【連載】LangChainの公式チュートリアルを1個ずつ地味に、地道にコツコツと【Basic編#3】
はじめに
こんにちは!「LangChainの公式チュートリアルを1個ずつ地味に、地道にコツコツと」シリーズ第三回、Basic編#3へようこそ。前回の記事では、Azure OpenAIを使ったチャットボット構築の基本を学び、会話履歴の管理やストリーミングなどの応用的な機能を実装しました。今回は、その知識を基に、LangChainの高度な機能である「埋め込み」「キャッシング」「カスタムリトリーバー」を駆使し、ベクトル検索とデータ検索を効率化する方法を解説していきます。
以下は、公式チュートリアルに対応する連載回と記事の有無をまとめた表です。どんどん更新予定なので、ぜひ一緒に学びましょう!
| 公式チュートリアル | 対応する連載記事 | 記事の有無 |
|---|---|---|
| Build a Simple LLM Application with LCEL | Basic編#1 | 公開中 |
| Build a Chatbot | Basic編#2(前回) | 公開中 |
| Build vector stores and retrievers | Basic編#3(本記事) | 公開中 |
| Build an Agent | Basic編#4 | 予定 |
| Build a Retrieval Augmented Generation (RAG) Application | Working with external knowledge編#1 | 予定 |
| Build a Conversational RAG Application | Working with external knowledge編#2 | 予定 |
| Build a Question/Answering system over SQL data | Working with external knowledge編#3 | 予定 |
| Build a Query Analysis System | Working with external knowledge編#4 | 予定 |
| Build a local RAG application | Working with external knowledge編#5 | 予定 |
| Build a Question Answering application over a Graph Database | Working with external knowledge編#6 | 予定 |
| Build a PDF ingestion and Question/Answering system | Working with external knowledge編#7 | 予定 |
| Build an Extraction Chain | Specialized tasks編#1 | 予定 |
| Build a PDF ingestion and Question/Answering system | Specialized tasks編#2 | 予定 |
| Classify text into labels | Specialized tasks編#3 | 予定 |
| Summarize text | Specialized tasks編#4 | 予定 |
RAG (Retrieval Augmented Generation) とは
RAG (Retrieval Augmented Generation) は、外部データソースから取得した情報を使って、LLMの応答を強化する技術です。RAGは、LLM単体では持ち合わせていない知識や情報を活用することで、より正確で包括的な回答を生成することを可能にします。
RAGの処理の流れ
RAGは、一般的に以下の手順で処理を行います。
- データの読み込み: ドキュメントローダーを使用して、外部データソースからテキストデータを読み込みます。
-
テキストの分割: 読み込んだテキストデータを、
TextSplitterを使って適切なチャンクに分割します。 - 埋め込みベクトルの生成: 埋め込みモデルを使って、各テキストチャンクを埋め込みベクトルに変換します。
- ベクトルストアへの格納: 埋め込みベクトルをベクトルストアに格納します。
- クエリに対する類似度検索: ユーザーのクエリを埋め込みベクトルに変換し、ベクトルストアで類似度検索を実行します。
- 関連ドキュメントの取得: 検索結果から、クエリに関連するドキュメントを取得します。
- LLMへの入力: 取得したドキュメントとユーザーのクエリを組み合わせて、LLMへのプロンプトを作成します。
- LLMによる回答生成: LLMがプロンプトに基づいて回答を生成します。
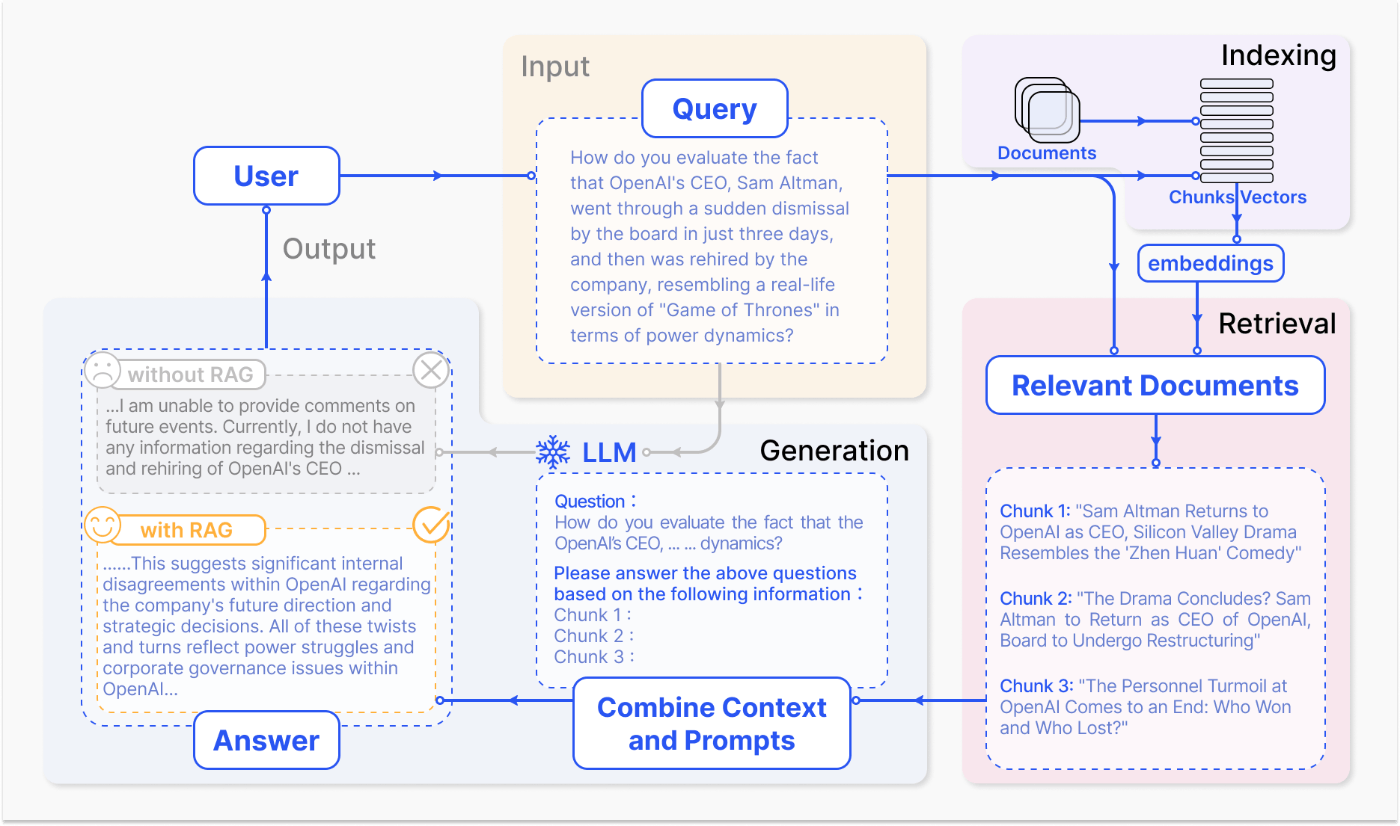
Retrieval-Augmented Generation for Large Language Models: A Survey
LangChainのドキュメントローダー
LangChainは、様々なデータソースからドキュメントを読み込むためのドキュメントローダーを提供しています。ドキュメントローダーは、外部データソースを活用する上で非常に重要な役割を果たします。
ドキュメントローダーとは
ドキュメントローダーは、様々なデータ形式からテキストデータを読み込み、LangChainで処理できるDocumentオブジェクトに変換する機能を提供します。Documentオブジェクトは、テキストデータとそのメタデータを格納するための標準的な形式です。
様々なデータ形式に対応するドキュメントローダー
