ModernBERTに学ぶモダンなBERTの学習レシピ
本記事はModernBERT[1]で採用された「モダンな」BERTの学習に関する技術についてまとめたものです。
調査した論文: Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference, Dec 2024
- 論文中に明記されていない情報は参考文献やソースコードの内容を元に記載(ソースコードの該当箇所はAppendix C参照)。
- また、今回未調査だが個人的に気になった技術のリストはAppendix D参照。
ModernBERTとは?
- 2018年のBERTのリリース以降、業界の興味がLLMに集中していく中でBERTと同規模の小さいパラメータのTransformerについては長らく記録更新がされてこなかった。
- 6年越しに最新のLLMの学習に使われる技術を使ってBERTを「モダン化」させた
(source: Finally, a Replacement for BERT[2])
採用された技術
網羅的に列挙しても仕方ないので、個人的に気になったものをピックアップして説明します。
1. 学習手法のモダン化
WSD(Warmup-Stable-Decay)の採用
- 学習率のスケジュールにWSD(Warmup-Stable-Decay)[5]を採用。
- Stableフェーズでは学習率が一定なので、Decayフェーズ直前のcheckpointから学習を簡単にやり直す(rollback)ことができる。
- Rollback: largeモデルの学習では長時間学習させているとlossが減らなくなったので最後の800B token 分の学習をやり直した。lrとweight decayを下げて学習を継続させるとlossが再び下がり始めた→WSDで長時間学習して生じた問題に対処した事例として参考になる。

(source: Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations[5])
2. 処理効率の改善
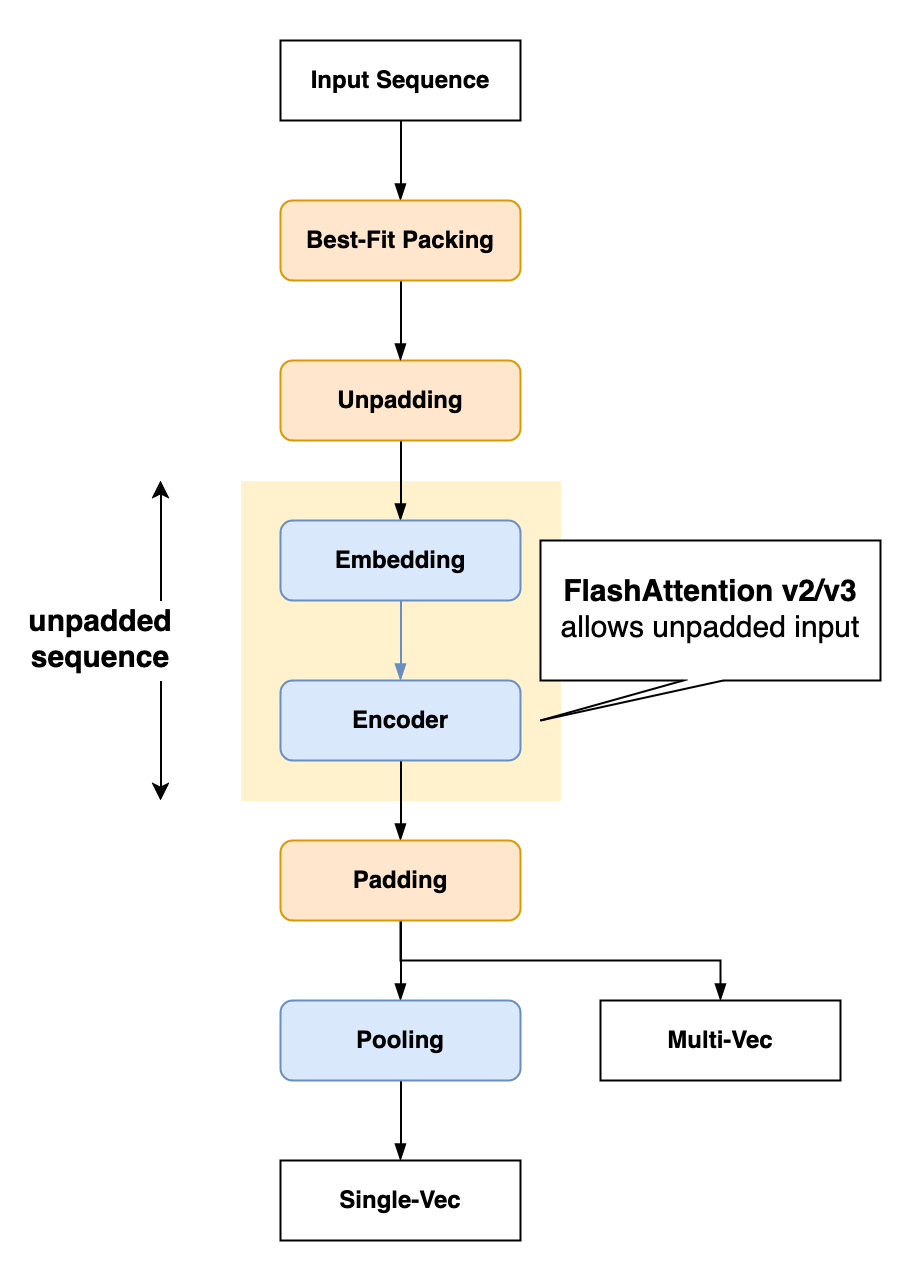
Unpadding
- 課題: ナイーブに最大長でpaddingするとpad tokenに関わる計算にかなりのコストがかかる(例: Wikipediaのテキストの場合約50%)
- 解決方法: pad tokenを除去してsequenceを連結し、pad token分の計算を省略する。
- 学習/推論時の両方に適用→学習と推論効率を同時に向上
具体的な実装方法
- Embedding, LayerNorm, Linear: pad tokenを除外しても処理結果は影響を受けない。
-
MultiHeadAttention: FlashAttention v2 の可変長入力に対応したAttentionを使う(
flash_attn_varlen_func)
(source: bilzard)
過去記事も参照。
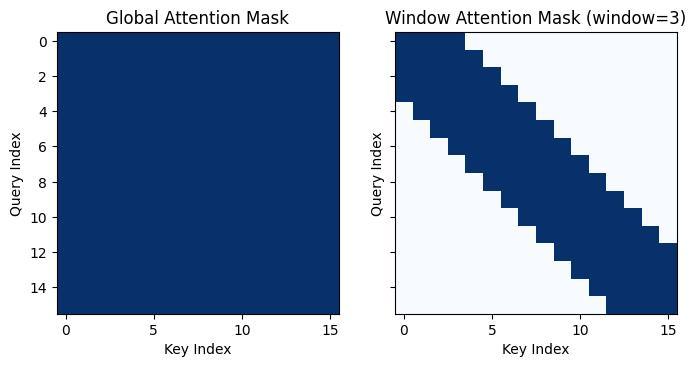
Window Attention
- Attentionの有効範囲を局所化することでAttentionの計算量を省略する。
- Global AttentionとShifted-Window Local Attentionを交互に配置(SwinTransformerなど画像用のTransformerでよく見るアーキテクチャ)
