Object Detectionタスクにおけるlabel assignmentについて
概要
ニューラルネットワークによるobject detectionモデルにはこれまでanchor-based手法とanchor-free手法がともに発展してきた。ところが、近年、anchor-basedかanchor-freeかどうかの差異はあまり重要でなく、むしろanchor boxに対して正例、負例を割り当てる問題、つまり、label assignmentの問題の方がより重要ではないか?という問題提起がなされた[3]。
本稿では比較的近年(2019年以降)に提案されたlabel assignmentについていくつかピックアップして概観する。
前半では[3]で議論されたanchor-based手法とanchor-free手法の本質的な違いとlabel assignmentの概要について説明し、後半では近年(2019年以降)に提示された手法を紹介する。
anchor-based手法とanchor-free手法には本質的な違いについて
本節ではlabel assignmentが重要であるという認識を強調した[3]の意義を理解するために、anchor-based/anchor-free手法の両者の概要とこれらの手法の本質的な差異について概観する。
ニューラルネットワークによるObject detectionモデル(本稿では主にone stageのモデルを想定する)には歴史的にanchor-basedと呼ばれる手法が用いられてきた(YOLO, RetinaNet, etc.)。
anchor-based手法の基本的なアイデアは入力画像のfeature mapを1/n x 1/nの区画に分割し、1/n x 1/nの区画のうち、GT boxとのIoUがある閾値を上回ったものを正例としてマークし、その中央の点(anchorと呼ぶ)のembeddingを元に、GT boxとあらかじめ決められたいくつかのbox(anchor boxと呼ぶ)との相対位置を回帰するというものである。
この手法は経験的に良い性能を示したものの、anchor boxのサイズとアスペクト比、正例、負例を決定するためのGTとanchorのIoU thresholdなど、ヒューリスティックに決定しなければならないハイパーパラメータが多いという面倒さがある。
これに対し、anchor-freeと呼ばれる一連の手法が提示されてきた。この系列の手法の基本コンセプトは、anchor-based手法でヒューリスティックに決めてきたハイパーパラメータを自動的に決めようというものである。
なお、anchor-free手法もboxの回帰を行う元となるembeddingが存在するので、「anchor-free」という表現は矛盾を含んでいる。両者を統一的に理解する上で理解の妨げとなるので、本稿ではanchor-free手法においても回帰の元となるembeddingを「anchor」と呼ぶことにする。
また、これも逆説的だが、anchor-free手法においても結局ヒューリスティックな決め事やhyper parameterが存在するので、anchor-based手法とanchor-free手法を明確に区別する点は、「1つのanchorに対して複数の回帰boxを割り当てるか、単一の回帰boxしか割り当てないか?」という点となる。
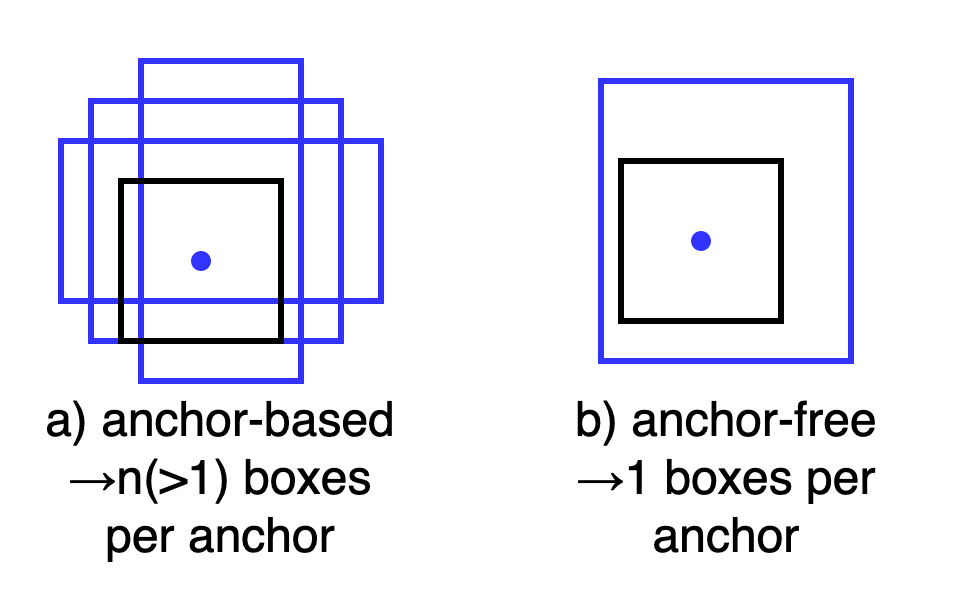
図1. anchor-based手法とanchor-free手法の本質的な差異はanchorあたりに複数のboxを割り当てるか、単一のboxを割り当てるかの違いに帰着する。
さらに、[3]ではanchor-based手法のRetinaNetと、そのanchor-free手法への拡張であるFCOSというモデルの差異のうち、性能に与える寄与が何かをを厳密に比較した。その結果、「性能的な違いを生み出しているのは、anchorや回帰ラベルの定義の仕方ではなく、予測boxを正例・負例に分割する方法、すなわちlabel assignmentである」ということを示した。この結果は具体的な2つのモデルについてのみ成り立つ内容であり、あらゆるanchor-based手法とanchor-free手法に対して一般的に成り立つ内容ではないが、label assignmentがobject detectionモデルの性能に与える寄与が無視できないということを印象づける結果である。
label assignmentとは?
