[Python / YOLOv8] Webえんじにゃ、物体検知をする③学習の準備
Webえんじにゃです
機械学習は大学時代(n>1 年前🤔)にチョトヤッタくらいのレベルです
当時とはだいぶ進化している…ので1からやっていきます
今回はPythonとYOLOv8を使って機械学習して物体検知にとりくみます
長くなるので分割して記事にしていきます
この記事は3個目です
[Python / YOLOv8] Webえんじにゃ、物体検知をする①仮想環境構築まで
[Python / YOLOv8] Webえんじにゃ、物体検知をする②YOLOv8で簡単に遊ぶ
[Python / YOLOv8] Webえんじにゃ、物体検知をする③学習の準備
[Python / YOLOv8] Webえんじにゃ、物体検知をする④学習モデルを自作する
さて、既存のモデルではなかなか検知できない場合がありますね
そういうときは自分でモデルを作成する必要があります
ちょっと大変だけどやってみましょう
使うものは labelimg と YOLOv8 の Train/Val モードです🚅🚅🚅🚅
今回はまず labelimg を使って準備していきましょう
labelimg でアノテーション
学習に必要なのは、そう。たくさんの画像ですね
ここでは、モデルのためのアノテーション(枠・タグのついた)された画像を作ります
この画像は多ければ多いと幸せになる……というわけでは必ずしもないみたいです
どれくらいの精度にするかによるので、超絶スーパー精度を目指すのであれば画像の質も量もどちらも必要になるよ(あたりまえ体操)
案件の内容や検出後の仕様…などによって画像の量を決めようね
私の場合、そもそも案件としてまだサンプルとできる画像が少ないので200枚程度になりました(モウチョットホシイ)
検出できる画像と何も物体がない画像の両方用意しましょう
下準備
- まずは仮想環境下にて、下記コマンドを実行して labelimg を立ち上げる
labelimg
そうすると、タスクバーにはPythonアプリのアイコン、そして下図のような labelimg アプリが立ち上がります

- アノテーションする画像をまとめたフォルダ(
Open Dir)と、内容を保存するフォルダ(Change Save Dir)をそれぞれ選択
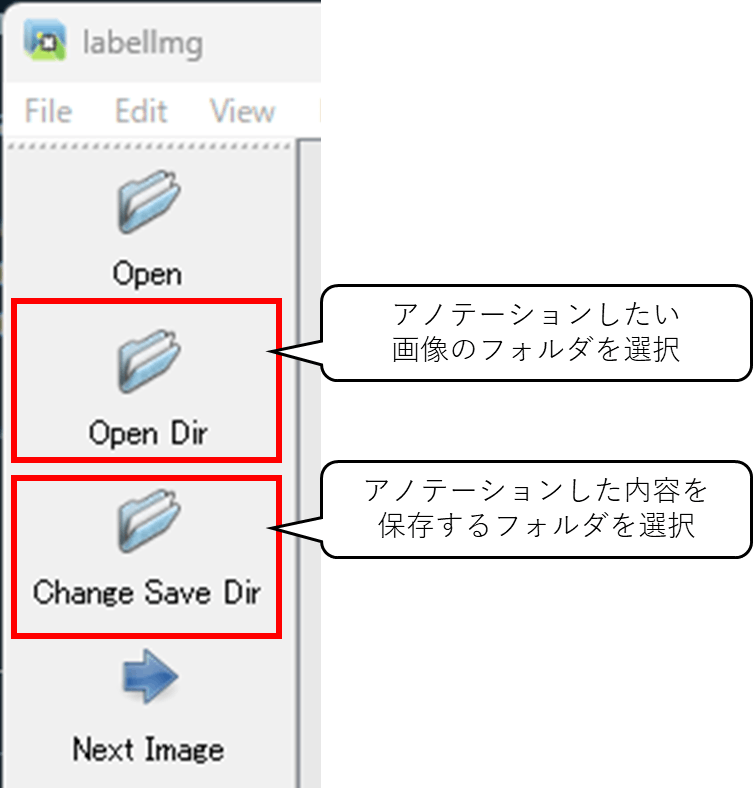
今回は便宜上
- アノテーションする画像をまとめたフォルダ(
Open Dir): images フォルダ - 内容を保存するフォルダ: labels フォルダ
として説明していきますね
- 学習モデルのモードを選択しておく
今回は YOLO 向けのデータを作成したいため、もし「Create ML」モードになっている場合はクリックして「YOLO」にしておきます

実際にアノテーションしていく
画面左のメニューボタンいろいろから編集開始/保存/画像切り替えができます
よく使うボタンを紹介しておきます
- Next Image: 次の画像へ
- Prev Image: 前の画像へ
- Save: アノテーションを保存
- Create RectBox: アノテーションの枠・タグの描画開始
つまり、アノテーションする場合はまず Create RectBox ボタンを押下します
そうするとカーソルが変化するので、物体を囲うようにクリック→ドラッグして矩形選択すると、その矩形に対してタグをつけることができます

もちろん、1枚の画像に複数の枠・タグをつけることが可能なので、やりたい放題 必要に応じてアノテーションしていきます
ちなみに登録したタグは保存されるので、同じタグで登録する場合は以後入力は不要。選択するだけでOKになります
これを Save して次の画像に行き、作業を繰り返します
ちなみにショートカットもいくつかあるので使いやすいものは使うと便利です
- Ctrl + S: 保存
- w: Create RectBox
- d: 次の画像へ
などなど(=゚ω゚)ノ
これを全部の画像やります。がんばろぽちぽち
labelimg が落ちる場合
argument 1 has unexpected type 'float'のようなエラーで死ぬ場合があります
例えば、描画しようとしたり画像の拡大縮小などを実行しようとすると発生することがあるみたいです😭
応急処置を紹介してくれている記事があるため紹介しておきます
簡単に説明すると、エラーが出ている個所に対してint型にするように修正すればOKです
例えば
- self.zoom_widget.setValue(value)
+ self.zoom_widget.setValue(int(value))
といったかんじ
今回はここまで
次はいよいよ画像を学習させていきます
Discussion