- 具体的には、3ブロックおきにGlobal Attentionを配置。それ以外はLocal Attention(window=128)に。
- Window Attentionによる計算量の削減効果: コンテクスト長=8192、window size=128の場合、Attentionの計算量の割合は1/3 + 2/3* (128/8192) = 0.34→Attentionの計算量の66%を削減
(source: bilzard)
CUDAに最適化したモデルのパラメータ設計
CUDAが動作する仕組みを考慮してモデルのパラメータを設計するのとしないのとでは処理効率に無視できない差が出ることが知られている。例えば、GPT3のアーキテクチャでMHAのheadの次元を64の倍数にするだけで全体の20%スループットが向上するという報告がある[4]。詳細は過去記事やAppendix A参照。
3. その他の特筆すべき技術
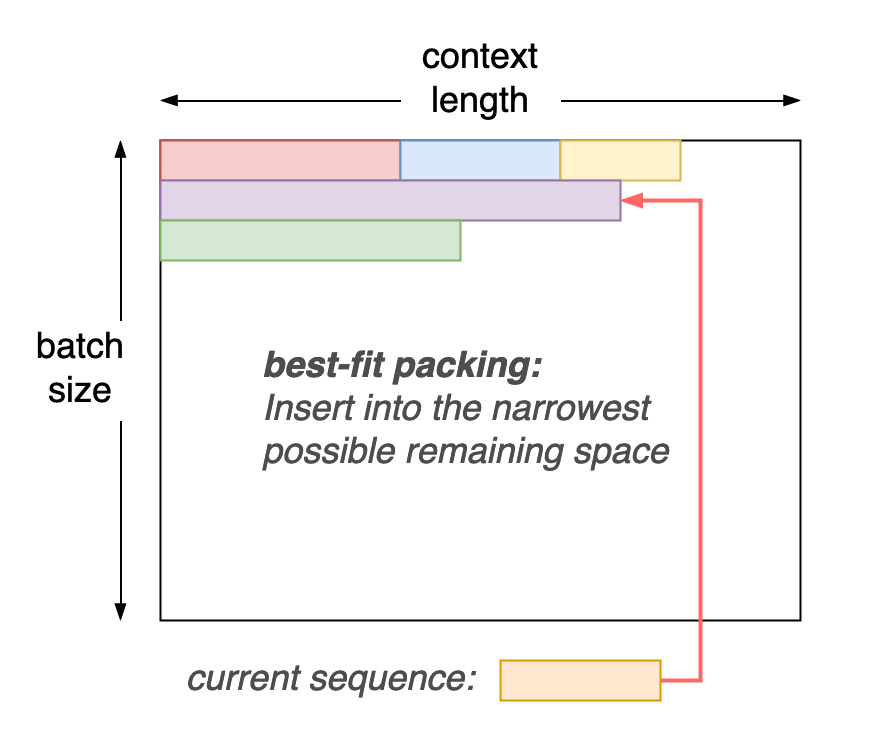
best-fit packing
- 課題: ナイーブにサンプリングするとGPUごとに割り当てられるmicrobatch中のtoken数が偏る→token数が少ないmicrobatchが割り当てられたGPUでidleが発生する
- 解決方法: best-fit packing - microbatch中の各行のtoken数を均一にするgreedyなアルゴリズム。トークン列を順に走査していき、「現時点で収めることが可能な最も狭い隙間」に挿入する。
(source: bilzard)
batch sizeのスケジューリング
- 課題: バッチサイズが大きい場合、入力token数に対するweightの更新頻度が遅くなるため、特に学習の初期段階における学習効率が悪い
-
解決方法: バッチサイズを50B tokenにわたりゆっくりと線形にwarmupする。
- Modern-BERT-base: 768→4,608
- Modern-BERT-large: 448→4,928
Weight Tiling
- 課題: モデルのパラメータ数をスケールするさい、毎回ゼロから学習せずに、小規模の学習ずみモデルの重みを有効活用したい
-
解決方法: Gopher[3]で採用されたアプローチをベースにした:
- weight matrixの次元拡張: top-left tiling + wraparound の代わりに center tiling + wraparound を採用
- layer方向の拡張: 中間のlayerの重みを前後のlayerの重みで線形補完

(source: Scaling Language Models: Methods, Analysis & Insights from Training Gopher[3])
4. 試行錯誤での知見
PyTorchのRandomSamplerのバグ
- Baseモデルの事前学習時、緩やかなジグサグを描きながらlossが発散していく問題があった。
-
原因: PyTorchのRandomSamplerに問題があり、500M~1B sampleのどこかのサンプルに偏っていた(Olmoでも同様のことを報告)→Numpyの
PCG64DXSMrandom samplerを用いた
実験設定
1. 性能評価
