こんにちは、前回に引き続き、RAGを構築していく記事になります。
前回はベクトル検索が実行できるテーブルを構築しましたが、それだけではRAGはできません。
Retrieval AND Generationのうち、Generationを実行する部分になります。
結論
まずは結論として以下のクエリを実行することでRAGを実行できるようになります
SELECT res.query, res.uris, res.generate_res FROM (SELECT `project.rag_sample.make_rag_answer`("問い合わせ文") as res)
今回のスコープ
以下の図が今回の対象となります
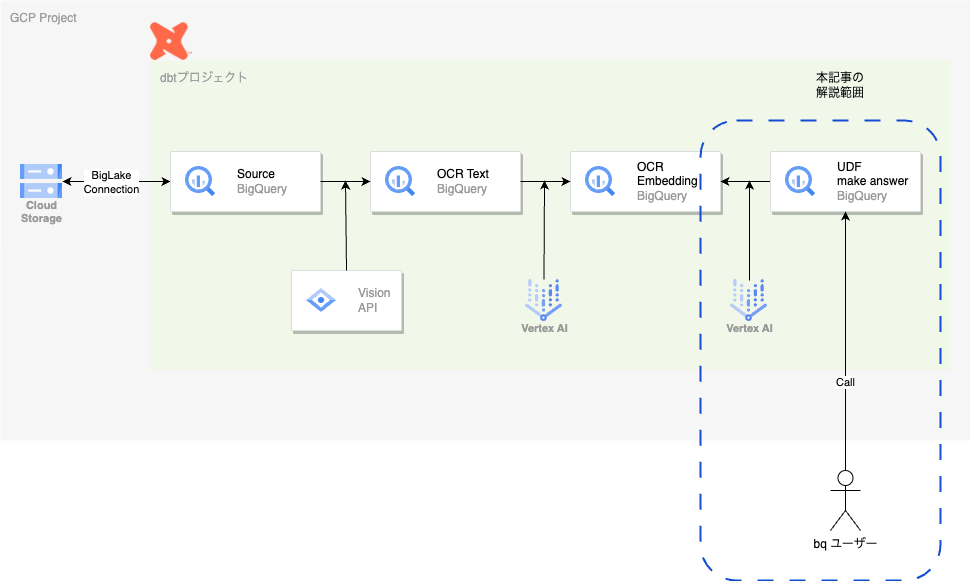
具体的には
- 問い合わせ文をembeddingに変換します
- embeddingを
ocr_text_chunk_vectorに対してベクトル検索を実施する - 検索結果として取得できたchunkを参考文書として
text-bison-32k(Palm2)のモデルに回答を生成させる
というような手順を含んだUDFを実装します。
手順
0.事前準備
今回もdbtでの開発の前にやらないといけないことがあります
前回の環境が構築されていることが前提です。
Vertex AIのリモートモデル作成(for palm2)
CREATE OR REPLACE MODEL `rag_sample.text_generator`
REMOTE WITH CONNECTION `project.us.rag_sample_connection`
OPTIONS (REMOTE_SERVICE_TYPE = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1', ENDPOINT='text-bison-32k');
前回のリモートモデルはベクトルを作る用途でしたが今度のリモートモデルは回答生成を実行するためのものになります。
以上で準備は完了です。
1. プロンプトのテンプレート作り
まずは、今回のRAGで回答生成をするためのプロンプトを作りましょう
{%- macro prompt_template() %}
"""
以下は質問への回答を作るために参考とすべき文です。
{summaries}
以下に示す質問に、質問の回答として適切な文体で回答してください。
上記の参考文をそのまま回答するのではなく、整理して回答してください。
回答がない場合は、「回答不明」と出力してください。
以下に質問を示します。
{question}
"""
{%- endmacro %}
{summaries}と{question}は後ほど置換する用途なので同じような間違えて複数置換されないようなものにしておくとよいでしょう。
2. UDF作成
上記のプロンプトを活用し、以下のUDFを作成します
{% macro udf_rag_question() %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.make_rag_answer(question string)
RETURNS STRUCT<query string, uris ARRAY<STRING>, generate_res STRING>
AS ((
SELECT
STRUCT(
query,
uris,
JSON_VALUE(ml_generate_text_result.predictions[0].content) as generate_res
)
FROM
ML.GENERATE_TEXT(
MODEL {{ var("generate_model") }},
(
SELECT
query,
uris,
prompt
FROM (
SELECT
query,
uris,
REPLACE(REPLACE({{ prompt_template() }}, "{summaries}", input_text), "{question}", query) as prompt
FROM (
SELECT
ANY_VALUE(query) as query,
STRING_AGG(chunk_text, "\n") as input_text,
ARRAY_AGG(DISTINCT uri) as uris
FROM (
SELECT
query.query,
base.uri,
base.chunk_text
FROM
VECTOR_SEARCH(
TABLE {{ target.schema }}.ocr_text_chunk_vector,
'text_embedding',
(
SELECT
content as query,
text_embedding
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL {{ var("vector_model") }},
(SELECT question as content),
STRUCT(TRUE AS flatten_json_output)
)
),
'text_embedding',
top_k => {{ var("search_num")}}
)
)
)
)
),
STRUCT(
0.8 AS temperature,
1024 AS max_output_tokens,
0.95 AS top_p,
40 AS top_k
)
)
));
{% endmacro %}
withで整理するとわかりやすいのですがUDFではwithが使えないので、サブクエリをネストしています。
若干やっていることが不明瞭かなと思うので日本語でやってることを説明すると
- 問い合わせ文をembeddingに変換します
- embeddingを
ocr_text_chunk_vectorに対してベクトル検索を実施する - 検索結果として取得できたchunkを参考文書として
text-bison-32k(Palm2)のモデルに回答を生成させる
というようなことをやっているUDFとなります。
3. UDF登録
以下の記述をdbt_project.ymlファイルに追記します。
on-run-end:
- '{{udf_rag_question()}}'
これによってdbtの処理が完了次第、UDFの作成および更新のクエリが走るようになります。
今後のブランチ戦略等を考慮するとUDFの定義をrepoに含めておき、適宜replaceをしていければいいのかなと思っています。
これで、UDFを打つことで
- query - 問い合わせ文
- uris - 検索に引っかかったファイルパス
- generate_res - 回答文
の結果がレスポンスとして返却されるようになります。
これで完成したと思ったあなたは
dbtとBigQueryでRAGを構築してみよう(その3ーインフラ構築IaC編)
を読みましょう

Discussion