Cloud Data Fusion でストリーミング データを BigQuery に格納する際の性能検証
クラウドエースでデータ ML エンジニアをやっている神谷と申します。業務では、データ基盤構築やデータ分析に取り組んでいます。本記事では、ノーコード・ローコードでデータ パイプラインを作成できる Cloud Data Fusion を使って、どのぐらいの量のストリーミング データを捌けるかの性能検証を行います。
1. はじめに
Google Cloud でストリーミング データのハンドリングと言えば Cloud Dataflow が挙がってくると思いますが、Data Fusion でも同様のことができるようなので、両者の違いを検証します。あらかじめ断っておくと、現時点(2022/11/14)で Data Fusion のストリーミング データに対する自動スケーリング機能はないため、スケーラビリティという観点であれば Dataflow が優れています。とはいえ、Data Fusion のノーコード・ローコードのコンセプトは一定ニーズがあるため、運用コストよりも開発コストを重視した場合に、パフォーマンス的にはどの程度実用に耐えうるかを検証します。
2. Cloud Data Fusion とは
Cloud Data Fusion は Google Cloud が提供するフルマネージドのデータ パイプライン構築用プロダクトであり、ノーコード・ローコードで ETL を実装できることが特徴です。中身は CDAP と呼ばれる OSS で、インフラ部分を Google Cloud が提供します。作成されたパイプラインは Dataproc(Apache Spark)ジョブとして動きます。様々なデータソース(Oracle、SQL Server、S3、SAP、Salesforce 等)を扱えるため、Google Cloud、とりわけ BigQuery にデータを集約・統合する際に便利です。
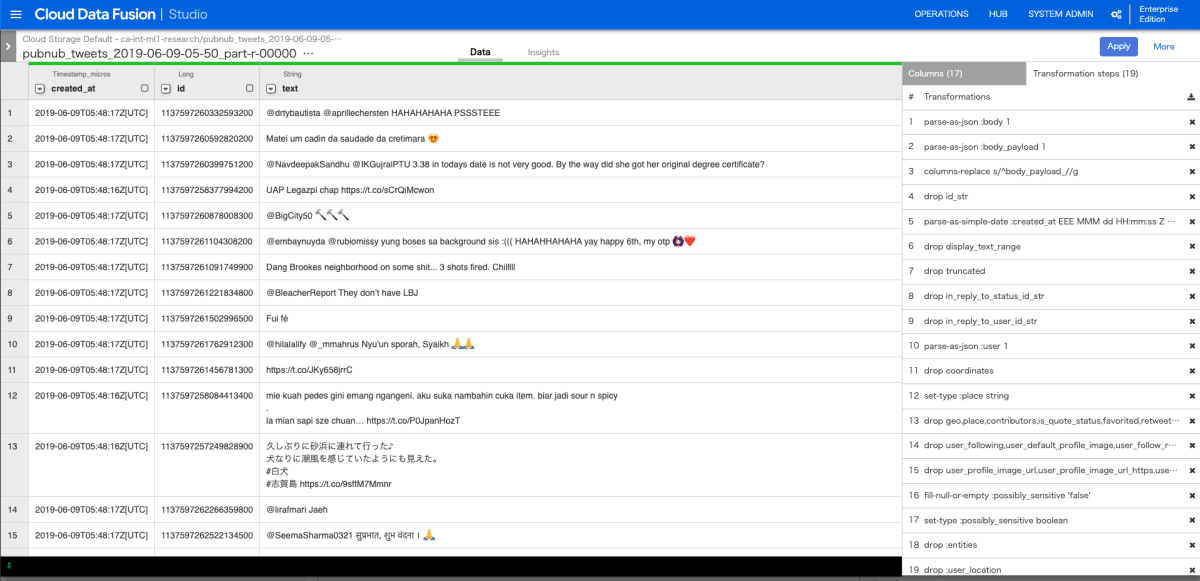
以下は、Data Fusion で加工処理をする際によく使うであろう「Wrangler」の画面です。
画面左に構造化データの列名や型、具体的な値が表示されています。画面右に「Wrangler」における一つ一つの処理(レシピと呼ばれる)が表示されています。
次の画面は、サンプルのパイプライン一覧です。「Import Data from Excel(エクセル読み込み処理)」、「Transfer Data From MySQL to Google BigQuery(MySQL から BigQuery へのデータ変換)」といった
定型的な処理がサンプルとしてあらかじめ用意されています。

3. Google Cloud における ETL プロダクト比較
Google Cloud における類似のプロダクトとして、Dataflow、Dataprep(本記事では割愛)などがありますが、以下のような違いがあります。
| Data Fusion | Dataflow | |
|---|---|---|
| 内部フレームワーク | CDAP | Apache Beam |
| ノーコード・ローコード | ◎(パイプライン全体を GUI から構築可能) | △(Google 提供のテンプレートは便利だが、基本的にはコーディングを行う必要がある) |
| 独自コーディング | ◯(基本コンセプトはノーコードだが、コンポーネント レベルで Python、Scala、Javascript、SQL 等のローコード利用が可能) | ◎(Java、Python 等で自由度の高いプログラミングが可能) |
| 依存関係定義 | △(パイプライン同士の順序制御の自由度が低い。大規模な基盤であれば、ほとんどのケースでジョブ管理ツールが必要になる) | ◯(作り込みは可能だが、別途ジョブ管理ツールを使うケースが多い) |
