Dataplex の Managed connectivity pipelines が一般提供(GA)になりました
はじめに
こんにちは、クラウドエース株式会社 第一事業部の梅木です。
今回紹介するのは、2024年9月30日に GA となった Dataplex の「Managed connectivity pipelines」についてです。
Managed connectivity pipelines により、サードパーティソースのデータベースから Dataplex Catalog へメタデータをインポートする Workflows のパイプライン テンプレートが提供されました。
サードパーティソースの場合、従来は、メタデータをインポートする処理をユーザー自身で一から構築する必要がありましたが、このリリースにより外部データベースのメタデータ インポート処理の構築・運用が効率化されると考えられます。
また、メタデータの整備は近年重要性を増しており、データの理解や、データの検索に使えるだけでなく、データ品質の把握やデータリネージなどのガバナンス面でも、大きなメリットがあります。
最近では LLM モデルや画像説明モデルの性能向上などにもメタデータの利用が始まっているため、メタデータ収集を効率化する今回のリリースは Dataplex の有用性を高める重要なものであると考えられます。
Managed connectivity pipelines の概要
Managed connectivity pipelines では、Workflows を用いてサードパーティソースのデータベースから Dataplex Catalog へのメタデータのインポートを行います。
Workflows とは、サーバーレスのジョブの自動化サービスのことで、サーバーの管理や追加リソースの割り当てをユーザーが行うことなく、ジョブの自動実行やスケジュール実行が可能です。また、Workflows は、モニタリングや基本的なエラーハンドリングなども行うことができるため、パイプラインの管理・運用の手間を削減することも期待できます。
Managed connectivity pipelines における Workflows での処理についてイメージしやすくするために、以下に図を示します。
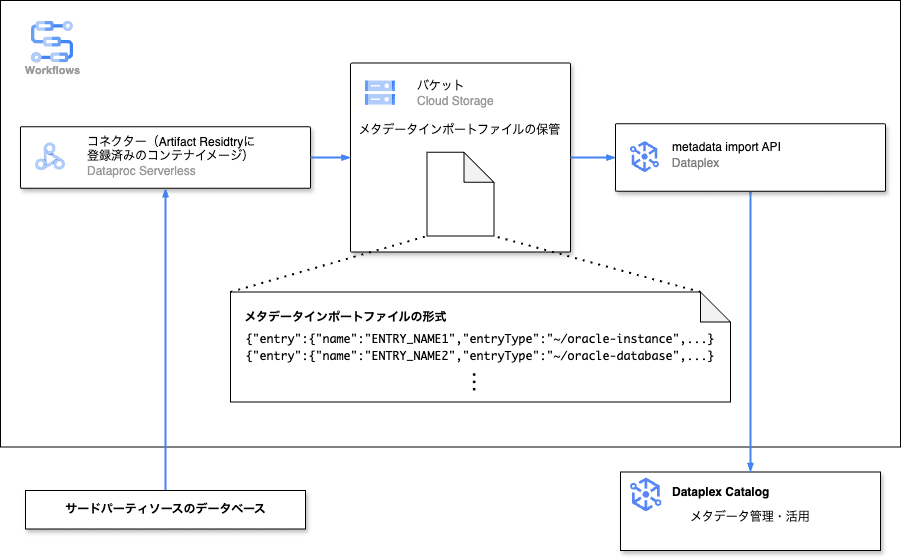
Managed connectivity pipelines の概略図
図の Workflows の処理で重要なのは、コネクター(コンテナイメージ)での処理と metadata import API による処理だと考えられます。コネクターでの処理は大まかに、
- サードパーティソース データベースへ接続する
- メタデータを抽出する
- メタデータインポートファイルを生成する
- Cloud Storage にメタデータインポートファイルをアップロードする
となっています。コネクターは、コンテナイメージとして Artifact Registry への登録が必要で、登録されたコンテナイメージは Dataproc Serverless で実行されることになるようです。また、このコネクターはメタデータを抽出したいデータベースによって自身でカスタムする必要があり、たたき台となるコードは公開されていますが、コネクターの自作には一定以上のコードスキルと Dataplex Catalog への理解が必要になると考えられます。
次に、metadata import API による処理です。ここでは、大まかに、
- バケットからメタデータインポートファイルを読み込む
- Dataplex Catalog へエントリを一括でインポートする
という流れの処理が行れています。読み込み可能な形式のメタデータインポートファイルと、Dataplex Catalog のリソース(エントリグループ、エントリタイプ、アスペクトタイプ)を準備すれば、Dataplex の API を用いて複数のエントリをまとめて Dataplex Catalog へ登録することが可能です。
したがって、サードパーティソースのデータベースに合わせたカスタムコネクター(コンテナイメージ)の作成は、ほぼ必須なようですが、Managed connectivity pipelines でそのイメージを指定することによって、サードパーティデータベースにおけるメタデータインポート処理の管理・運用が効率化されます。
また、コネクターを付け替えることで対応できる外部データベースは幅広く、MySQL、SQL Server、Oracle、Snowflake、Databricks など、データベースドライバーが提供されており、かつ Python、R、Java、Scala 経由で接続可能なデータベース全てが Managed connectivity pipelines の適応範囲だと考えられます。
実際に Managed connectivity pipelines を動かしてみた
今回はドキュメントにある Managed connectivity pipelines を実際に動かしてみました。
大まかな手順は以下になります。
- サードパーティデータベース(Oracle Database XE)の構築
- Managed connectivity pipelines の準備
2-a. 権限の付与
2-b. APIの有効化
2-c. Artifact Registry のリポジトリ作成
2-d. コネクターの作成
2-e. シークレットの作成
2-f. ネットワークの構成
2-g. Cloud Storage バケットの作成
2-h. Dataplex Catalog の準備
2-i. Workflows パイプラインのデプロイ - Managed connectivity pipelines の実行
動かす過程でつまづいた点や、検証の際見つかったバグの修正版などを載せておりますので、お試しいただく際の一助になれば幸いです。
準備
