The 8th APAC HPC-AI Competition参加記
これは木更津高専Advent Calendar1日目の記事です。
イントロダクション
この記事では8th APAC HPC-AI Competitionに参加の様子をまとめる。
そもそも、私はAIに関してバックグラウンドがあるがHPCに関する経験は全くなく、クラスタを使ってAIモデルの学習や推論をした経験もなかった。
HPC無経験からHPCの大会に参加して提出するまでに挑戦したことを書いていく。
実験ジョブスクリプトとスライドはGitHubリポジトリに置いてある。
この大会とは何なのか
HPC-AI Advisory CouncilとNSCC SingaporeとNCI Australiaが共同で開催するハイパフォーマンスコンピューティング(HPC)とAIの国際コンペティション。
このコンペティションでは2部門あり、純粋な科学計算の最適化と、AIベンチマークの最適化がタスクとして課される。今年の課題は次のとおりである。
- HPC部門
- NWChemというアプリケーションを使った化学計算ベンチマークの最適化
- 4 CPU nodesまで使用可能
- AI部門
- SGLangを使ったDeepSeek R1の推論ベンチマークの最適化
- モデルの性能を下げる変更(e.g. Quantization)や実験的機能(torch.compile)は禁止
- 2 GPU nodes (合計16 H100 GPUs)
何をするかというと
- ベースラインを定義する
- ベースラインに対して最適化アイデアを加える
- 繰り返す
- プレゼンをする
この大会に参加するとNSCCのAspire2a+とNCIのGadiというスーパーコンピュータを使用することができる。結果については、ベンチマークの結果とプレゼンテーションの内容を総合的に評価し、合計11チームが入賞する。
過去大会を見ていると、中国の清華大学と南方科技大学、シンガポールの南洋理工大学、台湾の国立清華大学あたりが毎年入賞していて、自分の知る限りで日本チームの入賞の例は知らない。
高専プロコンでの大会との出会い
日本チームの参加が極めて少ないためこの記事を読んでいる日本人でこの大会を存在を知っていた人は少ないと思う。
私のHPC-AI Competitionとの出会いは高専プロコンだった。理研R-CCSが高専プロコンにスポンサーとして出展をしており、ブースに立ち寄ったときにHPC-AI Competitionの存在を教えてもらった。理研R-CCSは昨年度から高専生や大学生を対象にHPC-AI Competitionの参加を支援しているらしい。ちなみに、今年度もやているのでぜひ参加してみてほしい。
スパコンを使えるなんてありがたいねぇという気持ちで参加することにした。
学校の友だちを集めた5人のチーム「Kisarazu Big Branch w/ RIKEN」というチーム名で理研R-CCSの支援のもと出場することになった。
大会が始まる前に、理研R-CCSからはいくつか勉強する機会を用意してくれた。
- キックオフミーティング at 理研R-CCS
- 富岳の見学をした
- SCA2025 at シンガポール
- 学会に行くことができた
- 私は学年の都合上行けなかったが、チームメイトが行った
- 前年のHPC-AI Competitionの表彰と、次の年の大会のタスク発表があった
- 九州大学の玄界の利用
- H100のノードがあるという点で本番に近い環境で練習できた
チームメイトが行ったSCA2025の中では、前年度の優秀チームの優勝した台湾の国立清華大学(NTHU)チームのプレゼンテーションも行われ、チームメイトがNTHUのプレゼン資料をゲットしてくれた。
我々のチームはチームの中で勉強会を開いてDeepSeekやSGLangについて勉強を重ねた。玄界にアクセスできたのは非常に良くてジョブスケジューラにジョブを投げて動かすという経験を大会前に積むことができた。最初から玄界の上でDeepSeek R1 671Bを動かすことはできなかったので、ステップを踏んでDeepSeek R1を動かすことに成功した。
