Google Cloud コンソールから直接マテリアライズドビューのレプリカを作成する
Google Cloud コンソールから直接マテリアライズドビューのレプリカを作成する
はじめに
こんにちは、クラウドエース第一開発部の谷です。
本記事では、2024年9月30日にリリースされた、「Google Cloud コンソールから直接マテリアライズドビューのレプリカを作成する方法」についてご紹介します。
また、同時にマテリアライズドビューのレプリカを作成するまでを検証します。
検証では以前から可能だった SQL を使用する方法と、今回のリリースで可能になったコンソールからの方法の両方を実施して比較します。
注意事項
今回の検証結果は、2024年11月時点でのものになります。
あらかじめご了承くださいますようお願い申し上げます。
BigQuery の概要
BigQuery とは、Google Cloud で提供されているフルマネージドのサーバーレス データウェアハウスです。
ペタバイト規模のデータに対して高速なクエリを実行し、分析を行うことができます。
BigQuery のマテリアライズドビュー
BigQuery のマテリアライズドビューは、クエリ結果を事前に計算して保存しておくことで、クエリの高速化を実現する機能です。
従来のマテリアライズドビューは BigQuery 内部のデータに対してのみ作成可能でしたが、 BigLake メタデータ キャッシュ対応テーブルの登場により、Cloud StorageやAmazon S3 などの外部ストレージに保存されたデータに対してもマテリアライズドビューを作成できるようになりました。
主なメリット
- クエリのパフォーマンス向上: 事前に計算された結果を利用することで、クエリの実行速度が向上します。
- データ出力コストの削減: 外部ストレージからデータを読み込む必要がないため、データ出力コストを削減できます。
- データの事前集計、事前フィルタリング、事前結合、再クラスタ化: マテリアライズドビューを作成する際に、データの集計、フィルタリング、結合などを事前に行うことができます。
