【Next.js】ポートレートの表情を編集する自作UIを作ってみた【ComfyUI-AdvancedLivePortrait】
はじめに
前回の記事で、超つよつよ技術である、「ComfyUI-AdvancedLivePortrait」を試してみました。
どんな技術かというと、下記のようなサービスの元となった技術です。
この技術を使うことで、AIが生成した人物画像の表情や構図に加え、自分で撮影した画像に対しても、自由に編集できるようになります。
私は前回の記事では、「ComfyUI」という画像生成AIのWeb UI上に導入できる「ComfyUI-AdvancedLivePortrait」という拡張機能を、WebUIに依存せずに、通常のpythonスクリプトで実行できるようにしました。
やはり、せっかくWebUIに依存しない形で動かせるようにしたので、自分で作ったフロントで動かしてみたいと思い、今回はNext.jsを利用して、ポートレートの表情を編集する自作UIを作ってみました。
できたもの
作ったものです。下記より動画でご覧ください。
私のフロントエンド知識は未熟なので、UIや機能は微妙な感じですが、かなり高速にストレスなく画像の編集ができていると思います。
動画では出せていないですが、プレビュー画像を右クリックして保存すれば、作成した画像を保存できます。
技術選定・動作環境
技術選定
下記の通り選定しました
フロントエンド:Next.js(App Router)
バックエンド:Python
動作環境
動作環境は下記です。
フロントエンドサーバ:M2 Mac
バックエンドサーバ:Ubuntu 20.04 (GPU:RTX3060 12GB RAM:64GB)
(ちょっと遅いですが、Google Colabでも動作確認済みです。また、遅いですがCPUでも動作はします。)
成果物
下記のリポジトリに置いてあります。
動作方法
環境構築
フロントエンドとして、Next.js+pnpm、
バックエンドとしてPythonが利用できる環境(もしくはGoogle Colabが利用できる環境)になっていれば問題ありません。
既に、利用できる方は下記のステップは飛ばしてください。
環境構築
フロントエンド、バックエンド両方
gitを導入している方は下記のコマンドで、リポジトリをクローンしてください
git clone https://github.com/personabb/AdvancedLivePortrait_Nextjs.git
gitを導入していない場合は、下記のページで緑色の「Code」ボタンをクリックして、下の方にある「Download ZIP」をクリックすることでダウンロードできます。
この後は、このリポジトリをカレントディレクトリとして、コマンドなどの実行をしてください。
このリポジトリ自体は、Desktopにおいても良いですし、そのままDownloadにおいておいても良いですが、ターミナルのカレントディレクトリだけ、このディレクトリを指定しておいてください。
フロントエンド (Next.jsの環境構築)
フロントエンドではNext.js(+ pnpm)を利用しています。
下記の通り、環境構築をしてください。(Macを想定しています。Windowsの方申し訳ございません)
(去年の環境構築に使った資料やスクリーンショットを引っ張ってきているので、古いかもしれません。最終的にNext.js(+ pnpm)を利用できるようになっていればいいので、他の方法で環境構築しても構いません)
Brewの導入(導入済みの方はスキップ)
バッケージインストーラであるbrewを導入します。
ターミナルを起動して、下記コマンドを実行してください。パスワードを求められるので入力してください。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
途中でEnterキーを押すことを求められます。押してください。
下記のコマンドで環境変数にパスを通します(一行ずつ実行してください)
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zshrc
eval "$(/opt/homebrew/bin/brew shellenv)"
PATH=/usr/local/bin:$PATH
export PATH
下記のコマンドを実行して、brewのバーションが表示されれば成功です。
brew -v
Node.jsの導入(nodebrewの導入)
下記コマンドでnodebrewをインストールします
brew install nodebrew
下記の画像の赤枠部分の記載されているコマンドを実行します(人によっておそらく違うのでよく見てください)

上記の画像なら下記コマンドです
/opt/homebrew/opt/nodebrew/bin/nodebrew setup_dirs

続いては、上記の画像の、赤枠の部分に記載されているPathを環境変数に追加します。
上記の画像なら、下記のコマンドで環境変数を追加できます。
echo export PATH=$HOME/.nodebrew/current/bin:$PATH >> ~/.zshrc
ただし、export PATH=$HOME/.nodebrew/current/bin:$PATHの部分は、皆様の実行画面(の赤枠の部分)に合わせて変更してください。
その後、設定した環境変数を適用するために下記コマンドで更新します。
source ~/.zshrc
Node.jsの導入(Node.jsの導入)
導入したnodebrewを使ってnodeのvarsion 19.6.1をインストールします。
(インストールするバージョンは、おそらくなんでもいいです。私が上記の環境のため書いていますが、基本は最新のバージョンをお勧めします)
下記のコマンドを実行します
nodebrew install v19.6.1
Installed successfullyと表示されればOKです。
続いて、インストールしたnodeのvarsion 19.6.1を利用できるように下記コマンドを実行します。
nodebrew use v19.6.1
use v19.6.1と表示されればOKです。
nodebrewを利用することで、複数のバージョンをインストールして、用途ごとにバージョンを使い分けることができるようになっています。
(もちろん、最終的にNext.js(+ pnpm)が利用できればいいので、他の方法でインストールしても良いです)
pnpmのインストール
下記コマンドでpnpmをインストールします
npm install --global pnpm@8.6.0
以上で、Next.jsとpnpmが利用できるようになりました。
バックエンド(ローカルPCを利用)
カレントディレクトリを./AdvancedLivePortrait_Nextjs/alp_backendに設定するために、下記のコマンドを実行します。
cd alp_backend
pythonの導入
前提として、pythonのバージョンは3.10もしくは3.11を利用します。
pythonはpyenvを利用して、バージョンを指定しながら導入します。
pythonのバージョンはpyenvで指定します。
pyenv自体の導入については下記をご覧ください。
pyenvが導入できていれば、下記のコマンドでpythonのバージョンを指定できます。
pyenv install 3.10.14 #もしくは3.11.9など
pyenv local 3.10.14 #もしくはpyenv global 3.10.14
これでpythonのバージョンが指定できます。
pyenv globalはシステム全体に、このバージョンを反映させたい時に利用してください。
pyenv localは現在のカレントディレクトリでのみ、このバージョンを反映させたい場合に利用します。
下記コマンドを実行して、pythonのバージョンが変更されているかを確認してください。
python -V
# Python 3.10.14
pythonの仮装環境の設定
続いて、必要なパッケージをインストールするために仮想環境を構築します
venvで仮想環境を構築します。
venvはpython公式の仮装環境のため、pythonが利用可能であれば導入の必要なく利用できます。
python -m venv env
source env/bin/activate
以降、バックエンドを実行する場合は、この仮装環境に毎回入って実行してください。
次回以降、仮装環境に入るだけなら下記コマンドだけで大丈夫です
source env/bin/activate
バックエンド(Google Colabを利用)
Google Colabを利用する場合は、環境自体は構築済みなため、特に必要な処理はありません。
強いていえば、Googleアカウントを作成してください。
実行準備
フロントエンド
カレントディレクトリは./AdvancedLivePortrait_Nextjsを想定しています。
バックエンドのURLを設定
.env.localをリポジトリ直下(./)に作成して、下記の通り設定してください。
URLはバックエンドサーバのURLです。(以下は例です)
NEXT_PUBLIC_API_BASE_URL=http://192.168.0.xxx:8000
(バックエンドサーバのプライベートIPアドレスを予め確認しておいてください。ポートは8000です)
http://192.168.0.xxxの部分は、バックエンドサーバのURLを指定してください。
Next.jsで必要なパッケージのインストールとビルド
下記のコマンドを一つずつ実行してください。
pnpm i
pnpm build
バックエンド(ローカルPCの場合)
バックエンドの準備では、./AdvancedLivePortrait_Nextjs/alp_backendをカレントディレクトリとして、それ以降のコマンドを実行してください。
pythonパッケージのインストール
必要なpythonのパッケージをインストールします。下記コマンドを実行してください。
# パッケージのインストール
git clone https://github.com/PowerHouseMan/ComfyUI-AdvancedLivePortrait.git
pip install fastapi\[all\]
cd ComfyUI-AdvancedLivePortrait
pip install -r requirements.txt
cd ..