本節はobject detectionタスクにおけるlabel assignmentの概要を説明する。
Object detectionタスクの特徴は、ラベルのオブジェクトの位置とクラスに対応するboxの"集合"を予測するという点にある。
集合は順序の概念を持たないので、SGDなどの勾配ベースの最適化手法で回帰するためにはGT boxとモデルが予測するboxの対応づけが必要となる。
そこで、object detectionタスクでは一般的に予測boxを以下の3つに分類する:
- positive(正例): ラベルのクラスのいずれかに対応するbox。これらのサンプルはクラスラベルとboxの位置の回帰の対象となる。
- negative(負例): ラベルのどのクラスと対応しないbox。(
\varnothing - ignore: 正例とも負例ともみなさないbox。これらのサンプルはクラスラベルとbox位置回帰の対象からともに除外される。
3番目のignoreは定義されないこともある。本稿では簡単のためignoreクラスについてはこれ以上触れない。

図2. IoU thresholdによるlabel assignmentの例。
このように、sigle stageのobject detectionモデルは内部的には
- 候補boxの抽出
- 候補boxへの正例、負例ラベルの割り当て(label assignment)
- boxのパラメータ(サイズ、位置、クラス)の回帰
という3 Stepの処理を行っている。特に、label assignmentは回帰のためのラベルを動的に生成する処理とみなすことができる。一般的に機械学習においてlabelの良し悪しはモデルの学習効率を左右するので、このSTEPが重要であることは直感的に理解できる。
近年提案されたlabel assignment手法の概観
本節では近年(2019年以降)に提案されたlabel assignment手法のうちいくつかをピックアップする。
- RetinaNet[1]: 異なる解像度のfeature mapに対し、1/n x 1/nの格子に分割し、1/n x 1 / nの格子とGt boxのIoUが閾値を上回るものを正例とみなす。
