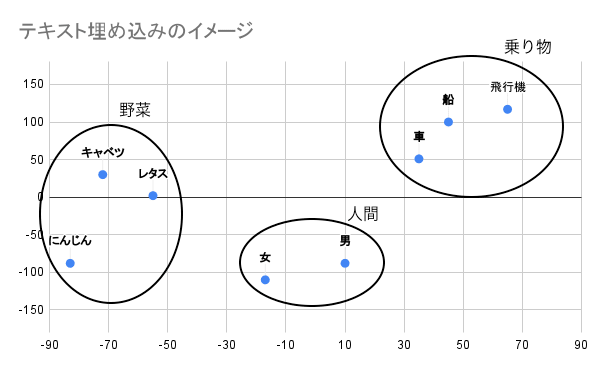
上記はテキスト埋め込みの概念をイメージしやすくするために、緯度と経度になぞらえて 2 次元でテキスト埋め込みをグラフ化しましたが、本来のテキスト埋め込みはより高次元のベクトルを用いて行われます。
また、座標におけるベクトルの乖離は物理的な距離が離れていることを意味しており、テキスト埋め込みにおけるベクトルの乖離は言葉の意味や分類が離れていることを意味します。
使用例
先述したように、自然言語を高次元のベクトルに変換することで文章同士の類似性や分類をコンピュータが認識できるようになります。
よって、テキスト埋め込みが向いているタスクは以下の通りです。
- セマンティック検索:単語の持つ意味を学習し、近い意味を持つ単語や類似的な単語で検索できるようになる
- テキストの分類:学習させたラベル付けテキストをもとに、新たなテキスト入力に対して 1 つ以上のカテゴリーに分類する
textembedding-geckoモデルとは
VertexAI が提供するテキスト埋め込みモデルです。
最大 3,072 の入力トークンを受け入れ、入力された自然言語のテキストを 768 次元のベクトルに変換して出力します.
textembedding-geckoのベクトル変換に対応している言語は英語のみとなっており、英語以外の自然言語をベクトル変換する際にはtextembedding-gecko-multilingualを使用します。
また、VertexAI は様々なモデルを提供しております。
参考:Generative AI foundation models
実際に使ってみる
Google Cloud の Cloud Shell 上にて、実際にtextembedding-geckoで自然言語テキストを数値ベクトルに変換してみます。
1. 自然言語テキストを持つrequest.jsonファイルを作成
{
"instances": [
{ "content": "Hello World!"}
]
}
2. 数値ベクトルに変換
以下コマンドでrequest.json内の自然言語テキストを数値ベクトルに変換して出力します。
参考:text-embeddings sample_reques
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/publishers/google/models/textembedding-gecko:predict"
以下のように出力されます。
{
"predictions": [
{
"embeddings": {
"statistics": {
"token_count": 3,
"truncated": false
},
"values": [
0.02306339330971241,
0.0026592114008963108,
...
]
}
}
],
"metadata": {
"billableCharacterCount": 11
}
}
valuesに含まれている値が入力テキスト内の単語に対応する数値ベクトルであり、これらをコサイン類似度などの計算を行うことでテキスト同士の類似性を測定することができます。
参考:広告数学の美しい物語 > コサイン類似度
ファインチューニングとは
日本語では「微調整」「追加学習」などと呼ばれます。
事前学習済みモデルを特定のタスクや新しいデータセットに適応させるために追加学習させるプロセスのことです。
学習データを追加した分だけ学習させればよいので、新たにモデルを作成して学習させるよりも時間を圧倒的に短縮できます。
使用例
例えば以下のような使用例があります。
- ドメイン特化言語理解:専門用語(医学や法律など)や固有名詞を使用した AI の解答精度の向上
- カスタムセンチメント分析:業界固有のデータセット(レストランのレビューや医療関連のフィードバックなど)を学習させることで、特定の条件下における文脈やニュアンスの違いなどを理解
実際にtextembedding-geckoモデルのファインチューニングを行う
該当機能は記事執筆時点(11/18)において Preview 機能のため、以下の手順は必ずしも動作を保証するものではありません。
1. データセットの作成
入力と予期される出力のペアを含むデータセットを基盤モデルに提供する必要があります。
以下の 4 つのファイルを Cloud Storage(以下、GCS とする)に配置しました。
注意点として、各データ内において最低でも 9 つのデータが必要かつ、データ内の改行は改行コードの記述である必要があります。
※各ファイルにおいて、1 ~ 3 つ目のパラメータは公式ドキュメントから引用し、4 ~ 9 つ目のパラメータは ChatGPT で作成したデータセットです。
corpus.jsonl
{"_id": "doc1", "title": "Get an introduction to generative AI on Vertex AI", "text": "Vertex AI's Generative AI Studio offers a Google Cloud console tool for rapidly prototyping and testing generative AI models. Learn how you can use Generative AI Studio to test models using prompt samples, design and save prompts, tune a foundation model, and convert between speech and text."}
{"_id": "doc2", "title": "Use gen AI for summarization, classification, and extraction", "text": "Learn how to create text prompts for handling any number of tasks with Vertex AI's generative AI support. Some of the most common tasks are classification, summarization, and extraction. Vertex AI's PaLM API for text lets you design prompts with flexibility in terms of their structure and format."}
{"_id": "doc3", "title": "Custom ML training overview and documentation", "text": "Get an overview of the custom training workflow in Vertex AI, the benefits of custom training, and the various training options that are available. This page also details every step involved in the ML training workflow from preparing data to predictions."}
{"_id": "doc4", "title": "Benefits of using Vertex for generative AI", "text": "Vertex AI offers a number of benefits for developing and deploying generative AI models, including:\n* A wide range of pre-trained foundation models that are optimized for different tasks, such as text generation, translation, and code generation.\n* A flexible and scalable infrastructure for training and deploying custom generative AI models.\n* A variety of tools and resources to help you get started with generative AI, such as tutorials, documentation, and community support."}