- シングルノードで動く13Bモデルの推論
- 13Bモデルをマルチノードで動かす
- DeepSeek R1をマルチノードで動かす
この過程の中でベンチマーク実行時にDeepSeekの重み(合計で1TB程度)をGPUに乗せるためだけに30分程度時間を食っていることが判明した。これは、玄界ではスファイルをクラッチ領域(マシンから高速にアクセスできるディスク)に乗る条件が厳しく、結局良い解決策は見つからなかった。ただ、大会で使用したAspire2a+はログインノードからスクラッチ領域にアクセスできてファイルを置くことができたのでロード時間は爆速(1分もかからない)で問題にならなかった。
このベースラインを動かすということに数週間かを費やした上に、IO関係の問題も知る事ができたので事前に玄界を使って練習できたのは非常に良かったと思う。
大会が始まったが、最適化を始めるまでに費やした数週間
この大会は8月から10月前半まで自由にクラスターにアクセスして実験をすることができる。
しかし、8月いっぱいは環境に慣れるの精一杯だった。そもそも、Aspire2a+にアクセスするには通常VPNが必要で、そもアカウントはチームで1つなので誰かがアクセスするために自分の携帯の2FAアプリで承認ボタンを押さないといけない煩わしさがあった。
どうやら、NSCCのスーパーコンピュータはシンガポール国内の大学や研究所のネットワークからならVPNなしで入れるそうで、試したらSSHが難なく通り最高だった。前年度のトップチームはNSCCのサーバーとVPNを通じて通信するジャンプサーバーを立てて回避していたらしい。
また、Aspire2a+のジョブスケジューラはPBSという富士通製の玄界とは異なるものだったため、同じジョブスクリプトで動くわけもなく、ベースラインを動かすまでに数週間かかってしまった。
そもそもSGLang自体は推論の高速化に特化しているので元々が速い。何を最適化したらいいのか全くわからない状況だった。そこで我々は、公式ドキュメントとブログを網羅的に読んで何を最適化すべきかについて知ることから始めた。
- SGLang公式ドキュメント: https://docs.sglang.ai/index.html
- SGLangのブログ: https://lmsys.org/blog/
以上のサーベイを通してどのようにして最適化するかのイメージがついてきた。
- Parallelismのconfig変更
- バッチサイズを上げる
- ネットワーク関連の最適化
- Attentionの変更
- DeepSeekのモデル特有の高速化(MoEやMTP)
- その他パラメータチューニング
我々はNTHUの発表資料で触れられていた階層に分けた最適化の戦略を参考にした。様々な最適化手法があるが、影響度が大きいものから徐々に影響度が小さいものを実験していく。最初にParallelismやバッチサイズといったラフなものを、後半にかけてネットワークのチューニング、パラメタチューニングをしていくことにした。
写真は発表スライドから拝借

大体やることが決まってきたので、チームのnotionに実験を記録するデータベースを作って実験管理していくことにした。最初はとりあえず試して、データベースに記録するというやり方だったが、記録するのを忘れてしまうことが多々あった。途中から、やりたい実験を先にデータベースに書いておいて、データベースを参考に実験をして記録するというやり方にしてやりやすくなったと思う。
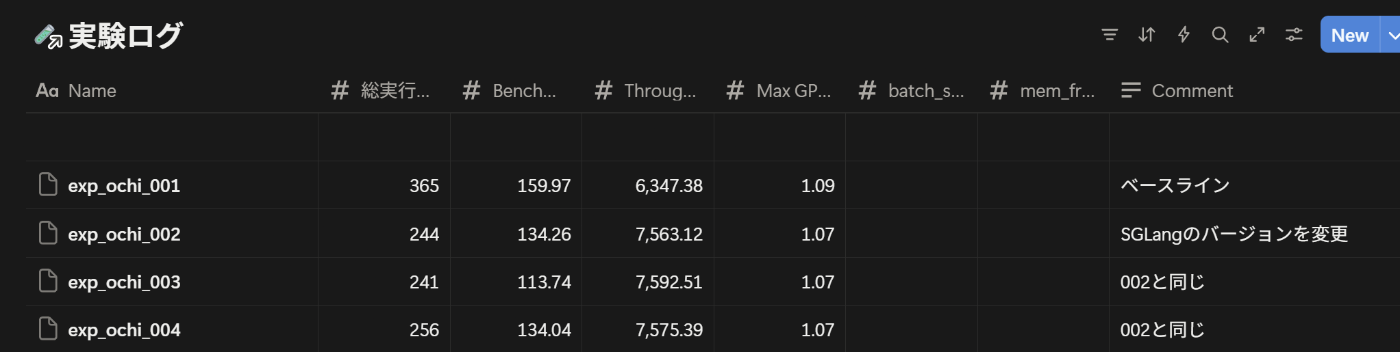
300回実験を回して気付いたこと
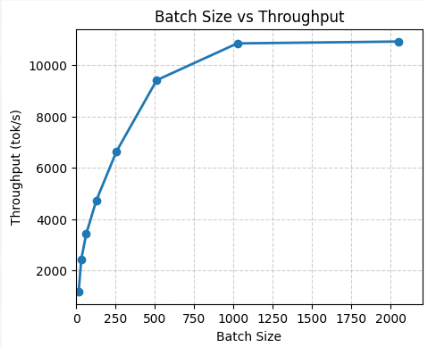
この記事では全ての最適化手法について網羅しないが、バッチサイズについては触れたいと思う。なぜかというと、バッチサイズを上げれば速くなることは多くの人が知っていると思うが、SGLangには明示的にバッチサイズをパラメタで指定できない。
様々なブログを読んだ結果、--max-running-requestsと--cuda-graph-max-bsをバッチサイズと同じ値に設定することで、
