始めまして、ちゅらデータの淡島です。
冬に沖縄に行きたいという理由でちゅらデータにジョインさせてもらいました
今はデータサイエンティストという肩書きでお仕事させてもらっています。
背景
ちゅらデータといえばSnowflakeみたいな風潮がありますが、自分は経歴的にもGCPにどっぷり浸かってきており、BigQueryもいいんだぞ!という感じで細々とやらせてもらっています。
弊社ではOSS活動等も推進しており、ひょんなことから自分もdbtとか周りのOSSに関する活動をすることになり、何か面白いテーマで記事を書けないかなぁと思っていたところ
こんな感じの記事を見つけてしまいました。
最近は弊社でも右を向いても、左を向いても生成AI周りの話がでてきており、自分もベクトル検索だのRAGだの色々頑張っておりふと
もしかしてdbtだけで非構造化データのRAGって作れちゃうのでは。。。そしてこれ結構BigQuery独自なんじゃね???
と思った次第です、最近dbtはデータエンジニア御用達みたいになってきており、そのパイプラインからRAGを構築できるようになるということは、生成AI周りのふわふわした領域に対してエンジニアが介入できる余地が増えるようになれるんじゃなかろうかと思うと同時に、BigQueryならではのよさを伝えられるんじゃないかなぁと思います。
というわけで以下、BigQueryでRAGを構築してみようシリーズを頑張って書いていきます
多分5-6回くらいに分けて投稿する予定です
今回のスコープ
以下の図が今回の対象となります
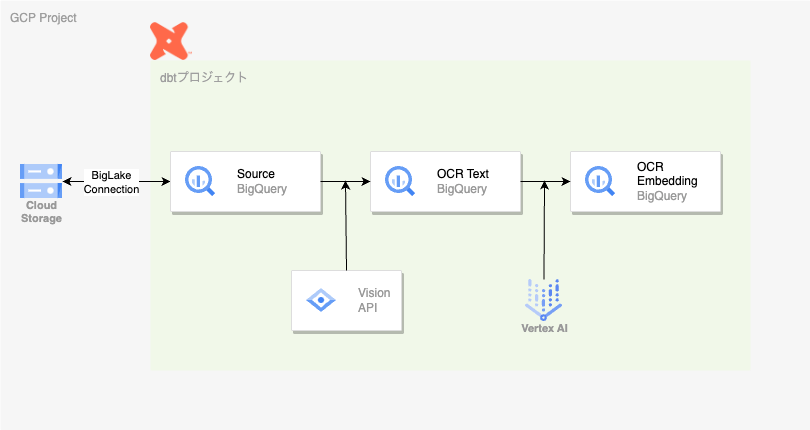
具体的には
- GCSに入れた画像データをオブジェクトテーブルとしてBigQueryに連携する
- Cloud Vision APIを使って画像データからテキスト抽出(OCR)する
- Vertex AIの生成AIを使ってテキストをベクトル化する
- BigQueryのベクトルインデックスを用いて、ベクトルDBとして保存する
という手順を踏みます各手順については以下詳細を記述していきます
注意
ここらへん2024/2/11時点でほとんどがプレビュー機能を利用しており、今後使えなくなったりする可能性があります。
また、BigQueryからCloud Vison APIおよびDocument AIを利用する機能に関する制限によって、この手法はRAGのメジャーな適用フォーマットであるPDFファイルには使えません。
(ここについてはIssueとして報告しています)
PDFに対してもやりたい場合おそらくリモート関数を使ってPDFをOCRするようにすれば同様の結果を得られるだろうとは思います。
手順
0.事前準備
dbtのモデルを書いていく前に今回はBigQueryの外側の準備が結構いっぱいあります、頑張りましょう
GCSのバケットの作成
とりあえず、適当にGCSのバケットを作成しましょう
このブログでは仮にrag-sampleとします。
BigQuery Connectionの作成
BigQueryからGCS/Cloud Vision API/Vertex AIなどにアクセスするようのコネクションを作成します。
の手順を参考に作りましょう、ここではproject.us.rag_sample_connection
というコネクションが作成されたことにします。
この時、このコネクションを利用するサービスアカウントが作成後わかるはずなのでそれをメモします。
コネクション用のサービスアカウントへのIAM付与
最終的には以下のような権限を付与すればよいです

詳しいことは
などに記載してあります
GCSへの画像のアップロード及びオブジェクトテーブルの作成
GCSに画像を投入します、なお今回はPDFのようなものを想定して