- 自動更新: ベースとなるテーブルのデータが更新されると、マテリアライズドビューも設定に応じて自動的に更新されます。自動更新はいつでも有効または無効にできます。有効の場合、デフォルトでは、キャッシュに保存されたマテリアライズドビューのデータは、ベーステーブルの変更から 5 ~ 30 分以内にベーステーブルから自動的に更新されます。手動更新はいつでも可能です。
BigLake メタデータ キャッシュ対応テーブルのマテリアライズドビュー
BigLake メタデータ キャッシュ対応テーブルに対するマテリアライズドビューでは、Cloud Storage と Amazon S3 に保存されている構造化データを参照できます。
注意点
Amazon S3 の BigLake テーブルに対してマテリアライズドビューを作成した場合、そのデータは BigQuery のデータと直接結合することができません。
結合を行うためには、マテリアライズドビューのレプリカを作成する必要があります。
以下は、弊社の BigLake メタデータキャッシュ対応テーブルのマテリアライズドビュー作成についての記事です。
ご参考になりましたら幸いです。
BigLake メタデータ キャッシュ対応テーブルに対してのマテリアライズドビュー作成が GA になりました
マテリアライズドビューのレプリカ
マテリアライズドビューのレプリカは、外部の Amazon S3、Apache Iceberg、または Salesforce Data Cloud のデータを BigQuery のデータセットに複製することで、BigQuery のローカルでデータを使用できるようにします。
主なメリット
- Amazon S3 などの外部データと BigQuery データの結合: レプリカを作成することで、外部データと BigQuery データを結合したクエリを実行できます。
- クエリのパフォーマンス向上: データが BigQuery 内に複製されるため、クエリのパフォーマンスが向上します。
- コストの削減: 外部ストレージからデータを読み込む必要がないため、データ出力コストを削減できます。
注意点