- FCOS[2]: 異なる解像度のfeature mapに対し、1/n x 1/nの格子に分割し、中心点がGT boxの内部に含まれ、かつ回帰boxのスケールレンジがある区間に収まるものを正例とする。
- ATSS[3]: GT近隣のboxの集合についてモデルの予測スコアの平均(
\mu \sigma \text{threshold} := \mu + \sigma - PAA[4]: GT box周辺のboxのscoreの分布をGMM(Gaussian Mixture Model)で回帰し、GMMモデルが予測する正例と負例の確率を元に閾値を動的に計算する。
- OTA[5]: GT boxがk個の予測boxに対応するとし、最適輸送問題により最適なassignmentを計算する。
- YOLO-F[6]: GTと重なる予測boxのうち、予測スコアのtop-Kを正例とみなす。
以下の小節ではこれらの手法の詳細について説明する。
固定のIoU thresholdを用いる(RetinaNet)
[1]のlabel assignmentは異なる階層のfeature mapに位置するanchorを、それぞれ異なるサイズのGT boxの回帰に特化させることを意図している。
固定のthresholdによるlabel assignmentの問題点は、特にIoU thresholdが大きな値に設定した場合、主に学習の初期段階において、GT近傍の全てのboxのスコアが閾値を下回る場合、正例のboxが存在しないのでこれらのboxについては学習が全く進まないという点がある。
モデルの回帰したboxサイズから動的に閾値を決定する(FCOS)
[2]のlabel assignmentにおけるスケールレンジも[1]と同様に、異なるfeature mapをそれぞれ異なるサイズレンジのboxの予測に対応させる手法である。ただし、スケールレンジの決定には1/n x 1/nの格子のサイズを元に固定で決めるのでなく、モデルが予測するboxのサイズを元に動的に決定する。[3]によればこちらのlabel assignmentの方が1と比べてMS COCO APによる評価で0.8-0.9%ほどのゲインがあったことが示されている。
スケールレンジはfeature mapごとに固定で決めており、これらの区間の境界の値がハイパーパラメータとなる。
