ChromeのContentに関するドキュメントを読む

High-level overview
contentモジュールは src/content に配置されている、そして、 content モジュールはマルチプロセスサンドボックス化されたブラウザを使って、ページをレンダリングするのに必要なコアコードだ。 content モジュールはすべての Web Platform の機能(i.e. HTML5)と、GPUアクセラレーションを含んでいる。
Motivation
Chromiumコードが成長するにつれて、機能が必然的に誤った場所にフックされる、そしてそれはレイヤリング違反や存在すべきでない依存の原因になる。何が最もいい方法かを見つけ出すのは開発者には難しいことだ。なぜなら、API(それらが存在するとき)と機能は同じディレクトリにあったから。この問題を避けるため、かつ、マルチプロセスブラウザで利用するページをレンダリングするコアな部品間に明快な境界を追加するために、Chromeコードを src/contentに移動するためのコンセンサスが作られた(content not chrome :) ).。
ここで content not chrome をカッコで書いているのは、リンク先では、"content, not chrome" = (Chrome (UI部品のchromeと、Google Chromeを両方指していると思われる)ではなく、コンテンツに集中できるようにしよう)と書いているのに、Chromeのコードを src/contentに移動させるのが面白いよね、ということかな?
content vs chrome
content はWeb Platformを実装するのに必要なコードを含むだけにするべきだ。一般的に、ある機能がこのカテゴリに属するのは、次のすべてのことがtrueであるときだ:
- そのローンチが https://chromestatus.com ダッシュボードでトラックされている
- specに関係している
- feature development lifecycleを通る
反対に、多くの共通モダンなWebブラウザ機能だが、これらのチェックリストを満たしていない機能は content には実装されていない。非網羅的なリストは次のとおりだ:
- Extensions
- NaCl
- SpellChecker
- Autofill
- Sync
- Safe Browsing
- Translation
その代わりに、これらの機能は chrome に実装されていて、content はこれらの機能が必要とするイベントをsubscribeできるようにするための一般的な拡張ポイントのみを提供する。いくつかの機能は新たに拡張ポイントを必要とする: より詳細を知りたい場合は「How to Add New Features(without bloating RenderView/RenderViewHost/WebContents)」を参照。
最後に、ベンダーから提供されているオンラインサービスとのインタラクションを必要とするいくつかのブラウザの機能がある(e.g. Safe Browsing Translate, Sync, Autofill はさまざまなネットワークサービスを必要としている)。 chromeレイヤーはベンダー固有の統合動作をカプセル化をするのに中立な場所である。
content に実装されたウェブプラットフォーム機能がネットワークサービスに依存するまれなケース(例えば、Geolocationで使用されるネットワークロケーションサービス)については、content はエンベッダーがエンドポイントを注入する方法を提供する必要があります(例えば、chrome は使用するサービスURLを提供するかもしれません)。