バックエンド(Google Colabの場合)
コードのアップロード
まず、必要なコードをGoogle Driveにアップロードします。
alp_backendディレクトリだけを、Google DriveのMyDrive直下においてください。
(バックエンドなので、フロントのファイルは不必要です)
下記のようなディレクトリになります。
MyDrive/
└ alp_backend/
ngrokのアクセストークンを取得
ngrokはローカルPC上で稼働しているネットワークサービスを簡単に外部に公開できるサービスです。
この機能を利用して、Google Colab上のサーバで起動したAPIサーバを外部に公開し、フロントエンドサーバから接続します。
アクセストークンは下記の記事を参考にして取得してください。
取得したngrokアクセストークンをGoogle Colabの環境変数に登録
取得したアクセストークンをNGROKという名前で、Colabの環境変数に登録してください 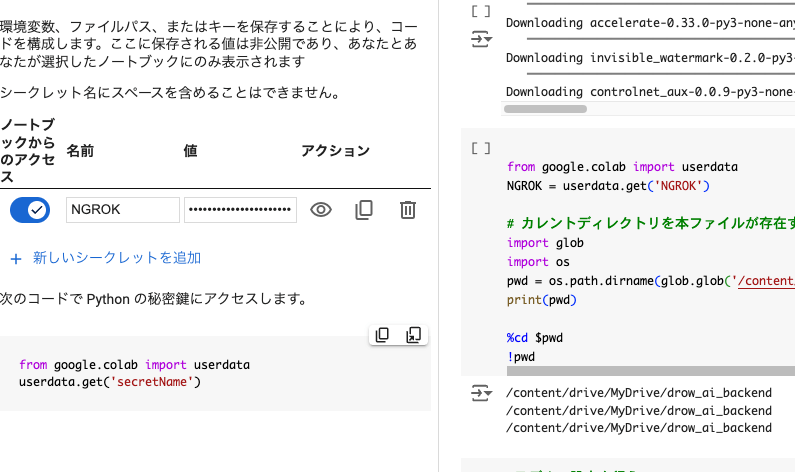
上記のようになっていたら問題ありません。
登録の仕方は下記の記事がわかりやすいです。
実行
フロントエンド
カレントディレクトリは./AdvancedLivePortrait_Nextjsを想定しています。
フロントエンドサーバの起動
下記のコマンドを実行してください
pnpm dev
ターミナルに接続用IPアドレス(同じPCからでしか、このアドレスには接続できません)が表示されたら、フロントエンドサーバの準備は完了です。
端末からの接続
フロントエンドサーバと同じPCからであれば、http://localhost:3000/にブラウザから接続することで、Webアプリに接続できます。
バックエンド(ローカルPCの場合)
バックエンドでは、./AdvancedLivePortrait_Nextjs/alp_backendをカレントディレクトリとして、それ以降のコマンドを実行してください。
バックエンドサーバの起動
下記コマンドを実行して、バックエンドサーバを立ち上げてください。
python run.py
ターミナルに緑の文字で接続用IPアドレス(このアドレスに接続しても接続できません)が表示されたら、バックエンドサーバの準備は完了です。
バックエンド(Google Colabの場合)
バックエンドサーバの起動
MyDrive/alp_backend/alp_api_backend.ipynb
を一番上のセルから全て実行してください。
(Google Driveの認証が入るので、承認してください)

ある程度時間はかかりますが、一番最後のセルにて、上記のような出力があります。
この出力が出たら、バックエンドサーバの準備は完了です。
ここで、下記のようなURLが表示されます。
PUBLIC_URL: https://cefb-xx-xxx-xxx-xxx.ngrok-free.app
このURLを.env.localに下記のように記載してください。
NEXT_PUBLIC_API_BASE_URL=https://cefb-xx-xxx-xxx-xxx.ngrok-free.app
使い方
共通
タブレットやPCなどから、フロントエンドサーバに接続すると下記のような画面が表示されます。

画面下部の「ファイルを選択」ボタンをクリックすることで、画像ファイルを選択できます。
こちらから、編集したい画像ファイルを選択してください。
そのあとは、記事トップで提示した動画のようにスライドバーを動かしたり、その右の数字を直接操作することで、画像を編集することができます。
まとめ
今回は、ポートレートの表情を編集する自作UIを「ComfyUI-AdvancedLivePortrait」の技術を使わせていただき、作ってみました。
「ComfyUI-AdvancedLivePortrait」をWebUIを使わずにプログラム上で実行する方法は、前回の記事で解説しましたので、そちらをご覧いただければと思います。
それでは、ここまで読んでくださりありがとうございました!
