こんにちは、atama plus でデータエンジニアをしている kumewata です!
先日 GA された Gemini in BigQuery の一機能であるデータ キャンバスが便利だったので、紹介していきます。
背景
最近何度か探索的にデータを見る機会があり、次のような場面でデータ キャンバスがニーズを満たしてくれそうでした。
- 弊社マーケティングチームが作成する記事向けのデータ抽出を担当したが、ドメイン知識がなく探索的にデータを見たかった。
- いつもどおり BigQuery のクエリエディタからデータを見ようとしたが、タブがどんどん増えるし、比較しながら可視化するのもめんどうで困っていた。
- とあるプロダクトの検証データをサクッと可視化したかった。
- クエリと可視化結果をまとめて簡単に共有したかった。
データ キャンバスの紹介
Google Cloud のデータ キャンバス紹介ブログによると次のような言葉で紹介されています。
・自然言語中心のエクスペリエンス: コードを書くのではなく、データに直接語りかけることができます。質問をしたり、タスクを指示したり、AI にさまざまな分析タスクを案内してもらうことができます。
・ユーザー エクスペリエンスの刷新: データ キャンバスでは、ノートブックのコンセプトが見直されています。広範なキャンバス ワークスペースにより、イテレーションを促進し、共同作業を容易にできるため、作業を洗練させ、結果を関連付け、ワークスペースを同僚と共有できます。
もう少し具体的に書くと Gemini in BigQuery の下記の機能群を、Miro のようなキャンバス上でシームレスに扱うことができるサービスです。
- 自然言語でデータアセット(テーブル、ビュー)を検索できる
- 自然言語の入力からクエリを生成
- 可視化
- 自動インサイト(出力データにサマリーをつけてくれる)
使ってみた機能と知見の紹介
自然言語からクエリを生成できる
便利なところ
BigQuery テーブル、カラムの名前やディスクリプションも参考にしつつ Gemini がクエリを生成してくれます。そのため、DWH 上のテーブルに詳しくないユーザーでも簡単なクエリ構築なら自然言語で作成することができます。
テーブル検索自体も自然言語とキーワード検索の 2 種類でおこなえ、利用可能なテーブルを探すところからサポートしてくれます。
メタデータの有無によるクエリ生成精度の違いについては、クラウドエース社の記事( 自然言語でデータ分析できる「BigQuery データ キャンバス」)が参考になります。
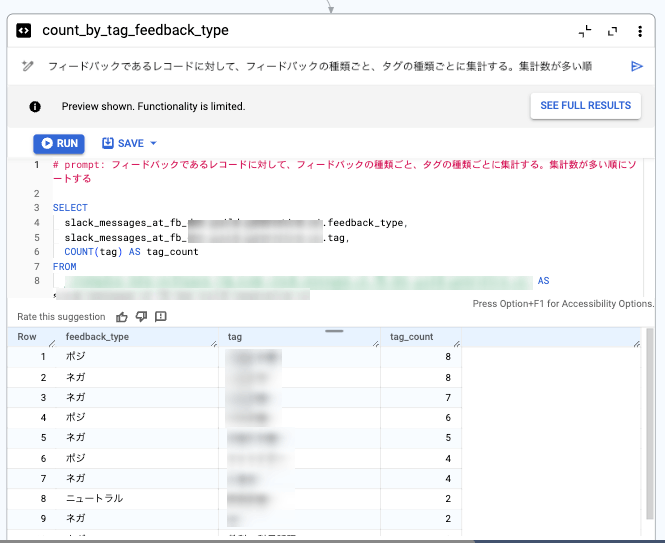
自然言語でクエリ生成した例
課題、気になったところ
- メタデータが少ない状態だと、真価を発揮できない。
- 弊社ではまだメタデータの整備が不十分なため、ちょうど今データカタログの選定とともにメタデータの拡充を進めていく予定です。
- 痒いところまでは手が届かないので、複雑なクエリが必要な場合は自分でも手を動かす必要がある。
- こちらは 1 つ目のメタデータの整備に加えて、データモデリングの改善などにも着手する必要がありそうです。また先日の Google Cloud UPDATESで「軽い分析をツール群に詳しくない人ができるようにすることを目指している」という言葉がありました。データ キャンバスの内容は Notebook に出力できるため、よりデータを深掘りしたい場合はこちらに切り替えるなど使い分けをするとよさそうです。
- 自然言語の入力欄が狭い。
- もう少し広くなると嬉しいです!