LangChainでは、CSV、PDF、Markdown、HTMLなど、様々なデータ形式に対応するドキュメントローダーが用意されています。
CSVローダー
CSVLoaderは、CSVファイルからドキュメントを読み込むことができます。CSVファイルは、表形式のデータを扱う際に広く使用されているため、CSVLoaderは非常に便利なドキュメントローダーです。
from langchain.document_loaders import CSVLoader
loader = CSVLoader(file_path='data.csv')
documents = loader.load()
print(documents)
ディレクトリローダー
DirectoryLoaderは、指定されたディレクトリ内のテキストファイルを一括で読み込むことができます。複数のテキストファイルをまとめて処理したい場合に役立ちます。
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader('./data/', glob='*.txt')
documents = loader.load()
print(documents)
HTMLローダー
UnstructuredHTMLLoaderは、HTMLファイルからドキュメントを読み込み、テキストコンテンツを抽出することができます。Webページのコンテンツを解析して利用したい場合に便利です。
from langchain.document_loaders import UnstructuredHTMLLoader
loader = UnstructuredHTMLLoader(file_path='data.html')
documents = loader.load()
print(documents)
JSONローダー
JSONLoaderは、JSONファイルからドキュメントを読み込むことができます。JSONは、Web APIなどで広く使われているデータ形式です。
from langchain.document_loaders import JSONLoader
loader = JSONLoader(file_path='data.json', jq_schema='.[]')
documents = loader.load()
print(documents)
Markdownローダー
MarkdownLoaderは、Markdownファイルからドキュメントを読み込むことができます。Markdownは、READMEファイルやブログ記事などでよく使われている軽量マークアップ言語です。
from langchain.document_loaders import MarkdownLoader
loader = MarkdownLoader(file_path='data.md')
documents = loader.load()
print(documents)
Markdownを要素ごとに分割して読み込む
UnstructuredMarkdownLoader を使用すると、Markdownファイルをタイトル、リスト項目、テキストなどの要素に分割して読み込むことができます。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_path = "README.md"
loader = UnstructuredMarkdownLoader(markdown_path, mode="elements")
data = loader.load()
print(f"Number of documents: {len(data)}\n")
for document in data[:2]:
print(f"{document}\n")
Officeファイルローダー
UnstructuredFileLoaderは、Word (.docx)、PowerPoint (.pptx) などのOfficeファイルからドキュメントを読み込み、テキストコンテンツを抽出することができます。ビジネス文書を扱う場合に役立ちます。
from langchain.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader(file_path='data.docx')
documents = loader.load()
print(documents)
PDFローダー
PyPDFLoaderは、PDFファイルからドキュメントを読み込むことができます。PDFは、電子文書の標準的なフォーマットとして広く普及しています。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(file_path='data.pdf')
documents = loader.load()
print(documents)
カスタムドキュメントローダーの作成
LangChainで提供されているドキュメントローダーでは対応できないデータ形式を扱う場合は、カスタムドキュメントローダーを作成することができます。
カスタムドキュメントローダーを作成するには、BaseLoaderクラスを継承し、loadメソッドを実装します。loadメソッドでは、独自のデータ読み込み処理を実装し、Documentオブジェクトのリストを返すようにします。
from langchain.document_loaders import BaseLoader
from langchain_core.documents import Document
class MyCustomLoader(BaseLoader):
def load(self):
# データの読み込み処理を実装
data = ...