| 料金 | △(インスタンス立てっぱなしでそれなりに料金がかかる) | ◯(サーバレスのため使ったぶんだけの従量課金) |
| パフォーマンス(バッチ) | ◎(オートスケーリング機能あり。バックエンドが、Dataproc(Apache Spark)なので、大規模なデータ量に耐えうる) | ◎ |
| パフォーマンス(ストリーミング) | △(現時点(2022/11/14)でストリーミング データに対するオートスケーリング機能なし。固定インスタンスでの性能を今回検証する) | ◎(オートスケーリング機能あり。ストリーミング データの増減にリアルタイムにコスパよく対応できる) |
また、Data Fusion には以下の2種類の自動スケーリング機能がありますが、いずれもストリーミング データには十分に対応していません。
| 種類 | 概要 |
|---|---|
| Data Fusion が用意した自動スケーリング | Data Fusion があらかじめ用意した Dataproc クラスタ構成であり、プロファイル画面から選択可能。 スケールアップはするがスケールダウンはしないため、ストリーミング データには適していない |
| 事前定義の自動スケーリング | ユーザが事前に定義した Dataproc クラスタ構成を Data Fusion で利用できる機能。 現時点(2022/11/14)でバッチパイプラインのみ対応 |
そのため、本記事では固定インスタンスでの性能検証を行います。ストリーミング データを扱う上で、レイテンシがそこまで要求されないが、複雑な ETL 処理(個人情報の秘匿化、時系列データの集計等)を GUI 経由でサクッと作ってしまいたい場合におすすめの手法となります。
4. ストリーミング データ性能検証方法
Pub/Sub 経由で BigQuery にデータを流し込んでいきます。
前述したとおり、Data Fusion で作成したパイプラインは Dataproc(Apache Spark)で動くため、これが秒間でどれぐらいのメッセージを捌けるかを検証します。ストリーミング データのパイプライン作成方法については以下のコンテンツを参考にしました。
-
Building Realtime Pipelines in Cloud Data Fusion[1]
-
Cloud Data Fusion のリアルタイム パイプラインで PubSub から BigQuery にロードする[2]
また、比較対象として、Google 提供の Dataflow テンプレート(Pub/Sub Subscription to BigQuery[3])を使用します。Google 提供のテンプレートは定型的な処理を雛形化したものであり、IN/OUT やオプションの設定をするだけでパイプラインの構築が可能です。ちょっとした変換・加工処理であればユーザ定義関数として Javascript でプログラミングすることもできる[4]ので、今回はその機能も使います。
今回の性能検証におけるデータ パイプラインは以下の図のようになります。
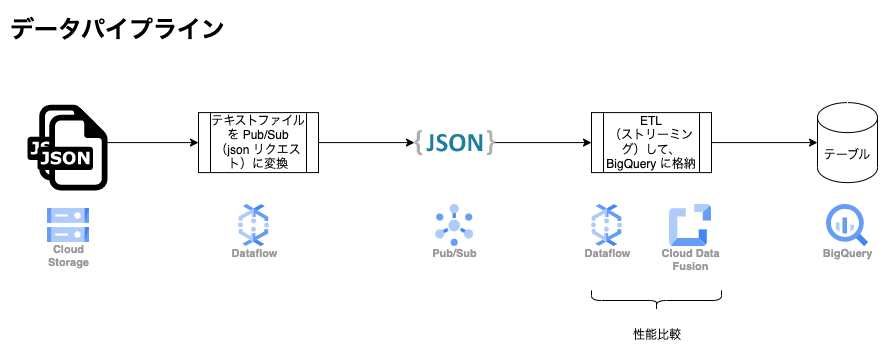
- GCS にある 大容量の json テキストファイルを読み込んで、Pub/Sub に変換(Dataflow テンプレートの一つである「Cloud Storage Text to Pub/Sub(Batch)」を利用)
- Pub/Sub から json リクエストを読み込んで、ストリーミングの ETL 処理を実行(Data Fusion のリアルタイム パイプライン と Dataflow テンプレートの「Pub/Sub Subscription to BigQuery」をそれぞれ比較)
参考として、Data Fusion と Dataflow それぞれの変換処理のコードを貼ります。Data Fusion の Wrangler レシピは、GUI からポチポチして作ったものをコードとしてエクスポートしたものです。
Data Fusion の変換処理(Wrangler のレシピ)