このようなファイル名でアップロードしています
次に、これらのファイルのメタ情報をBigQueryから参照できるようにするオブジェクトテーブルrag_sample.source_objectを作成します
CREATE OR REPLACE EXTERNAL TABLE `rag_sample.source_object`
WITH CONNECTION `project.us.rag_sample_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://rag-sample/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
この設定だとメタデータのキャッシュをBigQuery側に作って1時間毎に更新するようになっているので、ここらへんは柔軟に調整してください(その1時間内に新しい画像をアップロードしてもデータ反映がされない)
Cloud Vison APIのリモートモデル作成
BigQueryからCloud Vision APIにアクセスするためのリモートモデルrag_sample.image_parserを作成します
CREATE OR REPLACE MODEL `rag_sample.image_parser`
REMOTE WITH CONNECTION `project.us.rag_sample_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_VISION_V1'
);
Vertex AIのリモートモデル作成
BigQueryからVertex AIにアクセスするためのリモートモデルrag_sample.vector_makerを作成します
CREATE OR REPLACE MODEL `rag_sample.vector_maker`
REMOTE WITH CONNECTION `project.us.rag_sample_connection`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_TEXT_EMBEDDING_MODEL_V1', ENDPOINT='textembedding-gecko-multilingual');
以上で準備は完了です、長いですね。
1. dbtの準備
とりあえず、dbt[bigquery]のインストールとdbt initは完了した状態を想定します。
まずはproject.ymlに変数定義をします
vars:
cloud_vision_model: '`project.rag_sample.pdf_parser`'
vector_model: '`project.rag_sample.vector_maker`'
次にオブジェクトテーブルをsourceに定義します
version: 2
sources:
- name: source
schema: rag_sample
tables:
- name: source_object
2. OCRの実行
さて、ここまで準備したので、いよいよモデルを書いていきます。
上述の通り、OCRの実行には、Cloud Vision APIを活用するので、毎回洗い替えすると課金額が青天井になってしまうので、incrementを利用して差分のみ適用するようにしています。
{{
config(
materialized='incremental',
unique_key=['uri', 'page_num', 'paper_num']
)
}}
SELECT
uri,
REGEXP_EXTRACT(uri, r"paper_(\d+)_page_\d+.png") as paper_num,
REGEXP_EXTRACT(uri, r"paper_\d+_page_(\d+).png") as page_num,
JSON_VALUE(ml_annotate_image_result.full_text_annotation.text) as text,
updated as updated_at
FROM
ML.ANNOTATE_IMAGE(
MODEL {{ var("cloud_vision_model") }},
TABLE {{ source('source', 'source_object') }},
STRUCT( ['DOCUMENT_TEXT_DETECTION'] AS vision_features )
)
{% if is_incremental() %}
where updated > (select max(updated_at) from {{ this }})
{% endif %}
3. 中間処理
今回はファイル名にpaper_numとpage_numを想定しているのでこれらを1docとして扱うための処理を差し込みます
SELECT
uri,
paper_num,
STRING_AGG(text, "") as agg_text,
MAX(updated_at) as updated_at
FROM
{{ ref('ocr_text') }}
GROUP BY 1, 2
4. chunk処理
RAGで利用する生成AIには扱える文字数上限があります、そこで、長い文章はchunkに区切り処理するのが定石になっています
SELECT
uri,
paper_num,
chunk_num,
SUBSTR(agg_text, 1000 * (chunk_num - 1), 1000) as chunk_text,
updated_at
FROM
{{ ref('ocr_text_agg') }},
UNNEST(GENERATE_ARRAY(1, DIV(CHAR_LENGTH(agg_text), 1000 + 1))) as chunk_num
5. ベクトルの生成と格納およびインデックス化
chunkに対して検索可能にするための処理をします。
dbtのpost_hookを活用し、テーブルを作成した後にvector_indexの作成をしています。
またここでも生成AIを活用しているので、incrementモデルで課金額を抑えています。
BigQueryのベクトルインデックスは に詳細な情報があります。
現時点では5000行ないとベクトルインデックスを作成できなかったので、そのための処理をいれています。
{{
config(
materialized='incremental',
unique_key=['uri', 'paper_num', 'chunk_num'],
post_hook=[
"
IF (SELECT COUNT(*) > 5000 FROM {{ this }})
THEN CREATE VECTOR INDEX IF NOT EXISTS rag_sample_index ON {{ this }}(text_embedding) OPTIONS(index_type = 'IVF', distance_type='COSINE');
END IF;
"
]
)
}}
WITH chunk_as_content as (
SELECT
uri,
paper_num,
chunk_num,
chunk_text as content,
updated_at
FROM
{{ ref('ocr_text_chunk') }}
)
SELECT
uri,
paper_num,
chunk_num,
content as chunk_text,
text_embedding,
updated_at
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL {{ var("vector_model") }},
(SELECT * FROM chunk_as_content),
STRUCT(TRUE AS flatten_json_output)
)
{% if is_incremental() %}
where updated_at > (select max(updated_at) from {{ this }})
{% endif %}
ちなみに通常の文字列検索を利用したい場合は、 こちらの利用を検討しましょう。
以上です、後はdbt runでmodelを動かしてみましょう
つづきが気になる人は
dbtとBigQueryでRAGを構築してみよう(その2ー回答生成編)も読んでください

Discussion