{"_id": "doc5", "title": "How to use Vertex to generate different creative text formats", "text": "Vertex AI can be used to generate a variety of creative text formats, such as poems, code, scripts, musical pieces, and email. To do this, you can use the Generative AI Studio or the PaLM API for text.\nThe Generative AI Studio provides a user-friendly interface for generating different creative text formats. To get started, simply select the type of creative text format you want to generate and provide the necessary prompts.\nThe PaLM API for text provides a more flexible way to generate creative text formats. You can use the API to design your own prompts and to control the structure and format of the generated text."}
{"_id": "doc6", "title": "Best practices for training custom generative AI models on Vertex", "text": "Here are some best practices for training custom generative AI models on Vertex:\n* Use a high-quality dataset that is representative of the tasks you want your model to perform.\n* Choose a pre-trained foundation model that is optimized for the tasks you want your model to perform.\n* Use appropriate hyperparameters for training your model.\n* Monitor the training process and make adjustments as needed.\n* Evaluate the trained model on a holdout set to ensure that it is performing well on unseen data."}
{"_id": "doc7", "title": "How to deploy generative AI models on Vertex", "text": "Once you have trained a custom generative AI model on Vertex, you can deploy it to production so that it can be used to generate text. To do this, you can use the Vertex AI API or the Vertex AI console.\nThe Vertex AI API provides a programmatic way to deploy models to production. To use the API, you will need to create a Vertex AI model object and then deploy the model to a Vertex AI endpoint.\nThe Vertex AI console provides a graphical user interface for deploying models to production. To use the console, you will need to create a Vertex AI model object and then deploy the model to a Vertex AI endpoint."}
{"_id": "doc8", "title": "Pricing options for Vertex GenAI", "text": "Vertex GenAI offers a variety of pricing options to meet the needs of different businesses. The pricing options are based on the amount of compute resources used, the amount of data stored, and the number of requests made.\nFor more information on Vertex GenAI pricing, please visit the Vertex AI pricing page."}
{"_id": "doc9", "title": "How to get support for Vertex GenAI", "text": "Vertex GenAI offers a variety of support options to help you get the most out of the platform. The support options include:\n* Documentation: Vertex GenAI documentation provides detailed information on how to use the platform.\n* Tutorials: Vertex GenAI tutorials provide step-by-step instructions on how to complete common tasks.\n* Community forum: The Vertex AI community forum is a great place to ask questions and get help from other users.\n* Support: Vertex AI support offers 24/7 support for customers with active subscriptions."}
テキスト埋め込みモデルの学習に使用するテキストデータです。
ファイルのデータからテキストの意味や類似性を表現する数値ベクトルを学習します。
queries.jsonl
{"_id": "query1", "title": "generative AI on Vertex", "text": "Does Vertex support generative AI?"}
{"_id": "query2", "text": "What can I do with Vertex GenAI offerings?"}