謝辞
こちらの実装コードを多分に使用させていただきました。
開発者様に感謝申し上げます。
コード
忘備録的につらつら書いています。
興味がない方は読み飛ばしてもらって構いません。
フロントエンドコード全文
AdvancedLivePortrait_Nextjs/src/app/page.tsx
"use client";
import { useState, useEffect, useCallback } from "react";
import debounce from "lodash/debounce";
export default function Home() {
const [image, setImage] = useState<File | null>(null);
const [preview, setPreview] = useState<string | null>(null);
const [loading, setLoading] = useState(false); // ローディング状態の管理
const [isUpdating, setIsUpdating] = useState(false); // 画像処理中でもスライダー操作を許可するためのフラグ
const [isInitializing, setIsInitializing] = useState(false); // 初期化処理中の状態を管理
// 環境変数からAPIベースURLを取得
const API_BASE_URL = process.env.NEXT_PUBLIC_API_BASE_URL;
// スライダーで調整するパラメータの状態を管理
const [params, setParams] = useState({
rotate_pitch: 0,
rotate_yaw: 0,
rotate_roll: 0,
blink: 0,
eyebrow: 0,
wink: 0,
pupil_x: 0,
pupil_y: 0,
aaa: 0,
eee: 0,
woo: 0,
smile: 0, // 初期値は0
});
const sliderDescriptions: { [key: string]: string } = {
rotate_pitch: "顔の縦方向の回転(前後)",
rotate_yaw: "顔の横方向の回転(左右)",
rotate_roll: "顔の傾き",
blink: "瞬きの度合い",
eyebrow: "眉毛の動き",
wink: "片目のウインク",
pupil_x: "瞳の左右の動き",
pupil_y: "瞳の上下の動き",
aaa: "口を開ける動作",
eee: "口を「イ」と発音する動作",
woo: "口を「ウ」と発音する動作",
smile: "笑顔の度合い(0.5 = 50%笑顔)",
};
// パラメータが変更された時に呼び出される関数
const handleParamChange = (e: React.ChangeEvent<HTMLInputElement>) => {
const { name, value } = e.target;
setParams((prevParams) => ({
...prevParams,
[name]: parseFloat(value),
}));
console.log(`Updated ${name} to ${value}`);
};
// APIに画像とパラメータを送信する非同期関数
const sendUpdateToBackend = useCallback(
debounce(async (newParams) => {
if (image) {
setIsUpdating(true); // 処理が開始されたことを示す
setLoading(true);
const formData = new FormData();
formData.append("file", image);
Object.keys(newParams).forEach((key) => {
formData.append(key, String(newParams[key as keyof typeof params]));
});
try {
const response = await fetch(`${API_BASE_URL}/edit`, {
method: "POST",
body: formData,
});
if (!response.ok) {
throw new Error(`API request failed with status ${response.status}`);
}
const blob = await response.blob();
const editedImageURL = URL.createObjectURL(blob);
setPreview(editedImageURL);
} catch (error) {
console.error("Error while sending API request:", error);
} finally {
setLoading(false); // ローディング終了
setIsUpdating(false); // 画像処理終了を示す
}
}
}, 200), // 500msの遅延を設定
[image, API_BASE_URL]
);
// パラメータが変更された時にdebounced処理を呼び出す
useEffect(() => {
if (image) {
sendUpdateToBackend(params);
}
}, [params, sendUpdateToBackend]);
// 初期化処理用のAPIリクエスト関数を追加
const initializeImage = async (imageFile: File) => {
const formData = new FormData();
formData.append("file", imageFile);
try {
setIsInitializing(true); // 初期化開始
const response = await fetch(`${API_BASE_URL}/initialize`, {
method: "POST",
body: formData,
});
if (!response.ok) {
throw new Error(`Initialization API request failed with status ${response.status}`);
}
const result = await response.json(); // JSONレスポンスを取得
console.log(result.message); // "初期化が完了しました" と表示されるはず
} catch (error) {
console.error("Error during initialization API request:", error);
} finally {
setIsInitializing(false); // 初期化終了
}
};
// 画像を選択した際にプレビューを表示するための関数
const handleImageChange = (e: React.ChangeEvent<HTMLInputElement>) => {
const file = e.target.files?.[0] || null;
setImage(file);
if (file) {
initializeImage(file);
const reader = new FileReader();
reader.onloadend = () => {
setPreview(reader.result as string);
};
reader.readAsDataURL(file);
}
};
// リセットボタンのハンドラー
const handleReset = () => {
setParams({
rotate_pitch: 0,
rotate_yaw: 0,
rotate_roll: 0,
blink: 0,
eyebrow: 0,
wink: 0,
pupil_x: 0,
pupil_y: 0,
aaa: 0,
eee: 0,
woo: 0,
smile: 0,
});
};
return (
<div className="container mx-auto p-4">
<h1 className="text-2xl font-bold mb-4">画像編集ツール</h1>
<div className="flex">
{/* 画像プレビュー */}
{preview && (
<img
src={preview}
alt="Preview"
className="mb-4 h-auto object-contain mr-8" // 画像の右側に空白を追加
/>
)}
{/* スライダーを縦に配置 */}
<div className="flex flex-col items-start justify-center w-1/2 space-y-4">
{Object.keys(params).map((param) => (
<div key={param} className="flex items-center space-x-4">
{/* スライダーの名称 */}
<label className="w-32">{param}</label>
{/* スライダー */}
<input
type="range"
name={param}
min={param === "smile" ? "-2" : "-20"} // smileだけ-2から2、他は-20から20
max={param === "smile" ? "2" : "20"}
step={param === "smile" ? "0.1" : "1"} // どちらも0.1ステップ
value={params[param as keyof typeof params]}
onChange={handleParamChange}
className="w-48 h-4" // スライダーの幅を広く、少し太く
disabled={isInitializing} // 初期化中はスライダーを無効化
/>
{/* 数値入力フィールド */}
<input
type="number"
name={param}
min={param === "smile" ? "-2" : "-20"} // smileだけ-2から2、他は-20から20
max={param === "smile" ? "2" : "20"}
step={param === "smile" ? "0.1" : "1"}
value={params[param as keyof typeof params]}
onChange={handleParamChange}
className="w-16 p-1 border rounded"
disabled={isInitializing} // 初期化中はスライダーを無効化
/>
{/* 補足説明 */}
<span className="text-gray-500">{sliderDescriptions[param]}</span>
</div>
))}
{/* リセットボタン */}
<button
onClick={handleReset}
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded mt-4"
disabled={isInitializing} // 初期化中はリセットボタンも無効化
>
リセット
</button>
</div>
</div>
{/* 画像アップロード */}
<input type="file" accept="image/*" onChange={handleImageChange} className="mt-4" />
{loading && <p>画像を処理中...</p>}
{isUpdating && !loading && <p>新しい画像を処理中...</p>}
</div>
);
}
バックエンド側において、処理に時間がかかるモデルのダウンロードや、顔範囲の検出などは初期化時(画像をアップロードしたタイミング)initializeImageに実行させています。
また、スライドバーを動かすと、バックエンド側連続でAPIにリクエストを送り続けることになりますが、少しでも負荷を軽減するためにデバウンス処理debounceを利用して、スライドバーが停止してから200ms後に一回だけリクエストを送るようにしています。
デバウンス処理に関しては、下記の記事でわかりやすく説明してくれています。
各種パラメータに関しては、基本的に-20から20の範囲をスライドバーが動くようになっているが、smileパラメータのみは-2から2になっています。
リセットボタンを押すと、全てのパラメータを一発で0にすることができます
バックエンドコード全文
AdvancedLivePortrait_Nextjs/alp_backend/run.py
import sys
sys.path.append("./ComfyUI-AdvancedLivePortrait")
from fastapi import FastAPI, UploadFile,File, Form
from fastapi import HTTPException
from fastapi.middleware.cors import CORSMiddleware
from PIL import Image
import io
import os
from fastapi.responses import FileResponse, JSONResponse, StreamingResponse
from module.advanced_live_portrait import AdvancedLivePortrait_execution_prepare, AdvancedLivePortrait_execution_main
app = FastAPI()
# CORSの設定
origins = [
"*" # フロントエンドのURLを指定
# 必要に応じて他のオリジンを追加
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"], # すべてのHTTPメソッドを許可