Oracle JDBC ドライバ(ojdbc11.jar)のインストール
Oracle Database の JDBC driver ダウンロードページにアクセスして、ojdbc11.jar をダウンロードしてください。こちら後ほど使用します。
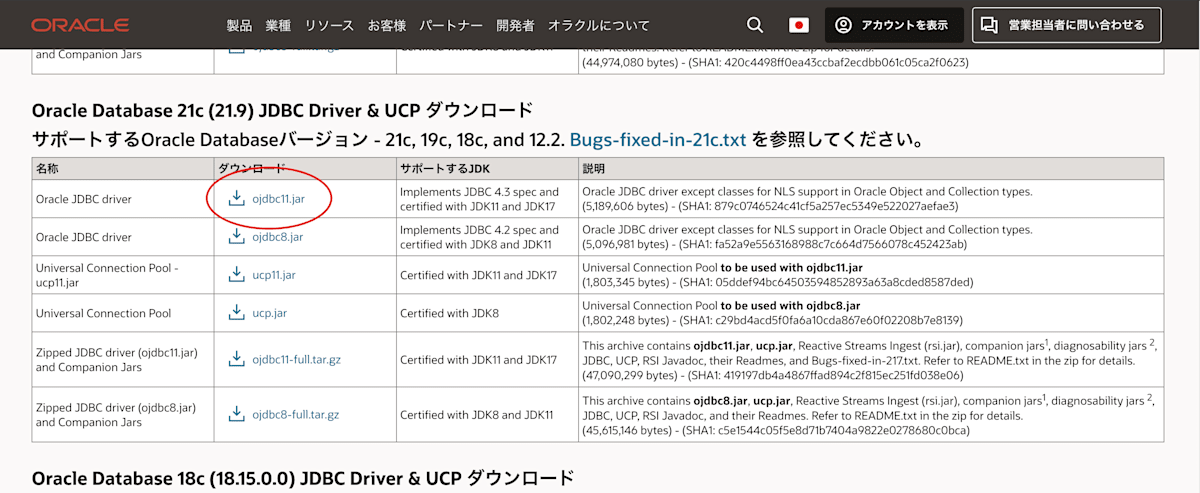
jar ファイルのダウンロードページ
Compute Engine の VM 上に Oracle Database XE を構築する
今回は、Compute Engine の VM 上に Oracle Database XE を構築するという過去記事を拝見し、作成リージョンのみ us-central1 に変更してデータベースを構築しました。作成方法は全く同じになりますので詳細はこちらをご覧ください。なお、次の手順でも VM 上の Cloud Shell を使用しますので、閉じずにそのままお進みください。
Oracle Net リスナーでホスト名、ポート番号を確認する
Oracle Database XE の構築が完了しましたら、以下の手順で Oracle Net Listener(リスナー)を開き、ホーム名とポート番号を確認します。
リスナーとは、データベースへの接続要求を最初に受信する窓口のようなもので、リスナーに登録されている受け入れ可能なクライアント接続の構成を満たすリクエストのみ、 Oracle Database への接続を許可します。そのため、リスナーに登録されている構成を用いて、Managed connectivity pipelines から接続要求を送信する必要があります。
リスナーのステータスを確認するためには、SQL から exit で抜けたあと、lsnrctl status と入力します。
SQL> exit
$ lsnrctl status
すると、以下のようなステータス画面が表示されるので、赤線の部分からホスト名とポート番号を確認し、メモしておきましょう。後ほど workflow の実行引数として使用します。
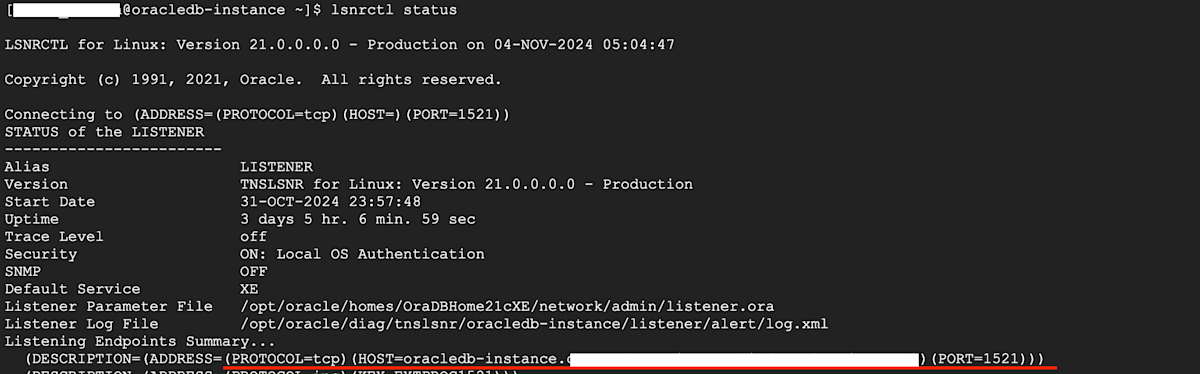
リスナーのステータス画面
確認できたら、VM 上の Cloud Shell は閉じてしまって大丈夫です。
権限の付与
今回は、Compute Engine のデフォルトサービスアカウントを用いて、パイプラインを実行します。サービスアカウントに、以下の権限を付与してください。
- Logs Writer
- Dataplex Entry Group Owner
- Dataplex Metadata Job Owner
- Dataplex Catalog Editor
- Dataproc Editor
- Dataproc Worker
- Secret Manager Secret Accessor
- Storage Object User
- Artifact Registry Reader
- Service Account User
- Workflows Invoker
API の有効化
Workflows API、Dataproc API、Cloud Storage API、Dataplex API、Secret Manager API、Artifact Registry API、Cloud Scheduler API を有効化します。公式ドキュメントに必要な API をまとめて有効化できるボタンがあるのでそちらを踏んでいただくとスムーズかと思います。
API の有効化
Artifact Registry のリポジトリ作成
Managed connectivity pipelines に必要なコネクター(コンテナイメージ)を登録する Artifact Registry のリポジトリを作成します。
- リポジトリ名は
docker-repoとしていただき、Format がDocker、Mode がStandard、Location type がRegionに設定されていることを確認してください。また、Region は今回us-central1を選択します。 - その他の値はデフォルト値のまま、リポジトリを作成してください。
コネクターの作成
この度リリースされた Managed connectivity pipelines により、Workflows のパイプライン テンプレートが提供されましたが、外部データベースに接続しメタデータインポートファイルを生成するためのコネクター(コンテナイメージ)部分は自作が必要です。
この記事を書くにあたってもコネクター部分を動かすことに苦労しましたが、管理するデータベースのテーブルやビューが多く、またそれらの関係性が複雑なほど自動化する価値はなかなか高いと考えられます。
コネクターのテンプレートは Github に公開されていましたので、今回はこちらを用いていきます。
- まず、cloud-dataplex リポジトリをクローンし、コネクターのテンプレートコードが入っているディレクトリに移動します。
git clone https://github.com/GoogleCloudPlatform/cloud-dataplex.git
cd cloud-dataplex/managed-connectivity/sample-custom-connector
- カレントディレクトリに、先ほどダウンロードした ojdbc11.jar ファイルを配置してください。
- build_and_push_docker.shを開き、4行目に自身のプロジェクトIDを設定します。
#!/bin/bash
IMAGE=oracle-pyspark:0.0.1
PROJECT=<YOUR_PROJECT_ID>
REPO_IMAGE=us-central1-docker.pkg.dev/${PROJECT}/docker-repo/oracle-pyspark
docker build -t "${IMAGE}" .
