LangGraphを使ってAIエージェントを実装する方法
はじめに
先日Difyというツールを利用して、AIエージェントを実装する方法についての記事を書きました。
Difyは非常に簡単に、LLMを利用したAIエージェントやワークフローを作成することができ、それを既存のWebアプリに埋め込んだり、APIで実行するのも非常に簡単です。
ただ、私は宗教上の理由で、WebUIは利用できない()ので、同様のことをPython上でも実装してみようと思います。
LangGraph
LangGraphとはLangChain上に構築されているツールの一つで、Difyと同様にLLMを利用した複雑なワークフローやAIエージェントを構築することができるフレームワークです。
基本的にはDifyでできることは全部でき、LLMモデルに依存せず、同じ書き方で利用できます。
また、LangChainの機能の一つではありますが、AIエージェントの構築という観点では、必ずしもLangChainを利用してLLMを動作させる必要はなく、各LLMプロバイダのネイティブな記述を利用することも可能です。
さらに、Difyと比較すると、低レベルなフレームワークになるため、アプリケーションのフローや状態を非常に自由度高く記述することが可能です。
その代わりDifyと比較すると学習コストは高いです。
ただ、それでもLangGraphを使わずに、コードベースでAIエージェントを実現することに比べれば、全然簡単に実装できますし、ある程度コードが書ける人なら、すぐに使えるようになるはずです。
ちなみに、11月9日にLangGraphに関する専門的な書籍が出版されるようです!楽しみですね。
LangChainとLangGraphによるRAG・AIエージェント[実践]入門 (エンジニア選書)
前提条件
使う環境
今回は、Google Colabの環境を利用します。
LLMの処理は全てAzureのOpenAI APIを利用するため、GPUでの処理をする必要がないため、ほぼ無制限にGoogle Colabの環境を利用できます。
(ありがたいですね)
利用する生成AI
今回は、Azure OpenAI APIを利用して、gpt-4oを例として記事を記載します。
他のモデル(gpt-4o-miniなど)や他の生成AIプロバイダ(AnthropicのClaudeやGoogleのgeminiなど)、ローカルLLM(LLaMaなど)を利用することももちろんできますが、その場合はモデル定義の箇所を適切に変更いただく必要があります。
