BigLake メタデータ キャッシュ対応テーブルに対してのマテリアライズド ビュー作成が GA になりました
はじめに
こんにちは、クラウドエース データ ML ディビジョン所属の仲佐です。
クラウドエースの IT エンジニアリングを担うシステム開発部の中で、特にデータ基盤構築・分析基盤構築からデータ分析までを含む一貫したデータ課題の解決を専門とするのがデータ ML ディビジョンです。
データ ML ディビジョンでは活動の一環として、毎週 Google Cloud の新規リリースを調査・発表し、データ領域のプロダクトのキャッチアップをしています。その中でも重要と考えるリリースを本ページ含め記事として公開しています。
今回紹介するリリースは、2023 年 9 月 25 日付に発表された「Cloud Storage に保存されているファイルを参照する BigLake メタデータ キャッシュ対応テーブルに対して、マテリアライズド ビューを作成する機能が GA(一般提供)になった」ことについてです。該当リリースノートはこちらです。
このリリースによって、BigQuery にデータを格納せずに、Cloud Storage にファイルを置いたままの状態でマテリアライズド ビューを作成するという機能が GA になりました。また、 BigLake メタデータ キャッシュ対応テーブルに対して、BigQuery テーブルでのマテリアライズド ビューと同様の利点が得られます。該当リリースノートでは例として、自動更新やスマート チューニングが機能するようになるとの記載がありました。
本記事では、以下のような流れで本リリースの紹介をしていきます
- BigLake について
- BigLake のメタデータ キャッシュ対応テーブルに対するマテリアライズド ビューについての説明とその利点
- 実際に検証をして本リリースの利点が得られているかを確認
BigLake について
BigLake とは、データ ウェアハウスとデータレイクを統合できるストレージ エンジンです。BigLake テーブルを作成することで、Cloud Storage、Amazon S3、Azure Data Lake Storage Gen 2 などのデータレイクに存在するファイルを BigQuery 上で扱うことができます。それによって、基盤となるストレージ形式やシステムを意識することなくデータを分析できるようにすることができ、データの複製や移動が不要になり、コスト削減と効率化を図ることができます。
詳細は Google Cloud Blog をご参照ください。
BigLake のメタデータ キャッシュ対応テーブルに対するマテリアライズド ビューについてとその利点
以下の流れで解説します。
- BigLake のメタデータ キャッシュ対応テーブルとは
- BigQuery でのマテリアライズド ビューとは
- BigLake のメタデータ キャッシュ対応テーブルに対するマテリアライズド ビューの利点
BigLake のメタデータ キャッシュ対応テーブルとは
