object detectionタスクのdynamic label assignmentに関する近年の研究成果についての補遺
概要
近年におけるobject detectionタスクの研究では、提案boxに正例、負例のラベルを割り当てる処理(label assignment)をモデルの内部状態に基づいて動的に行うdynamic assignmentが主流となっていることを以前書いた記事で述べた。
本稿ではdynamic label assignmentに関する比較的最近(2019年以降)の研究成果のうち、以前の記事で扱わなかったものについて補足する。
前提知識
本稿の内容を理解するにあたって以下の2点について説明する。
- "anchor"という用語について
- anchor-based手法における2種類の予測boxについて
"anchor"という用語について
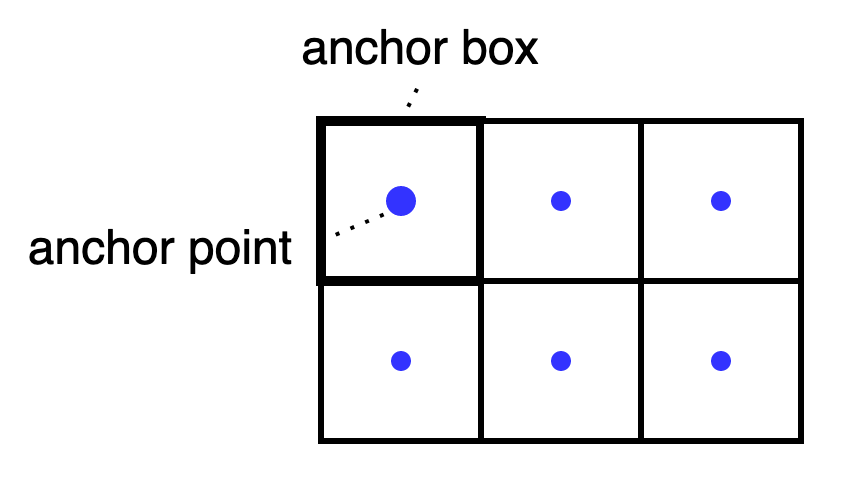
Object detection界隈の論文では"anchor"という言葉が複数の意味で用いられているようなので本項では以下のように定義する。
- anchor point: 候補boxの生成の元となるfeature map上の点。
- anchor box: anchor pointを中心とするfeature map上の1/n x 1/nの区画。
文脈から推察できる場合は上記をともに「anchor」と呼ぶ。そうでない場合は上記の明示的な呼び方を用いる。
anchor-based手法における2種類の予測boxについて
anchor-basedなobject detection modelは、本質的に以下の2段階の予測boxを行っているとみなせる。
- anchor box: anchor box自体。
- predicted box: anchor pointのembeddingをもとに回帰ヘッダにより予測されるより正確なboxのこと。
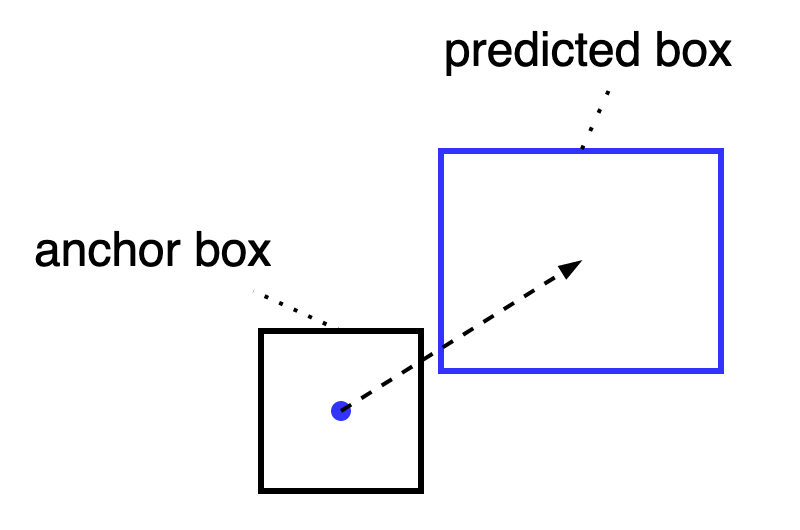
実際、ATSS[1]ではanchor boxとGTとのIoUに基づいてlabel assignmentを決定しているので、anchor boxを「1段階目の粗い予測」として活用している。本稿では可能な限り両者を区別して表記するが、文脈から想定できる場合は単にboxと表記する。
label assignment に predicted boxを利用する
ATSS[1]ではlabel assignmentにおけるboxの評価値をanchor boxとGTとのIoUに基づいて計算していた。
これに対し、DLA[7]はanchor boxとGTとのIoU(AIoU)に加えて、回帰ヘッダの出力する予測boxとGTとのIoU(PIoU)も加味して評価値を計算する。
Anchor boxは学習可能なパラメータを持たないため、モデルの学習状態を加味してboxの評価を決定することができない、一方、回帰ヘッダが予測するboxはモデルの学習状態を反映しているため、より正確な評価ができると考えられる。
その一方で、学習の初期段階においては回帰ヘッダの予測するboxの評価値は信頼できず、anchor boxに基づく評価値がよりモデルの学習の助けになると考えられる。
このような考察から、DLAではAIoUとPIoUを組み合わせたassignment方針をとる。
具体的にはGT付近のPIoUとAIoUのスコアの平均と分散をそれぞれ独立して算出し、両者を足し合わせた以下の式により閾値を動的に決定する。
class予測タスクにlocalityの評価を組み込む
Object detectionの研究論文では伝統的にpost processにNMS(Non Maximum Suppression)が使用されることが多い。NMSではモデルの予測するboxの評価値に基づいて、重複したboxのうち評価値の高いboxのみをのこす処理を行う。boxの評価値をどのように設計するかについては試行錯誤の余地がある。一般的にはクラスの予測確率とboxの位置の精度の評価値(locality)に基づいて行われることが多い。