{"_id": "query3", "text": "How do I train my models using Vertex?"}
{"_id": "query4", "text": "What are the benefits of using Vertex for generative AI?"}
{"_id": "query5", "text": "How can I use Vertex to generate different creative text formats?"}
{"_id": "query6", "text": "What are the best practices for training custom generative AI models on Vertex?"}
{"_id": "query7", "text": "How can I use Vertex to deploy my generative AI models to production?"}
{"_id": "query8", "text": "What are the pricing options for Vertex GenAI?"}
{"_id": "query9", "text": "How can I get support for Vertex GenAI?"}
テキスト埋め込みモデルの評価に使用されるテキストデータです。
データ内に必要なフィールドはcorpus.jsonlファイルと同様です。
training_label.tsv
query-id corpus-id score
query1 doc1 1
query2 doc2 1
query3 doc3 2
query4 doc4 3
query5 doc5 3
query6 doc6 3
query7 doc7 4
query8 doc8 4
query9 doc9 4
corpus.jsonl ファイルに含まれるテキストの正解ラベルです。
test_label.tsv
query-id corpus-id score
query1 doc1 4
query2 doc2 4
query3 doc3 3
query4 doc4 3
query5 doc5 3
query6 doc6 2
query7 doc7 1
query8 doc8 1
query9 doc9 1
queries.jsonl ファイルに含まれるテキストの正解ラベルです。
2. チューニングジョブを実行
以下環境変数で実行します。
-
LOCATION:リージョン -
PIPELINE_SCRATCH_PATH:チューニンングジョブ実行結果の出力するパス -
PROJECT_ID:任意のプロジェクトID -
BASE_MODEL_VERSION_ID:textembedding-gecko@002- 記事執筆時点(11/18)での安定バージョン(参考:available model version)
-
TASK_TYPE:特定の下流タスク用にモデルを最適化するためのパラメータ-
RETRIEVAL_QUERY:指定されたテキストが検索/取得設定のクエリであることを指定 -
RETRIEVAL_DOCUMENT:指定されたテキストが検索/取得設定のドキュメントであることを指定 -
SEMANTIC_SIMILARITY:指定されたテキストがセマンティックテキスト類似性 (STS) に使用されることを指定 -
CLASSIFICATION:埋め込みが分類に使用されることを指定 -
CLUSTERING:埋め込みがクラスタリングに使用されることを指定
-
-
QUERIES_PATH:queries.jsonl`を配置した GCS の URI -
CORPUS_PATH:corpus.jsonl`を配置した GCS の URI -
TRAIN_LABEL_PATH:training_label.tsv`を配置した GCS の URI -
TEST_LABEL_PATH:test_label.tsv`を配置した GCS の URI -
BATCH_SIZE:大きくするとオーバーフィッティングのリスクが低下し、小さくするとトレーニングの学習データが少なくなり効率が向上する -
ITERATIONS:モデルのチューニングの反復回数
実行コマンド
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
"https://${LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/pipelineJobs?pipelineJobId=tune-text-embedding-$(date +%Y%m%d%H%M)" \
-d '{
"displayName": "tune-text-embedding-model",
"runtimeConfig": {
"gcsOutputDirectory": "'${PIPELINE_SCRATCH_PATH}'",
"parameterValues": {
"project": "'${PROJECT_ID}'",
"base_model_version_id": "'${BASE_MODEL_VERSION_ID}'",
"task_type": "'${TASK_TYPE}'",
"location": "us-central1",
"queries_path": "'${QUERIES_PATH}'",
"corpus_path": "'${CORPUS_PATH}'",
"train_label_path": "'${TRAIN_LABEL_PATH}'",
"test_label_path": "'${TEST_LABEL_PATH}'",
"batch_size": "'${BATCH_SIZE}'",
"iterations": "'${ITERATIONS}'"
}
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/llm-text-embedding/tune-text-embedding-model/v1.1.1"
}'
これで準備したデータセットをもとにtextembedding-geckoモデルのチューニングが完了しました。チューニングしたモデルは VertexAIのモデル レジストリで確認できます。
なお、この時点ではチューニング後のモデルはデプロイされていないため、オンライン予測ができません。
チューニングしたモデルをデプロイする
VertexAIのモデル レジストリに表示されているモデルの中から、デプロイしたいモデルを選択します。
「デプロイとテスト」タブを選択し、「エンドポイントにデプロイ」をクリックします。
モデルをデプロイするエンドポイントや、予測トラフィックを処理するためのコンピューティングリソースなどの設定を行い、「デプロイ」をクリックすれば完了です。
デプロイしたモデルを使用する
モデルをデプロイしたエンドポイントを指定して、テキスト埋め込みを実行するだけです。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
${ENDPOINT_URI}/v1/projects/${PROJECT_ID}/locations/${LOCATION}/endpoints/${MODEL_ENDPOINT}:predict \
-d '{
"instances": [
{
"content": "Hello World!"
}
]
}'
まとめ
今回はtextembedding-geckoモデルのファインチューニングの手順を紹介しました。
ファインチューニングはすでに多くの企業にて行われており、これから様々なタスクに特化したモデルが公開されていくことでしょう。
このビッグウェーブに乗り遅れないよう、これからも最新のリリース動向を追っていきたいと思います。
最後までご覧いただきありがとうございました!!
Discussion