allow_headers=["*"], # すべてのヘッダーを許可
)
editor = None
img_tensor = None
prepared_face = None
@app.post("/initialize")
async def initialize_image_endpoint(file: UploadFile = File(...)):
global editor, img_tensor, prepared_face
# アップロードされた画像を一時ファイルに保存
input_image_path = f"./tmp/{file.filename}"
output_image_path = f"./tmp/initialized_{file.filename}"
os.makedirs(os.path.dirname(input_image_path), exist_ok=True)
with open(input_image_path, "wb") as f:
f.write(await file.read())
# 初期化処理を実行
editor, img_tensor, prepared_face = AdvancedLivePortrait_execution_prepare(input_image_path, output_image_path)
# 初期化完了メッセージを返す
return JSONResponse(content={"message": "初期化が完了しました", "status": "success"})
# 画像編集関数(AdvancedLivePortrait_executionのラッパー)
def edit_image(output_path, parameters):
# ここにAdvancedLivePortrait_execution関数を呼び出すコードを記載
# parametersはNext.jsから送られてくるパラメータ
edited_image_pil = AdvancedLivePortrait_execution_main(editor, img_tensor, prepared_face, output_path, parameters)
# メモリバッファに画像を保存
img_byte_arr = io.BytesIO()
edited_image_pil.save(img_byte_arr, format='PNG') # PNG形式で保存(JPEGでも可)
img_byte_arr.seek(0) # バッファの先頭にポインタを移動
return img_byte_arr
@app.post("/edit")
async def edit_image_endpoint(
file: UploadFile = File(...),
rotate_pitch: float = Form(0),
rotate_yaw: float = Form(0),
rotate_roll: float = Form(0),
blink: float = Form(0),
eyebrow: float = Form(0),
wink: float = Form(0),
pupil_x: float = Form(0),
pupil_y: float = Form(0),
aaa: float = Form(0),
eee: float = Form(0),
woo: float = Form(0),
smile: float = Form(0.5),
):
# アップロードされた画像を一時ファイルに保存
input_image_path = f"./tmp/{file.filename}"
output_image_path = f"./tmp/edited_{file.filename}"
with open(input_image_path, "wb") as f:
f.write(await file.read())
# パラメータをAdvancedLivePortrait_executionに渡して編集を行う
parameters = [
rotate_pitch, rotate_yaw, rotate_roll, blink, eyebrow, wink,
pupil_x, pupil_y, aaa, eee, woo, smile
]
print(f"Received parameters: {parameters}")
img_byte_arr = edit_image(output_image_path, parameters)
# 編集された画像を返す
#return FileResponse(output_image_path)
return StreamingResponse(img_byte_arr, media_type="image/png")
if __name__ == "__main__":
import uvicorn
uvicorn.run("run:app", host="0.0.0.0", port=8000, reload=True)
APIとしては@app.post("/initialize")と@app.post("/edit")の2つ実装しています。
フロント側で画像がアップロードされた時に@app.post("/initialize")は呼ばれ、顔検出モデルのダウンロードから顔検出までをあらかじめ実行します。
続いて、パラメータがフロント側で変更された時に、@app.post("/edit")は呼ばれ、画像の編集処理を行います。
処理済みの画像は、そのままフロントに送信されます。
AdvancedLivePortrait_Nextjs/alp_backend/module/advanced_live_portrait.py
import os
import sys
import numpy as np
import torch
import cv2
from PIL import Image
import time
import copy
import dill
import yaml
from ultralytics import YOLO
from module.utils import checkpoint_pickle
current_directory = "./ComfyUI-AdvancedLivePortrait"
models_dir = "./ComfyUI-AdvancedLivePortrait/models"
os.makedirs(models_dir, exist_ok=True)
import math
import struct
import safetensors.torch
import logging
import itertools
def load_torch_file(ckpt, safe_load=False, device=None):
if device is None:
device = torch.device("cpu")
if ckpt.lower().endswith(".safetensors") or ckpt.lower().endswith(".sft"):
sd = safetensors.torch.load_file(ckpt, device=device.type)
else:
if safe_load:
if not 'weights_only' in torch.load.__code__.co_varnames:
logging.warning("Warning torch.load doesn't support weights_only on this pytorch version, loading unsafely.")
safe_load = False
if safe_load:
pl_sd = torch.load(ckpt, map_location=device, weights_only=True)
else:
pl_sd = torch.load(ckpt, map_location=device, pickle_module=checkpoint_pickle)
if "global_step" in pl_sd:
logging.debug(f"Global Step: {pl_sd['global_step']}")
if "state_dict" in pl_sd:
sd = pl_sd["state_dict"]
else:
sd = pl_sd
return sd
from LivePortrait.live_portrait_wrapper import LivePortraitWrapper
from LivePortrait.utils.camera import get_rotation_matrix
from LivePortrait.config.inference_config import InferenceConfig
from LivePortrait.modules.spade_generator import SPADEDecoder
from LivePortrait.modules.warping_network import WarpingNetwork
from LivePortrait.modules.motion_extractor import MotionExtractor
from LivePortrait.modules.appearance_feature_extractor import AppearanceFeatureExtractor
from LivePortrait.modules.stitching_retargeting_network import StitchingRetargetingNetwork
from collections import OrderedDict
cur_device = None
def get_device():
global cur_device
if cur_device == None:
if torch.cuda.is_available():
cur_device = torch.device('cuda')
print("Uses CUDA device.")
"""elif torch.backends.mps.is_available():
cur_device = torch.device('mps')
print("Uses MPS device.")"""
else:
cur_device = torch.device('cpu')
print("Uses CPU device.")
return cur_device
def tensor2pil(image):
return Image.fromarray(np.clip(255. * image.cpu().numpy().squeeze(), 0, 255).astype(np.uint8))
def pil2tensor(image):
return torch.from_numpy(np.array(image).astype(np.float32) / 255.0).unsqueeze(0)
def rgb_crop(rgb, region):
return rgb[region[1]:region[3], region[0]:region[2]]
def rgb_crop_batch(rgbs, region):
return rgbs[:, region[1]:region[3], region[0]:region[2]]
def get_rgb_size(rgb):
return rgb.shape[1], rgb.shape[0]
def create_transform_matrix(x, y, s_x, s_y):
return np.float32([[s_x, 0, x], [0, s_y, y]])
def get_model_dir(m):
return os.path.join(models_dir, m)
def calc_crop_limit(center, img_size, crop_size):
pos = center - crop_size / 2
if pos < 0:
crop_size += pos * 2
pos = 0
pos2 = pos + crop_size
if img_size < pos2:
crop_size -= (pos2 - img_size) * 2
pos2 = img_size
pos = pos2 - crop_size
return pos, pos2, crop_size
def retargeting(delta_out, driving_exp, factor, idxes):
for idx in idxes:
#delta_out[0, idx] -= src_exp[0, idx] * factor
delta_out[0, idx] += driving_exp[0, idx] * factor
class PreparedSrcImg:
def __init__(self, src_rgb, crop_trans_m, x_s_info, f_s_user, x_s_user, mask_ori):
self.src_rgb = src_rgb
self.crop_trans_m = crop_trans_m
self.x_s_info = x_s_info
self.f_s_user = f_s_user
self.x_s_user = x_s_user
self.mask_ori = mask_ori
import requests
from tqdm import tqdm
class LP_Engine:
pipeline = None
detect_model = None
mask_img = None
temp_img_idx = 0
def get_temp_img_name(self):
self.temp_img_idx += 1
return "expression_edit_preview" + str(self.temp_img_idx) + ".png"
def download_model(_, file_path, model_url):
print('AdvancedLivePortrait: Downloading model...')