例えば、FCOSではboxのlocalityの評価値としてGTと予測boxとのIoUを予測する独立したheadをもち、推論時にclassの予測確率とIoUの予測値を掛け合わせたものをboxの評価値とする。
ところが、クラス予測確率とIoU予測値は学習時は独立して学習しているのに対し、推論時に両者を掛け合わせているので、このようにヒューリスティックに決定したboxの評価値が真の評価値の推定値として最適である保証はない。
また、IoU予測値は正例のサンプルのみで学習しているため、負例に対しては過大なスコアを出力する可能性がある。
以上の考察に基づき、[2]ではクラス予測値とIoUスコアの予測値を同時に学習する手法を提案する。
具体的にはクラスの予測ヘッダを学習するさい、ターゲットをクラスのone-hotベクトルにGTとのIoUを掛け合わせたソフトラベルを用いる。
なお、負例についてはIoUが定義できないため
また、RetinaNet以降に提案されたモデルは正例と負例のクラス不均衡を改善するために、Focal Lossを損失関数とする場合が多い。
ところが、Focal Lossはソフトラベルに対応していないので、[2]では以下のようなFocal lossをソフトラベルに拡張した損失関数を提案する。
新しいloss関数ではBinary Cross Entropy LossにIoU評価値とclass-box評価値の誤差の
Focal Lossをソフトラベルに拡張したLossには他にもVFL(Varifocal Loss)[4]がある。
こちらの形式では正例と負例で重みが非対称になっている。
負例に対しては元のFocal Lossと同じだが、正例に対してはソフトラベルとの誤差でなく、ソフトラベルの値自体を重みとして用いている。これは、著者らによると、「質の高い(=IoUの大きい)正例をより重視する」意図らしい。
論文中の報告では、QFL, VFLともにCOCO APで0.7-0.9ポイントのゲインを得ている[3,4]。
class予測タスクとbox回帰タスクをアーキテクチャレベルで協調して学習する
QFLやVFLではソフトラベルによって間接的にlocalityの評価値をclassification headに組み込んだが、依然として学習時はclassification taskとlocationの回帰タスクで独立したheadを使い学習している。
これに対し、TOOD[6]はさらに踏み込んでクラスの予測タスクとlocationの回帰タスクをアーキテクチャレベルで協調して学習する手法を提案した。
この研究ではclassの評価値が最大となるanchor boxとlocalityの評価値が最大となるanchor boxが異なることに着目し、両者に相関を持たせることを目標とする。
ナイーブには両者のheadの大部分を共通とし、最後の浅いレイヤのみ異なるアーキテクチャが考えうるが、一般的にクラスの予測とboxのlocationの回帰には特徴マップの同じ領域を使用するとは限らない。
これに対し、提案手法では特徴抽出用のheadの大部分は共通としつつ、タスクに応じて注目するfeature mapの領域を選択する方式をとる。
具体的には、以下のような処理を行う。
表記について、
FPNの出力特徴マップから新たに抽出した特徴マップ
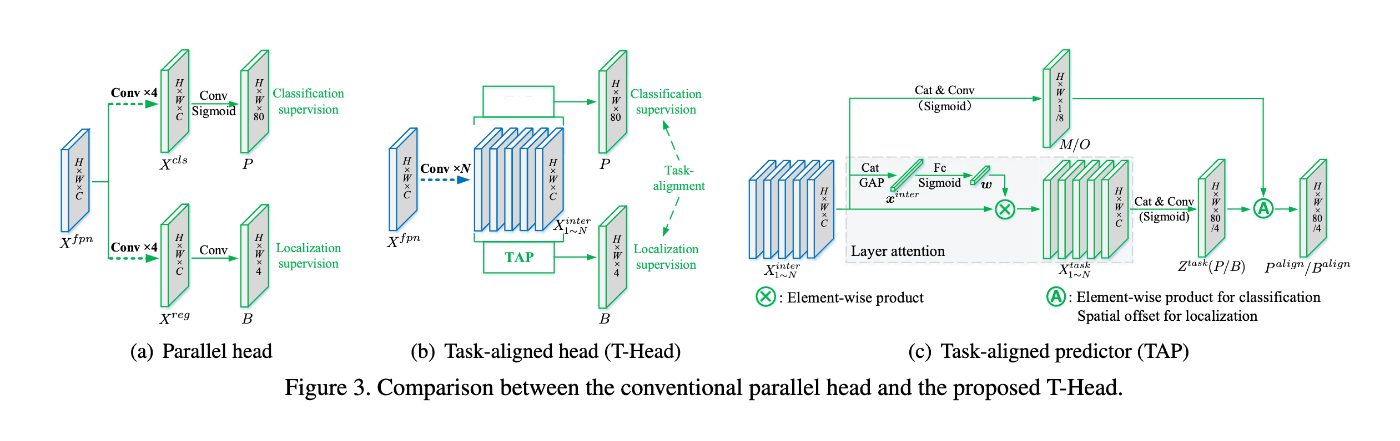
図. TOODのアーキテクチャ。[6]より抜粋。
headのアーキテクチャ変更に加え、boxの評価値をlossの重みづけとして用いる。boxの評価値は以下のようなヒューリスティックで決定する。
実際に使用する評価メトリクスは以下のように正規化している(論文によれば、
損失関数は以下のようになる。
classの回帰にQFLを用いているほか、boxのlocalityの回帰にboxの評価値によって重みづけを加えている(著者らによれば、このようにすることで質の高いboxの影響を大きくすることを意図したらしい)。
なお、QFLの論文ではNMSにおけるboxの評価値を最適化することが目標だったが、TOODではlabel assignmentでのboxの評価値を最適化することに用いている。
論文中のCOCO APによる評価結果では、QFL単体で0.9, headのアーキテクチャ変更で1.9、両者を共に用いることで2.3のゲインが得られたと報告している。