BigLake のメタデータ キャッシュ対応テーブルとは、ファイルのメタデータ(ファイル名、パーティショニング情報、行数など)を一時的に保存しておくことで、BigLake テーブルに対するクエリ パフォーマンスを向上できることです。多数のファイルと Hive パーティション フィルタを使用したクエリでは、メタデータのキャッシュから最大限にメリットを得られます。詳細は パフォーマンス向上のためのメタデータ キャッシュ をご参照ください。
BigQuery でのマテリアライズド ビューとは
まず、BigQuery でのビューについて解説します。
ビューとは、SQL クエリによって定義される仮想テーブルです。ビューを参照するたびに、ビューを定義しているクエリが実行されます。
マテリアライズド ビューとは、物理的に格納されたビューのことで、クエリの結果を定期的にキャッシュに保存します。何度も同じクエリを使用するような場合に有用です。詳細は マテリアライズド(実体化)ビューの概要 をご参照ください。
BigLake のメタデータ キャッシュ対応テーブルに対するマテリアライズド ビューの利点
本リリースにより、BigLake メタデータ キャッシュ対応テーブルに対してマテリアライズド ビューを作成する機能が GA になりました。その利点として、BigQuery にデータを格納せずに、Cloud Storage にファイルを置いたままの状態でマテリアライズド ビューを作成できるようになったことが挙げられます。
また、BigLake メタデータ キャッシュ対応テーブルから作成されたマテリアライズド ビューは、BigQuery テーブルに対するマテリアライズド ビューと同様に機能するため、特に以下のような利点があります。
- 自動更新:一定時間ごとに、ベーステーブルの現在の状況が保存されたキャッシュに自動で更新されます。
- スマート チューニング:ベーステーブルに対するクエリの一部がマテリアライズド ビューへのクエリによって解決できる場合は、マテリアライズド ビューを使用するように BigQuery によってクエリのルートが変更され、パフォーマンスと効率が向上します。
実際に検証をして本リリースの利点が得られているかどうかを確認
ここでは実際に Cloud Storage に保存されているファイルを参照する BigLake メタデータ キャッシュ対応テーブルを作成し、そのマテリアライズド ビューを作成します。また、BigLake メタデータ キャッシュ対応テーブルのマテリアライズド ビューが BigQuery テーブルのマテリアライズド ビューと同様に自動更新やスマートチューニングの利点があることを確認します。
まずは BigLake メタデータ キャッシュ対応テーブルを作成します。
テーブルとして、Python で Faker ライブラリを用いて以下のようなランダムな名前や email などの情報を作り出しました。
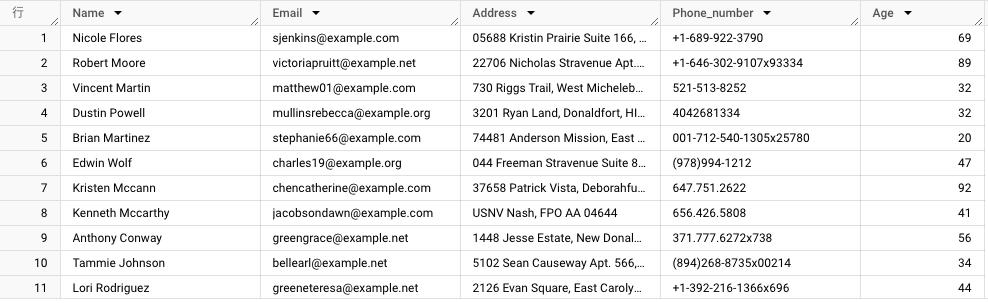
このテーブルを Cloud Storage に保存し、その保存されたテーブルを参照する BigLake メタデータ キャッシュ対応テーブルを作成します。作成方法は BigLake テーブルを作成して管理する と Cloud Storage BigLake テーブルを作成する をご参照ください。