# Tag and push to GCP container registry
gcloud config set project ${PROJECT}
gcloud auth configure-docker us-central1-docker.pkg.dev
docker tag "${IMAGE}" "${REPO_IMAGE}"
docker push "${REPO_IMAGE}"
- src/bootstrap.py を開き、50行目に
file.writelines("\n")を追加します。以下の bootstrap.py コード全文で、緑にハイライトされた部分が修正必要箇所です。
bootstrap.py コード全文
"""The entrypoint of a pipeline."""
from typing import Dict
from src.constants import EntryType
from src import cmd_reader
from src import secret_manager
from src import entry_builder
from src import gcs_uploader
from src import top_entry_builder
from src.oracle_connector import OracleConnector
FILENAME = "output.jsonl"
def write_jsonl(output_file, json_strings):
"""Writes a list of string to the file in JSONL format."""
# For simplicity, dataset is written into the one file. But it is not
# mandatory, and the order doesn't matter for Import API.
# The PySpark itself could dump entries into many smaller JSONL files.
# Due to performance, it's recommended to dump to many smaller files.
for string in json_strings:
output_file.write(string + "\n")
def process_dataset(
connector: OracleConnector,
config: Dict[str, str],
schema_name: str,
entry_type: EntryType,
):
"""Builds dataset and converts it to jsonl."""
df_raw = connector.get_dataset(schema_name, entry_type)
df = entry_builder.build_dataset(config, df_raw, schema_name, entry_type)
return df.toJSON().collect()
def run():
"""Runs a pipeline."""
config = cmd_reader.read_args()
config["password"] = secret_manager.get_password(config["password_secret"])
connector = OracleConnector(config)
with open(FILENAME, "w", encoding="utf-8") as file:
# Write top entries that don't require connection to the database
file.writelines(top_entry_builder.create(config, EntryType.INSTANCE))
file.writelines("\n")
file.writelines(top_entry_builder.create(config, EntryType.DATABASE))
+ file.writelines("\n")
# Get schemas, write them and collect to the list
df_raw_schemas = connector.get_db_schemas()
schemas = [schema.USERNAME for schema in df_raw_schemas.select("USERNAME").collect()]
schemas_json = entry_builder.build_schemas(config, df_raw_schemas).toJSON().collect()
write_jsonl(file, schemas_json)
# Ingest tables and views for every schema in a list
for schema in schemas:
print(f"Processing tables for {schema}")
tables_json = process_dataset(connector, config, schema, EntryType.TABLE)
write_jsonl(file, tables_json)
print(f"Processing views for {schema}")
views_json = process_dataset(connector, config, schema, EntryType.VIEW)
write_jsonl(file, views_json)
gcs_uploader.upload(config, FILENAME)
- src/name_builder.py を開き、70行目にエントリがビューの場合の処理を追加します。以下の name_builder.py コード全文で、緑にハイライトされた部分が追加箇所です。
name_builder.py コード全文
"""Builds Dataplex hierarchy identifiers."""
from typing import Dict
from src.constants import EntryType, SOURCE_TYPE
# Oracle cluster users start with C## prefix, but Dataplex doesn't accept #.
# In that case in names it is changed to C!!, and escaped with backticks in FQNs
FORBIDDEN_SYMBOL = "#"
ALLOWED_SYMBOL = "!"
def create_fqn(config: Dict[str, str], entry_type: EntryType,
schema_name: str = "", table_name: str = ""):
"""Creates a fully qualified name or Dataplex v1 hierarchy name."""
if FORBIDDEN_SYMBOL in schema_name:
schema_name = f"`{schema_name}`"
if entry_type == EntryType.INSTANCE:
# Requires backticks to escape column
return f"{SOURCE_TYPE}:`{config['host_port']}`"
if entry_type == EntryType.DATABASE:
instance = create_fqn(config, EntryType.INSTANCE)
return f"{instance}.{config['database']}"
if entry_type == EntryType.DB_SCHEMA:
database = create_fqn(config, EntryType.DATABASE)
return f"{database}.{schema_name}"
if entry_type in [EntryType.TABLE, EntryType.VIEW]:
database = create_fqn(config, EntryType.DATABASE)
return f"{database}.{schema_name}.{table_name}"
return ""
def create_name(config: Dict[str, str], entry_type: EntryType,
schema_name: str = "", table_name: str = ""):
"""Creates a Dataplex v2 hierarchy name."""
if FORBIDDEN_SYMBOL in schema_name:
schema_name = schema_name.replace(FORBIDDEN_SYMBOL, ALLOWED_SYMBOL)
if entry_type == EntryType.INSTANCE:
name_prefix = (
f"projects/{config['target_project_id']}/"
f"locations/{config['target_location_id']}/"
f"entryGroups/{config['target_entry_group_id']}/"
f"entries/"
)
return name_prefix + config["host_port"].replace(":", "@")
if entry_type == EntryType.DATABASE:
instance = create_name(config, EntryType.INSTANCE)
return f"{instance}/databases/{config['database']}"
if entry_type == EntryType.DB_SCHEMA:
database = create_name(config, EntryType.DATABASE)
return f"{database}/database_schemas/{schema_name}"
if entry_type == EntryType.TABLE:
db_schema = create_name(config, EntryType.DB_SCHEMA, schema_name)
return f"{db_schema}/tables/{table_name}"
if entry_type == EntryType.VIEW:
db_schema = create_name(config, EntryType.DB_SCHEMA, schema_name)
return f"{db_schema}/views/{table_name}"
return ""
def create_parent_name(config: Dict[str, str], entry_type: EntryType,
parent_name: str = ""):
"""Generates a Dataplex v2 name of the parent."""
if entry_type == EntryType.DATABASE:
return create_name(config, EntryType.INSTANCE)
if entry_type == EntryType.DB_SCHEMA:
return create_name(config, EntryType.DATABASE)
if entry_type == EntryType.TABLE:
return create_name(config, EntryType.DB_SCHEMA, parent_name)
+ if entry_type == EntryType.VIEW:
+ return create_name(config, EntryType.DB_SCHEMA, parent_name)
return ""
def create_entry_aspect_name(config: Dict[str, str], entry_type: EntryType):
"""Generates an entry aspect name."""
last_segment = entry_type.value.split("/")[-1]
return f"{config['target_project_id']}.{config['target_location_id']}.{last_segment}"
- src/entry_builder.py を開き、116行目にバックスラッシュ(\)を追加してください。また117行目に、
.dropDuplicates(["TABLE_NAME", "name"])を追加し、156行目をparent_name = nb.create_parent_name(config, entry_type, db_schema)に修正してください。以下の entry_builder.py コード全文で、緑にハイライトされた部分が修正必要箇所です。
entry_builder.py コード全文
"""Creates entries with PySpark."""
import pyspark.sql.functions as F
from pyspark.sql.types import StringType
from src.constants import EntryType, SOURCE_TYPE
from src import name_builder as nb
@F.udf(returnType=StringType())
def choose_metadata_type_udf(data_type: str):
"""Choose the metadata type based on Oracle native type."""
