[Python / YOLOv8] Webえんじにゃ、物体検知をする②YOLOv8で簡単に遊ぶ



Webえんじにゃです
機械学習は大学時代(n>1 年前🤔)にチョトヤッタくらいのレベルです
当時とはだいぶ進化している…ので1からやっていきます
今回はPythonとYOLOv8を使って機械学習して物体検知にとりくみます
長くなるので分割して記事にしていきます
この記事は2個目です
[Python / YOLOv8] Webえんじにゃ、物体検知をする①仮想環境構築まで
[Python / YOLOv8] Webえんじにゃ、物体検知をする②YOLOv8で簡単に遊ぶ
[Python / YOLOv8] Webえんじにゃ、物体検知をする③学習の準備
[Python / YOLOv8] Webえんじにゃ、物体検知をする④学習モデルを自作する
ではまずはYOLOv8を使ってどんなことができるのかやってみます
モード
サンプルコードを触る前に、YOLOv8にはいくつかのモードがあります
メインでよく使われるであろう3つを先に紹介します
Train
トレーニングモード。つまり 学習させる(モデルを自作する) 場合はこれを使う
※電車ではない🚅
Val
トレーニングモードが完了したあと、検証するために使うモード
ここで検証結果がよければモデル完成!というかんじ
Predict
トレーニングされたモデルを使用して、新しい画像ではどうなるか予想するためのモード
→画像認識(物体検知)自体はこれを使うよ
サンプルコード
実行してみる
ここを参考にコードを触ってみます
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO('yolov8n.pt')
# Predict the model
model.predict('https://ultralytics.com/images/bus.jpg', save=True, conf=0.5)
これで出来上がるものが