実用的なモデルにおけるdynamic label assignmentの採用実績について
本節では実用よりのモデルにおけるdynamic label assignmentの採用実績について説明する。「実用的」かどうかの基準は主観的にはなるが、大まかな区分けとしては、特定の要素技術の効果を明らかにするための研究用のモデルというよりは、最新の研究成果を積極的に取り込んだ、down-stream taskでの利用を前提としたモデルを想定している(例えば、ultralytics/ultralytics [10]など)。
YOLOX[5]では、OTA[3]を擬似的に再現したより計算機コストの小さいSimOTAと呼ばれるアルゴリズムによってOTAと同等の結果を得ることができたと報告している。SimOTAでは最適輸送問題を扱わずに、GT
また、RTMDet[8]ではYOLOXのSimOTAアルゴリズムにGTと予測boxの中心点同士の距離を推定したcenterness評価値を合わせたloss関数を用いている。
PP-YOLOE[11]およびYOLOv8[10]では、TOODで使われたTAL[6]において、QFLをVFLとDFL[2]に置き換えたlossを用いている。
DFLはboxの回帰において確率モデルを導入した損失である。モデルはboxの位置情報(top, left, right, bottom)のそれぞれについての確率分布
まとめ
本稿では、object detectionタスクにおけるlabel assignment関連の最近(2019年以降)の研究成果について、以下の内容を説明した。
- anchor boxとprediction boxを共にlabel assignmentで利用する手法[7]
- class予測の評価値とlocalityの評価値を組み合わせたboxの評価手法、およびそれをpostprocessやlabel assignmentに利用する手法
- IoU評価値をclass予測タスクのソフトラベルとして用いる[2, 4, 6]
- class予測タスクとbox回帰タスクをアーキテクチャレベルで協調して学習する[6]
- 実用的なモデルにおけるdynamic assignment手法の採用実績について[5, 8, 10, 11]
Reference
- [1] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection, Jun 2020
- [2] Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection, Jun 2020
- [3] OTA: Optimal Transport Assignment for Object Detection, Mar 2021
- [4] VarifocalNet: An IoU-aware Dense Object Detector, Mar 2021
- [5] YOLOX: Exceeding YOLO Series in 2021, Aug 2021
- [6] TOOD: Task-aligned One-stage Object Detection, Aug 2021
- [7] Dynamic Label Assignment for Object Detection by Combining Predicted IoUs and Anchor IoUs, Jul 2022
- [8] RTMDet: An Empirical Study of Designing Real-Time Object Detectors, Dec 2022
- [9] Squeeze-and-Excitation Networks, May 2019
- [10] https://github.com/ultralytics/ultralytics
- [11] PP-YOLOE: An evolved version of YOLO, Mar 2022
- [12] Deformable Convolutional Networks, Jun 2017
Discussion