if data_type.startswith("NUMBER") or data_type in ["FLOAT", "LONG"]:
return "NUMBER"
if data_type.startswith("VARCHAR") or data_type.startswith("NVARCHAR2"):
return "STRING"
if data_type == "DATE":
return "DATETIME"
return "OTHER"
def create_entry_source(column):
"""Create Entry Source segment."""
return F.named_struct(F.lit("display_name"),
column,
F.lit("system"),
F.lit(SOURCE_TYPE))
def create_entry_aspect(entry_aspect_name):
"""Create aspect with general information (usually it is empty)."""
return F.create_map(
F.lit(entry_aspect_name),
F.named_struct(
F.lit("aspect_type"),
F.lit(entry_aspect_name),
F.lit("data"),
F.create_map()
)
)
def convert_to_import_items(df, aspect_keys):
"""Convert entries to import items."""
entry_columns = ["name", "fully_qualified_name", "parent_entry",
"entry_source", "aspects", "entry_type"]
# Puts entry to "entry" key, a list of keys from aspects in "aspects_keys"
# and "aspects" string in "update_mask"
return df.withColumn("entry", F.struct(entry_columns)) \
.withColumn("aspect_keys", F.array([F.lit(key) for key in aspect_keys])) \
.withColumn("update_mask", F.array(F.lit("aspects"))) \
.drop(*entry_columns)
def build_schemas(config, df_raw_schemas):
"""Create a dataframe with database schemas from the list of usernames.
Args:
df_raw_schemas - a dataframe with only one column called USERNAME
Returns:
A dataframe with Dataplex-readable schemas.
"""
entry_type = EntryType.DB_SCHEMA
entry_aspect_name = nb.create_entry_aspect_name(config, entry_type)
# For schema, parent name is the name of the database
parent_name = nb.create_parent_name(config, entry_type)
# Create user-defined function.
create_name_udf = F.udf(lambda x: nb.create_name(config, entry_type, x),
StringType())
create_fqn_udf = F.udf(lambda x: nb.create_fqn(config, entry_type, x),
StringType())
# Fills the missed project and location into the entry type string
full_entry_type = entry_type.value.format(
project=config["target_project_id"],
location=config["target_location_id"])
# Converts a list of schema names to the Dataplex-compatible form
column = F.col("USERNAME")
df = df_raw_schemas.withColumn("name", create_name_udf(column)) \
.withColumn("fully_qualified_name", create_fqn_udf(column)) \
.withColumn("parent_entry", F.lit(parent_name)) \
.withColumn("entry_type", F.lit(full_entry_type)) \
.withColumn("entry_source", create_entry_source(column)) \
.withColumn("aspects", create_entry_aspect(entry_aspect_name)) \
.drop(column)
df = convert_to_import_items(df, [entry_aspect_name])
return df
def build_dataset(config, df_raw, db_schema, entry_type):
"""Build table entries from a flat list of columns.
Args:
df_raw - a plain dataframe with TABLE_NAME, COLUMN_NAME, DATA_TYPE,
and NULLABLE columns
db_schema - parent database schema
entry_type - entry type: table or view
Returns:
A dataframe with Dataplex-readable data of tables of views.
"""
schema_key = "dataplex-types.global.schema"
# The transformation below does the following
# 1. Alters NULLABLE content from Y/N to NULLABLE/REQUIRED
# 2. Renames NULLABLE to mode
# 3. Renames DATA_TYPE to dataType
# 4. Creates metadataType column based on dataType column
# 5. Renames COLUMN_NAME to name
df = df_raw \
.withColumn("mode", F.when(F.col("NULLABLE") == 'Y', "NULLABLE").otherwise("REQUIRED")) \
.drop("NULLABLE") \
.withColumnRenamed("DATA_TYPE", "dataType") \
.withColumn("metadataType", choose_metadata_type_udf("dataType")) \
+ .withColumnRenamed("COLUMN_NAME", "name") \
+ .dropDuplicates(["TABLE_NAME", "name"])
# The transformation below aggregate fields, denormalizing the table
# TABLE_NAME becomes top-level filed, and the rest is put into
# the array type called "fields"
aspect_columns = ["name", "mode", "dataType", "metadataType"]
df = df.withColumn("columns", F.struct(aspect_columns))\
.groupby('TABLE_NAME') \
.agg(F.collect_list("columns").alias("fields"))
# Create nested structured called aspects.
# Fields are becoming a part of a `schema` struct
# There is also an entry_aspect that is repeats entry_type as aspect_type
entry_aspect_name = nb.create_entry_aspect_name(config, entry_type)
df = df.withColumn("schema",
F.create_map(F.lit(schema_key),
F.named_struct(
F.lit("aspect_type"),
F.lit(schema_key),
F.lit("data"),
F.create_map(F.lit("fields"),
F.col("fields")))
)
)\
.withColumn("entry_aspect", create_entry_aspect(entry_aspect_name)) \
.drop("fields")
# Merge separate aspect columns into the one map called 'aspects'
df = df.select(F.col("TABLE_NAME"),
F.map_concat("schema", "entry_aspect").alias("aspects"))
# Define user-defined functions to fill the general information
# and hierarchy names
create_name_udf = F.udf(lambda x: nb.create_name(config, entry_type,
db_schema, x),
StringType())
create_fqn_udf = F.udf(lambda x: nb.create_fqn(config, entry_type,