columns-replace s/^body_payload_//g
drop id_str
parse-as-simple-date :created_at EEE MMM dd HH:mm:ss Z yyyy
drop display_text_range
drop truncated
drop in_reply_to_status_id_str
drop in_reply_to_user_id_str
parse-as-json :user 1
drop coordinates
set-type :place string
drop geo,place,contributors,is_quote_status,favorited,retweeted,filter_level,user_id_str,user_url,user_description,user_translator_type,user_protected,user_verified,user_followers_count,user_friends_count,user_statuses_count,user_favourites_count,user_listed_count,user_is_translator,user_contributors_enabled,user_lang,user_geo_enabled,user_time_zone,user_utc_offset,user_created_at,user_profile_background_color,user_profile_background_image_url,user_profile_background_image_url_https,user_profile_background_tile,user_profile_link_color,user_profile_sidebar_border_color,user_profile_sidebar_fill_color,user_profile_text_color,user_profile_use_background_image
drop user_following,user_default_profile_image,user_follow_request_sent,user_notifications,extended_tweet,quoted_status_id,quoted_status_id_str,quoted_status,quoted_status_permalink
drop user_profile_image_url,user_profile_image_url_https,user_profile_banner_url,user_default_profile,extended_entities
fill-null-or-empty :possibly_sensitive 'false'
set-type :possibly_sensitive boolean
drop :entities
drop :user_location
Dataflow の変換処理(UDF の js)
/**
* User-defined function (UDF) to transform events
* as part of a Dataflow template job.
*
* @param {string} inJson input Pub/Sub JSON message (stringified)
*/
function process(inJson) {
// Nashorn engine is only ECMAScript 5.1 (ES5) compliant. Newer ES6
// JavaScript keywords like `let` or `const` will cause syntax errors.