# Documentオブジェクトに変換
documents = [Document(page_content=d) for d in data]
return documents
テキスト分割: Splitter
LangChainでは、長いテキストを扱う際に、TextSplitterを使ってテキストを適切なチャンクに分割することができます。これにより、コンテキストウィンドウのサイズ制限に対応したり、各チャンクを個別に処理したりすることができます。
TextSplitterとは
TextSplitterは、テキストを意味のある単位に分割するためのインターフェースを提供します。分割されたテキストは、それぞれDocumentオブジェクトとして扱われます。
TextSplitterの種類
LangChainには、様々な種類のTextSplitterが用意されています。それぞれのTextSplitterは、異なる基準でテキストを分割します。
-
CharacterTextSplitter: 文字数に基づいてテキストを分割します。 -
RecursiveCharacterTextSplitter: 文字数に基づいてテキストを再帰的に分割します。 -
MarkdownHeaderTextSplitter: Markdownファイルの見出しに基づいてテキストを分割します。 -
HTMLHeaderTextSplitter: HTMLファイルの見出しに基づいてテキストを分割します。 -
HTMLSectionSplitter: HTMLファイルのセクションに基づいてテキストを分割します。 -
CodeSplitter: コードファイルの関数やクラス定義に基づいてテキストを分割します。 -
RecursiveJsonSplitter: JSONファイルを再帰的に分割します。 -
TokenTextSplitter: トークン数に基づいてテキストを分割します。 -
SemanticTextSplitter: テキストの意味的なまとまりに基づいてテキストを分割します。
TextSplitterの実装例
RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitterは、指定されたチャンクサイズを超えないように、テキストを再帰的に分割します。chunk_overlapパラメータで、チャンク間の重複する文字数を指定することができます。
from langchain_core.text_splitter import RecursiveCharacterTextSplitter
# テキスト分割器を初期化
long_text = "これは、RecursiveCharacterTextSplitterの使用例です。このテキストは、チャンクサイズに応じて分割されます。分割されたチャンクは、それぞれ独立して処理されます。"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=20, chunk_overlap=5)
# テキストを分割
texts = text_splitter.create_documents([long_text])
# 分割されたテキストを表示
for i, text in enumerate(texts):
print(f"チャンク {i+1}: {text.page_content}")
MarkdownHeaderTextSplitter
MarkdownHeaderTextSplitterは、Markdownファイルの見出しに基づいてテキストを分割します。headers_to_split_onパラメータで見出しレベルを指定することができます。
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_text = """# 見出し1
これは、見出し1のセクションです。
## 見出し1.1
これは、見出し1.1のセクションです。
## 見出し1.2
これは、見出し1.2のセクションです。
# 見出し2
これは、見出し2のセクションです。
"""
# MarkdownHeaderTextSplitterを初期化
headers_to_split_on = ["# ", "## "]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# テキストを分割
markdown_docs = markdown_splitter.create_documents([markdown_text])
# 分割されたドキュメントを表示
for i, doc in enumerate(markdown_docs):
print(f"ドキュメント {i+1}:\n{doc.page_content}")
HTMLHeaderTextSplitter
HTMLHeaderTextSplitterは、HTMLファイルの見出しに基づいてテキストを分割します。headers_to_split_onパラメータで見出しレベルを指定することができます。
from langchain.text_splitter import HTMLHeaderTextSplitter
html_text = """<h1>見出し1</h1>
<p>これは、見出し1のセクションです。</p>
<h2>見出し1.1</h2>
<p>これは、見出し1.1のセクションです。</p>
<h3>見出し1.1.1</h3>
<p>これは、見出し1.1.1のセクションです。</p>
<h1>見出し2</h1>
<p>これは、見出し2のセクションです。</p>
"""
# HTMLHeaderTextSplitterを初期化
headers_to_split_on = ["h1", "h2"]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
# テキストを分割
html_docs = html_splitter.create_documents([html_text])
# 分割されたドキュメントを表示
for i, doc in enumerate(html_docs):
print(f"ドキュメント {i+1}:\n{doc.page_content}")
HTMLSectionSplitter
HTMLSectionSplitterは、HTMLファイルのセクションに基づいてテキストを分割します。セクションを区切るタグを指定することで、テキストを意味のある単位に分割することができます。
from langchain.text_splitter import HTMLSectionSplitter
html_text = """<section>
<h1>見出し1</h1>
<p>これは、セクション1の内容です。</p>
</section>
<section>
<h2>見出し2</h2>
<p>これは、セクション2の内容です。</p>
</section>
"""
# HTMLSectionSplitterを初期化
html_splitter = HTMLSectionSplitter(section_tag="section")