db_schema, x), StringType())
+ parent_name = nb.create_parent_name(config, entry_type, db_schema)
full_entry_type = entry_type.value.format(
project=config["target_project_id"],
location=config["target_location_id"])
# Fill the top-level fields
column = F.col("TABLE_NAME")
df = df.withColumn("name", create_name_udf(column)) \
.withColumn("fully_qualified_name", create_fqn_udf(column)) \
.withColumn("entry_type", F.lit(full_entry_type)) \
.withColumn("parent_entry", F.lit(parent_name)) \
.withColumn("entry_source", create_entry_source(column)) \
.drop(column)
df = convert_to_import_items(df, [schema_key, entry_aspect_name])
return df
- 最後に、これらをコンテナとしてビルドし、Artifact Registry にプッシュします。以下のコマンドを実行してください。
bash build_and_push_docker.sh
データベースのパスワードをシークレットに保管する
Oracle Database XE のパスワードをシークレットに保存します。シークレットに保管することで、Workflow からパスワードを安全に参照できます。
- [Secret Manager] ページにアクセスします。
- シークレットの名前に
passwordと入力し、Secret value にメモしたパスワードを入力します。画像の例では、パスワードが、OraclePass1234の場合を示しています。
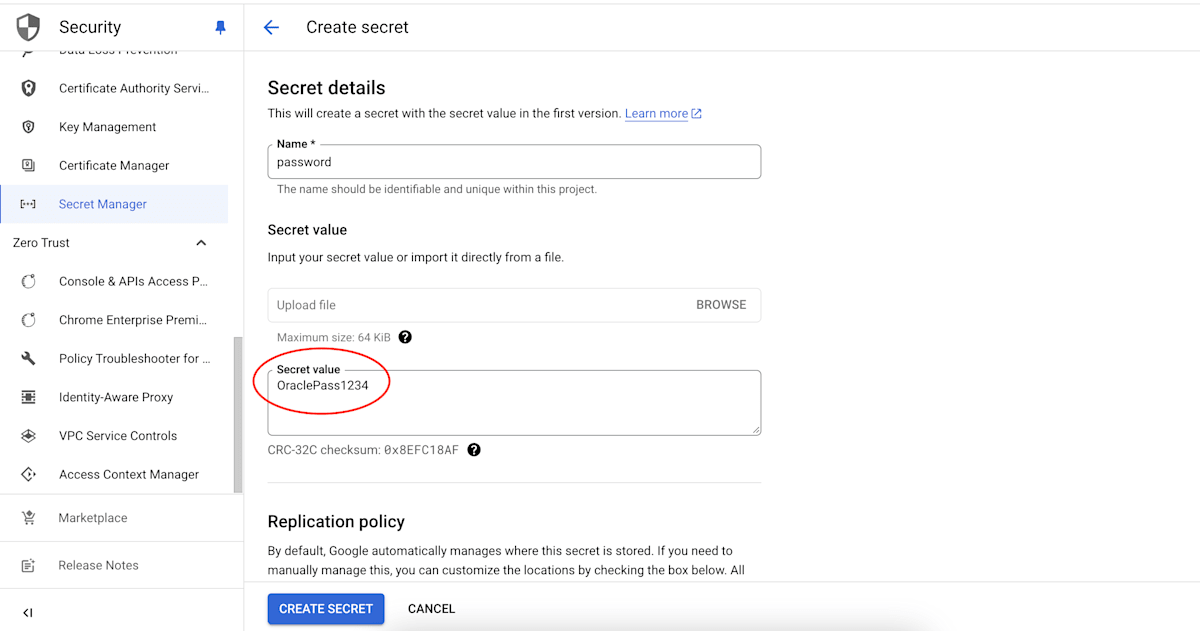
パスワードをシークレットに保管する - [CREATE SECRET] ボタンをクリックし、シークレットを作成します。
- パスワードを参照するための Resource ID は、作成した password の右端の Actions から Edit 画面を開き確認することができます。後ほど workflow の実行引数として使用しますのでこちらはメモしておいてください。
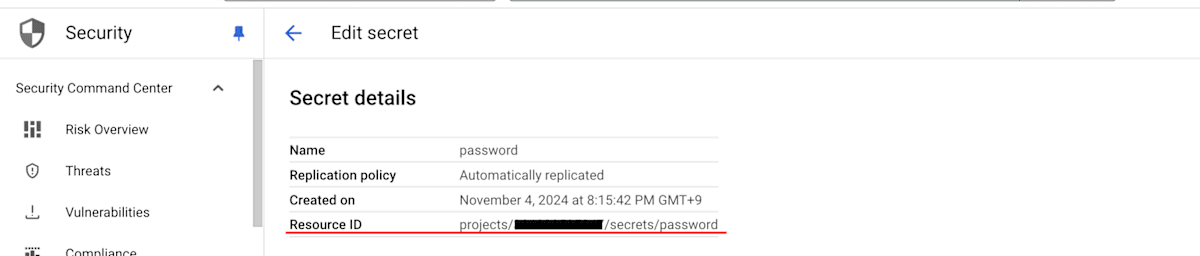
シークレットの Resource ID を確認する
ネットワークを構成する
Dataproc Serverless for Spark network configuration にある要件を満たすようにネットワークを構成してください。今回は default ネットワークを用いるので、us-central1 リージョンの default サブネットにおいて、Private Google Access を On に変更してください。
Cloud Storage バケットの作成
メタデータインポートファイルを保存するための Cloud Storage バケットを作成してください。
今回の検証では us-central1 リージョンにバケットを作成しました。
Dataplex Catalog の準備
Dataplex Catalog にメタデータをインポートする準備として、エントリグループ、エントリタイプ、アスペクトタイプを作成します。
Dataplex Catalogにおける情報資産の管理について
Dataplex Catalog では、エントリという単位で各情報を管理しています。今回登録するオラクルデータベースを例にあげると、データベース インスタンスもデータベースもテーブルもビューも区別なく一旦すべてエントリとして登録していきます。
また、いま作成している、エントリグループやエントリタイプ、アスペクトタイプは、エントリを登録・管理しやすくするための Dataplex Catalog の仕組みの一つです。Dataplex Catalog の仕組みについてもう少し詳しく知りたい方はこちらのドキュメントをご覧いただくと良いかもしれません。
エントリグループの作成
- Google Cloud コンソールで、Dataplex の [Catalog] ページに移動します。
- [Catalog] ページ内の[ENTRY GROUPS] タブからさらに [CUSTOM] タブに入り、[CREATE] ボタンをクリックします。
- Display name に
oracledbと入力すると、Entry group ID が自動入力されoracledbに設定されます。また、Location がus-central1に設定されていることを確認し、[Save] をクリックしてください。
アスペクトタイプの作成
- Google Cloud コンソールで、Dataplex の [Catalog] ページに移動します。
- [ASPECT TYPES] タブから [CUSTOM] タブに入り、[CREATE] ボタンをクリックします。
- Display name に
oracle-instanceと入力すると、Aspect type ID が自動入力されoracle-instanceに設定されます。また、Location がus-central1に設定されていることを確認し、[Save] をクリックしてください。 - 1~3をくり返り、以下の5つのアスペクトタイプを作成してください。
| Display name | Aspect type ID | Location | |
|---|---|---|---|
| 1 | oracle-instance | oracle-instance | us-central1 |
| 2 | oracle-database | oracle-database | us-central1 |
| 3 | oracle-schema | oracle-schema | us-central1 |
| 4 | oracle-table | oracle-table | us-central1 |
| 5 | oracle-view | oracle-view | us-central1 |
事前定義されたアスペクトタイプ
エントリタイプの作成
- Google Cloud コンソールで、Dataplex の [Catalog] ページに移動します。
- [ENTRY TYPES] タブから [CUSTOM] タブに入り、[CREATE] ボタンをクリックします。
- Display name に
oracle-instanceと入力すると、Entry type ID が自動入力されoracle-instanceに設定されます。また、Location がus-central1に設定されていることを確認してください。 - Required aspect types セクションで [CHOOSE ASPECT TYPE] ボタンをクリックします。
- Select aspect types ウィンドウで、oracle-instance アスペクトタイプにチェックを入れ、エントリタイプを作成します。
- 1~5をくり返り、以下の5つのエントリタイプを作成してください。
| Display name | Entry type ID | Location | Required aspect types (複数可) | |
|---|---|---|---|---|
| 1 | oracle-instance | oracle-instance | us-central1 | oracle-instance(Custom) |
| 2 | oracle-database | oracle-database | us-central1 | oracle-database(Custom) |
| 3 | oracle-schema | oracle-schema | us-central1 | oracle-schema(Custom) |
| 4 | oracle-table | oracle-table | us-central1 | oracle-table(Custom) と Schema(System) |
| 5 | oracle-view | oracle-view | us-central1 | oracle-view(Custom) と Schema(System) |
workflow のデプロイ
- Google Cloud コンソールで、[Workflows] ページに移動し、[CREATE] をクリックします。
- workflow の名前には任意の名前を入力し、Region が
us-central1、Service account がCompute Engine default service account、Encryption がGoogle-managed encryption keyに設定されていることを確認してください。 - その他の値はデフォルトのまま、[NEXT] ボタンをクリックします。
- Define workflow に以下のパイプラインコード全文を入力します。その際、コンテナイメージ名とアスペクトタイプ、エントリタイプのプロジェクト名を自身のプロジェクトに合わせて置き換えてください(緑でハイライトした部分が修正必要箇所です)。
パイプラインコード全文
main:
params: [args]
steps:
- init:
assign:
- WORKFLOW_ID: ${"metadataworkflow-" + sys.get_env("GOOGLE_CLOUD_WORKFLOW_EXECUTION_ID")}
- NETWORK_URI: ${default(map.get(args, "NETWORK_URI"), "")}
- SUBNETWORK_URI: ${default(map.get(args, "SUBNETWORK_URI"), "")}
- NETWORK_TAGS: ${default(map.get(args, "NETWORK_TAGS"), [])}
- check_networking:
switch:
- condition: ${NETWORK_URI != "" and SUBNETWORK_URI != ""}
raise: "Error: cannot set both network_uri and subnetwork_uri. Please select one."