var obj = JSON.parse(inJson);
var payload = JSON.parse(obj.payload);
var parsed = {
created_at: toTimestamp(payload.created_at),
id: payload.id,
text: payload.text,
source: payload.source,
in_reply_to_status_id: payload.in_reply_to_status_id,
in_reply_to_user_id: payload.in_reply_to_user_id,
in_reply_to_screen_name: payload.in_reply_to_screen_name,
quote_count: payload.quote_count,
reply_count: payload.reply_count,
retweet_count: payload.retweet_count,
favorite_count: payload.favorite_count,
lang: payload.lang,
timestamp_ms: payload.timestamp_ms,
user_id: payload.user.id,
user_name: payload.user.name,
user_screen_name: payload.user.screen_name,
possibly_sensitive: payload.possibly_sensitive,
};
return JSON.stringify(parsed);
}
function toTimestamp(inStr) {
var d = new Date(inStr);
var formatted_d = d.getFullYear()
+ '-' + ('0' + (d.getMonth() + 1)).slice(-2)
+ '-' + ('0' + d.getDate()).slice(-2)
+ ' ' + ('0' + d.getHours()).slice(-2)
+ ':' + ('0' + d.getMinutes()).slice(-2)
+ ':' + ('0' + d.getSeconds()).slice(-2)
+ ' UTC';
return formatted_d;
}
5. 検証結果
Data Fusion と Dataflow テンプレートの性能検証結果は以下のようになりました。
Data Fusion(デフォルト プロファイル)
| 件数*1 | 最大メッセージ数(秒間)*2 | 最大 BQ 書き込み件数(秒間)*3 | 合計処理時間(min)*4 |
|---|---|---|---|
| 867 | 14 | 14.45 | 1 |
| 86700 | 667 | 168.2 | 38 |
| 867000 | 9660 | 計測不可(途中でフリーズ) | 計測不可(途中でフリーズ) |
Dataflow テンプレート(Pub/Sub サブスクリプション to BigQuery)
| 件数*1 | 最大メッセージ数(秒間)*2 | 最大 BQ 書き込み件数(秒間)*3 | 合計処理時間(min)*4 |
|---|---|---|---|
| 867 | 14 | 3.81 | 6 |
| 86700 | 667 | 300 | 6 |
| 867000 | 9660 | 2600 | 6 |
*1 大元となるテキストファイルのレコード件数
*2 テキストファイルを Pub/Sub に変換したものの最大秒間メッセージ数(Cloud Monitoring 指標の「pubsub.googleapis.com/subscription/sent_message_count」を利用)
*3 BigQuery への最大秒間書き込み件数(Cloud Monitoring 指標の「bigquery.googleapis.com/storage/uploaded_row_count」と 「bigquery.googleapis.com/storage/insertall_inserted_rows」を利用)
*4 Pub/Sub へのリクスエストが発生してから、BigQuery への書き込みが完了するまでの処理時間
両者ともにデフォルト スペックで「最大 BQ 書き込み件数(秒間)」では Data Fusion が 168.2件/秒、Dataflow が 2600件/秒となり、Dataflow が優位となりました。Data Fusion では、テキストファイルのレコード件数が 867000 件(Pub/Sub での最大秒間メッセージ数が 9660 件)の場合に処理がフリーズして、BigQuery にデータを書き込むことができませんでした。一方で、Dataflow は件数が多くなっても全体処理時間が 6 分と変わらず、ストリーミング データに対して処理が遅延せず、うまくスケールできていることがわかります。
6. Data Fusion のチューニング(手動スケール方法)
ここで Data Fusion の設定をチューニングしてみます。現状だと、ストリーミング データに対する自動スケーリング機能がないため、手動でスケーリングする方法について検証してみました。
こちらの記事[5]を参考に、Pub/Sub Streaming Source と Configure の設定を以下のように変更したところ、エラーにならずに処理が完了しました。
-
Configure
-
Compute config:デプロイ後に設定可能
- Dataproc(プロファイル)
- Worker node configuration
- Worker Machine Type: e2
- Worker Cores:16
- Worker Memory (GB):32GB
- Worker node configuration
- Dataproc(プロファイル)
-
Pipeline config
- Batch interval:30min
-
Engine config
- Number of Executors:8
-
Resources
- Executor
- CPU:1
- Memory:2048
- Executor
-
-
Pub/Sub Streaming Source
- Number of Readers:8
