🦁
Unpadding: padding tokenの除外によるBERTの訓練コストの削減
本記事は以下の論文のまとめ記事です。ModernBert[3]でunpaddingという処理が採用されていたので調べてみました。
paper: Boosting Distributed Training Performance of the Unpadded BERT Model, Aug 2022
注意: 本記事で引用した図の著作権は全て著者らに帰属します。
Summary
- BERTの学習コストのかなりの割合はpadding tokenの計算に割かれている
- pading token以外の有効なtokenの計算に集中することでスループット向上につながる
- unpadding処理を適用し、BERTモデルの学習で2.3xのスループット向上を実現
背景
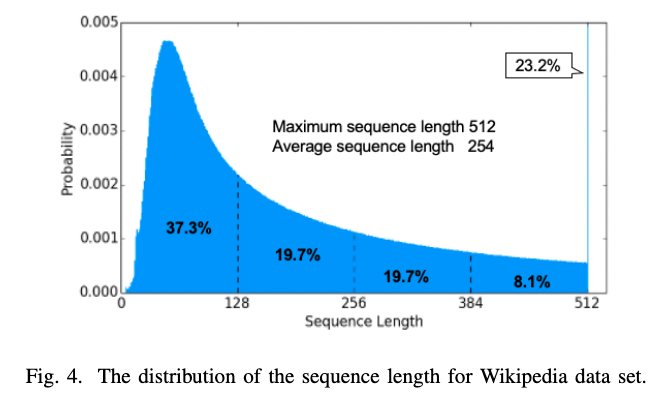
- token長を固定でBERTを学習した場合、batch中のpadding tokenの割合は意外と多い(参考: Wikipedia datasetの場合、約50%)
- →padding token以外の意味のあるtokenのみに計算資源を使えばスループットが向上する。
手法
改善の方針
- Unpaddingを明示的に行うBlock: Embedding, Linear, LayerNorm, Addなどはbatchの次元とtokenの次元を混ぜても影響を受けない → unpadding(後述)の適用
- FlashAttentionの利用: FlashAttention内でpad tokenが最小限のみ付加されるようにデータの渡し方を最適化
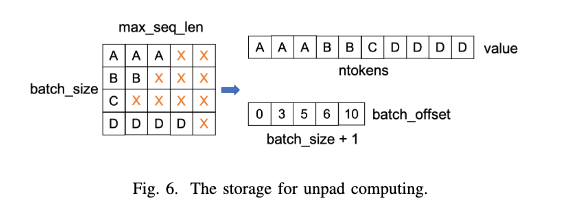
Unpadding
- unpadding: pad tokenを全部除外して1つの大きなsequenceとして処理する
Grouping: FlashAttentionでのpad tokenの処理を最小限にする
- tokenサイズが似たsequenceどうしをグループ化→padding tokenが最小限ですむ
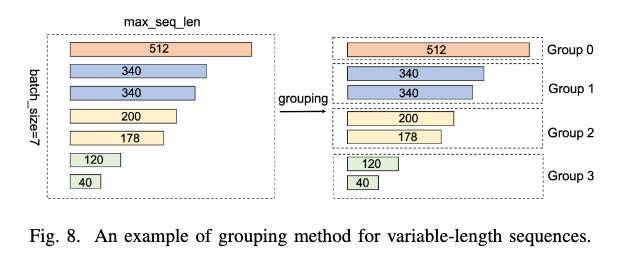
- 各Groupの計算は独立しているので並列処理が可能

技術的課題: GPU間でのLoad Balancing
- unpaddingによりbatchごとにトークン数が異なる→GPU間で負荷の不均衡が生じる
- 具体的には、より短いtokenしか含まないGPUでは処理が早く終わり、より長いtokenのGPUの処理の完了を待たないといけないので、この間GPUのidle時間が生じる

exchange padding
- GPU間での負荷を分散するため、PublicベンチマークMLPerf Training v1.0でNVIDIAが提出したコードにはexhange paddingと呼ばれるgreedyな負荷分散アルゴリズムが実装されている[2]。
- 論文ではこの処理をCPUにオフロードすることでさらにスループットを向上する手法を提案している(Appendix A)

Experimental Result
各改善手法のPerformanceへの寄与
- unpaddingの導入でbaselineから2.3xスループットが向上した

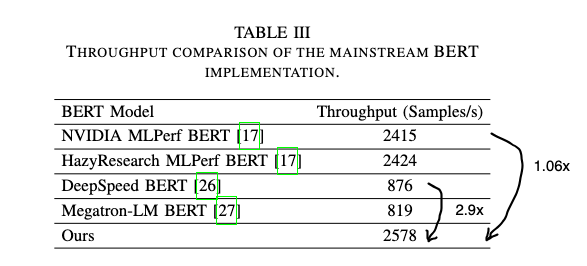
End-to-End Performance
- DeepSpeed/Megatron-LMと比較して2.9xの高速化(kernel fusionなどunpadding以外の影響も含む)
- MLPerf v2.0でNVIDIAが提出したベンチマーク結果と比較して1.06xの高速化
まとめ
- unpaddingによりBERTのモデルの学習コストを2.3倍に高速化できる
- unpaddingにより、GPU間でのloadの不均衡が新たに課題になってくる
- GPU間での負荷分散対策として、GPUごとにbatch中の有効トークン長をバランスする実装がある(exchange padding)
Reference
- [1] Boosting Distributed Training Performance of the Unpadded BERT Model, https://arxiv.org/abs/2208.08124
- [2] exchange padding, Nvidia's submissison in MLPerf training v1.0, https://github.com/mlcommons/training_results_v1.0/blob/master/NVIDIA/benchmarks/bert/implementations/pytorch/run_pretraining.py#L888
- [3] Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference, https://arxiv.org/abs/2412.13663
Appendix
A. exchange paddingのCPU offload
NVIDIAのexchange paddingの実装には以下の課題がある。
- 全ての処理をGPUで処理している。All Gather→sortの処理がserialであり、他のGPUでidleが生じる。
- CPUの処理がほぼidleになっている
これを解決するために、論文ではexchage paddingの処理をCPUにoffloadする手法を提案している。

Discussion