作成するAIエージェント
前回Difyで作ったものと同じものを実装するため、詳細は前回の記事をご覧いただけますと幸いですが、簡単に説明します。
今回作成するのは、「今日、明日、明後日」の日付の範囲内で、「天気」もしくは「日付」に関してのユーザ質問を回答するAIエージェントです。
より具体的には、まず、下記の3つのワークフローを作成します。
- tool01
- ユーザの質問が「天気に関する質問」か「日付に関する質問」かを前段のLLMが判定して、条件分岐を行い、後段の「今日の天気回答専門LLM」と『今日の日付回答専門LLM」が設定されているSYSTEMプロンプトの情報(今日のダミー日付と今日のダミー天気)に則って回答を行います。
- tool02
- tool01とほぼ同様ですが、「明日」の天気・日付を回答します。
- tool03
- tool01とほぼ同様ですが、「明後日」の天気・日付を回答します。
続いて、上記のワークフローを束ねるAIエージェントを構築します。
エージェントはユーザの質問が
「今日に関する質問」なら「tool01」ワークフローを
「明日に関する質問」なら「tool02」ワークフローを
「明後日に関する質問」なら「tool03」ワークフローを起動して、
ユーザの質問内容を、起動したワークフローに流し込んで回答を取得し、その結果をユーザに回答します。
イメージとしては下記のような感じです。
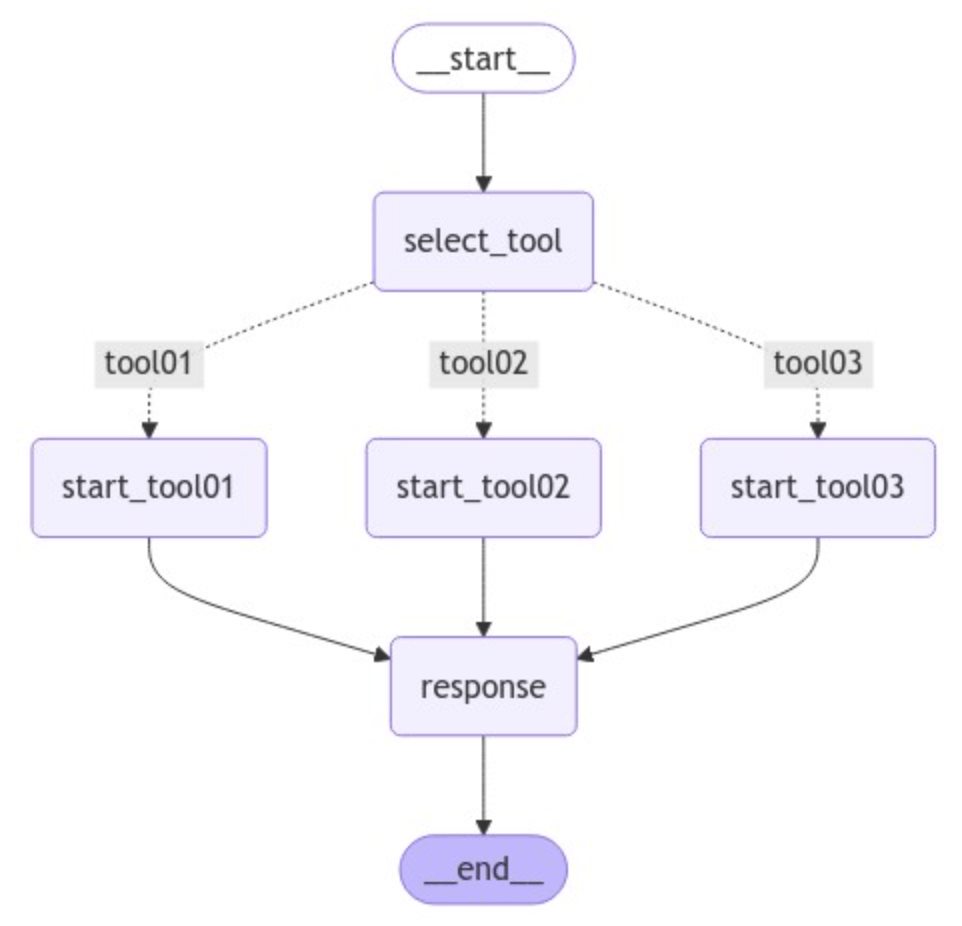
(それぞれのtoolがワークフローになります)
成果物
今回は普通にGoogle Colabのipynbなので、そのままコードを公開します。
下記リポジトリをご覧ください。
また、実際にGoogle Colabを実行すると下記のようにAIエージェントを利用できます。
実行方法
事前準備
AIを呼び出すための準備
今回はAzureのOpenAI APIを利用するため、下記の情報が必要です。
- エンドポイント
- API KEY
- API VERSION
これらの情報を準備してください。
ノートブック中に記載する箇所がございます
ノードブックをドライブに格納する
上記の「colab_LangGraph_sample.ipynb」をダウンロード(もしくはクローン)して、Google Driveの好きな場所にアップロードしてください。
その後、Google Colabratoryとして起動してください。
下記のような画面になればOKです。
取得した情報をノートブック内に記載する
