LLMの推論では外れ値は重要な役割を果たす
本記事はTransformerの8bit行列演算を実装した以下の論文のまとめ記事です。推論フェーズでは4bitの量子化が主流の現在において、8bitの量子化手法はメリットが薄れた感がありますが、outlierとLLMの推論性能の関係についての考察とoutlierとそれ以外を分けて計算するアプローチが面白かったので取り上げました。
なお、著者らが実装したコードは現在でもbitsandbytes[6]という名前でGitHubでメンテされHuggingFaceのエコシステムに組み込まれています。本記事ではソースコードの実装箇所に関して調査した結果についてもAppendix Aに掲載しています。
paper: LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale, Nov 2022
Overview
- Transformerの推論には膨大なVRAMを消費する→行列計算を量子化することでVRAMの最低要件を減らせないか?(🪓)
- outlier以外を8bit、outlierを16bitの混合精度で推論することで175Bまで性能劣化させずに量子化推論を実現(🏹)
- tokenごと、レイヤごとのoutlierの分布の解析により、層の深いLLMほどoutlierの絶対値、頻度ともに増加する傾向が確認できた。これは特定のモデルアーキテクチャや訓練方法によらない一般的な傾向である。
- また、outlierの生じた次元の重みを0で埋めるとTransformerの性能は著しく低下した→outlierがTransformerの推論性能に重要な役割を果たしている可能性
背景
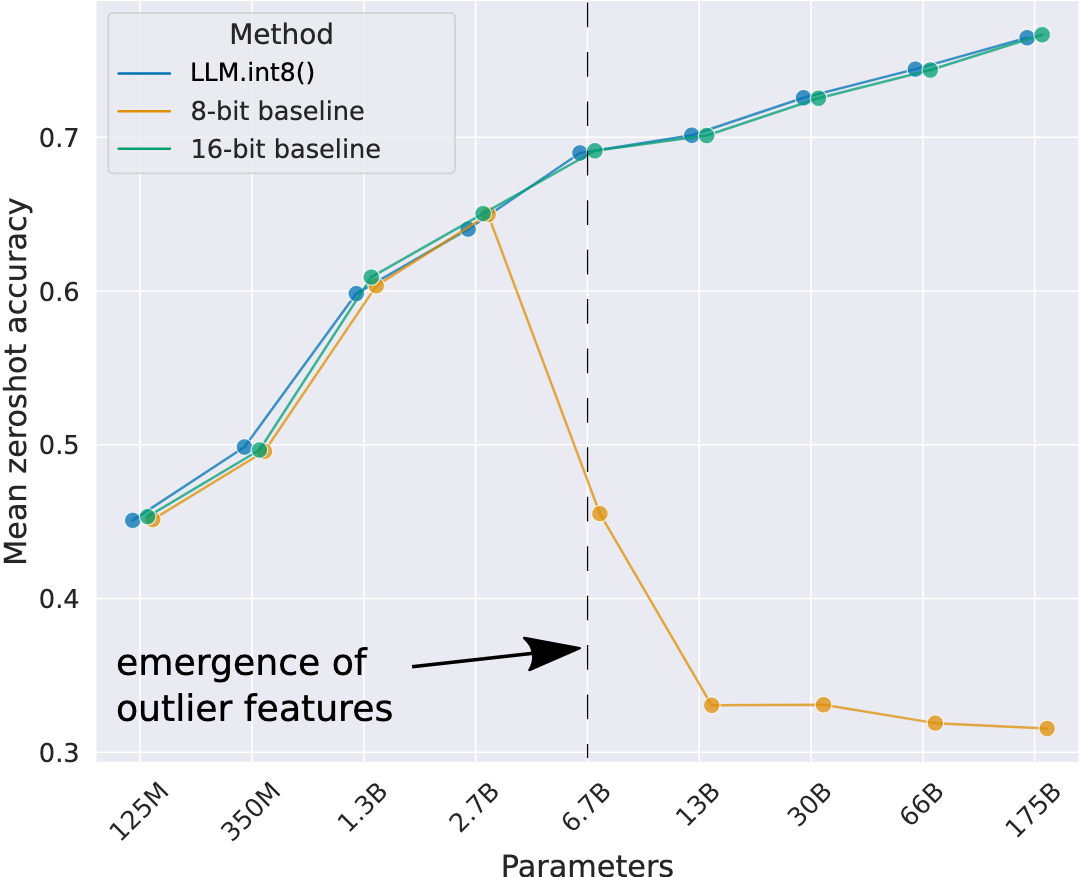
- OPTモデルの行列演算をvector-wiseに8bit量子化してzero-shotの性能を確認したところ、2.7Bまでは性能劣化しなかったが、6.7B以降は性能が急激に劣化した
- →量子化推論におけるモデルの性能劣化の原因は?
(source: [1])
outlierは極めて"系統的"に出現する
モデルの各次元のアクティベーションの大きさを1) tokenごと、2) 層ごとに追跡すると、6.7Bスケールでは、わずか0.1%の次元に集中してoutlierが現れる(🗡️)。これらのoutlierの特徴の次元を0で埋めて無効化すると、softmaxのtop-1確率は20%以上減少し、validationのperplexityは600-1000%増加する。
仮説: これらの0.1%のoutlierを適切に扱えていないことがTransfromerの量子化推論の性能劣化の原因である
手法
outlierを独立して計算する
-
解決方法(decomposition): 99.9%のoutlier以外と、0.1%のoutlierを独立して計算する
- 行列計算にて入力の次元の分布でoutlierを分離。対応するモデルの重みの次元も分離する
- outlierの精度は16bitとすることで桁落ち、overflowを防ぐ