# テキストを分割
html_docs = html_splitter.create_documents([html_text])
# 分割されたドキュメントを表示
for i, doc in enumerate(html_docs):
print(f"ドキュメント {i+1}:\n{doc.page_content}")
CodeSplitter
CodeSplitterは、コードファイルの関数やクラス定義に基づいてテキストを分割します。プログラミング言語に合わせて適切な分割を行うことができます。
from langchain.text_splitter import CodeSplitter
python_code = """
def my_function(a, b):
"""これは関数です。"""
return a + b
class MyClass:
"""これはクラスです。"""
def __init__(self, x):
self.x = x
"""
# CodeSplitterを初期化
code_splitter = CodeSplitter(language="python")
# コードを分割
code_docs = code_splitter.create_documents([python_code])
# 分割されたドキュメントを表示
for i, doc in enumerate(code_docs):
print(f"ドキュメント {i+1}:\n{doc.page_content}")
RecursiveJsonSplitter
RecursiveJsonSplitterは、JSONファイルを再帰的に分割します。ネストされたJSONデータ構造を、扱いやすいチャンクに分割することができます。
from langchain.text_splitter import RecursiveJsonSplitter
json_data = {
"name": "山田太郎",
"age": 30,
"address": {
"country": "日本",
"city": "東京都",
},
"hobbies": ["読書", "映画鑑賞", "旅行"],
}
# RecursiveJsonSplitterを初期化
json_splitter = RecursiveJsonSplitter()
# JSONデータを分割
json_docs = json_splitter.create_documents([json_data])
# 分割されたドキュメントを表示
for i, doc in enumerate(json_docs):
print(f"ドキュメント {i+1}:\n{doc.page_content}")
TokenTextSplitter
TokenTextSplitterは、トークン数に基づいてテキストを分割します。encoding_nameパラメータでトークンのエンコーディング方式を指定することができます。
from langchain.text_splitter import TokenTextSplitter
# トークン分割器を初期化
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0, encoding_name="cl100k_base")
# テキストを分割
text = "これは、TokenTextSplitterの使用例です。このテキストは、トークン数に応じて分割されます。"
texts = text_splitter.create_documents([text])
# 分割されたテキストを表示
for i, text in enumerate(texts):
print(f"チャンク {i+1}: {text.page_content}")
SemanticTextSplitter
SemanticTextSplitterは、テキストの意味的なまとまりに基づいてテキストを分割します。意味的に関連する文章をまとめてチャンク化することで、より自然な分割を行うことができます。
# !pip install nltk
import nltk
from langchain.text_splitter import SemanticTextSplitter
nltk.download('punkt')
# SemanticTextSplitterを初期化
text_splitter = SemanticTextSplitter(chunk_size=100, chunk_overlap=20)
# テキストを分割
text = "これは、SemanticTextSplitterの使用例です。このテキストは、意味的なまとまりに応じて分割されます。意味的な分割により、各チャンクがより自然な単位になります。"
texts = text_splitter.create_documents([text])
# 分割されたテキストを表示
for i, text in enumerate(texts):
print(f"チャンク {i+1}: {text.page_content}")
テキストの埋め込み
TextSplitterでテキストを分割したら、次に埋め込みモデルを使って、各テキストチャンクを埋め込みベクトルに変換します。
埋め込みとは何か、なぜ重要なのか
テキスト埋め込み(Text Embedding)とは、自然言語で書かれたテキストを、コンピュータが理解しやすい固定長の数値ベクトルに変換する技術です。このベクトルは、テキストの意味や文脈を反映するように設計されており、テキスト同士の類似度を計算したり、機械学習モデルの入力として使用したりすることができます。
埋め込みは、自然言語処理の様々なタスクにおいて重要な役割を果たします。例えば、
- 意味の理解: 埋め込みベクトルは、テキストの意味を数値化することで、コンピュータがテキストの意味を理解しやすくなります。
- 類似度計算: 埋め込みベクトル間の距離や角度を計算することで、テキスト同士の類似度を定量化することができます。
- 機械学習への入力: 埋め込みベクトルは、テキスト分類、感情分析、質問応答など、様々な機械学習タスクの入力特徴量として使用できます。
LangChainでの埋め込みモデルの使い方
LangChainでは、OpenAI、Hugging Faceなど、様々な埋め込みモデルを簡単に利用することができます。ここでは、Azure OpenAIの埋め込みモデルを例に、LangChainでの使い方を説明します。
import os
from dotenv import find_dotenv, load_dotenv
from langchain_openai import AzureOpenAIEmbeddings
# 環境変数を設定します
load_dotenv(find_dotenv())
# AzureOpenAIEmbeddingsインスタンスを作成します
embeddings = AzureOpenAIEmbeddings(