response = requests.get(model_url, stream=True)
try:
if response.status_code == 200:
total_size = int(response.headers.get('content-length', 0))
block_size = 1024 # 1 Kibibyte
# tqdm will display a progress bar
with open(file_path, 'wb') as file, tqdm(
desc='Downloading',
total=total_size,
unit='iB',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in response.iter_content(block_size):
bar.update(len(data))
file.write(data)
except requests.exceptions.RequestException as err:
print('AdvancedLivePortrait: Model download failed: {err}')
print(f'AdvancedLivePortrait: Download it manually from: {model_url}')
print(f'AdvancedLivePortrait: And put it in {file_path}')
except Exception as e:
print(f'AdvancedLivePortrait: An unexpected error occurred: {e}')
def remove_ddp_dumplicate_key(_, state_dict):
state_dict_new = OrderedDict()
for key in state_dict.keys():
state_dict_new[key.replace('module.', '')] = state_dict[key]
return state_dict_new
def filter_for_model(_, checkpoint, prefix):
filtered_checkpoint = {key.replace(prefix + "_module.", ""): value for key, value in checkpoint.items() if
key.startswith(prefix)}
return filtered_checkpoint
def load_model(self, model_config, model_type):
device = get_device()
if model_type == 'stitching_retargeting_module':
ckpt_path = os.path.join(get_model_dir("liveportrait"), "retargeting_models", model_type + ".pth")
else:
ckpt_path = os.path.join(get_model_dir("liveportrait"), "base_models", model_type + ".pth")
is_safetensors = None
if os.path.isfile(ckpt_path) == False:
is_safetensors = True
ckpt_path = os.path.join(get_model_dir("liveportrait"), model_type + ".safetensors")
if os.path.isfile(ckpt_path) == False:
self.download_model(ckpt_path,
"https://huggingface.co/Kijai/LivePortrait_safetensors/resolve/main/" + model_type + ".safetensors")
model_params = model_config['model_params'][f'{model_type}_params']
if model_type == 'appearance_feature_extractor':
model = AppearanceFeatureExtractor(**model_params).to(device)
elif model_type == 'motion_extractor':
model = MotionExtractor(**model_params).to(device)
elif model_type == 'warping_module':
model = WarpingNetwork(**model_params).to(device)
elif model_type == 'spade_generator':
model = SPADEDecoder(**model_params).to(device)
elif model_type == 'stitching_retargeting_module':
# Special handling for stitching and retargeting module
config = model_config['model_params']['stitching_retargeting_module_params']
checkpoint = load_torch_file(ckpt_path)
stitcher = StitchingRetargetingNetwork(**config.get('stitching'))
if is_safetensors:
stitcher.load_state_dict(self.filter_for_model(checkpoint, 'retarget_shoulder'))
else:
stitcher.load_state_dict(self.remove_ddp_dumplicate_key(checkpoint['retarget_shoulder']))
stitcher = stitcher.to(device)
stitcher.eval()
return {
'stitching': stitcher,
}
else:
raise ValueError(f"Unknown model type: {model_type}")
model.load_state_dict(load_torch_file(ckpt_path))
model.eval()
return model
def load_models(self):
model_path = get_model_dir("liveportrait")
if not os.path.exists(model_path):
os.mkdir(model_path)
model_config_path = os.path.join(current_directory, 'LivePortrait', 'config', 'models.yaml')
model_config = yaml.safe_load(open(model_config_path, 'r'))
appearance_feature_extractor = self.load_model(model_config, 'appearance_feature_extractor')
motion_extractor = self.load_model(model_config, 'motion_extractor')
warping_module = self.load_model(model_config, 'warping_module')
spade_generator = self.load_model(model_config, 'spade_generator')
stitching_retargeting_module = self.load_model(model_config, 'stitching_retargeting_module')
self.pipeline = LivePortraitWrapper(InferenceConfig(), appearance_feature_extractor, motion_extractor, warping_module, spade_generator, stitching_retargeting_module)
def get_detect_model(self):
if self.detect_model == None:
model_dir = get_model_dir("ultralytics")
if not os.path.exists(model_dir): os.mkdir(model_dir)
model_path = os.path.join(model_dir, "face_yolov8n.pt")
if not os.path.exists(model_path):
self.download_model(model_path, "https://huggingface.co/Bingsu/adetailer/resolve/main/face_yolov8n.pt")
self.detect_model = YOLO(model_path)
return self.detect_model
def resize_image_to_stride(self,image_tensor, stride=32):
# 画像の高さと幅を取得
_, _, h, w = image_tensor.shape
# ストライドで割り切れるサイズにリサイズする
new_h = (h // stride) * stride
new_w = (w // stride) * stride
# テンソルを NumPy に変換してリサイズ
image_np = image_tensor.squeeze(0).permute(1, 2, 0).cpu().numpy() # (B, C, H, W) -> (H, W, C)
resized_image_np = cv2.resize(image_np, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
# リサイズされた画像をテンソルに戻す
resized_image_tensor = torch.from_numpy(resized_image_np).permute(2, 0, 1).unsqueeze(0).float() # (H, W, C) -> (B, C, H, W)
return resized_image_tensor
def get_face_bboxes(self, image_rgb):
detect_model = self.get_detect_model()
# 画像が正しく読み込まれているかチェック
if image_rgb is None or image_rgb.size == 0:
raise ValueError("The input image is empty or invalid.")
# 画像が3チャンネル (RGB) であることを確認
if len(image_rgb.shape) == 2: # もしグレースケール画像の場合、3チャンネルに変換
image_rgb = cv2.cvtColor(image_rgb, cv2.COLOR_GRAY2RGB)
elif len(image_rgb.shape) == 3 and image_rgb.shape[2] == 1: # 1チャンネル (モノクロ画像) も3チャンネルに変換
image_rgb = cv2.cvtColor(image_rgb, cv2.COLOR_GRAY2RGB)
# 画像が正しい次元か確認し、4次元に拡張 (YOLOが期待するバッチ形式)
if len(image_rgb.shape) == 3:
image_rgb = np.expand_dims(image_rgb, axis=0) # (height, width, 3) -> (1, height, width, 3)
# 次元を (batch_size, channels, height, width) の形式に変換
image_rgb = torch.from_numpy(image_rgb).permute(0, 3, 1, 2).float() # (1, height, width, 3) -> (1, 3, height, width)
# 0-255の範囲のピクセル値を0-1に正規化
image_rgb /= 255.0
# デバッグ用にサイズを確認
print(f"Image dimensions before YOLO: {image_rgb.shape}")
image_rgb = self.resize_image_to_stride(image_rgb, stride=32)
pred = detect_model(image_rgb, conf=0.7, device="") # YOLOモデルに入力
return pred[0].boxes.xyxy.cpu().numpy() # 検出したバウンディングボックスを返す
def detect_face(self, image_rgb, crop_factor, sort = True):
bboxes = self.get_face_bboxes(image_rgb)
w, h = get_rgb_size(image_rgb)
print(f"w, h:{w, h}")
cx = w / 2
min_diff = w
best_box = None
for x1, y1, x2, y2 in bboxes:
bbox_w = x2 - x1
if bbox_w < 30: continue
diff = abs(cx - (x1 + bbox_w / 2))
if diff < min_diff:
best_box = [x1, y1, x2, y2]
print(f"diff, min_diff, best_box:{diff, min_diff, best_box}")
min_diff = diff
if best_box == None:
print("Failed to detect face!!")