マテリアライズドビューのレプリカのデータの更新頻度は、レプリケーション間隔に加えて、ソース マテリアライズドビューの更新頻度とマテリアライズドビューの更新に使用される Amazon S3 テーブルのメタデータキャッシュの更新頻度にも影響される。
マテリアライズドビューのレプリカの作成方法について
コンソール操作によって、より直感的でわかりやすく手軽に設定を行えます。
本記事では、マテリアライズドビューの作成、マテリアライズドビューのレプリカの作成に対応している Amazon S3 を使用して実際にマテリアライズドビューを作成していきます。
マテリアライズドビューのレプリカの作成方法 (SQL)
マテリアライズドビューのレプリカについて、以下の手順に沿って行います。
上記の手順に従う前に、検証に使うデータを用意しておきます。
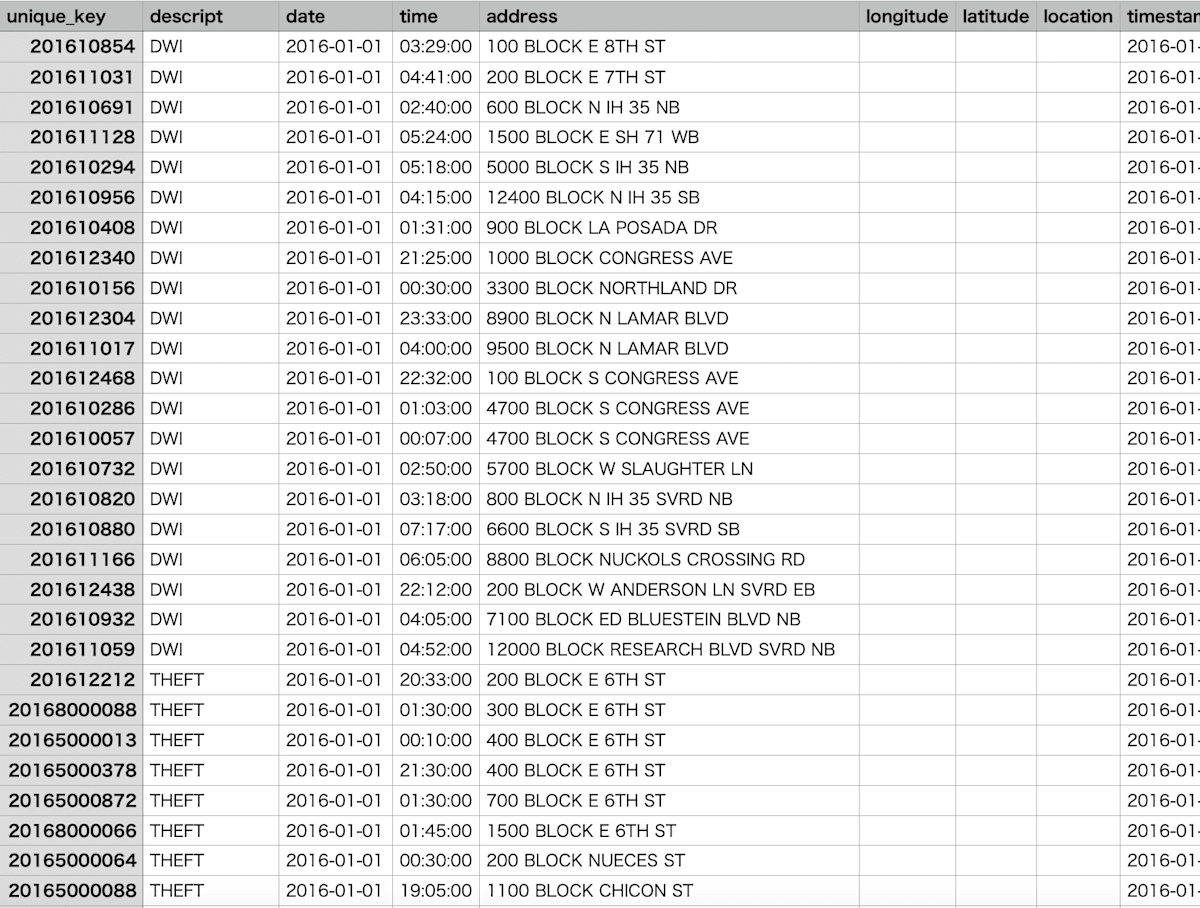
今回は、BigQuery のパブリックデータである austin_incidents.incidents_2016 から 1 月分だけ抽出し、CSV ファイルとして Amazon S3 のバケットにアップロードしています。
1. BigQuery とAmazon S3 を接続する
BigQuery と Amazon S3 の接続を作成します。
接続の名前と、Amazon S3 のバケットの S3_URI は後で使用します。
Amazon S3 に保存されているデータから BigLake テーブルを作成するためには、BigQuery Omni を使用します。
BigQuery Omni を使用することで、データをクラウド間でコピーすることなく、クエリを実行することができます。
2. Amazon S3 BigLake 外部テーブルを作成する
Amazon S3 BigLake 外部テーブルを作成する手順は以下の通りです。
- Amazon S3 のリージョンに合わせてデータセットを作成する
- メタデータキャッシュを有効にして、テーブルを作成する
サポートされているリージョンに合わせてデータセットを作成する必要があります。
今回は aws_dataset という名前で、Amazon S3 のバケットを作成したリージョン aws-us-east1 と同様に、BigQuery のデータセットも aws-us-east1 に作成します。