クエリエディタで以下のステートメントを実行し、BigLake メタデータ キャッシュ対応テーブルのマテリアライズド ビューを作成します。
注意点として、BigLake テーブルからマテリアライズド ビューを作成するには、BigLake テーブルでメタデータ キャッシュが有効になっている必要があります。また、max_staleness オプション値はベーステーブルよりも大きくする必要があります。
CREATE MATERIALIZED VIEW
`プロジェクトID.データセット名.マテリアライズドビューの名前` OPTIONS (max_staleness=INTERVAL "1:00:0" HOUR TO SECOND) AS(
SELECT
Age
FROM
`プロジェクトID.データセット名.BigLakeテーブル名`)
まずは自動更新について検証します。すなわち、ベーステーブルの現在の状況がマテリアライズド ビューに自動で更新されることを確認します。
作成したマテリアライズド ビューに対して試しに以下のクエリを実行します。
SELECT
COUNT(*)
FROM
`プロジェクトID.データセット名.マテリアライズドビューの名前`
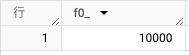
実行すると以下の結果が出力され、テーブルは 10000 行あることが分かります。
ここで、マテリアライズド ビューのベーステーブル(BigLake メタデータ キャッシュ対応テーブル)の最初の 1 行目を削除します。
その後、ベーステーブルに対して以下のクエリを実行します。
SELECT
COUNT(*)
FROM
`プロジェクトID.データセット名.BigLakeテーブル名`
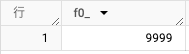
実行すると以下の結果が出力され、テーブルが 9999 行になり確かに 1 行減っていることが分かります。
一定時間後、マテリアライズド ビューに対しても以下の同様のクエリを実行します。
SELECT
COUNT(*)
FROM
`プロジェクトID.データセット名.マテリアライズドビューの名前`
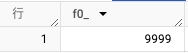
実行すると以下の結果が出力され、マテリアライズド ビューが 9999 行になっており、ベーステーブルの変更が自動でマテリアライズド ビューに反映されることが確認できました。
次に、スマート チューニングについて検証します。すなわち、マテリアライズド ビューを作成することで、ベーステーブルに対してのクエリのパフォーマンスが向上することを確認します。
テーブルとしては、BigQuery の一般公開データセットである bigquery-public-data.covid19_open_data.covid19_open_data を用います。これはその名の通り、以下のような COVID-19 のデータが格納されています。
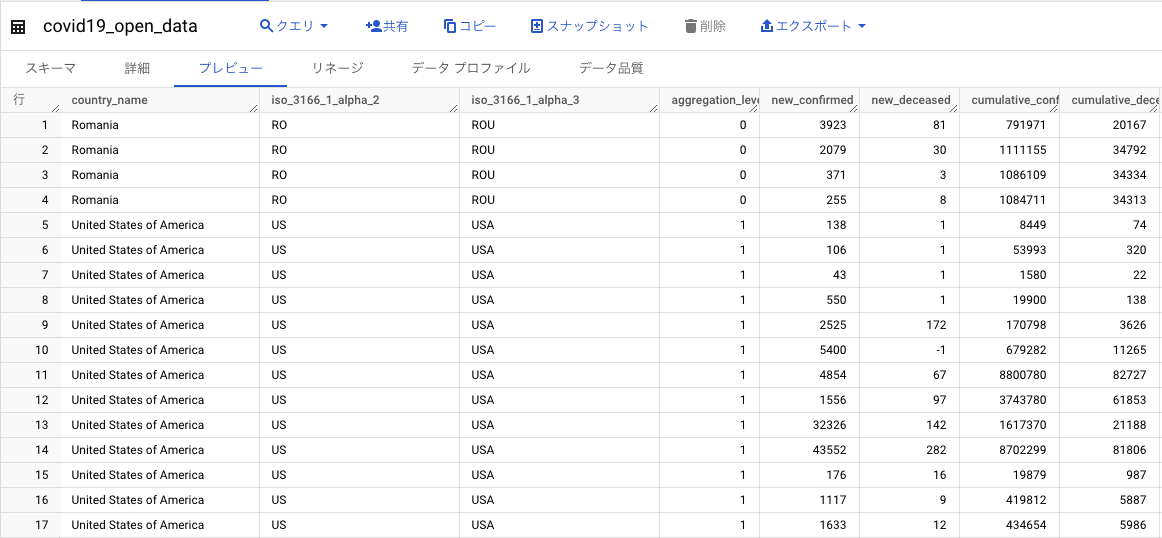