2セル目の下記の部分に、事前準備で取得した「OPENAI_API_VERSION」と「AZURE_OPENAI_ENDPOINT」と「AZURE_OPENAI_API_KEY」を記載してください。
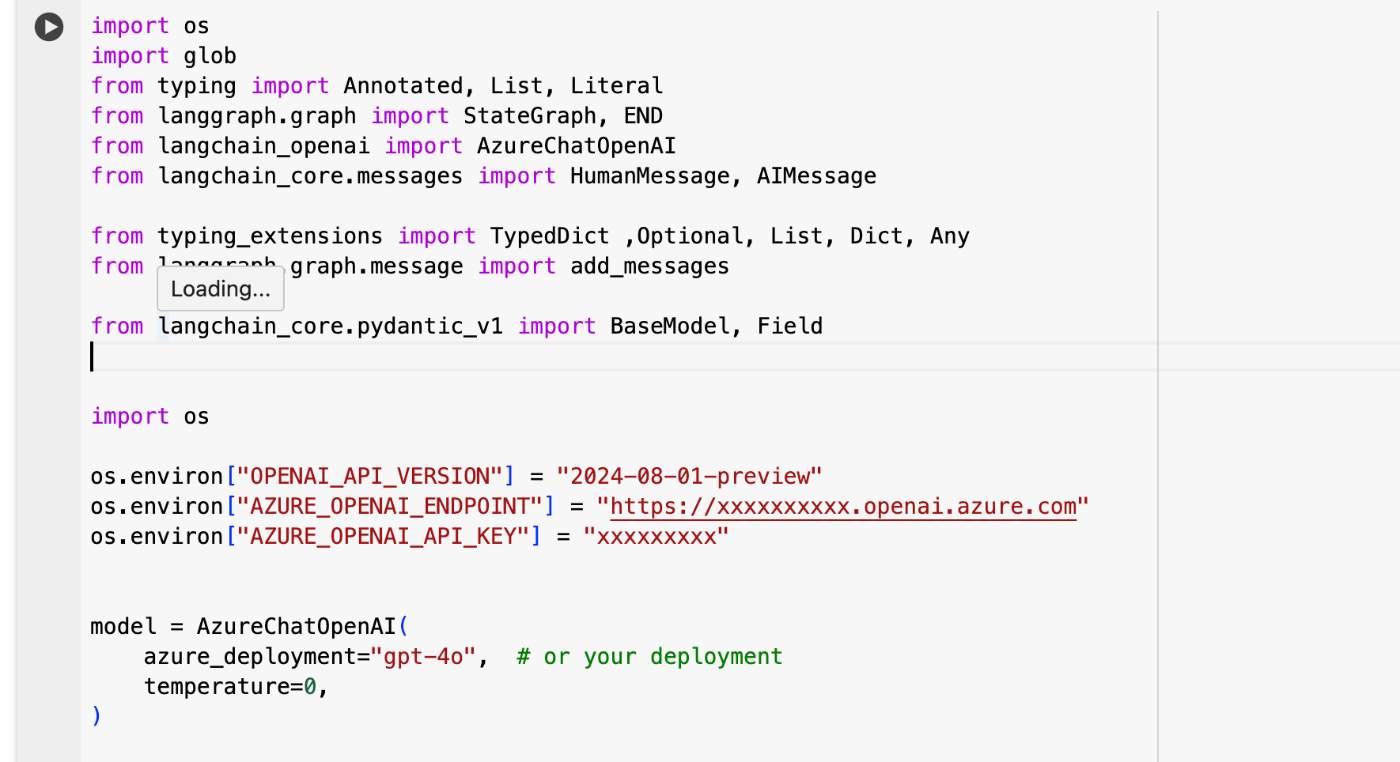
また、Azureの別モデル(例えばgpt-4o-mini)を利用したい場合は、下記部分を変更してください。
model = AzureChatOpenAI(
azure_deployment="gpt-4o-mini", # or your deployment
temperature=0,
)
また、Azure以外のLLMを利用したい場合は、下記の部分を大きく変更する必要があります。
from langchain_openai import AzureChatOpenAI
・・・
os.environ["OPENAI_API_VERSION"] = "2024-08-01-preview"
os.environ["AZURE_OPENAI_ENDPOINT"] = "https://xxxxxxxxxx.openai.azure.com"
os.environ["AZURE_OPENAI_API_KEY"] = "xxxxxxxxx"
model = AzureChatOpenAI(
azure_deployment="gpt-4o", # or your deployment
temperature=0,
)
上記の部分を、利用したいLLMのLangChain記法に則って変更してください。
逆にいうと、ここだけ適切に設定すれば、以降の処理はどんなLLMであっても(性能の差はあれど)、適切に動作するはずです。
実行方法
「ランタイム」→「すべてのセルを実行」で実行してください

すると、一番最後のセルにおいて、ユーザ入力を受け付けるようになります。
Difyで作成したAIエージェントと同様に、ここに質問してみてください。
例えば、私が質問した例は下記です。

(テキスト)
Your message: 明後日は傘が必要ですか?
Assistant: 明後日は傘が必要ですか?
明後日は晴れですので、傘は必要ありません。
Your message: 明日は緑の日ですか?
Assistant: 明日は緑の日ですか?
いいえ、明日は緑の日ではありません。緑の日は日本では5月4日に祝われます。明日は10月24日です。
Your message: 明日は傘を持って行かなくてもいいですか?