deployment_name=os.environ["AZURE_OPENAI_DEPLOYMENT"],
model=os.environ["AZURE_OPENAI_MODEL_NAME"],
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
複数の埋め込みモデルの組み合わせ
複数の埋め込みモデルを組み合わせることで、より精度の高い埋め込みベクトルを得ることができます。LangChainでは、MultiEmbeddingクラスを使って、複数の埋め込みモデルを組み合わせることができます。
from langchain_core.embeddings import MultiEmbedding
from langchain_huggingface import HuggingFaceEmbeddings
# 複数の埋め込みモデルを定義
embeddings = MultiEmbedding(
embeddings=[
embeddings, # Azure OpenAIの埋め込みモデル
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"),
]
)
埋め込みを活用した検索システムの構築
埋め込みベクトルを活用することで、高精度な類似度検索システムを構築することができます。LangChainでは、様々なベクトルストアと連携して、埋め込みベクトルを効率的に管理・検索することができます。
ベクトルストア
ベクトルストアは、埋め込みベクトルを格納・検索するためのデータベースです。LangChainでは、Chroma、FAISS、Pineconeなど、様々なベクトルストアをサポートしています。ベクトルストアを利用することで、大量のテキストデータに対して高速な類似度検索を実行することができます。
ベクトルストアの共通機能
LangChainのベクトルストアは、以下の共通機能を提供します。
-
埋め込みベクトルの追加:
add_textsメソッドやadd_documentsメソッドを使って、埋め込みベクトルを追加することができます。 -
類似度検索:
similarity_searchメソッドやsimilarity_search_with_scoreメソッドを使って、クエリに類似したドキュメントを検索することができます。 - その他の検索方法: ベクトルストアによっては、最大マージン関連検索(MMR)やスコア閾値検索などの検索方法も提供しています。
ベクトルストアの実装例
Chroma
Chromaは、使いやすさと高速な検索性能が特徴のベクトルストアです。ローカル環境で手軽に利用できるため、小規模なプロジェクトやプロトタイピングに適しています。
from langchain.vectorstores import Chroma
# 埋め込み対象のドキュメントを作成
documents = [
Document(page_content="犬は忠実な友達です。", metadata={"source": "ペット百科事典"}),
Document(page_content="猫は独立心が強いです。", metadata={"source": "猫の飼い方ガイド"}),
]
# Chromaベクトルストアを初期化
vectorstore = Chroma.from_documents(documents, embeddings)
FAISS
FAISS (Facebook AI Similarity Search) は、高速な検索性能に特化したベクトルストアです。大規模なデータセットに対しても高速な検索を実現することができます。C++で実装されており、Pythonからも利用可能です。
from langchain.vectorstores import FAISS
# 埋め込み対象のドキュメントを作成
documents = [
Document(page_content="犬は忠実な友達です。", metadata={"source": "ペット百科事典"}),
Document(page_content="猫は独立心が強いです。", metadata={"source": "猫の飼い方ガイド"}),
]
# FAISSベクトルストアを初期化
vectorstore = FAISS.from_documents(documents, embeddings)
Pinecone
Pineconeは、スケーラビリティと信頼性に優れたクラウドベースのベクトルストアです。大規模なデータセットを管理し、高速な検索を提供することができます。マネージドサービスのため、運用負荷が低く、商用利用にも適しています。
from langchain.vectorstores import Pinecone
# 埋め込み対象のドキュメントを作成
documents = [
Document(page_content="犬は忠実な友達です。", metadata={"source": "ペット百科事典"}),
Document(page_content="猫は独立心が強いです。", metadata={"source": "猫の飼い方ガイド"}),
]
# Pineconeベクトルストアを初期化
vectorstore = Pinecone.from_documents(
documents, embeddings, index_name="langchain-demo"
)
ベクトルストアの選択基準
ベクトルストアを選ぶ際には、以下の点を考慮する必要があります。
- データ規模: 扱うデータの量によって、適切なベクトルストアは異なります。小規模なデータセットであればChroma、大規模なデータセットであればFAISSやPineconeが適しています。
- 検索速度: 必要な検索速度はアプリケーションによって異なります。高速な検索が必要な場合は、FAISSやPineconeを検討しましょう。
- スケーラビリティ: データ量の増加に対応できるスケーラビリティが必要かどうか。将来的にデータ量が増加する見込みがある場合は、Pineconeのようなクラウドベースのベクトルストアが適しています。
- 費用: クラウドベースのベクトルストアは、利用料金が発生する場合があります。費用を抑えたい場合は、ChromaやFAISSのようなオープンソースのベクトルストアを検討しましょう。
- 機能: フィルタリングやデータ管理などの機能が必要かどうか。高度な機能が必要な場合は、Pineconeのようなマネージドサービスを検討しましょう。
時間加重ベクトルストア
TimeWeightedVectorStoreRetrieverを使うと、時間の経過とともにドキュメントの重要度を減衰させることができます。これは、ニュース記事やソーシャルメディアの投稿など、時間とともに鮮度が落ちる情報を取り扱う際に役立ちます。
from langchain_core.retrievers import TimeWeightedVectorStoreRetriever
# 時間加重ベクトルストアを作成
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=0.99)