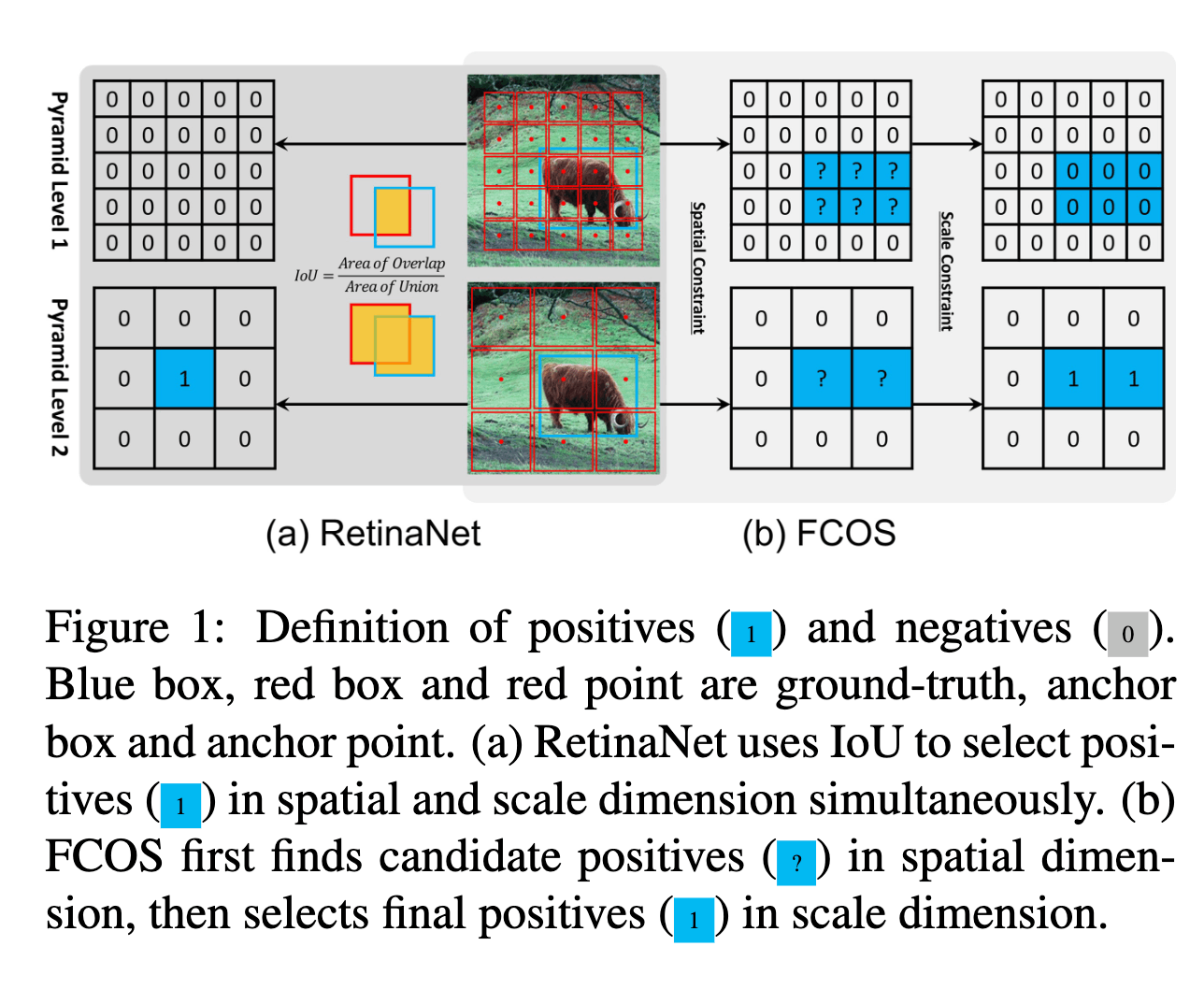
図3. RetinaNetとFCOSのlabel assignmentの違いについて([3]より抜粋)
GT周辺のBoxの分布から相対的に閾値を決定する(ATSS)
[3]では固定の閾値の代わりに、GT box周辺のboxのスコアの分布を元に相対的に決定する。
分布が正規分布に従うと仮定すると、理論的には
統計モデル(GMM)によるIoU thresholdの動的な推定(PAA)
[4]は[3]でヒューリスティックに決めた閾値の判別ルールを統計モデルに基づいて理論的に決めようというもの。GT box周辺の予測boxのスコアの分布をそれぞれ正例、負例に対応する2峰のGMMにより回帰し、正例、負例の予測分布に基づき閾値を動的に決定する。
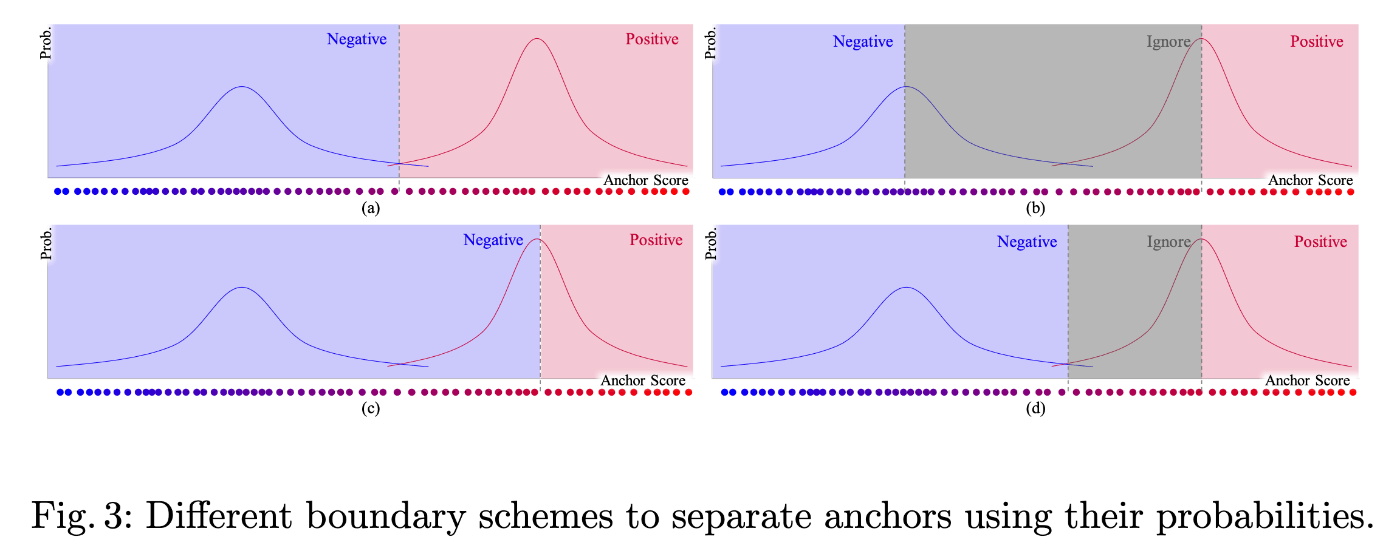
図4. [4]における閾値決定手法のパターンについて([4]より抜粋)
label assignmentを最適輸送問題として解く(OTA)
[5]は予測boxのlabel assignmentを最適輸送問題(Optimal Transport Problem)として定義して解くというもの。[2]では同じboxに対して複数のGTが対応する場合、「最も面積が小さいGTと対応する」というヒューリスティックにより決定していたが、こちらの手法ではモデルの予測するboxの位置とclass予測の正確性に基づいて動的に決定することができる。また、ablation studyの結果でもこちらの手法の方が「曖昧なラベル」の影響が小さいことが示されている。
本手法のデメリットは計算コストで、計算コストが20%程度増加したと報告している。
Uniformed samplingによりboxの大きさごとの正例サンプル数の不均衡を是正する(YOLO-F)
[6]では[1]の手法において、GT boxのサイズごとに正例、負例の分布が大きく偏りがあることに着目する。具体的にはGT周辺のk-近傍のanchorおよびGT boxを正例とみなすことで異なるサイズのGT boxごとの正例、負例の分布の不均衡を是正することで性能改善を実現した。