$ bq --location=aws-us-east-1 mk --dataset PROJECT_ID:aws_dataset
次にメタデータキャッシュを有効にして、BigLake テーブルを作成します。
メタデータキャッシュが有効になっていないとマテリアライズドビューの作成ができません。
コンソールから作成するとメタデータキャッシュが有効にならず苦戦したので、SQL文から作成しました。
今回はパーティション化されていないデータを用いて、テーブル名を aws_table と名付けました。
CONNECTION_NAMEは先ほど作成したコネクションの名前に置き換えて、S3_URI は接続した S3 のバケットのものを用いてください。
CREATE EXTERNAL TABLE aws_dataset.aws_table
WITH CONNECTION `aws-us-east-1.CONNECTION_NAME`
OPTIONS (
format = "CSV",
uris = ["S3_URL"],
max_staleness = INTERVAL 1 DAY,
metadata_cache_mode = 'AUTOMATIC');
作成したaws_tableのスキーマです。
マテリアライズドビューを作成
次に、マテリアライズドビューを作成します。
マテリアライズドビューの作成方法としては、SQL、Terraform、API、Java がありますが、SQL 文を使用します。
今回は mate_view という名前でマテリアライズドビューを作成しました。
データについて、gameId 列の重複を除いた値を抽出するクエリを用いています。
CREATE MATERIALIZED VIEW
`PROJECT_ID.aws_dataset.mate_view` OPTIONS (max_staleness=INTERVAL 1 DAY) AS(
SELECT
FORMAT('%02d-%02d', EXTRACT(MONTH FROM date), EXTRACT(DAY FROM date)) AS incident_date,