return [0, 0, w, h]
x1, y1, x2, y2 = best_box
#for x1, y1, x2, y2 in bboxes:
bbox_w = x2 - x1
bbox_h = y2 - y1
crop_w = bbox_w * crop_factor
crop_h = bbox_h * crop_factor
crop_w = max(crop_h, crop_w)
crop_h = crop_w
kernel_x = int(x1 + bbox_w / 2)
kernel_y = int(y1 + bbox_h / 2)
new_x1 = int(kernel_x - crop_w / 2)
new_x2 = int(kernel_x + crop_w / 2)
new_y1 = int(kernel_y - crop_h / 2)
new_y2 = int(kernel_y + crop_h / 2)
if not sort:
return [int(new_x1), int(new_y1), int(new_x2), int(new_y2)]
if new_x1 < 0:
new_x2 -= new_x1
new_x1 = 0
elif w < new_x2:
new_x1 -= (new_x2 - w)
new_x2 = w
if new_x1 < 0:
new_x2 -= new_x1
new_x1 = 0
if new_y1 < 0:
new_y2 -= new_y1
new_y1 = 0
elif h < new_y2:
new_y1 -= (new_y2 - h)
new_y2 = h
if new_y1 < 0:
new_y2 -= new_y1
new_y1 = 0
if w < new_x2 and h < new_y2:
over_x = new_x2 - w
over_y = new_y2 - h
over_min = min(over_x, over_y)
new_x2 -= over_min
new_y2 -= over_min
return [int(new_x1), int(new_y1), int(new_x2), int(new_y2)]
def calc_face_region(self, square, dsize):
region = copy.deepcopy(square)
is_changed = False
if dsize[0] < region[2]:
region[2] = dsize[0]
is_changed = True
if dsize[1] < region[3]:
region[3] = dsize[1]
is_changed = True
return region, is_changed
def expand_img(self, rgb_img, square):
crop_trans_m = create_transform_matrix(max(-square[0], 0), max(-square[1], 0), 1, 1)
new_img = cv2.warpAffine(rgb_img, crop_trans_m, (square[2] - square[0], square[3] - square[1]),
cv2.INTER_LINEAR)
return new_img
def get_pipeline(self):
if self.pipeline == None:
print("Load pipeline...")
self.load_models()
return self.pipeline
def prepare_src_image(self, img):
h, w = img.shape[:2]
input_shape = [256,256]
if h != input_shape[0] or w != input_shape[1]:
if 256 < h: interpolation = cv2.INTER_AREA
else: interpolation = cv2.INTER_LINEAR
x = cv2.resize(img, (input_shape[0], input_shape[1]), interpolation = interpolation)
else:
x = img.copy()
if x.ndim == 3:
x = x[np.newaxis].astype(np.float32) / 255. # HxWx3 -> 1xHxWx3, normalized to 0~1
elif x.ndim == 4:
x = x.astype(np.float32) / 255. # BxHxWx3, normalized to 0~1
else:
raise ValueError(f'img ndim should be 3 or 4: {x.ndim}')
x = np.clip(x, 0, 1) # clip to 0~1
x = torch.from_numpy(x).permute(0, 3, 1, 2) # 1xHxWx3 -> 1x3xHxW
x = x.to(get_device())
return x
def GetMaskImg(self):
if self.mask_img is None:
path = os.path.join(current_directory, "LivePortrait/utils/resources/mask_template.png")
self.mask_img = cv2.imread(path, cv2.IMREAD_COLOR)
if self.mask_img is None:
raise FileNotFoundError(f"Mask image not found at path: {path}")
return self.mask_img
def crop_face(self, img_rgb, crop_factor):
crop_region = self.detect_face(img_rgb, crop_factor)
face_region, is_changed = self.calc_face_region(crop_region, get_rgb_size(img_rgb))
face_img = rgb_crop(img_rgb, face_region)
if is_changed: face_img = self.expand_img(face_img, crop_region)
return face_img
def prepare_source(self, source_image, crop_factor, is_video = False, tracking = False):
print("Prepare source...")
engine = self.get_pipeline()
source_image_np = (source_image * 255).byte().cpu().numpy()
img_rgb = source_image_np[0]
psi_list = []
for img_rgb in source_image_np:
if tracking or len(psi_list) == 0:
crop_region = self.detect_face(img_rgb, crop_factor)
face_region, is_changed = self.calc_face_region(crop_region, get_rgb_size(img_rgb))
s_x = (face_region[2] - face_region[0]) / 512.
s_y = (face_region[3] - face_region[1]) / 512.
crop_trans_m = create_transform_matrix(crop_region[0], crop_region[1], s_x, s_y)
mask_ori = cv2.warpAffine(self.GetMaskImg(), crop_trans_m, get_rgb_size(img_rgb), cv2.INTER_LINEAR)
mask_ori = mask_ori.astype(np.float32) / 255.
if is_changed:
s = (crop_region[2] - crop_region[0]) / 512.
crop_trans_m = create_transform_matrix(crop_region[0], crop_region[1], s, s)
face_img = rgb_crop(img_rgb, face_region)
if is_changed: face_img = self.expand_img(face_img, crop_region)
i_s = self.prepare_src_image(face_img)
x_s_info = engine.get_kp_info(i_s)
f_s_user = engine.extract_feature_3d(i_s)
x_s_user = engine.transform_keypoint(x_s_info)
psi = PreparedSrcImg(img_rgb, crop_trans_m, x_s_info, f_s_user, x_s_user, mask_ori)
if is_video == False:
return psi
psi_list.append(psi)
return psi_list
def prepare_driving_video(self, face_images):
print("Prepare driving video...")
pipeline = self.get_pipeline()
f_img_np = (face_images * 255).byte().numpy()
out_list = []
for f_img in f_img_np:
i_d = self.prepare_src_image(f_img)
d_info = pipeline.get_kp_info(i_d)
out_list.append(d_info)
return out_list
def calc_fe(_, x_d_new, eyes, eyebrow, wink, pupil_x, pupil_y, mouth, eee, woo, smile,
rotate_pitch, rotate_yaw, rotate_roll):
x_d_new[0, 20, 1] += smile * -0.01
x_d_new[0, 14, 1] += smile * -0.02
x_d_new[0, 17, 1] += smile * 0.0065
x_d_new[0, 17, 2] += smile * 0.003
x_d_new[0, 13, 1] += smile * -0.00275
x_d_new[0, 16, 1] += smile * -0.00275
x_d_new[0, 3, 1] += smile * -0.0035
x_d_new[0, 7, 1] += smile * -0.0035
x_d_new[0, 19, 1] += mouth * 0.001
x_d_new[0, 19, 2] += mouth * 0.0001
x_d_new[0, 17, 1] += mouth * -0.0001
rotate_pitch -= mouth * 0.05
x_d_new[0, 20, 2] += eee * -0.001
x_d_new[0, 20, 1] += eee * -0.001
#x_d_new[0, 19, 1] += eee * 0.0006
x_d_new[0, 14, 1] += eee * -0.001
x_d_new[0, 14, 1] += woo * 0.001
x_d_new[0, 3, 1] += woo * -0.0005
x_d_new[0, 7, 1] += woo * -0.0005
x_d_new[0, 17, 2] += woo * -0.0005
x_d_new[0, 11, 1] += wink * 0.001
x_d_new[0, 13, 1] += wink * -0.0003
x_d_new[0, 17, 0] += wink * 0.0003
x_d_new[0, 17, 1] += wink * 0.0003
x_d_new[0, 3, 1] += wink * -0.0003
rotate_roll -= wink * 0.1
rotate_yaw -= wink * 0.1
if 0 < pupil_x:
x_d_new[0, 11, 0] += pupil_x * 0.0007
x_d_new[0, 15, 0] += pupil_x * 0.001
else:
x_d_new[0, 11, 0] += pupil_x * 0.001
x_d_new[0, 15, 0] += pupil_x * 0.0007
x_d_new[0, 11, 1] += pupil_y * -0.001
x_d_new[0, 15, 1] += pupil_y * -0.001
eyes -= pupil_y / 2.