このテーブルを Cloud Storage に保存し、その保存されたテーブルを参照する BigLake メタデータ キャッシュ対応テーブルを作成します。
BigLake メタデータ キャッシュ対応テーブルに対して以下のクエリを実行します。
SELECT
country_name,
AVG(new_confirmed) AS sum_new_confirmed
FROM
`プロジェクトID.データセット名.BigLakeテーブル名`
GROUP BY
country_name
これで、国ごとの日次新規感染者数の平均値を求められました。
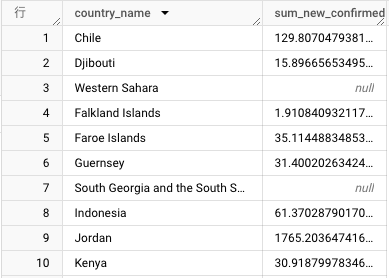
このクエリ結果を表示するために処理されたバイト数は 21.27GB でした。
ここで、クエリエディタで以下のステートメントを実行し、BigLake メタデータ キャッシュ対応テーブルのマテリアライズド ビューを作成します。
CREATE MATERIALIZED VIEW
`プロジェクトID.データセット名.マテリアライズドビューの名前` OPTIONS (max_staleness=INTERVAL "1:00:0" HOUR TO SECOND) AS(
SELECT
country_name,
AVG(new_confirmed) AS sum_new_confirmed
FROM
`プロジェクトID.データセット名.BigLakeテーブル名`
GROUP BY
country_name);
ここでは、biglake_table_materialized_view_covid19_open_data という名前のマテリアライズド ビューを作成しました。

マテリアライズド ビューを作成した後に、ベーステーブルに対して再度国ごとの日次新規感染者数の平均値を求めるクエリを実行します。
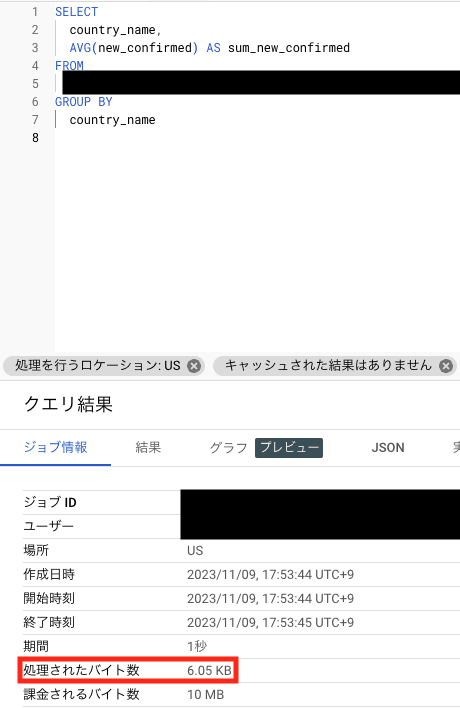
処理されたバイト数が 6.05KB になりました。
実行の詳細を見てみると、マテリアライズド ビューである biglake_table_materialized_view_covid19_open_data が確かに参照されていることが分かります。
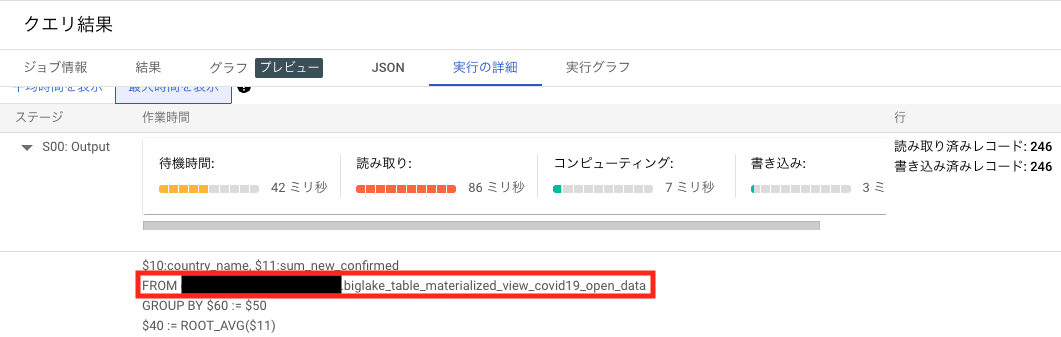
これにより、マテリアライズド ビューを作成したことでベーステーブルに対するクエリのパフォーマンスが向上することが確認できました。
まとめ
今回の記事では、「Cloud Storage に保存されているファイルを参照する BigLake メタデータ キャッシュ対応テーブルに対して、マテリアライズド ビューを作成する機能が GA(一般提供)になった」というリリースについて紹介をしました。特に以下についての紹介をしました。
- BigLake についての説明
- BigLake のメタデータ キャッシュ対応テーブルに対するマテリアライズド ビューについての説明とその利点
- 実際に検証をして本リリースの利点が得られているかを確認
ここまで読んでいただきありがとうございました。
Discussion