COUNT(descript) AS theft_count
FROM
aws_dataset.aws_table
GROUP BY incident_date
)
上記のクエリで作成した mate_view の中身を見てみましょう。
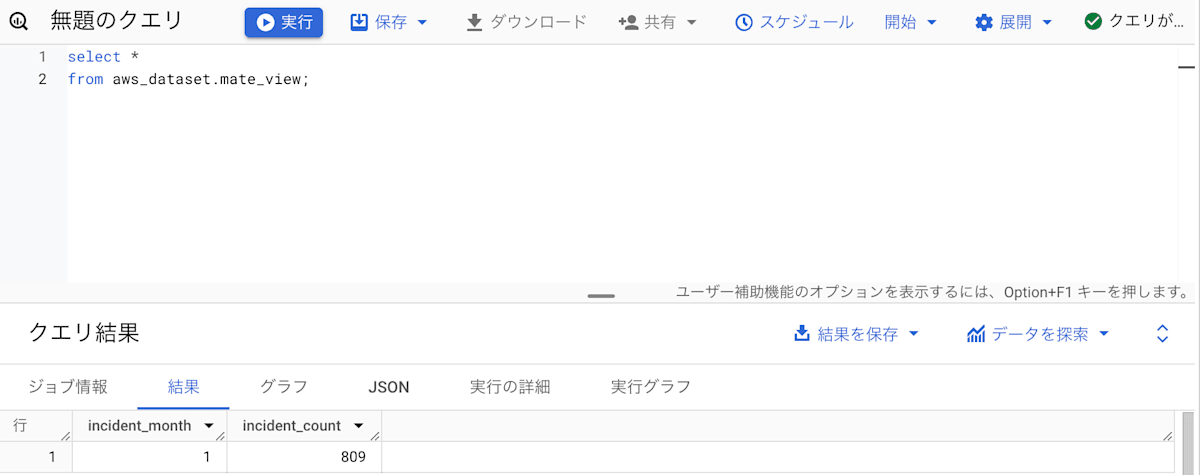
マテリアライズドビューのレプリカを作成
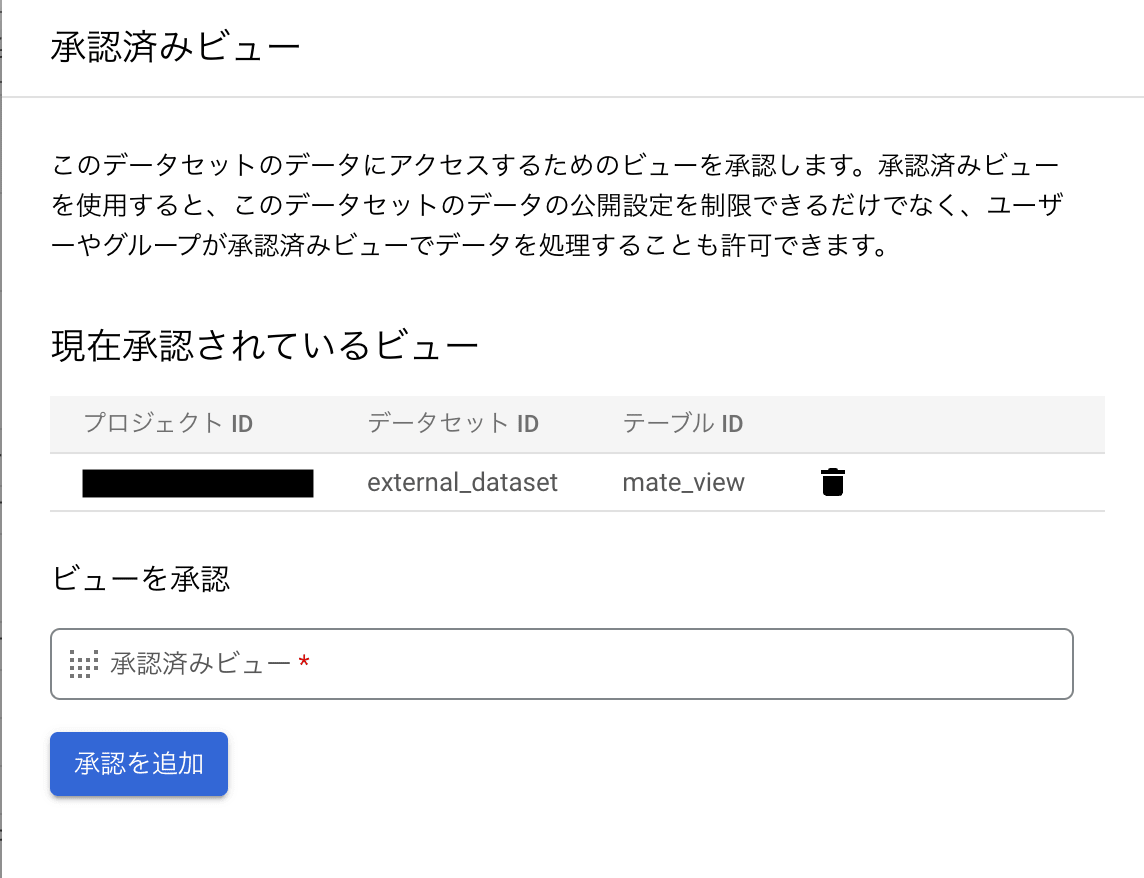
マテリアライズドビューのレプリカを作成するには、先ほど作成したマテリアライズドビューを承認する必要があります。
BigQuery のデータセット情報パネルで [共有] を選択し、[ビューの承認] を選択した後、承認するビューの名前を入力し、[承認の追加] をクリックします。
現在承認されているビューにマテリアライズドビューの名前があれば大丈夫です。
次に、マテリアライズドビューのレプリカを作成するデータセットを作成します。
データセットは、Amazon S3をサポートするリージョンで作成する必要があります。
今回は、マテリアライズドビューのデータセットは aws_us-east1 で作成したので、レプリカのデータセットは us-east1 で作成します。
$ bq --location=us-east1 mk --dataset PROJECT_ID:replica_dataset
SQL 文でレプリカを作成します。
レプリカを作成するデータセットは replica_dataset とし、作成するマテリアライズドビューのレプリカの名前を my_replica としています。
CREATE MATERIALIZED VIEW `PROJECT_ID.replica_dataset.my_replica`
OPTIONS(replication_interval_seconds=600)
AS REPLICA OF `PROJECT_ID.aws_dataset.mate_view`
replication_interval_seconds とは、ソースマテリアライズドビューからレプリカにデータを複製する頻度を秒単位で指定します。