(source: [1])
Zeropoint Quantization
- 課題: absmaxだと[-127, 127]の範囲を全て利用できない(例: ReLUの出力は[-127, 0)を無駄にしている)
- 解決方法: biasパラメータを保持してmin-max normalizationを適用する(🪓)
例) zeropoint quantizationの量子化アルゴリズム:
Result
- C4評価セットのperplexityで評価。提案手法により13Bまでのモデルで性能劣化を免れた
- 最も性能劣化の回復に寄与してそうなのはdecomposition(outlierとそれ以外の分解)

(source: [1])
INT8演算による速度改善
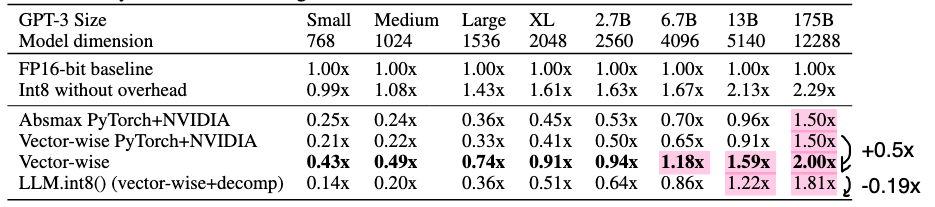
最初のFF層における行列計算の速度を比較した(中間の次元はモデルの次元の4倍)。
- 行列サイズが小さい場合はFloat16->INT8への変換で逆に行列積の計算は遅くなる(quantize/dequantizeのオーバーヘッドのため?)
- 8bit演算の恩恵を受けられるのは13B〜(🪓🤩✍️)。
(source: [1])
Related Works
- 重みの量子化手法: 推論時に限定した話だと、LLMの重みを4/8bitに量子化するGPTQ[4], AWQ[5], GGUFなどの各種手法がある。
- 4bit量子化+LoRAファインチューニング: ファインチューニングフェーズに限定した手法だと、4bitに量子化したベースの重みをフリーズした状態でLoRA adapterの重みを学習する手法QLoRAがある[3]。
- FP4量子化学習 : 最近ではFP4演算に対応したNVIDIAの次世代チップBlackwellシリーズでの最適化に向けてFP4精度での量子化学習が提案されている[2]。[2]では本論文と同様にoutlierを分離することでoutlier以外の量子化誤差を改善するアプローチが取られている。
本手法は、重みとアクティベーションをともにINT8で量子化するという点で上記の手法と異なる。8bitの演算に対応したGPUチップを利用する場合に、16bit精度の行列計算よりも高速に計算できる可能性がある(🪓)。
過去記事も参照。
著者らのブログ記事も参考になる。
Reference
- [1] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale, Nov 2022
- [2] Optimizing Large Language Model Training Using FP4 Quantization, Jan 2025, https://arxiv.org/abs/2501.17116
- [3] QLoRA: Efficient Finetuning of Quantized LLMs, May 2023, https://arxiv.org/abs/2305.14314
- [4] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Mar 2023, https://arxiv.org/abs/2210.17323
- [5] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration, Jun 2023, https://arxiv.org/abs/2306.00978
- [6] https://github.com/bitsandbytes-foundation/bitsandbytes
- [7] https://github.com/bitsandbytes-foundation/bitsandbytes/releases/tag/0.45.0
Appendix
A. bitsandbytesにおける8bit行列計算の実装

(source: bilzard)
Discussion