- condition: ${NETWORK_URI != ""}
steps:
- submit_extract_job_with_network_uri:
assign:
- NETWORKING: ${NETWORK_URI}
- NETWORK_TYPE: "networkUri"
- condition: ${SUBNETWORK_URI != ""}
steps:
- submit_extract_job_with_subnetwork_uri:
assign:
- NETWORKING: ${SUBNETWORK_URI}
- NETWORK_TYPE: "subnetworkUri"
next: set_default_networking
- set_default_networking:
assign:
- NETWORK_TYPE: "networkUri"
- NETWORKING: ${"projects/" + args.TARGET_PROJECT_ID + "/global/networks/default"}
next: check_create_target_entry_group
- check_create_target_entry_group:
switch:
- condition: ${args.CREATE_TARGET_ENTRY_GROUP == true}
next: create_target_entry_group
- condition: ${args.CREATE_TARGET_ENTRY_GROUP == false}
next: generate_extract_job_link
- create_target_entry_group:
call: http.post
args:
url: ${"https://dataplex.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/entryGroups?entry_group_id=" + args.TARGET_ENTRY_GROUP_ID}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
next: generate_extract_job_link
- generate_extract_job_link:
call: sys.log
args:
data: ${"https://console.cloud.google.com/dataproc/batches/" + args.CLOUD_REGION + "/" + WORKFLOW_ID + "/monitoring?project=" + args.TARGET_PROJECT_ID}
severity: "INFO"
next: submit_pyspark_extract_job
- submit_pyspark_extract_job:
call: http.post
args:
url: ${"https://dataproc.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/batches"}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
headers:
Content-Type: "application/json"
query:
batchId: ${WORKFLOW_ID}
body:
pysparkBatch:
mainPythonFileUri: file:///main.py
jarFileUris:
- "file:///opt/spark/jars/ojdbc11.jar"
args:
- ${"--host_port=" + args.ORACLE_HOST_PORT}
- ${"--user=" + args.ORACLE_USER}
- ${"--password-secret=" + args.ORACLE_PASSWORD}
- ${"--database=" + args.ORACLE_DATABASE}
- ${"--target_project_id=" + args.TARGET_PROJECT_ID}
- ${"--target_location_id=" + args.CLOUD_REGION}
- ${"--target_entry_group_id=" + args.TARGET_ENTRY_GROUP_ID}
- ${"--output_bucket=" + args.CLOUD_STORAGE_BUCKET_ID}
- ${"--output_folder=" + WORKFLOW_ID}
runtimeConfig:
+ containerImage: "us-central1-docker.pkg.dev/<YOUR_PROJECT_ID>/docker-repo/oracle-pyspark"
environmentConfig:
executionConfig:
serviceAccount: ${args.SERVICE_ACCOUNT}
result: RESPONSE_MESSAGE
next: check_pyspark_extract_job
- check_pyspark_extract_job:
call: http.get
args:
url: ${"https://dataproc.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/batches/" + WORKFLOW_ID}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
result: PYSPARK_EXTRACT_JOB_STATUS
next: check_pyspark_extract_job_done
- check_pyspark_extract_job_done:
switch:
- condition: ${PYSPARK_EXTRACT_JOB_STATUS.body.state == "SUCCEEDED"}
next: generate_import_logs_link
- condition: ${PYSPARK_EXTRACT_JOB_STATUS.body.state == "CANCELLED"}
raise: ${PYSPARK_EXTRACT_JOB_STATUS}
- condition: ${PYSPARK_EXTRACT_JOB_STATUS.body.state == "FAILED"}
raise: ${PYSPARK_EXTRACT_JOB_STATUS}
next: pyspark_extract_job_wait
- pyspark_extract_job_wait:
call: sys.sleep
args:
seconds: 30
next: check_pyspark_extract_job
- generate_import_logs_link:
call: sys.log
args:
data: ${"https://console.cloud.google.com/logs/query?project=" + args.TARGET_PROJECT_ID + "&query=resource.type%3D%22dataplex.googleapis.com%2FMetadataJob%22+AND+resource.labels.location%3D%22" + args.CLOUD_REGION + "%22+AND+resource.labels.metadata_job_id%3D%22" + WORKFLOW_ID + "%22"}
severity: "INFO"
next: submit_import_job
- submit_import_job:
call: http.post
args:
url: ${"https://dataplex.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/metadataJobs?metadata_job_id=" + WORKFLOW_ID}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