# ドキュメントを追加 (新しいドキュメントはより高い重みを持つ)
retriever.add_documents(
[Document(page_content="最新のニュースです。", metadata={"timestamp": "2023-12-20"})]
)
# 検索 (新しいドキュメントが優先的に返される)
results = retriever.get_relevant_documents("ニュース")
print(results)
ハイブリッド検索
LangChainでは、ベクトル検索とキーワード検索などの異なる検索手法を組み合わせたハイブリッド検索を実装することができます。これにより、それぞれの検索手法の長所を生かし、より包括的な検索結果を得ることが可能になります。例えば、ベクトル検索で意味的に関連性の高いドキュメントを取得し、キーワード検索で特定の単語を含むドキュメントを絞り込むことができます。
from langchain_core.retrievers import HybridSearchRetriever
from langchain_keyword_search.keyword_search import KeywordSearch
# キーワード検索を初期化
keyword_search = KeywordSearch.from_documents(documents)
# ハイブリッド検索を作成
retriever = HybridSearchRetriever(
vectorstore_retriever=vectorstore.as_retriever(),
keyword_search_retriever=keyword_search,
)
# 検索 (ベクトル検索とキーワード検索の結果がマージされる)
results = retriever.get_relevant_documents("犬")
print(results)
最大マージン関連検索
最大マージン関連検索 (Maximal Marginal Relevance Search: MMR) は、多様性と関連性のバランスをとった検索結果を得るための手法です。検索クエリに関連性の高いドキュメントだけでなく、多様性も考慮することで、よりユーザーのニーズに合った検索結果を提供することができます。
# 検索クエリを埋め込み
query_embedding = embeddings.embed_query("猫")
# MMRを使って類似するドキュメントを検索
results = vectorstore.max_marginal_relevance_search(
query_embedding, k=2, fetch_k=4
)
for result in results:
print(f"コンテンツ: {result.page_content}, メタデータ: {result.metadata}")
Retriever
LangChainにおけるRetrieverは、様々なデータソースから関連するドキュメントを取得するための汎用的なインターフェースです。RetrieverはRunnableを継承しており、LangChain Expression Languageチェーンに組み込むことができます。
Retrieverの種類
LangChainには、様々な種類のRetrieverが用意されています。
-
VectorStoreRetriever: ベクトルストアからドキュメントを取得するRetrieverです。 -
SelfQueryRetriever: クエリ自体をドキュメントとしてベクトルストアに追加し、類似のドキュメントを検索するRetrieverです。 -
TimeWeightedVectorStoreRetriever: 時間の経過とともにドキュメントの重要度を減衰させるRetrieverです。 -
ParentDocumentRetriever: ドキュメントの親子関係を考慮した検索を行うRetrieverです。
VectorStoreRetriever
VectorStoreRetrieverは、ベクトルストアからドキュメントを取得するためのRetrieverです。VectorStoreRetrieverを使うことで、ベクトルストアに保存されている埋め込みベクトルに基づいて、クエリに類似したドキュメントを検索することができます。
VectorStoreRetrieverは、以下の属性を持ちます。
-
vectorstore: ベクトルストア -
search_type: 検索方法("similarity", "mmr", "similarity_score_threshold") -
search_kwargs: 検索に渡す追加の引数
search_type
search_type属性は、以下のいずれかの値を指定することができます。
-
"similarity": 類似度検索(デフォルト) -
"mmr": 最大マージン関連検索 -
"similarity_score_threshold": スコア閾値検索
search_kwargs
search_kwargs属性は、検索に渡す追加の引数を指定することができます。
例えば、k引数を指定することで、取得するドキュメントの件数を指定することができます。
# 類似度検索で上位3件のドキュメントを取得する
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
Retrieverを使ったRAGの例
Retrieverは、RAG(Retrieval Augmented Generation)パイプラインの一部として使用することができます。
RAGは、外部データソースから取得した情報を使って、LLMの応答を強化する技術です。
以下の例では、Retrieverを使ってWikipediaの記事から関連する情報を取得し、LLMに渡して質問に答えています。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain.vectorstores import Wikipedia
from langchain_openai import AzureChatOpenAI
from langchain.chains import RetrievalQA
# Wikipediaベクトルストアを作成
wikipedia = Wikipedia()
# Azure OpenAIのチャットモデルを初期化
llm = AzureChatOpenAI(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
# Retrieverを作成
retriever = wikipedia.as_retriever()
# RAGパイプラインを作成
rag_pipeline = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=retriever
)
# 質問
query = "東京の人口は?"