ポイントは、Pub/Sub 読み込み時の処理性能を上げるために、「Pub/Sub Streaming Source」の「Number of Readers」をデフォルトの 1 から 8 に変更した点です。これによって並列度が高まり、大容量のデータを上手く処理することができるようになりました。注意点として、「Number of Readers」の数と 「Engine config」の「Number of Executors」の数は一致させる必要があります。また、Executor は Worker の内部に発生するプロセスのようなもので、Worker(親) が持つリソースを Executor(子) それぞれで分け合うため、「Worker Cores」 は Executor の数 と Executor の CPU を掛け算したものより大きくする必要があります。
今回の例だと、「Worker Cores」 が 16 で、「Number of Executors」が 8 であるため、Executor ひとつあたりの CPU は 2(= 16 / 8)以下の値を設定する必要があります。さらに、Memory についてはオーバーヘッド分を含めて確保する必要があるため、2.7 GB( = 32GB * 75% / 8 * 90%)以下にします。Data Fusion の裏側で動いている Dataproc(Apache Spark)の内部構造についてこちらの記事[6]を参考にしました(実際には、Executor 以外のワーカー VM が使うリソースも十分に確保する必要があるため、筆者の環境では余裕を持って Executor の CPU は 1、Memory は 2 GB(2048 MB) としました)。
また、「Batch interval」はデフォルトで 10 秒になっていますが、これだと書き込み間隔が短すぎるため、30 min に変更しました。
結果としては、以下のようになりました。「Batch interval」を増やしたことによってストリーミングデータを溜めて一気に書き込むようになったため、最大 BQ 書き込み件数が大幅に増えています。合計処理時間は 83 min となり、全体で 3,4 回書き込んで処理が終了しました。
Data Fusion(カスタム プロファイル かつ Pub/Sub Streaming Source の設定変更あり)
| 件数*1 | 最大メッセージ数(秒間)*2 | 最大 BQ 書き込み件数(秒間)*3 | 合計処理時間(min)*4 |
|---|---|---|---|
| 867000 | 9660 | 5560 | 83 |
7. まとめ
Data Fusion でストリーミング データをどのぐらい捌けるかを検証しました。現状だと、ストリーミング データに対する自動スケール機能がなく、大量のデータに対しては、デフォルトの設定だと処理がフリーズしてしまいました。しかし、Pub/Sub Streaming Source と Configure の設定を変更することで、エラーが解消し、手動スケールを実現することができました。ここらへんのチューニングは、Data Fusion の裏側で動いている CDAP や Apache Spark の仕様や内部構造を押さえておく必要があり、筆者としても苦労しました。Data Fusion はここ最近ユーザ数を伸ばしている印象があり、アップデートも積極的に行われているため、今後自動スケーリングにも対応することを期待したいと思います。一方で、今回比較対象とした Dataflow は想像以上に強いなと感じました。サーバを管理しなくていいのは楽で良いです。Data Fusion、Dataflow それぞれにメリット・デメリットありますが、ユースケースに応じて適切な技術選定とアーキテクチャ設計を行うことの重要性を改めて感じました。
8. [コラム]:BigQuery 書き込み方法の違い
Data Fusion では内部的にストリーミング データを AVRO フォーマットに変換し、バッチで書き込んでいるようでした。一方で、Dataflow テンプレートの方はストリーミング インサートを使って書き込んでいるようです。ストリーミング インサートはデータ量が多くなると課金に響いてくるため、最近ではBigQuery Storage Write API の利用が推奨[7]されているようです。今回のようにテンプレート(Pub/Sub Subscription to BigQuery)をそのまま使うのではなく、BigQuery Storage Write API を使うようにカスタマイズしてもいいかもしれません。
また、BigQuery 投入前に特段の加工集計処理が不要であれば、BigQuery サブスクリプション[8]がおすすめです。Dataflow 料金と BigQuery 書き込み料金が無料となり、Pub/Sub の料金しかかからないため、非常にコスパが良くなります。
-
https://www.cloudskillsboost.google/focuses/12365?parent=catalog ↩︎
-
https://tech.rhythm-corp.com/pubsub-to-bigquery-with-cloud-data-fusion-realtime-pipeline/ ↩︎
-
https://cloud.google.com/dataflow/docs/guides/templates/provided-streaming?hl=ja#pubsub-subscription-to-bigquery ↩︎
-
https://cloud.google.com/blog/ja/topics/developers-practitioners/extend-your-dataflow-template-with-udfs ↩︎
-
https://cdap.atlassian.net/wiki/spaces/DOCS/pages/1280638983/Pub+Sub+Streaming+Source+Best+Practices ↩︎
-
https://zenn.dev/hssh2_bin/articles/a79b0d9841a025120f29#2-3.-spark-driverとexecutor ↩︎
-
https://cloud.google.com/bigquery/docs/streaming-data-into-bigquery?hl=ja ↩︎
Discussion