Assistant: 明日は傘を持って行かなくてもいいですか?
明日は曇りですので、傘を持って行かなくても大丈夫かもしれませんが、念のため天気予報を確認しておくと安心です。
Your message: exit
Goodbye!
この通り、適切なワークフローが選択されて、適切な専門家LLMが呼び出されていることで、そのLLMしか知らない情報を用いて回答されていることがわかります
(例えば、明後日が晴れであることや、明日の天気・日付の情報は、私がプロンプトに埋め込んだダミーのデータなので、適切な(たった一つの)LLMしか知らない情報です)
最後に「exit」と入力することで、システムを終了することもできています。
コードの解説
では、ここまでで、AIエージェントをLangGraphを用いて実装できることがわかったので、どのように作っているかの解説を行います。
基本的には、コード内のコメントアウトにも記載しているので、簡単に解説します。
1セル目(パッケージのインストール)
!pip install langgraph langchain_openai langchain_core httpx
必要なパッケージをインストールしています。
主にLangGraphやLangChainを利用するために必要なパッケージです。
2セル目(モジュールのインポート、モデル定義)
import os
import glob
from typing import Annotated, List, Literal
from langgraph.graph import StateGraph, END
from langchain_openai import AzureChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from typing_extensions import TypedDict ,Optional, List, Dict
from langchain_core.pydantic_v1 import BaseModel, Field
os.environ["OPENAI_API_VERSION"] = "2024-08-01-preview"
os.environ["AZURE_OPENAI_ENDPOINT"] = "https://xxxxxxxxxx.openai.azure.com"
os.environ["AZURE_OPENAI_API_KEY"] = "xxxxxxxxx"
model = AzureChatOpenAI(
azure_deployment="gpt-4o", # or your deployment
temperature=0,
)
ここでは、AzureのOpenAI APIを利用して、事前にAzure側でデプロイしたgpt-4oモデルを定義しています。
そのために必要なAZURE_OPENAI_API_KEYやAZURE_OPENAI_ENDPOINTは取得した情報を記載してください。
(もちろん環境変数においても良いです。むしろそちらの方が良いです)
Colabの場合は、左タブの鍵マークから、環境変数を登録でき、下記コマンドで呼び出せます。
from google.colab import userdata
os.environ["OPENAI_API_VERSION"] = userdata.get('OPENAI_API_VERSION')
os.environ["AZURE_OPENAI_ENDPOINT"] = userdata.get('AZURE_OPENAI_ENDPOINT')
os.environ["AZURE_OPENAI_API_KEY"] = userdata.get('AZURE_OPENAI_API_KEY')
ちなみにgpt-4o-miniなどの安価モデルを利用する場合は、下記のように変更すれば利用できます。
(もちろんAzure側でデプロイされていることが前提ですが)
model = AzureChatOpenAI(
azure_deployment="gpt-4o-mini", # or your deployment
temperature=0,
)
3セル目(データの型を指定する)
#ワークフローを流れるデータの型を指定する。
class State(TypedDict, total=False):
message_type: Optional[str]
messages: Optional[str]
#分類器LLMの出力を固定するクラスを指定する
class MessageType(BaseModel):
message_type: str = Field(description="The type of the message", example="search")
#AIエージェントが選択するツールの選択出力を固定するクラスを指定する
class ToolType(BaseModel):
message_type: str = Field(description="Must use the Tool", example="tool01")
#ワークフローを流れるデータの型を指定する。
class State(TypedDict, total=False):
message_type: Optional[str]
messages: Optional[str]
Stateクラスは、ワークフロー全体において流れるデータの型を指定しています。
message_typeには選ばれたツールの名前を、messagesにはユーザからの質問内容を格納してワークフローを進めます。
#分類器LLMの出力を固定するクラスを指定する
class MessageType(BaseModel):
message_type: str = Field(description="The type of the message", example="search")
#AIエージェントが選択するツールの選択出力を固定するクラスを指定する
class ToolType(BaseModel):
message_type: str = Field(description="Must use the Tool", example="tool01")
上記では、LLMが出力する値を構造化するためのクラスです。
descriptionに書かれている説明も参照しながら、モデルが構造化した出力を吐き出します。
4セル目(エージェントLLMの挙動を定義)
#AIエージェントがユーザの質問(今日か明日か明後日か)を分類し、適切なワークフロー(tool01からtool03)を呼び出すための関数の定義
#出力を固定するため
tools = model.with_structured_output(ToolType)
def select_tool(State):
# プロンプトの作成
classification_prompt = """