各種retrievalタスクのデータセットを使用してfine-tuningを実施し、各種ベンチマークで既存手法と NDCG@10 を比較。
Vector Representation:
- Single-Vector: text embeddingを全tokenで集約して1つのtext embeddingを計算する
- Multi-Vector: text中の各tokenのembeddingを全て保持する。Similarityの計算方法はAppendix Bを参照。
2. 処理効率
ランダムに生成したトークン列を入力して推論時のスループットを計測。
- Fixed Token Length (Short): 512 tokens
- Fixed Token Length (Long): 8192 tokens
- Variable Token Length (Short/Long): 中心がそれぞれ 256/4096 tokens の正規分布
variable lengthの設定の方が現実の設定に近い。まば、batch中のpadding tokenの割合がfixed lengthに比べて大きいので、unpaddingの効果が強調される。
実験結果
1. 性能評価
1-a. Short Text Retrieval / Natural Language Understanding
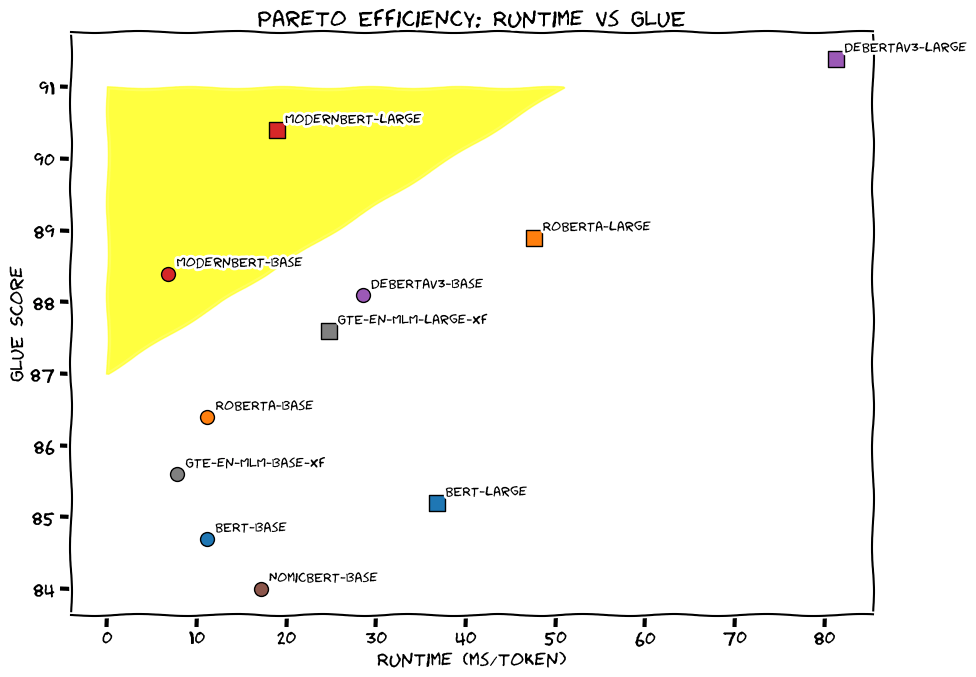
- 自然言語理解タスク(GLUE)ではRoBERTa-V3にやや劣るが悪くないパフォーマンス
- Retrievalタスク(BEIR)ではパラメータ数が同規模のモデルを押さえてトップの性能

(source: bilzard)
1-b. Long Text Retrieval
- long text retrieval(MLDR)タスクではSingle-VecでTopのGTE-en-MLMと同程度の性能。Multi-Vecではトップ。
- Code retrieval(CodeSearchNet/StackQA)ではいずれもトップ
- →おそらく学習データ中にコーディングのデータセットが含まれるため

(source: bilzard)
2. 処理効率
2-a. Short Textのスループット
- GTE-en-MLMと同程度→unpaddingの効果

(source: bilzard)
2-b. Long Textのスループット
- GTE-en-MLMより2.0~2.6倍スループットが高い→Window Attentionの効果

(source: bilzard)
参考: モデルの学習コスト
以下は論文のTable 3を元にモデルの学習にかかった費用を試算したもの。
-
ModernBERT-base: 425 hour x 14.404 USD/hour = 2,794 USD (0.42MJPY) -
ModernBERT-large: 194 hour x 14.404 USD/hour = 6,121 USD (0.93 MJPY)
合計: 約 8,916 USD (1.35 MJPY)。
費用シミュレーションの仮定:
- レートは 152 JPY/USD で計算
- GPUのランニングコストはvast.aiの8 x H100 SXMインスタンスの最低価格を元に計算(14.404 USD/hour)
Reference