body:
type: IMPORT
import_spec:
source_storage_uri: ${"gs://" + args.CLOUD_STORAGE_BUCKET_ID + "/" + WORKFLOW_ID + "/"}
entry_sync_mode: FULL
aspect_sync_mode: INCREMENTAL
scope:
entry_groups:
- ${"projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/entryGroups/"+args.TARGET_ENTRY_GROUP_ID}
entry_types:
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/entryTypes/oracle-instance"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/entryTypes/oracle-database"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/entryTypes/oracle-schema"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/entryTypes/oracle-table"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/entryTypes/oracle-view"
aspect_types:
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/aspectTypes/oracle-instance"
- "projects/dataplex-types/locations/global/aspectTypes/schema"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/aspectTypes/oracle-database"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/aspectTypes/oracle-schema"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/aspectTypes/oracle-table"
+ - "projects/<YOUR_PROJECT_ID>/locations/us-central1/aspectTypes/oracle-view"
result: IMPORT_JOB_RESPONSE
next: get_job_start_time
- get_job_start_time:
assign:
- importJobStartTime: ${sys.now()}
next: import_job_startup_wait
- import_job_startup_wait:
call: sys.sleep
args:
seconds: 30
next: initial_get_import_job
- initial_get_import_job:
call: http.get
args:
url: ${"https://dataplex.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/metadataJobs/" + WORKFLOW_ID}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
result: IMPORT_JOB_STATUS
next: check_import_job_status_available
- check_import_job_status_available:
switch:
- condition: ${sys.now() - importJobStartTime > 300} # 5 minutes = 300 seconds
next: kill_import_job
- condition: ${"status" in IMPORT_JOB_STATUS.body}
next: check_import_job_done
next: import_job_status_wait
- import_job_status_wait:
call: sys.sleep
args:
seconds: 30
next: check_import_job_status_available
- check_import_job_done:
switch:
- condition: ${IMPORT_JOB_STATUS.body.status.state == "SUCCEEDED"}
next: the_end
- condition: ${IMPORT_JOB_STATUS.body.status.state == "CANCELLED"}
raise: ${IMPORT_JOB_STATUS}
- condition: ${IMPORT_JOB_STATUS.body.status.state == "SUCCEEDED_WITH_ERRORS"}
raise: ${IMPORT_JOB_STATUS}
- condition: ${IMPORT_JOB_STATUS.body.status.state == "FAILED"}
raise: ${IMPORT_JOB_STATUS}
- condition: ${sys.now() - importJobStartTime > 43200} # 12 hours = 43200 seconds
next: kill_import_job
next: import_job_wait
- get_import_job:
call: http.get
args:
url: ${"https://dataplex.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/metadataJobs/" + WORKFLOW_ID}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
result: IMPORT_JOB_STATUS
next: check_import_job_done
- import_job_wait:
call: sys.sleep
args:
seconds: 30
next: get_import_job
- kill_import_job:
call: http.post
args:
url: ${"https://dataplex.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/metadataJobs/" + WORKFLOW_ID + ":cancel"}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
next: get_killed_import_job
- get_killed_import_job:
call: http.get
args:
url: ${"https://dataplex.googleapis.com/v1/projects/" + args.TARGET_PROJECT_ID + "/locations/" + args.CLOUD_REGION + "/metadataJobs/" + WORKFLOW_ID}
auth:
type: OAuth2
scopes: "https://www.googleapis.com/auth/cloud-platform"
result: KILLED_IMPORT_JOB_STATUS
next: killed
- killed:
raise: ${KILLED_IMPORT_JOB_STATUS}
- the_end:
return: ${IMPORT_JOB_STATUS}