ドキュメントには次のように書かれている
-
--max-running-requests: 1回の最大リクエスト -
--cuda-graph-max-bs: CUDA Graphの最大バッチサイズ
後で実験ログを見返したら300程度の実験ログが見つかった。たくさん実験したが、同時にたくさんの困難にも遭遇した。上手くいくとされている最適化手法が全然上手くいかないことである。
例えば、DP Attentionである。DP AttentionはSGLangがDeepSeekモデルのために開発した最適化手法で、MLAの計算でTPの代わりにDPを使うことでGPUごとに持つべきKV cacheの量を減らすことができて推論が1.9倍速くなったと報告されている。
我々の実験では、確かにDP Attentionを有効化することでKV cacheの量が減っていることを確認したがスループットが劇的に下がってしまった。文献や実装を調べたりしたが、なぜかを突き止めることはできなかった。

結果
Excellent AI Performance賞を受賞した。
他チームの様子を見ているとスコア的には2~3番目だそう。また、プレゼンテーションではアイデアのバラエティや実験のクオリティを評価してもらった。
1月28日にSupercomputingAsia 2026 (SCA2026)にて表彰式があるため、自分はシンガポールから大阪に行ってチームメイトと出席する予定である。
コラム:強豪校
HPC-AI Competitionは毎年開催されているが、昨年までは日本からの出場は皆無に等しかった。
- NTHU (National Tsing Hua University, Taiwan): 伝統があり、他のクラスターコンペティションでも毎年表彰台に出ている。先輩から後輩の引き継ぎが上手らしい。
- Monash University(Australia): この大会にはよく出ていて、表彰もよくされている。
- NTU (Nanyang Technological University): 毎年出場しており、今年は2チーム送っている。毎年表彰されていて、他のクラスターコンペティションでも有名。なお、自分は今NTUのHPCクラブにいるので来年以降NTUとしてHPC関連コンペに出場する予定である。
- SUSTECH (China), NTU (National Taiwan University, Taiwan), Thammasat University (Thailand)も毎年出ている。
今年は理研のサポートがあり、日本から多くの参加があった。そのうち僕らを含む3チームが入賞しており、その中でも産技高専がHPC部門でトップを飾っていた。
なお、結果はHPC-AI Advisory Councilのプレスリリースから確認できる。
アジア環太平洋の中で見たときにスパコンを持っている国はそう多くなく(e.g. シンガポール、タイ、オーストラリア、日本、中国)、多くの大学や研究機関にスパコンがある日本はかなり恵まれているので、こういった大会を通じてHPC人口が増えるのも大事なのかなと思っている。
おわりに
HPC分野は計算資源が必要という理由で簡単に手を出すことができない分野だと思うが、この大会はスパコンについて何も知らない人にとってもHPCに入門する良いきっかけになると思う。
その理由は
- 1回の実行時間が速く、検証サイクルをたくさん回せること(今回は1ジョブで3分程度)
- 計算クラスターを無料で使えること(Aspire 2A+とFirmus SMC H200クラスターが使えた)
- 目的がはっきりしていて、ベースラインが用意されていること(何をすれば良いのかが明確)
からである。
今年も理研は参加チームを支援しているらしいので、興味があればぜひ参加してみてほしい。
謝辞
この大会の参加にあたり理研R-CCSに支援を頂いています。また、九州大学情報基盤研究開発センターの一般用途のカテゴリのもとで提供していただいた計算資源をトレーニングとして使用させてもらいました。
Discussion