ブロックごとにクエリ結果を使いまわせる
便利なところ
- CTE ごとにブロックを作ることでクエリの分岐を作れるので、探索的な分析をしやすい。
- 最初にウェアハウス的なブロックを作り、そこから特殊化したクエリ(特定のユーザーに絞る、とか)を複数生やす、的な流れで繋げると複数パターンの結果を比較しやすくなります。
- CTE の途中で結果をチェックしたい時に、わざわざクエリコメントアウトして戻す的な手間がなくなる(デバッグ観点でも便利)。
- クエリエディタだけだとめんどうだった、複雑なクエリの途中確認が簡単になります。想定とは違う使い方かもしれませんが、複雑な既存クエリを CTE ごとに分解して解読したり、再利用する時にも便利です。
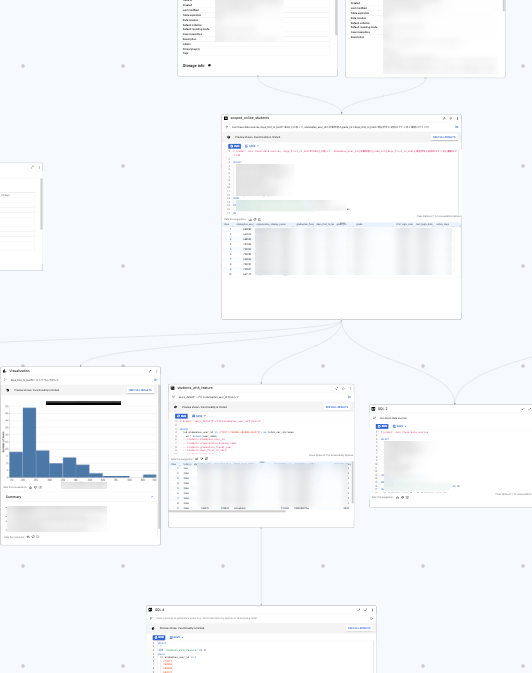
CTE ごとにブロックを分けて、可視化したり、クエリを繋げている例
課題、気になったところ
- ブロックに適切な名前(またはコメント)をつけておかないとすぐ訳がわからなくなるので注意
- これは CTE の名前を決めるのが重要なのと同じ話です。キャンバス上にどんどんブロックを増やせるので、その反動でとっ散らかりやすい感触があります。クエリと同じくデータ キャンバスも共有できるので、チーム内で共有予定がある場合はぜひ名前やコメントをつけましょう。
-
ブロックの配置に自由度が少ない。->アップデートで自由に配置できるようになりました!(2024/10/25追記)個人的に Miro をよく使うのですが、そのイメージでいくと最初はブロックを自分で動かせなかったり、サイズを変えられなかったりするのに違和感がありました。ただブロックは自動で整理されるため、一定散らからないように抑制する効果がありそうです。
- ブロックや同時に join するテーブルが増えると読み込みが遅くなる。
- ブロックが増えるにつれて、自然言語からクエリ生成するのに時間がかかるようになります。特に 3 つ以上のテーブルを join する時は顕著に遅くなる感触がありました。ここは Gemini のバージョンが上がると改善されていくのかもしれません。
クエリ結果をスムーズに可視化できる
便利なところ
- BigQuery クエリエディタで利用できるグラフを使って、キャンバス上でも簡単に可視化できる。
- 棒グラフ、円グラフ、折れ線グラフとカスタマイズされた可視化の 4 つから選択して可視化を行えます。カスタマイズされた可視化では、入力した自然言語をもとに 3 種類から最適なグラフを選んで可視化が行われるそうです。
- ブロックとの組み合わせで可視化を横並びで比較できる。
- 一つ前の節で紹介した内容とも被りますが、ブロックを分岐させることで可視化を横並びに比較できて便利です。
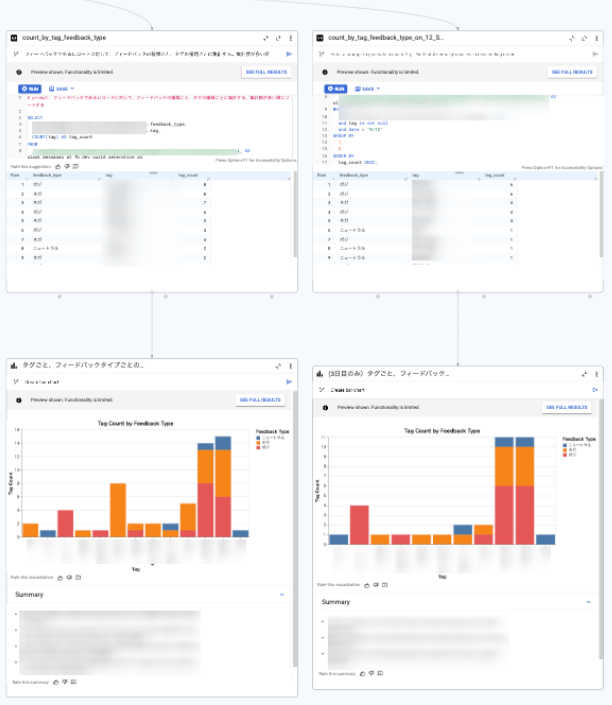
可視化の例
課題、気になったところ
- 可視化のパターンが少ない。
- データを深掘りしたい場合は、エクスポートして Notebook やスプレッドシートなどに切り替えましょう。
まとめ
データ キャンバスは探索的なデータ分析が必要なケースにおすすめなので、ぜひ使ってみてください!
特に BigQuery を含めた分析用ツールに不慣れなメンバーでも、ツールを切り替えずに自然言語ベースで可視化まで行えて便利です。
最後に
現在 atama plus では多くの職種で採用を行なっております。
新しいサービスも立ち上がっているので一緒に盛り上げてくれる方、教育業界のデータに興味があるといった方、ぜひお話ししましょう!

Discussion