x_d_new[0, 11, 1] += eyes * -0.001
x_d_new[0, 13, 1] += eyes * 0.0003
x_d_new[0, 15, 1] += eyes * -0.001
x_d_new[0, 16, 1] += eyes * 0.0003
x_d_new[0, 1, 1] += eyes * -0.00025
x_d_new[0, 2, 1] += eyes * 0.00025
if 0 < eyebrow:
x_d_new[0, 1, 1] += eyebrow * 0.001
x_d_new[0, 2, 1] += eyebrow * -0.001
else:
x_d_new[0, 1, 0] += eyebrow * -0.001
x_d_new[0, 2, 0] += eyebrow * 0.001
x_d_new[0, 1, 1] += eyebrow * 0.0003
x_d_new[0, 2, 1] += eyebrow * -0.0003
return torch.Tensor([rotate_pitch, rotate_yaw, rotate_roll])
g_engine = LP_Engine()
class ExpressionSet:
def __init__(self, erst = None, es = None):
if es != None:
self.e = copy.deepcopy(es.e) # [:, :, :]
self.r = copy.deepcopy(es.r) # [:]
self.s = copy.deepcopy(es.s)
self.t = copy.deepcopy(es.t)
elif erst != None:
self.e = erst[0]
self.r = erst[1]
self.s = erst[2]
self.t = erst[3]
else:
self.e = torch.from_numpy(np.zeros((1, 21, 3))).float().to(get_device())
self.r = torch.Tensor([0, 0, 0])
self.s = 0
self.t = 0
def div(self, value):
self.e /= value
self.r /= value
self.s /= value
self.t /= value
def add(self, other):
self.e += other.e
self.r += other.r
self.s += other.s
self.t += other.t
def sub(self, other):
self.e -= other.e
self.r -= other.r
self.s -= other.s
self.t -= other.t
def mul(self, value):
self.e *= value
self.r *= value
self.s *= value
self.t *= value
#def apply_ratio(self, ratio): self.exp *= ratio
def logging_time(original_fn):
def wrapper_fn(*args, **kwargs):
start_time = time.time()
result = original_fn(*args, **kwargs)
end_time = time.time()
print("WorkingTime[{}]: {} sec".format(original_fn.__name__, end_time - start_time))
return result
return wrapper_fn
class Command:
def __init__(self, es, change, keep):
self.es:ExpressionSet = es
self.change = change
self.keep = keep
crop_factor_default = 1.7
crop_factor_min = 1.5
crop_factor_max = 2.5
class AdvancedLivePortrait:
def __init__(self):
self.src_images = None
self.driving_images = None
self.crop_factor = None
def parsing_command(self, command, motoin_link):
command.replace(' ', '')
# if command == '': return
lines = command.split('\n')
cmd_list = []
total_length = 0
i = 0
#old_es = None
for line in lines:
i += 1
if line == '': continue
try:
cmds = line.split('=')
idx = int(cmds[0])
if idx == 0: es = ExpressionSet()
else: es = ExpressionSet(es = motoin_link[idx])
cmds = cmds[1].split(':')
change = int(cmds[0])
keep = int(cmds[1])
except:
assert False, f"(AdvancedLivePortrait) Command Err Line {i}: {line}"
return None, None
total_length += change + keep
es.div(change)
cmd_list.append(Command(es, change, keep))
return cmd_list, total_length
def run(self, retargeting_eyes, retargeting_mouth, turn_on, tracking_src_vid, animate_without_vid, command, crop_factor,
src_images=None, driving_images=None, motion_link=None):
if turn_on == False: return (None,None)
src_length = 1
if src_images == None:
if motion_link != None:
self.psi_list = [motion_link[0]]
else: return (None,None)
if src_images != None:
src_length = len(src_images)
if id(src_images) != id(self.src_images) or self.crop_factor != crop_factor:
self.crop_factor = crop_factor
self.src_images = src_images
if 1 < src_length:
self.psi_list = g_engine.prepare_source(src_images, crop_factor, True, tracking_src_vid)
else:
self.psi_list = [g_engine.prepare_source(src_images, crop_factor)]
cmd_list, cmd_length = self.parsing_command(command, motion_link)
if cmd_list == None: return (None,None)
cmd_idx = 0
driving_length = 0
if driving_images is not None:
if id(driving_images) != id(self.driving_images):
self.driving_images = driving_images
self.driving_values = g_engine.prepare_driving_video(driving_images)
driving_length = len(self.driving_values)
total_length = max(driving_length, src_length)
if animate_without_vid:
total_length = max(total_length, cmd_length)
c_i_es = ExpressionSet()
c_o_es = ExpressionSet()
d_0_es = None
out_list = []
psi = None
pipeline = g_engine.get_pipeline()
for i in range(total_length):
if i < src_length:
psi = self.psi_list[i]
s_info = psi.x_s_info
s_es = ExpressionSet(erst=(s_info['kp'] + s_info['exp'], torch.Tensor([0, 0, 0]), s_info['scale'], s_info['t']))
new_es = ExpressionSet(es = s_es)
if i < cmd_length:
cmd = cmd_list[cmd_idx]
if 0 < cmd.change:
cmd.change -= 1
c_i_es.add(cmd.es)
c_i_es.sub(c_o_es)
elif 0 < cmd.keep:
cmd.keep -= 1
new_es.add(c_i_es)
if cmd.change == 0 and cmd.keep == 0:
cmd_idx += 1
if cmd_idx < len(cmd_list):
c_o_es = ExpressionSet(es = c_i_es)
cmd = cmd_list[cmd_idx]
c_o_es.div(cmd.change)
elif 0 < cmd_length:
new_es.add(c_i_es)
if i < driving_length:
d_i_info = self.driving_values[i]
d_i_r = torch.Tensor([d_i_info['pitch'], d_i_info['yaw'], d_i_info['roll']])#.float().to(device="cuda:0")
if d_0_es is None:
d_0_es = ExpressionSet(erst = (d_i_info['exp'], d_i_r, d_i_info['scale'], d_i_info['t']))
retargeting(s_es.e, d_0_es.e, retargeting_eyes, (11, 13, 15, 16))
retargeting(s_es.e, d_0_es.e, retargeting_mouth, (14, 17, 19, 20))
new_es.e += d_i_info['exp'] - d_0_es.e
new_es.r += d_i_r - d_0_es.r
new_es.t += d_i_info['t'] - d_0_es.t
r_new = get_rotation_matrix(
s_info['pitch'] + new_es.r[0], s_info['yaw'] + new_es.r[1], s_info['roll'] + new_es.r[2])
d_new = new_es.s * (new_es.e @ r_new) + new_es.t
d_new = pipeline.stitching(psi.x_s_user, d_new)