- [1] Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference, Dec 2024, https://arxiv.org/abs/2412.13663
- [2] Finally, a Replacement for BERT, https://huggingface.co/blog/modernbert
- [3] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Dec 2021, https://arxiv.org/abs/2112.11446
- [4] The Case for Co-Designing Model Architectures with Hardware, Jan 2024, https://arxiv.org/abs/2401.14489
- [5] Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations, Oct 2024, https://arxiv.org/abs/2405.18392
- [6] ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT, Jun 2020, https://arxiv.org/abs/2004.12832
- [7] GLU Variants Improve Transformer, Feb 2020, https://arxiv.org/abs/2002.05202
- [8] OLMo: Accelerating the Science of Language Models, Feb 2024, https://arxiv.org/abs/2402.00838
- [9] Stable and low-precision training for large-scale vision-language models, Oct 2023, https://arxiv.org/abs/2304.13013
- [10] Data Engineering for Scaling Language Models to 128K Context, Feb 2024, https://arxiv.org/abs/2402.10171
- [11] How to Train Long-Context Language Models (Effectively), Oct 2024, https://arxiv.org/abs/2410.02660
Appendix
A. CUDAに最適化したパラメータ設定
推奨設定: float16/bfloat16の場合
- Tensor Core Reruirement: weight matrixの次元を64で割り切れること
- Tile Quantization: weight matrixは128x256で割り切れること
- Wave Quantization: blocks数がSM(Streaming Multiprocessor)の数で割り切れること
Wave Quantizationの要件は使うGPUのSM数に依存するが、典型的なGPUで「block数/#SM」を計算してヒューリスティックに決めた。
B. Multi-VecでのSimilarityの計算方法
ColBERT[6]におけるSimilarytyの計算方法に従った。
