QLoRAを知らずして量子化ファインチューニングを語るなかれ
本記事は4bit量子化重み+LoRAによるファインチューニング手法QLoRAのまとめ記事です。特に4bit量子化フォーマットNF4の技術的詳細を掘り下げて記述しています。
paper: QLoRA: Efficient Finetuning of Quantized LLMs, May 2023
Overview
- モデルの重みの4bit量子化フォーマット(NF4)を提案
- モデルの重みをNF4で量子化した状態でRoLAの重みを学習→QLoRAは16bit精度のfull-finetuningと同等の性能を実現
- QLorAはfine-tuningにおけるGPU環境の敷居を下げた(33Bモデルを24GBのGPUで、65Bモデルを48GBのGPUで学習)
- fine-tuningからさらに発展させて、QLoRAを用いてInstruction TuningしたモデルQuanaco(7B~65B)の包括的な評価を実施。幅広いベンチマーク性能でGPT-4と概ね同等の性報を報告する一方で、安全性の評価指標(biasの有無)においてはfull-finetuningした他のモデルと比べて明確な劣性が確認された
- チャットエージェントのベンチマーク性能と学習データセットの内容(i.e. ベンチマークタスクと同種のタスクのデータセットが学習データセット中に含まれるか)に明確な相関が確認された→現状のSOTAモデルのベンチマーク評価は特定のタスクに偏っている可能性がある
本手法の位置付け
学習フェーズ
a) 事前学習: 例) next-token prediction etc.
b) 事後学習: 例) Instruction Tuning, 継続学習 etc.
c) ファインチューニング
主にc) ファインチューニングに適用する目的で提案。ただし、論文の後半ではQLoRAを用いてInstructin Tuningしたチャットエージェントの性能評価を行っており、b) 事後学習での使用も視野に入れた調査を行なっている。
量子化手法
a) 重みの量子化
b) アクティベーションの量子化
モデルの重みを4bitに量子化する手法。アクティベーションの計算は16bit精度で行う。
手法
本論文はモデルの重みを4bitに量子化した状態でベースの重みをフリーズし、LoRA[2] adapterの重みを新たに学習する手法QLoRAを提案する。LoRA以外の新しい部分は以下の3つなので、以降これらの技術の詳細について記載する。
- 量子化フォーマットNormalFloat4(NF4) の提案
- Quantile Quantization
- Double Quantization
- Paged OptimizerによるOOMの回避
1. Quantile Quantization
- 課題: ナイーブに等間隔に量子化してabsmaxで正規化すると、outlierに引きずられて0付近の細かい値の差異が潰れてしまう(図1)