crop_out = pipeline.warp_decode(psi.f_s_user, psi.x_s_user, d_new)
crop_out = pipeline.parse_output(crop_out['out'])[0]
crop_with_fullsize = cv2.warpAffine(crop_out, psi.crop_trans_m, get_rgb_size(psi.src_rgb),
cv2.INTER_LINEAR)
out = np.clip(psi.mask_ori * crop_with_fullsize + (1 - psi.mask_ori) * psi.src_rgb, 0, 255).astype(
np.uint8)
out_list.append(out)
if len(out_list) == 0: return (None,)
out_imgs = torch.cat([pil2tensor(img_rgb) for img_rgb in out_list])
return (out_imgs,)
class ExpressionEditor_modify:
def __init__(self):
self.sample_image = None
self.src_image = None
self.crop_factor = None
def run(self, prepared_face, rotate_pitch, rotate_yaw, rotate_roll, blink, eyebrow, wink, pupil_x, pupil_y, aaa, eee, woo, smile,
src_ratio, sample_ratio, sample_parts, crop_factor, src_image=None, sample_image=None, motion_link=None, add_exp=None):
rotate_yaw = -rotate_yaw
self.psi = prepared_face
self.crop_factor = crop_factor
self.src_image = src_image
new_editor_link = []
new_editor_link.append(self.psi)
pipeline = g_engine.get_pipeline()
psi = self.psi
s_info = psi.x_s_info
#delta_new = copy.deepcopy()
s_exp = s_info['exp'] * src_ratio
s_exp[0, 5] = s_info['exp'][0, 5]
s_exp += s_info['kp']
es = ExpressionSet()
if sample_image != None:
if id(self.sample_image) != id(sample_image):
self.sample_image = sample_image
d_image_np = (sample_image * 255).byte().numpy()
d_face = g_engine.crop_face(d_image_np[0], 1.7)
i_d = g_engine.prepare_src_image(d_face)
self.d_info = pipeline.get_kp_info(i_d)
self.d_info['exp'][0, 5, 0] = 0
self.d_info['exp'][0, 5, 1] = 0
# "OnlyExpression", "OnlyRotation", "OnlyMouth", "OnlyEyes", "All"
if sample_parts == "OnlyExpression" or sample_parts == "All":
es.e += self.d_info['exp'] * sample_ratio
if sample_parts == "OnlyRotation" or sample_parts == "All":
rotate_pitch += self.d_info['pitch'] * sample_ratio
rotate_yaw += self.d_info['yaw'] * sample_ratio
rotate_roll += self.d_info['roll'] * sample_ratio
elif sample_parts == "OnlyMouth":
retargeting(es.e, self.d_info['exp'], sample_ratio, (14, 17, 19, 20))
elif sample_parts == "OnlyEyes":
retargeting(es.e, self.d_info['exp'], sample_ratio, (1, 2, 11, 13, 15, 16))
es.r = g_engine.calc_fe(es.e, blink, eyebrow, wink, pupil_x, pupil_y, aaa, eee, woo, smile,
rotate_pitch, rotate_yaw, rotate_roll)
if add_exp != None:
es.add(add_exp)
new_rotate = get_rotation_matrix(s_info['pitch'] + es.r[0], s_info['yaw'] + es.r[1],
s_info['roll'] + es.r[2])
x_d_new = (s_info['scale'] * (1 + es.s)) * ((s_exp + es.e) @ new_rotate) + s_info['t']
x_d_new = pipeline.stitching(psi.x_s_user, x_d_new)
crop_out = pipeline.warp_decode(psi.f_s_user, psi.x_s_user, x_d_new)
crop_out = pipeline.parse_output(crop_out['out'])[0]
crop_with_fullsize = cv2.warpAffine(crop_out, psi.crop_trans_m, get_rgb_size(psi.src_rgb), cv2.INTER_LINEAR)
out = np.clip(psi.mask_ori * crop_with_fullsize + (1 - psi.mask_ori) * psi.src_rgb, 0, 255).astype(np.uint8)
out_img = pil2tensor(out)
filename = g_engine.get_temp_img_name() #"fe_edit_preview.png"
results = list()
results.append({"filename": filename, "type": "temp"})
new_editor_link.append(es)
return {"result": (out_img, new_editor_link, es)}
def AdvancedLivePortrait_execution_prepare(input_image_path, output_image_path):
# 入力画像のパスを指定します
if not os.path.exists(os.path.dirname(output_image_path)):
os.makedirs(os.path.dirname(output_image_path))
# 顔を含む画像を読み込む
image = Image.open(input_image_path)
image = image.convert("RGB")
print(image.size)
img_tensor = pil2tensor(image).to(get_device()) # 画像をテンソルに変換し、GPUに転送
print(img_tensor.shape)
print("load image")
# LP_Engineクラスのインスタンス作成
engine = LP_Engine()
print("load LP_Engine")
# 顔の検出と準備
crop_factor = 1.7 # 顔のクロップサイズ
prepared_face = engine.prepare_source(img_tensor, crop_factor) # 顔の準備
# 表情を編集するためのExpressionEditorクラスのインスタンスを作成
editor = ExpressionEditor_modify()
print("load ExpressionEditor")
return editor, img_tensor, prepared_face
def AdvancedLivePortrait_execution_main(editor, img_tensor, prepared_face, output_image_path, parameters):
# 表情を変更するための設定
rotate_pitch = parameters[0] # 顔の縦方向の回転(前後)
rotate_yaw = parameters[1] # 顔の横方向の回転(左右)
rotate_roll = parameters[2] # 顔の傾き
blink = parameters[3] # 瞬きの度合い
eyebrow = parameters[4] # 眉毛の動き
wink = parameters[5] # 片目のウインク
pupil_x = parameters[6] # 瞳の左右の動き
pupil_y = parameters[7] # 瞳の上下の動き
aaa = parameters[8] # 口を開ける動作
eee = parameters[9] # 口を「イ」と発音する動作
woo = parameters[10] # 口を「ウ」と発音する動作
smile = parameters[11] # 笑顔の度合い(0.5 = 50%笑顔)
print("start running")
mainprocess_time = time.time()
# 表情を編集し、結果の画像を取得
result = editor.run(prepared_face,
rotate_pitch, rotate_yaw, rotate_roll,
blink, eyebrow, wink, pupil_x, pupil_y,
aaa, eee, woo, smile,
src_ratio=1, sample_ratio=1,
sample_parts="All", # 全体的な表情を編集する
crop_factor=1.7,
src_image=img_tensor # 先ほど準備した顔画像を指定
)
print("メイン処理実行時間:", time.time() - mainprocess_time)
# 結果を展開
edited_img, motion_link, expression_data = result["result"]
print("finish running")
# 結果の画像を保存する
edited_image_pil = tensor2pil(edited_img) # テンソルをPIL画像に変換
#edited_image_pil.save(output_image_path)
#print(f"Edited image saved at: {output_image_path}")
return edited_image_pil
基本的には前回の記事と同様です
しかし、処理速度を高速化させるために、顔検出部分と顔編集部分をAdvancedLivePortrait_execution_prepareとAdvancedLivePortrait_execution_mainの二つの関数に分けました。
Discussion