content モジュール自身はベンダー固有のハードコードのロジックをなしにして、汎用性を維持しなければいけません。
Architectural Diagram
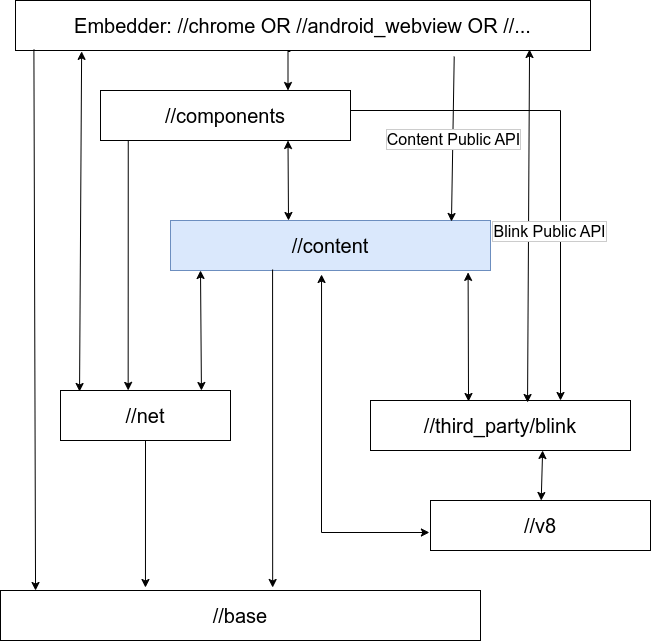
古い図は https://www.chromium.org/developers/content-module を参照。
図は、異なるモジュールのレイヤーを図示している。モジュールは低層のコードを直接includeできる。しかし、そのモジュールよりも高層のモジュールはincludeできない。これは、DEPSルールで強制されている。モジュールはembedder用のAPIを実装でき、自分より低層のモジュールはembedder用のAPIを呼び出すことができる。これらのAPIの例はWebKit APIとContent APIだ。
https://www.chromium.org/developers/content-module. にある図と比較すると、chrome と content の依存関係が整理されていそう。もともとは、全てが双方向に依存していたが、chrome と content の依存関係を chrome -> content にすることで、 chrome 以外が content に依存しやすくなった(?)。
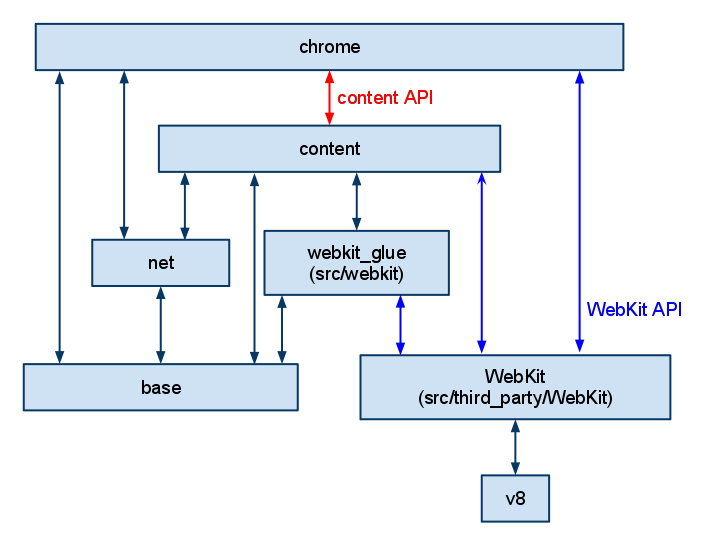
net が chrome に依存していたり、 third_party/blink が chrome に依存しているっぽいのはどういうところなんだろう。subscribeできるように拡張ポイントを実装する必要があると書いてたから、subscribeして、embedder側からpublishする部分もあるから双方向なのかな。具体例を見ないと分からない。
Content API
Content APIは、コンテンツ内のコードが Chrome を間接的に呼び出す方法です。可能な場合、Chromeの機能は、IPCをフィルタリングして、 「How to Add New Features」に記載の通りイベントをリッスンすることでフックを試みる。十分なコンテキストがないとき(i.e. WebKit からのcallback)や、callbackが単発の場合は、embedder(Chrome) が実装するContentClientインターフェースがあります。 ContentClient はすべてのプロセスで利用可能です。いくつかのプロセスではそのプロセス自身のcallback APIがあります (i.e. ContentBrowserClient/ContentRendererClient/ContentPluginClient)。
Status and Roadmap
現状の content のステータスは、chrome に依存していません(meta bugやすべてのそれに依存しているバグ を見てください)。私達は今、すべてのプラットフォームで content を使ってページを描画する content (content_shell)の上に構築されている、基本的なブラウザを持っています。これは、Web Platformやcontentのコアコードの開発者が、Chromeすべてではなくcontent のみをビルドテストすることを可能にしています。
私達はcontent_unittestsにあるcontentのユニットテストと、content_browsertests にある統合テストの別れたターゲットを持っています。
contentはビルドを高速化するために別れたdllでビルドされる。
私たちは、WebKit APIと同様に、コンテンツに関するAPIを作成しました。これにより、エンベッダとコンテンツの内部構造が分離され、エンベッダがどのメソッドを使用しているかが、コンテンツに関わる人々にとって明確になります。