# 質問に答える
result = rag_pipeline.run(query)
# 結果を表示
print(result)
また、以前の記事で、もう少し具体的な実装例を紹介しています。
埋め込みデータのキャッシングとその効果的な活用法
埋め込みの計算は、計算コストがかかる場合があります。同じテキストに対する埋め込みを何度も計算するのは非効率です。そこで、キャッシングを導入することで、一度計算した埋め込み結果を再利用し、処理速度を向上させることができます。
キャッシュの仕組み
キャッシュは、埋め込み結果を保存しておく一時的な記憶領域です。同じテキストに対する埋め込みが要求された場合、キャッシュに保存されている結果を返すことで、再計算を避けることができます。
キャッシュのメリット
- 処理速度の向上: 埋め込みの再計算が不要になるため、処理速度が向上します。
- 計算コストの削減: 埋め込みの計算回数が減るため、計算コストを削減することができます。
LangChainでのキャッシュ実装
LangChainでは、InMemoryCacheなどのキャッシュクラスを提供しています。
from langchain_core.cache import InMemoryCache
# キャッシュを初期化
cache = InMemoryCache()
# 埋め込みモデルにキャッシュを設定
embeddings.cache = cache
# テキストを埋め込み(キャッシュされます)
embedding_1 = embeddings.embed_query("猫は独立心が強い。")
embedding_2 = embeddings.embed_query("猫は独立心が強い。") # ここでキャッシュが利用されます
print(embedding_1 == embedding_2) # True が出力されます
Redisを使ったキャッシュの永続化
InMemoryCacheは、アプリケーションが終了するとキャッシュの内容が失われます。キャッシュの内容を永続化したい場合は、Redisなどの外部キャッシュを使用することができます。
from langchain_core.cache import RedisCache
# Redisキャッシュを初期化
cache = RedisCache(redis_url="redis://localhost:6379")
# 埋め込みモデルにキャッシュを設定
embeddings.cache = cache
# テキストを埋め込み(Redisにキャッシュされます)
embedding_1 = embeddings.embed_query("猫は独立心が強い。")
カスタムリトリーバーの作成と応用
LangChainでは、デフォルトのリトリーバー以外にも、独自のロジックで動作するカスタムリトリーバーを作成することができます。
カスタムリトリーバーの必要性
カスタムリトリーバーを作成する必要があるのは、例えば以下のような場合です。
- 特定のデータソースからドキュメントを取得したい場合
- 特定の条件でドキュメントをフィルタリングしたい場合
- 独自のランキングアルゴリズムでドキュメントを並べ替えたい場合
RunnableLambdaを使ったカスタムリトリーバーの実装
RunnableLambdaを使うと、Pythonの関数をリトリーバーとして使用することができます。
from langchain_core.runnables import RunnableLambda
# カスタム検索ロジックを実装
def custom_search(query):
# 単純な例として、クエリに基づいてフィルタリングを行います
if "犬" in query:
return [documents[0]]
elif "猫" in query:
return [documents[1]]
else:
return []
# カスタムリトリーバーを定義
custom_retriever = RunnableLambda(custom_search)
# クエリを実行
results = custom_retriever.invoke("犬に関する情報を教えてください。")
for result in results:
print(result.page_content)
リトリーバーのスコアリング
リトリーバーは、取得したドキュメントにスコアを付与することができます。このスコアは、ドキュメントとクエリとの関連性の強さを表し、より関連性の高いドキュメントを上位に表示する際に役立ちます。
LangChainでは、ScoreThresholdRetrieverなど、スコアに基づいてドキュメントをフィルタリングするリトリーバーも提供されています。
from langchain_core.retrievers import ScoreThresholdRetriever
# スコア閾値リトリーバーを作成
retriever = ScoreThresholdRetriever(vectorstore.as_retriever(), score_threshold=0.8)
# 検索 (スコアが0.8以上のドキュメントのみが返される)
results = retriever.get_relevant_documents("犬")
print(results)
文脈圧縮によるコンテキストの最適化
LangChainでは、ContextualCompressionRetrieverを用いることで、取得したドキュメントの文脈を圧縮し、コンテキストウィンドウのサイズ制限に対応することができます。
文脈圧縮は、類似したドキュメントをまとめたり、重要度の低い部分を削除することで、コンテキストウィンドウに収まるように情報を絞り込む技術です。
from langchain_core.retrievers import ContextualCompressionRetriever
# 文脈圧縮リトリーバーを作成
retriever = ContextualCompressionRetriever(
base_retriever=vectorstore.as_retriever(),
compression_function=lambda docs: "".join([doc.page_content for doc in docs]),
)
# 検索 (圧縮されたコンテキストが返される)
results = retriever.get_relevant_documents("犬と猫")
print(results)
複数のリトリーバーの組み合わせ