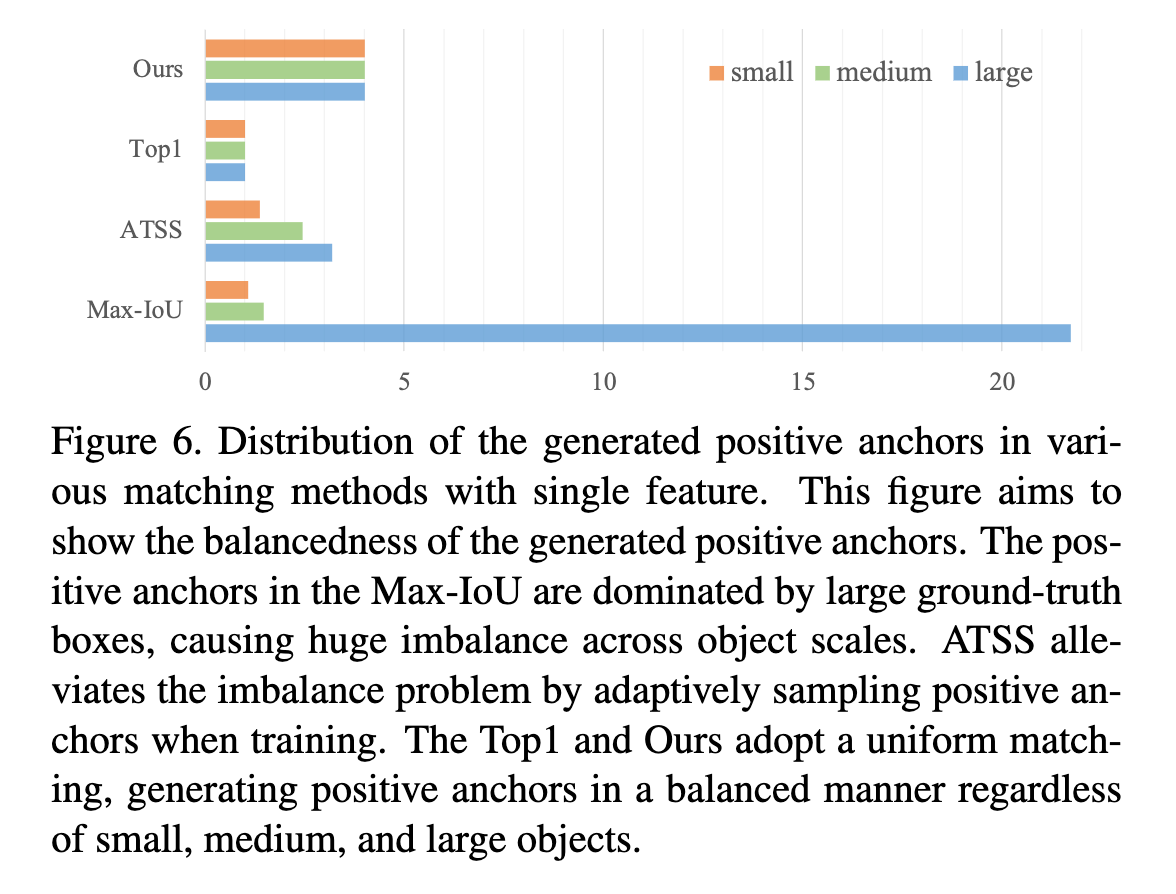
図5. GT boxのサイズごとの正例クラスの分布([6]より抜粋)
まとめ
本稿ではobject detectionタスクのlabel assignmentの概要と近年(2019年以降)に提案されたassignment手法について説明した。
本項で説明した内容を以下にまとめる。
- anchor-based手法とanchor-free手法の違いは1つのanchorに複数のboxを割り当てるか、単一のboxを割り当てるかの違いでしかない。
- [3]によれば、anchor-based手法のRetinaNetと、anchor-free手法のFCOSを他の条件を同じにして比較した場合、性能に大きく寄与するのはanchorあたりいくつのboxを割り当てるか?ではなく、label assignmentの差異だった。
- 固定のIoU thresholdによるlabel assignmentをベースラインとした場合、thresholdをモデルの予測スコアの分布(ATSS, APP, YOLO-F)やGTとのloss(OTA)に基づいて動的に割り当てることにより性能改善を報告したとする手法がいくつかある。つまり、label assignment手法の改善はobject detectionモデルの性能改善に寄与しうる。
Reference
- [1] Focal Loss for Dense Object Detection
- [2] FCOS: Fully Convolutional One-Stage Object Detection
- [3] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
- [4] Probabilistic Anchor Assignment with IoU Prediction for Object Detection
- [5] OTA: Optimal Transport Assignment for Object Detection
- [6] You Only Look One-level Feature
Discussion