- アイデア: 量子化した時の各binに入るサンプルの期待値が同じになるようにする
- 手法: 正規分布の累積分布の値域を等分割し、それぞれの区間の中点に相当する点をサンプル点として定義する(図2)
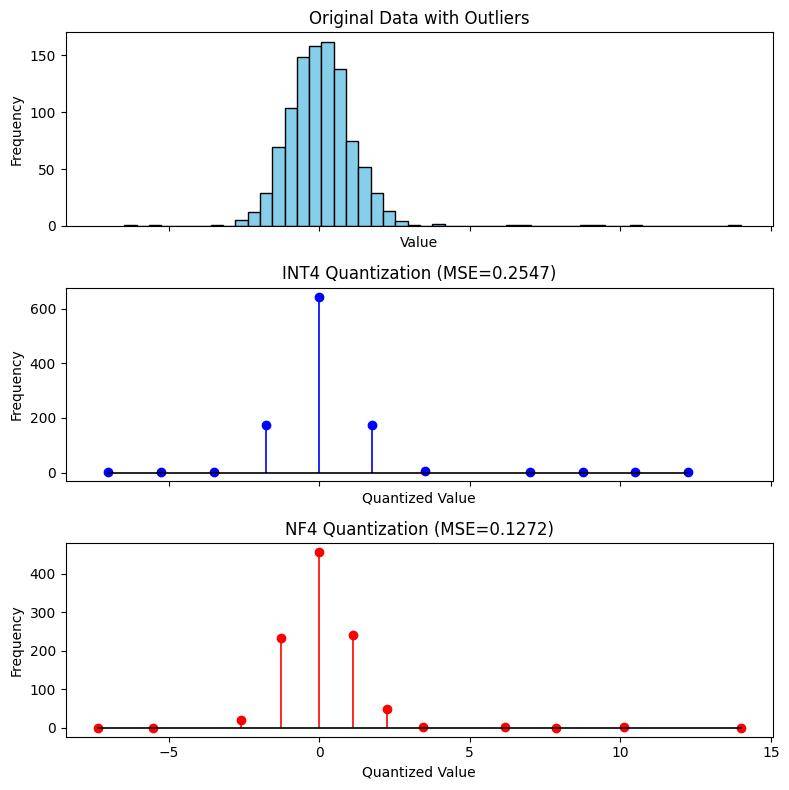
図1. outlierを含む分布の量子化精度の比較: outlierを含む正規分布を量子化する場合、INT4よりNF4の方が量子化誤差(MSE)が小さい。作図にあたりbitsandbytesのNF4の実装[3]を参考にした。 (source: bilzard)
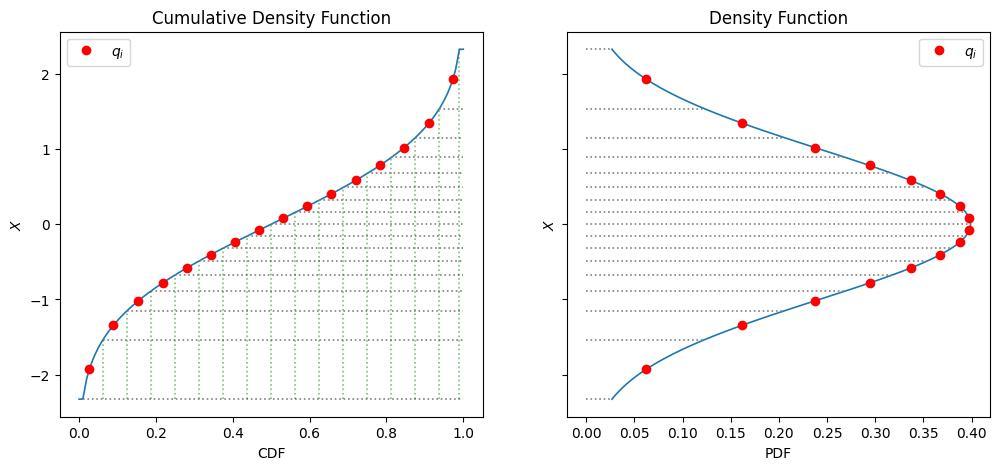
図2. Quantize Quantizationの構成方法: 標準正規分布の累積分布(CDF)の値域を等分割することで各binの確率密度を等しくする (source: bilzard)
1-a) スケールの正規化
実際の分布を標準正規分布に正規化するためには、重みの分布のスケール(標準偏差)をどう推定するか? という問題が残される。ナイーブな方法として、ブロック内のサンプルの標本標準偏差をとる方法が考えつくが、この方法だとoutlierをclipする必要が生じる。重みのoutlierには重要な情報が含まれることが多いらしく、捨てると性能劣化するため、NF4では単純にabsmaxで[-1, 1]に正規化するアプローチをとった。この方法では重みの分布のスケールの正確な推定は諦め、outlierの値の情報がなるべく残るようにしている。経験的にはこの方法でBF16と比べて性能劣化は生じなかったと報告している。
1-b) 非対称な量子化
- 課題: サンプル点が16点なので、正負対称に量子化すると、1) 0が含まれなくなる、2) 0の表現が冗長になる、のいずれかの問題が生じる
- 解決方法: 正負非対称な量子化を用いる(図3)
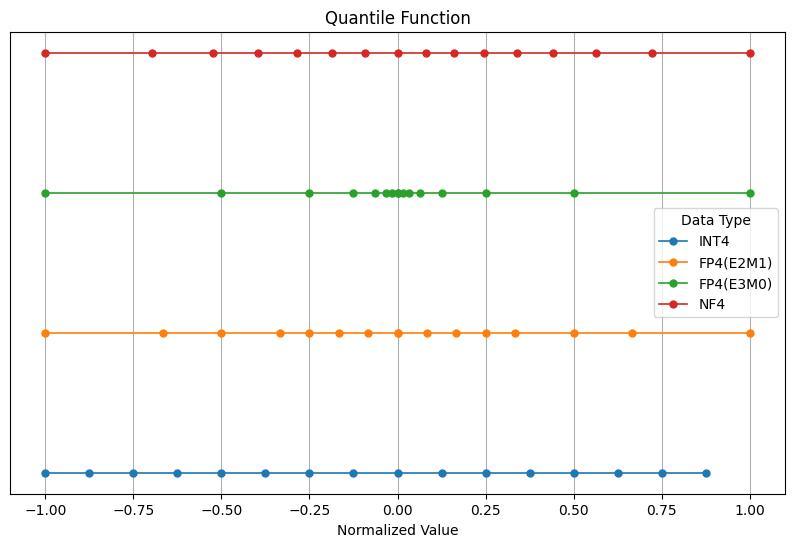
図3. 量子化タイプごとのスケールの可視化: NF4は平均に近い重要なデータをより細かい精度で表現する。FP4(E2M1)と概ねスケールが一致する (source: bilzard)
2.Double Quantization
- GGUFのsuperblock(✍️)と同様の考え方に基づく。各blockのscaleを32bit精度で持つともったいないので、scale自体も量子化して8bitで保持する(図4)。
- 例えば、block size=64とすると、1段階目の量子化で、scaleに32bit使うと32/64=0.5bpp消費する。一方で、scaleを(super) block size=256で8bitに量子化すると、scale分のビットレートは8/64+32/(64*256)=0.127 bpsとなり、0.373bppビットレートを減らすことができる
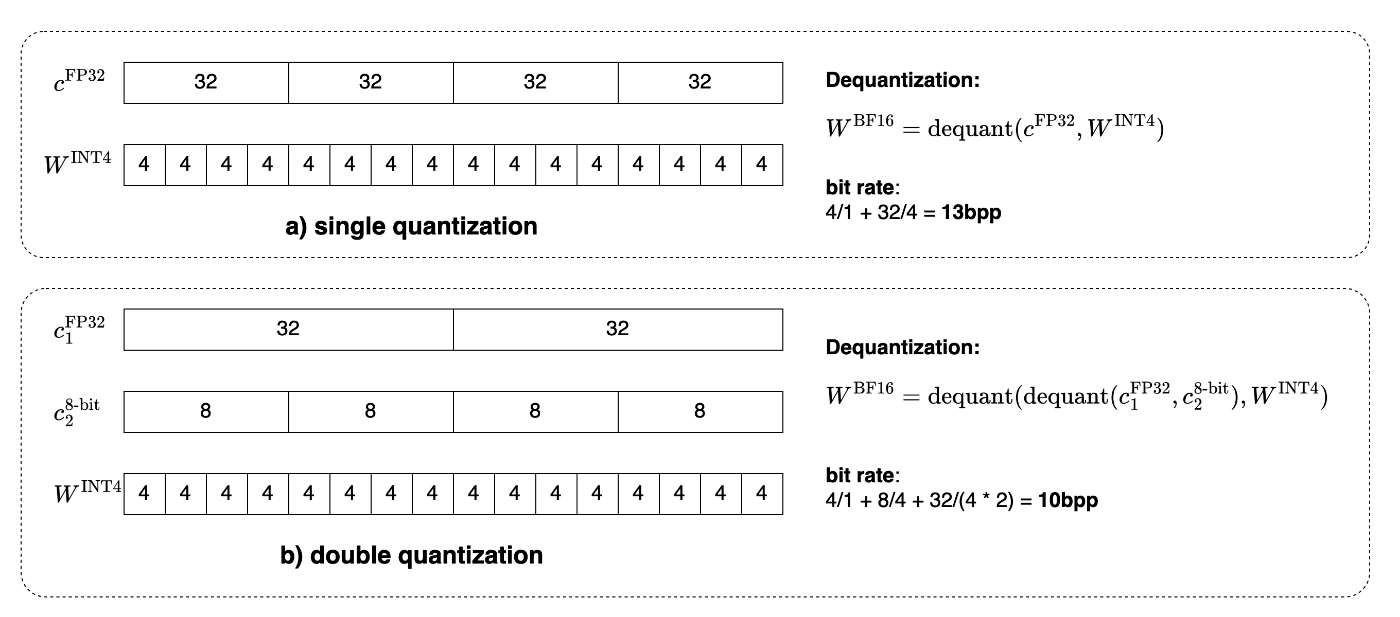