- [DEPLOY] ボタンをクリックし、workflow を作成します。
workflow を実行する
作成した workflow を実行します。
- 作成した workflow をクリックし、[EXECUTE]ボタンをクリックします。
- Input 欄に、実行に必要な引数を入力し、[EXECUTE]ボタンから workflow を実行します。

workflow の実行
以下の実行引数の内、プロジェクト ID とバケット名、プロジェクトナンバー、オラクルデータベースのホスト名を自身のプロジェクトに合わせて置き換えてください(これまでの手順と異なる設定をしている場合は、下記の表を元に適宜置き換えてください。)
{
"TARGET_PROJECT_ID": "<YOUR_PROJECT_ID>",
"CLOUD_REGION": "us-central1",
"TARGET_ENTRY_GROUP_ID": "oracledb",
"CREATE_TARGET_ENTRY_GROUP": false,
"CLOUD_STORAGE_BUCKET_ID": "<YOUR_STORAGE_BUCKET_NAME>",
"SERVICE_ACCOUNT": "<YOUR_PROJECT_NUMBER>-compute@developer.gserviceaccount.com",
"ORACLE_USER": "system",
"ORACLE_PASSWORD": "projects/<YOUR_PROJECT_NUMBER>/secrets/password",
"ORACLE_HOST_PORT": "<YOUR_ORACLE_HOST_NAME>:1521",
"ORACLE_DATABASE": "xe",
"ADDITIONAL_CONNECTOR_ARGS":[],
"IMPORT_JOB_LOG_LEVEL": "INFO",
"NETWORK_TAGS": [],
"NETWORK_URI": "",
"SUBNETWORK_URI": ""
}
実行引数一覧(workflow のパイプラインを書き換えることでカスタムが可能です)
| 引数名 | 入力 | 備考 |
|---|---|---|
| "TARGET_PROJECT_ID" | "<YOUR_PROJECT_ID>" | メタデータをインポートするプロジェクトを入力。 |
| "CLOUD_REGION" | "<YOUR_LOCATION_ID>" | メタデータジョブを行うロケーションを入力。 |
| "TARGET_ENTRY_GROUP_ID" | "<YOUR_ENTRY_GROUP_ID>" | エントリグループIDを入力。小文字、数字、ハイフンのみ使用可能。 |
| "CREATE_TARGET_ENTRY_GROUP" | <CREATE_ENTRY_GROUP_BOOLEAN> | entry group を未作成の場合、true に設定することで、entry group を作成するステップがパイプラインに追加される。 |
| "CLOUD_STORAGE_BUCKET_ID" | "<YOUR_STORAGE_BUCKET_NAME>" | メタデータインポートファイルを保存する Cloud Storage バケット名を入力。 |
| "SERVICE_ACCOUNT" | "<YOUR_SERVICE_ACCOUNT_ID>" | workflow を実行するサービスアカウントを入力。 |
| "ORACLE_USER" | "<YOUR_ORACLE_USER_NAME>" | オラクルデータベースのユーザー名を入力。 |
| "ORACLE_PASSWORD" | "projects/<YOUR_PROJECT_NUMBER>/secrets/<YOUR_SECRETS_NAME>" | Secret の Resource ID を入力。 |
| "ORACLE_HOST_PORT" | "<YOUR_ORACLE_HOST_NAME>:<YOUR_ORACLE_PORT_NUMBER>" | Oracle Net リスナーで確認したホスト名とポート番号を入力。 |
| "ORACLE_DATABASE" | "<YOUR_ORACLE_DATABASE>" | オラクルデータベースで接続するサービス名を入力。 今回はデフォルトサービス名である、XE および XEPDB1 のうち XE を使用。 |
| "ADDITIONAL_CONNECTOR_ARGS" | [ ] | 今回は追加引数等はありませんが、コネクター改良し追加引数が必要な場合は入力可能です。その際はカンマ区切りで、各引数は""で囲むことが必要です。例:"--target_location_id=us-central1","--target_entry_group_id=oracle" |
| "IMPORT_JOB_LOG_LEVEL" | "INFO" | オプションで、メタデータインポートジョブのログレベルを設定可能。"INFO"または"DEBUG"を選択可能。デフォルトは"INFO"。 |
| "NETWORK_TAGS" | [ ] | オプションで、ネットワークタグを入力可能。 |
| "NETWORK_URI" | "" | オプションで、ネットワークURLを入力可能。 |
| "SUBNETWORK_URI" | "" | オプションで、サブネットURLを入力可能。 |
Dataplex Catalog にメタデータがインポートされたことを確認する
workflow の実行が正常に完了したら、Dataplex Catalog にメタデータがインポートされているか確認します。今回のテンプレートコネクターでは、例えばテーブルなら親エントリの情報や、テーブル名、カラム名、カラムのデータ型やメタデータの型、モード(NULLABLE/REPEATED/REQUIRED)などの情報がインポートできているはずです。
- Google Cloud コンソールで、Dataplex の [Search] ページに移動します。
- Filters パネルの、Aspects 項目で oracle-database にチェックを入れます。
- ヒットしたエントリ(<YOUR_ORACLE_HOST_NAME>@1521/databases/xe)をクリックします。[ENTRY LIST] タブを参照すると、オラクルのデフォルトデータベース xe を親エントリに持つ全ての子エントリが登録されていることを確認できます。(今回はデータベース xe の子エントリとして、ユーザーネーム一覧が登録されていることを確認できます。)
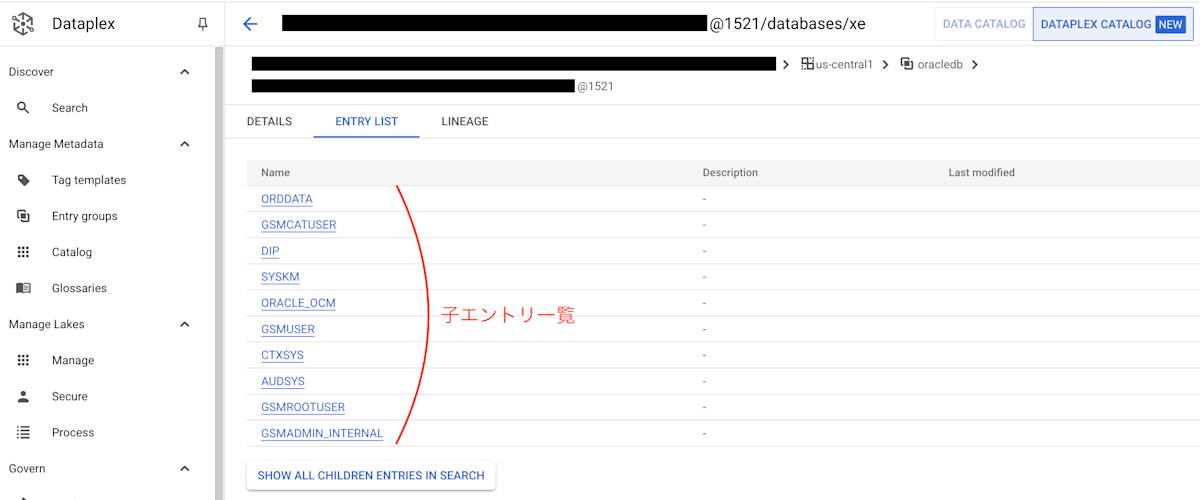
エントリの親子関係 - 同様に、Filters パネルの、Aspects 項目で oracle-table にチェックを入れます。
- ヒットしたエントリから任意のエントリ(テーブル)をクリックします。[SCHEMA] タブを参照すると、テーブルのカラム名や、データ型、メタデータの型、モードが登録されていることを確認できます。
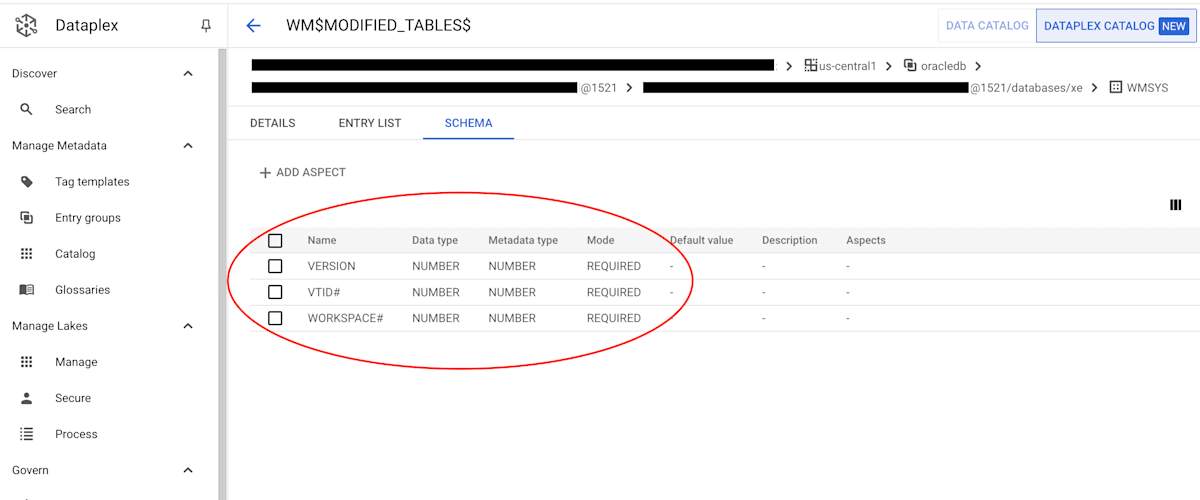
テーブルのメタデータ
おわりに
この記事では、最近一般提供が開始された Managed connectivity pipelines について紹介しました。
公式ドキュメントが予想以上に複雑で、また使用経験のなかったオラクルデータベースやプロダクト等も扱ったため、検証に四苦八苦しましたが、偉大な先輩方の記事や技術ブログ、相談に乗ってくれた方々のおかげでなんとか記事にまとめることができました。心から感謝申し上げます。
動かしてみると分かるように、サードパーティデータベースに合わせたコネクターを作る部分には手間が必要ですが、Dataplex を利用するほどの大規模なデータレイクやデータマート、データウェアハウスを処理するパイプラインを構築する際には、非常に有益だと考えられます。
Dataplex でサードパーティデータベースから大規模にメタデータを収集・管理する際にはぜひ Managed connectivity pipelines をお試しください。ここまで、ご一読いただきありがとうございました。
Discussion