60 から 3,600 までの値を指定でき、デフォルトでは 300 になります。
これを実行した結果、レプリカの作成に成功しました。
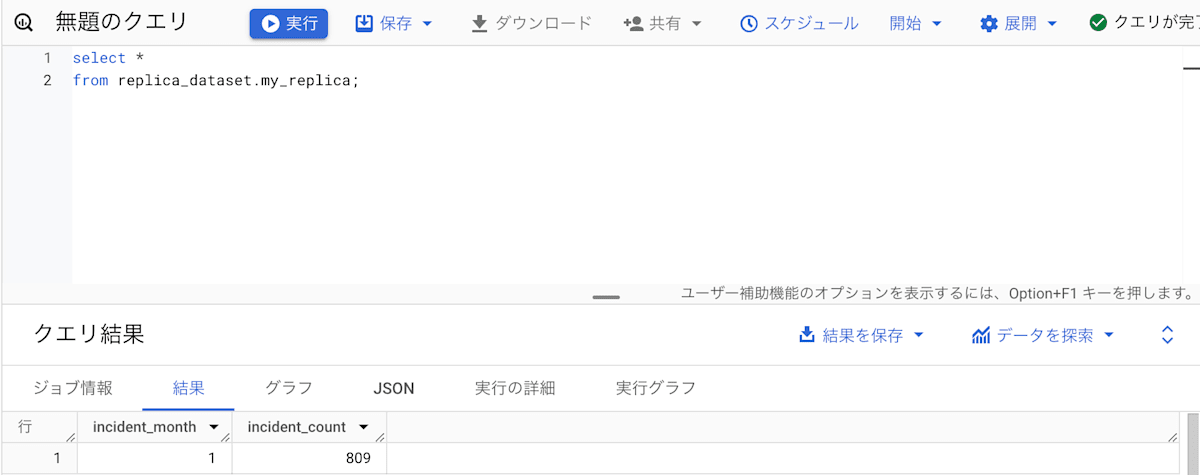
マテリアライズドビューのレプリカの作成方法(コンソール)
次に、コンソールからの作成方法を検証します。
コンソールでレプリカを作成する方法では、2、3、4 のステップがまとめて行われる仕様になっています。
の次のステップから、レプリカの作成を行います。
マテリアライズドビューのレプリカを作成するのドキュメントを参考に進めていきます。
- BigQuery のページに移動します。
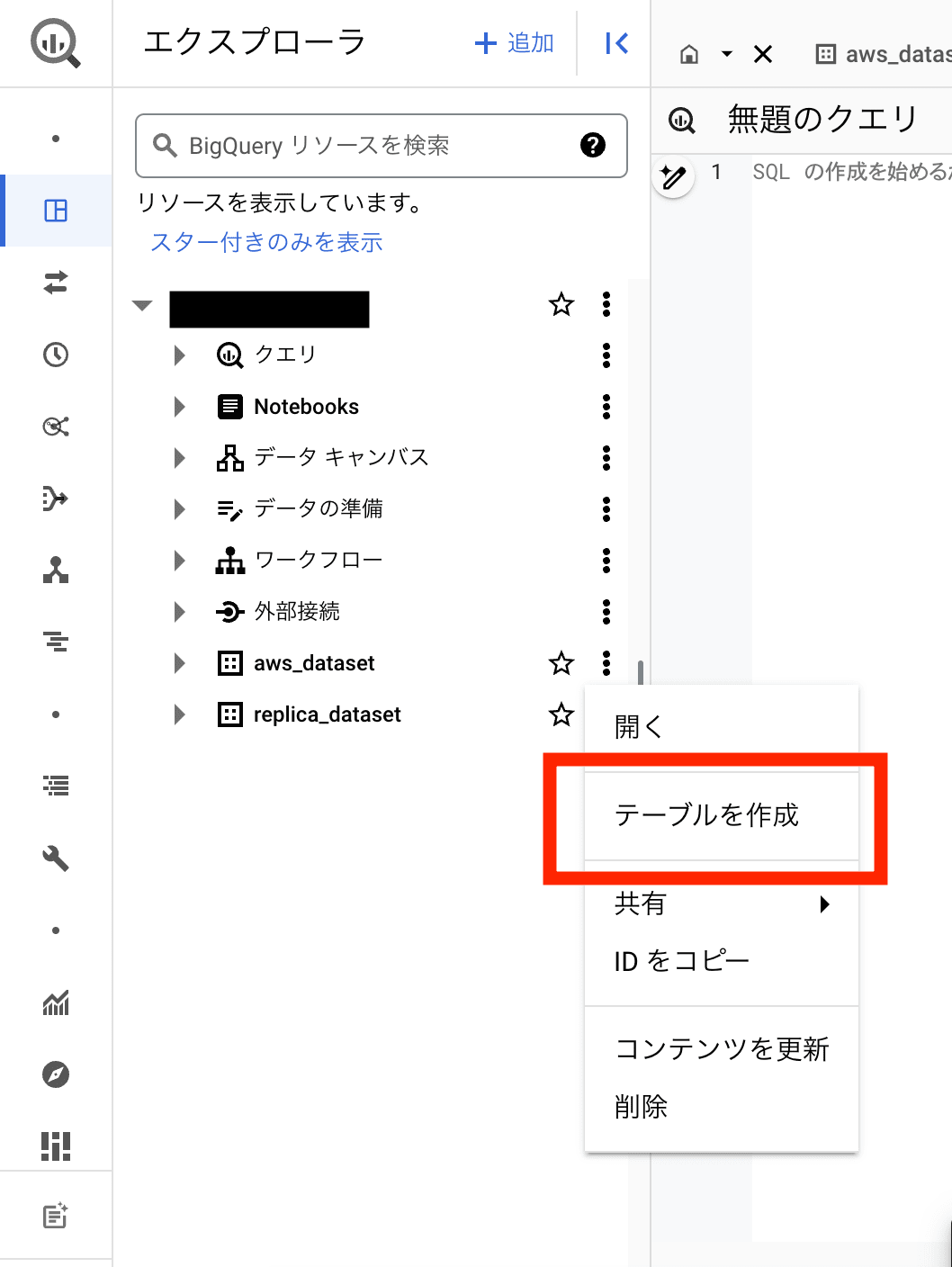
- エクスプローラペインで、マテリアライズドビューのレプリカを作成するプロジェクトとデータセットに移動し、︙ を開き、[テーブルの作成]を押します。
-
[テーブルを作成]で、以下のように操作します。
a. [テーブルの作成元]で、[既存のテーブル/ビュー]を選択します。
b. [プロジェクト]は、ソーステーブルまたはビューが配置されているプロジェクトを選択します。
c. [データセット]は、BigLake 外部テーブルがあるデータセットを選択します。今回の場合は、aws_dataset を選びます。
d. [表示]には、複製するソーステーブルまたはビューが配置されているデータセットを入力します。今回の場合は、aws_table を選びます。 -
[ローカルマテリアライズドビューの最大未更新]に、max_staleness 値を入力します。
コンソールでの作成方法では、マテリアライズドビューではなくローカルマテリアライズドビューと表記されているため、それに合わせます。

- [送信先]で、以下のように操作します。
a. [プロジェクト]は、マテリアライズドビューのレプリカを作成するプロジェクトを入力します。
b. [データセット]は、マテリアライズドビューのレプリカを作成するデータセットを選択します。今回の場合は先ほど作成した replica_dataset を選びます。