LangChainでは、複数のリトリーバーを組み合わせて使用することもできます。例えば、ベクトル検索とキーワード検索を組み合わせることで、より精度の高い検索システムを構築することができます。
複数のリトリーバーを組み合わせるには、EnsembleRetrieverを使用します。EnsembleRetrieverは、複数のリトリーバーから取得したドキュメントをマージし、重複を削除することができます。
投票方式
EnsembleRetrieverは、デフォルトでは投票方式でドキュメントをマージします。各リトリーバーが返したドキュメントに投票を行い、最も多くの票を獲得したドキュメントを上位に表示します。
from langchain_core.retrievers import EnsembleRetriever
# アンサンブルリトリーバーを作成 (投票方式)
retriever = EnsembleRetriever(
retrievers=[vectorstore.as_retriever(), keyword_search]
)
# 検索 (ベクトル検索とキーワード検索の結果がマージされる)
results = retriever.get_relevant_documents("犬")
print(results)
重み付け
EnsembleRetrieverでは、各リトリーバーに重みを設定することもできます。重みが高いリトリーバーが返したドキュメントは、より上位に表示されます。
# アンサンブルリトリーバーを作成 (重み付け)
retriever = EnsembleRetriever(
retrievers=[vectorstore.as_retriever(), keyword_search],
weights=[0.8, 0.2], # ベクトル検索の重みを高く設定
)
# 検索 (ベクトル検索とキーワード検索の結果がマージされる)
results = retriever.get_relevant_documents("犬")
print(results)
親ドキュメントのリトリーバル
ParentDocumentRetrieverを使うと、ドキュメントの親子関係を考慮した検索を行うことができます。
例えば、長いドキュメントを複数のチャンクに分割してベクトルストアに保存している場合、ParentDocumentRetrieverを使うことで、関連するチャンクだけでなく、そのチャンクが属する元のドキュメント全体を取得することができます。
from langchain_core.retrievers import ParentDocumentRetriever
# 親ドキュメントリトリーバーを作成
retriever = ParentDocumentRetriever(
vectorstore_retriever=vectorstore.as_retriever(),
document_id_key="document_id",
)
# 検索 (関連するチャンクと親ドキュメントが返される)
results = retriever.get_relevant_documents("犬")
print(results)
自己クエリリトリーバー
SelfQueryRetrieverを使うと、クエリ自体をドキュメントとしてベクトルストアに追加し、そのクエリに類似したドキュメントを検索することができます。
これは、ユーザーが入力したクエリに似た過去のクエリとその回答を検索する際に役立ちます。
from langchain_core.retrievers import SelfQueryRetriever
# 自己クエリリトリーバーを作成
retriever = SelfQueryRetriever(
vectorstore=vectorstore,
search_kwargs={"k": 5}, # 類似クエリを5件取得
)
# 検索 (クエリに類似した過去のクエリと回答が返される)
results = retriever.get_relevant_documents("犬の飼い方")
print(results)
フィルタリングによるメタデータに基づいた検索
リトリーバーは、メタデータに基づいてドキュメントをフィルタリングすることができます。
例えば、特定の著者によって書かれたドキュメントだけを検索したい場合などに便利です。
# メタデータに基づいてフィルタリング
retriever = vectorstore.as_retriever(
search_kwargs={"filter": {"author": "山田太郎"}}
)
# 検索 (山田太郎によって書かれたドキュメントのみが返される)
results = retriever.get_relevant_documents("犬")
print(results)
まとめ
今回は、LangChainを用いたテキストの埋め込み、キャッシングによる効率化、カスタムリトリーバーの作成と応用、そして様々なデータソースからドキュメントを読み込むためのドキュメントローダー、テキスト分割について解説しました。
- ドキュメントローダー: 様々なデータ形式からテキストデータを読み込み、LangChainで処理できる形式に変換することで、多様なデータソースを活用できます。
- テキスト分割: 長いテキストを適切なチャンクに分割することで、コンテキストウィンドウのサイズ制限に対応したり、各チャンクを個別に処理したりすることができます。
- 埋め込み: テキストデータを数値ベクトルに変換することで、コンピュータがテキストの意味を理解しやすくなり、類似度計算や機械学習への入力に利用できます。
- ベクトルストア: 埋め込みベクトルを格納・検索するためのデータベースです。大量のテキストデータに対して高速な類似度検索を実行することができます。
- Retriever: ベクトルストアやその他のデータソースから関連するドキュメントを取得するためのインターフェースです。
- キャッシング: 埋め込みの計算結果をキャッシュすることで、処理速度の向上と計算コストの削減を実現できます。
- カスタムリトリーバー: 特定のデータソースや検索ロジックに対応したリトリーバーを作成することで、柔軟な検索システムを構築できます。
これらの技術を組み合わせることで、より高度で柔軟な検索システムやチャットボットを構築することができます。
次回は、これらの技術をさらに発展させ、複雑な質問応答システムの構築に挑戦します。
参考文献
- LangChain公式チュートリアル: Build vector stores and retrievers
- LangChain公式ドキュメント: How to Guides
Discussion