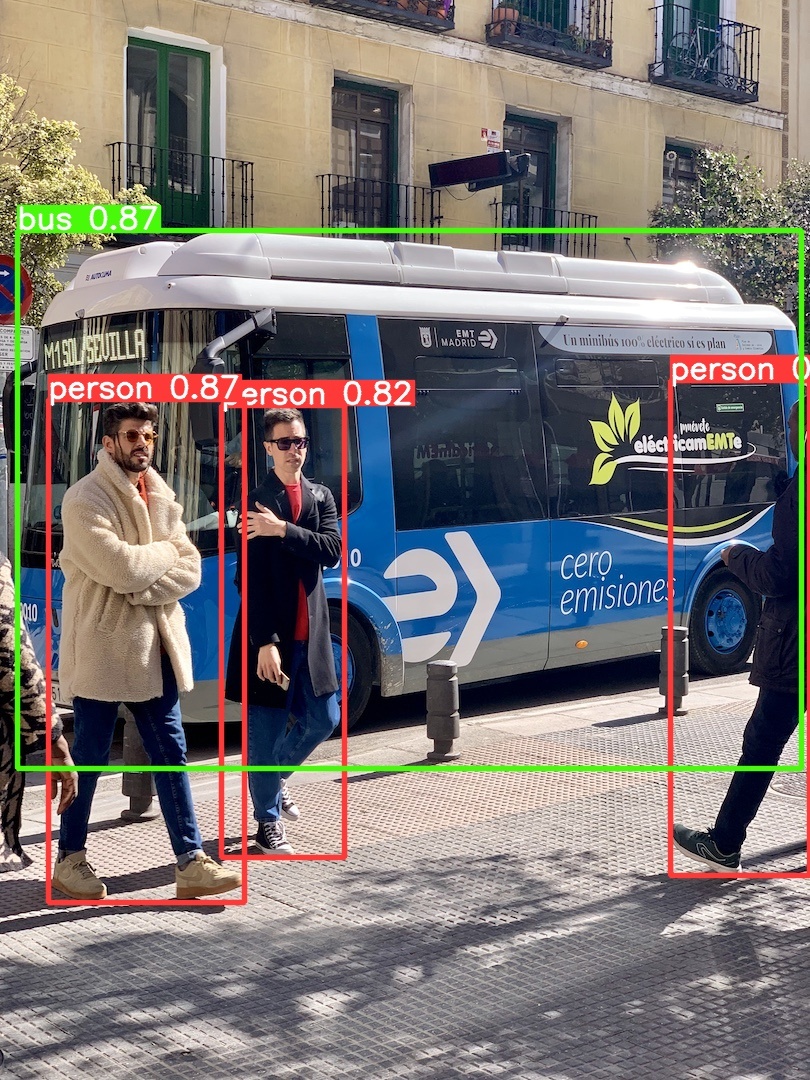
これ。すgggっごい。すごくない??すごいよね、私は感動しました
基本的に成果物は .runs/detect/predict の中に入っています
(実行するたびに predict2, predict3,…みたいな連番でフォルダが作られるかんじ)
では読む
では公式ドキュメントをもとに何をしているのか簡単に理解していきます
モデルを読み込む
model = YOLO('yolov8n.pt')
そもそも機械学習でいうモデルとは、特定の種類のパターンを認識するようにトレーニングされたファイルのこと
モデルさえ読んでしまえば、いわゆる学習とか色々面倒なことは全部もう済んでいるのであとは指定された画像なりを読み込めばおkってこと
画像を読んで結果を出力
model.predict('https://ultralytics.com/images/bus.jpg', save=True, conf=0.5)
さきほど紹介した Predict モードを使用しています
引数はいろいろ指定できるみたい。めちゃくちゃ数が多いので公式を読むことを推奨
今回のサンプルコードでは、
①物体検出したい画像のパスを指定(https://ultralytics.com/images/bus.jpg)
②検知結果を別のファイルに保存するかを設定(save=True)
③信頼性閾値を指定(conf=0.5)
を設定しています
信頼性閾値 は、検出結果の信頼性に対するレベル
例えば信頼性閾値を0.5(50%)で設定すると、検出結果が80%の信頼度だった場合は結果として出力するが、20%(閾値以下)だった場合は結果として保存されないようになる
つまりこんなイメージ
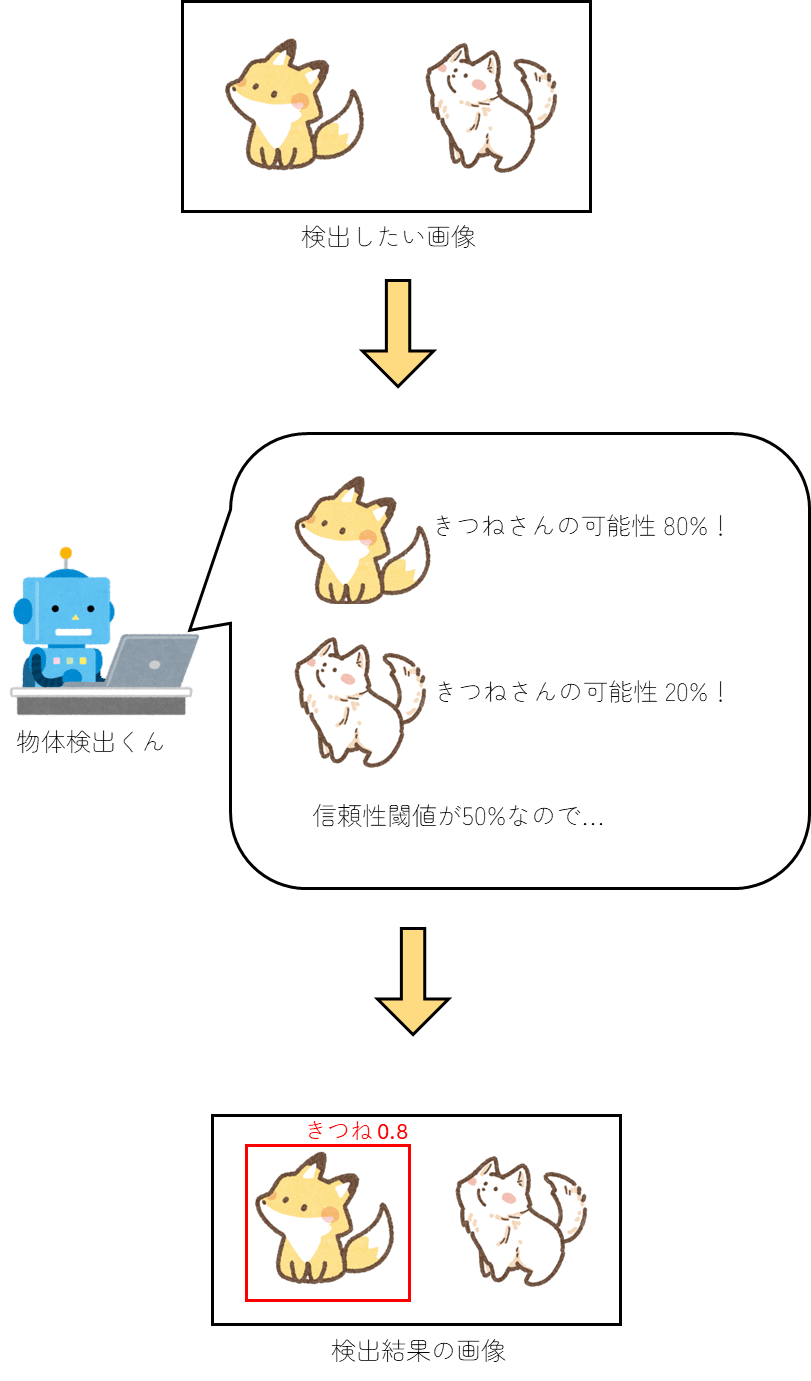
かわいいね
今回はここまで
次は実際に自作モデルを作るために準備をしていきます(labelimg を使うよ!)
Discussion