c. [レプリカのマテリアライズドビューの名前]に、レプリカの名前を入力します。今回の場合は、replica_console_mate_view としました。
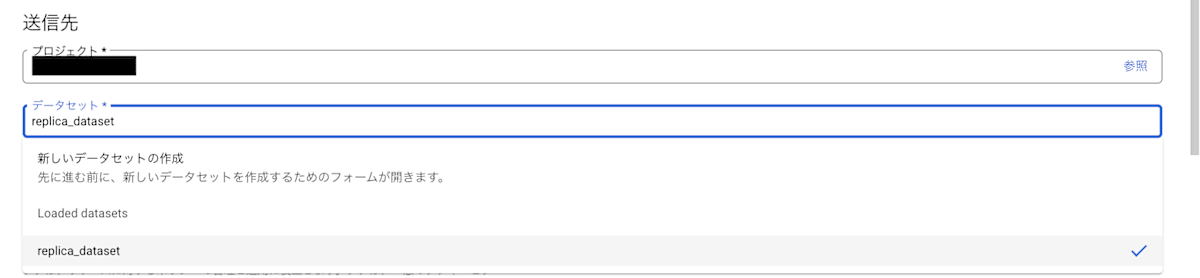
コンソールの方では、送信先を操作するタイミングでデータセットの作成も可能です。
- [詳細オプション]を開き、以下のように指定します。このステップは省略可能です。
[レプリケーション間隔(秒)]は、ソースマテリアライズドビューからレプリカにデータを複製する頻度を指定できます。
[ローカルマテリアライズドビュー データセット]では、ローカルマテリアライズドビューを作成するデータセット名を入力します。
入力されていない場合は、ソースデータと同じプロジェクトおよびリージョンにデータセットが自動的に作成されます。
[ローカルマテリアライズドビューの名前]に、ローカルマテリアライズドビューの名前を入力します。
今回の場合は、console_mate_view としました。
入力されていない場合、ソースデータと同じプロジェクトおよびリージョンに作成されます。
[ローカルマテリアライズドビューの更新間隔(分)]では、ローカルマテリアライズドビューを更新する頻度を指定できます。
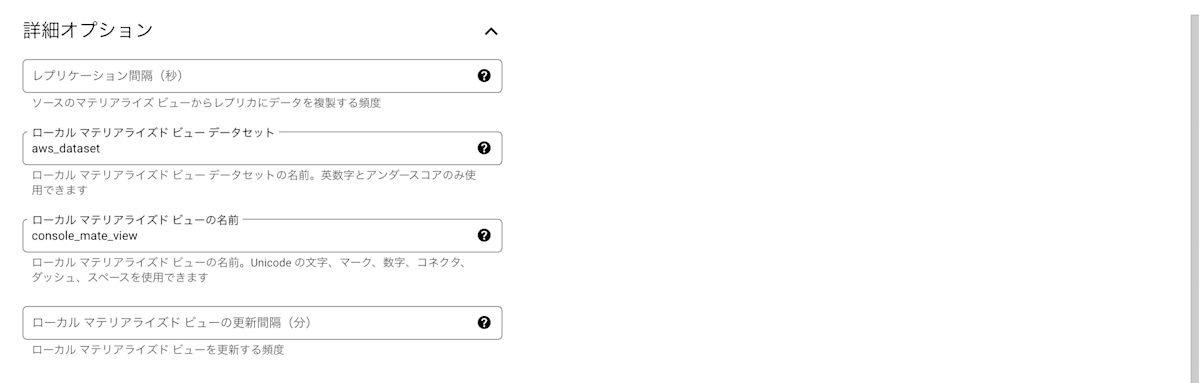
- [テーブルを作成]をクリックします。
新しいローカルマテリアライズドビューとローカルマテリアライズドビューのレプリカを作成できました。
確認してみましょう。
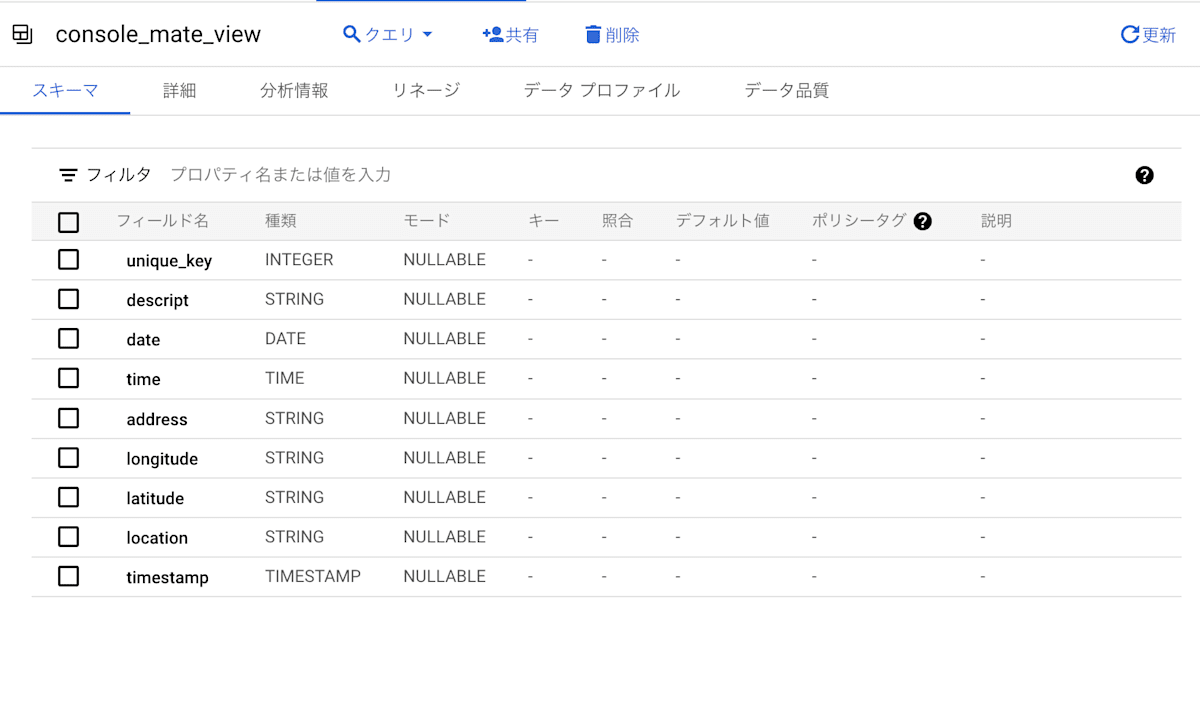
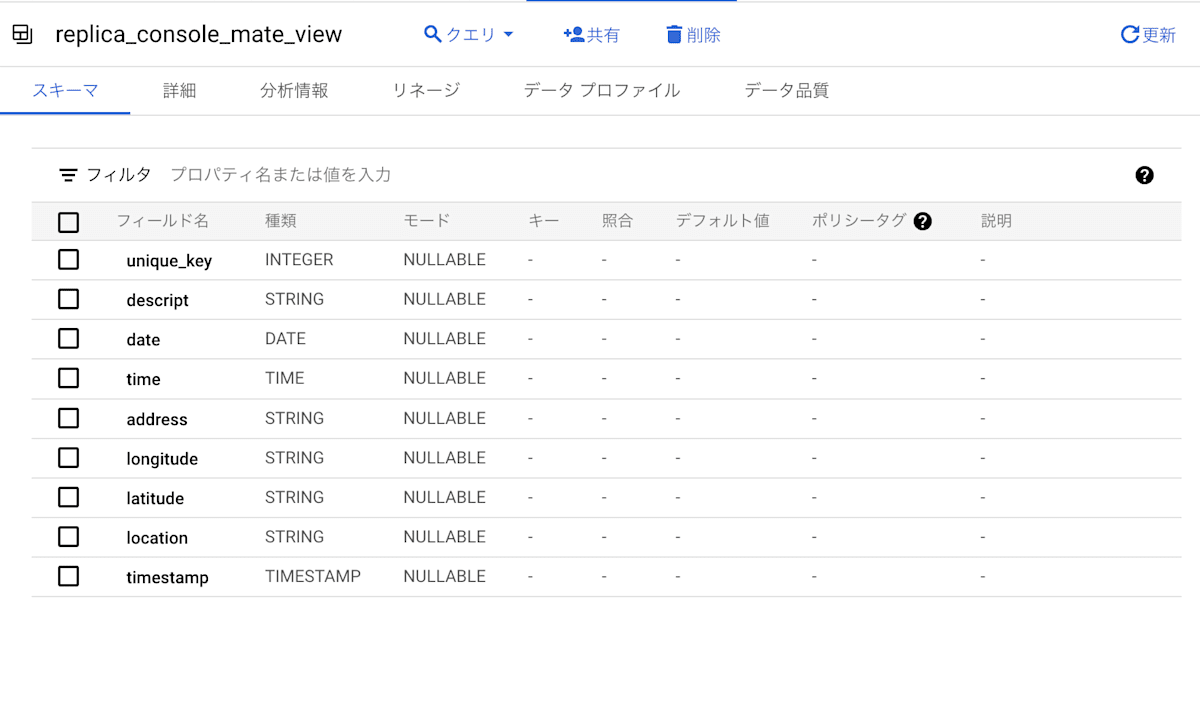
BigLake テーブルと同じスキーマのローカルマテリアライズドビューとローカルマテリアライズドビューのレプリカができています。
コンソールからの作成方法では、マテリアライズドビューを定義するクエリを入力するステップがないため、BigLake テーブルの複製が作成されます。
コンソールでの作成方法とSQL文での作成方法の比較
コンソールでの作成方法
BigLake 外部テーブルを作成さえすれば、コンソールから一括でローカルマテリアライズドビューとローカルマテリアライズドビューのレプリカを作成することができます。