図4. Double Quantization: block size=4, super block size=2の場合の可視化。四角内の数字はbit数を表す (source: bilzard)
3. Paged Optimizer
- NVIDIAのunified memoryを使い、GPUとCPU間でのページ単位でのデータの退避・復元を実装→学習中のOOMを防止する。
評価
- NF4とその他の量子化方法(INT4, FP4)との比較→NF4が一貫して優位と報告(🪓)
- Double Quantization単体の比較はしていないが、NF4+DQの組み合わせが他の量子化手法と比べて優位と報告
- QLoRAでInstruction TuningしたモデルはSOTAのChatAgentに被検するか?→QLoRAで学習したモデルDuanacoは安全性(bias評価)において明確な劣性が確認されたものの、ベンチマーク性能については幅広いタスクでGPT-4と概ね同等の性能を示した
その他の知見:
- SOTAモデルの性能を比較すると、ベンチマーク性能と、学習に使用されたデータの種類(i.e. ベンチマークと同種のタスクのデータが含まれるか?)に明確な相関がある→現状のベンチマークは特定のタスクに偏っている可能性がある
所感・考察
- 量子化学習+LoRAを適用してうまくいった例として参考になった(33Bモデルを24GBのGPUで学習)
- 事前学習タスクでは、学習時に量子化重みを使う手法はlossのスパイクが生じる現象が報告されるが、本手法では問題にならなかったのか?→fine-tuning程度では問題にならない? or LoRAによる正則化がうまく機能している?
- NF4単体の優位性については疑問が残るが、少なくともNF4+DQでBF16のfine-tuningと遜色ない性能が得られたとする事例として参考になった
- fine-tuningから発展してInstruction Tuningなどの事後学習フェーズにQLoRAを使用するのは少し危険かなという印象(bias評価で明確な劣性が確認されているため)
Reference
- [1] QLoRA: Efficient Finetuning of Quantized LLMs, May 2023, https://arxiv.org/abs/2305.14314
- [2] LoRA: Low-Rank Adaptation of Large Language Models, Oct 2021, https://arxiv.org/abs/2106.09685
- [3] bitsandbytes-foundation/bitsandbytes v0.45.2, https://github.com/bitsandbytes-foundation/bitsandbytes/blob/0.45.2/csrc/kernels.cu#L171
Discussion