- 各tokenごとのquery embeddingについて、全てのdocument token embeddingとのsimilarityを計算し、その最大値で集約する(MaxSim演算)
- 1で計算したsimilarityについて、全てのquery tokenで和をとる
上記の計算方法は、tokenごとの情報の集約が最後に来るので、late interactionと呼ぶ。これに対し、tokenごとのembeddingを最初に集約する手法はearly interactionと呼ぶ。後者がtokenが長くなっても同じ次元のベクトルに情報を詰め込もうとするのに対し、前者はtokenごとのベクトル表現を保持するため、情報損失が小さい。一方で、前者は全てのtokenについてembedding vectorを保持する必要があるため、storage/memoryをより多く消費する。

(source: ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT[6])
C. ソースコードの該当箇所
- batch size scheduling:
- best-fit sampling:
- unpadding:
- 可変長入力に対応したattention:
D. 今回未調査だが個人的に気になる技術のリスト
-
Activation: GeGLU [7]
- GLUの変種の中では一貫して性能が良いと報告[7]
-
Tokenizer: BERT tokenizer -> modified version of Olmo[8] Tokenizer (BPE)
- better token efficiency & performance on code-related tasks
- preserve same special tokens (
[CLS],[SEP], etc.) for backward compatibilty to original BERT model - vocabulary=50,368 -> set multiple of 64 for better GPU utilization
-
Optimizer: StableAdamW[9]
- add Adafactor-style update clipping as a per-parameter LR adjustment
- outperfomed standard gradient clipping on downstream tasks & more stable training
-
Context Length Extention
- extend context length: 1024 -> 8192
- increasing RoPE theta to 160K & train additional 300B tokens
- Stable: constant LR=3e-4 for 250B tokens on an 8192 token mixture of the original pretraining dataset sampled following[10]
- Decay: upsample higher-quality sources following[11] & conduct decay phase (1-sqrt) over 50B tokens
Discussion