しかし、現状ではマテリアライズドビューを定義することはできませんでした。
主なメリット
- ローカルマテリアライズドビューとローカルマテリアライズドビューのレプリカを一括で作成できます。
注意点
- マテリアライズド ビューを定義することはできません。
- 現状はローカル マテリアライズドビュー、ローカルマテリアライズドビューのレプリカは BigLake 外部テーブルの複製になります。
SQL文での作成方法
クエリを使用してマテリアライズドビューを作成することができますが、マテリアライズドビューとマテリアライズドビューのレプリカの作成を同時に行うことはできません。
作成したマテリアライズドビューを承認する必要もあるため、注意が必要です。
主なメリット
- クエリを使用してマテリアライズドビューを定義することができます。
注意点
- マテリアライズドビューとマテリアライズドビューのレプリカの作成は同時に行うことはできません。
まとめ
この記事では、Google Cloud コンソールから直接マテリアライズドビューのレプリカを作成する方法を紹介しました。
従来の方法、コンソールから直接作成できるようになったことで、より直感的でわかりやすく手軽に設定を行えるようになりました。
コンソールでの作成方法と SQL文での作成方法を比較検証した結果、それぞれにメリットと注意点があることがわかりました。
- コンソールでの作成方法では、BigLake 外部テーブルを作成さえすれば、ローカルマテリアライズドビューとローカルマテリアライズドビューのレプリカを一括で作成することができます。しかし、現状ではマテリアライズドビューを定義することはできません。
- SQL での作成方法では、クエリを使用してマテリアライズドビューを定義することができます。しかし、マテリアライズドビューとマテリアライズドビューのレプリカの作成を同時に行うことはできません。
どちらの方法を選択するかは、要件に合わせて判断する必要があります。
この記事が、BigQuery でのマテリアライズドビューのレプリカを作成する際の参考になれば幸いです。
Discussion