## You are a message classifier.
## 今日についての質問の場合は"tool01"と返答してください。
## 明日についての質問の場合は"tool02"と返答してください。
## 明後日についての質問の場合は"tool03"と返答してください。
## user message: {user_message}
"""
if State["messages"]:
return {
"message_type": tools.invoke(classification_prompt.format(user_message=State["messages"])).message_type,
"messages": State["messages"]
}
else:
return {"message": "No user input provided"}
ここでは、最初のAIエージェントが、ユーザの質問から、「今日に関する質問」か「明日に関する質問」か「明後日に関する質問」かを判定して、どのワークフロー(tool)を選択するかを回答してもらいます。
また、このLLMは下記によって出力を構造化して吐き出させています。
tools = model.with_structured_output(ToolType)
また、returnでは基本的に上で提示したStateに合わせて出力されます。
最初のLLMはユーザの質問からどのツールを選択するかを出力しますので、モデルの出力がmessage_typeにかかり、messagesはユーザの質問内容がそのまま入っています。
return {
"message_type": tools.invoke(classification_prompt.format(user_message=State["messages"])).message_type,
"messages": State["messages"]
}
5セル目(ワークフロー内の日付天気質問分類LLMの定義)
# tool01からtool03までで利用する、ユーザの質問(天気か日付か)を分類するLLMノードを定義
#出力を固定するため
classifier = model.with_structured_output(MessageType)
#ノードで実行される関数を定義
def classify(State):
# プロンプトの作成
classification_prompt = """
## You are a message classifier.
## ユーザが天気に関しての質問をしていたら"weather"と返答してください。
## それ以外の質問をしていたら、"day"と返答してください。
## user message: {user_message}
"""
if State["messages"]:
return {
"message_type": classifier.invoke(classification_prompt.format(user_message=State["messages"])).message_type,
"messages": State["messages"]
}
else:
return {"message": "No user input provided"}
分類器自体は、日付に関わらず「天気に関する質問」か「日付に関する質問」かが分割できれば良いので、共通として利用します。
4セル目と同様にwith_structured_outputで出力を構造化します。
挙動はclassify関数により定義されております。
6セル目(ワークフロー内の専門家LLMを定義)
#tool01ワークフローの質問回答LLMノードを定義
def chat_w1(State):
if State["messages"]:
State["messages"][0] = ("system", "あなたはユーザからの質問を繰り返してください。その後、質問に回答してください。ただし今日は雨です")
return {"messages": model.invoke(State["messages"])}
return {"messages": "No user input provided"}
def chat_d1(State):
if State["messages"]:
State["messages"][0] = ("system", "あなたはユーザの質問内容を繰り返し発言した後、それに対して回答してください。ただし今日は10/23です")
return {"messages": model.invoke(State["messages"])}
return {"messages": "No user input provided"}
#tool02ワークフローの質問回答LLMノードを定義
def chat_w2(State):
if State["messages"]:
State["messages"][0] = ("system", "あなたはユーザからの質問を繰り返してください。その後、質問に回答してください。ただし明日は曇りです")
return {"messages": model.invoke(State["messages"])}
return {"messages": "No user input provided"}
def chat_d2(State):
if State["messages"]:
State["messages"][0] = ("system", "あなたはユーザの質問内容を繰り返し発言した後、それに対して回答してください。ただし明日は10/24です")
return {"messages": model.invoke(State["messages"])}
return {"messages": "No user input provided"}
#tool03ワークフローの質問回答LLMノードを定義
def chat_w3(State):
if State["messages"]:
State["messages"][0] = ("system", "あなたはユーザからの質問を繰り返してください。その後、質問に回答してください。ただし明後日は晴れです")
return {"messages": model.invoke(State["messages"])}
return {"messages": "No user input provided"}
def chat_d3(State):
if State["messages"]:
State["messages"][0] = ("system", "あなたはユーザの質問内容を繰り返し発言した後、それに対して回答してください。ただし明後日は10/25です")
return {"messages": model.invoke(State["messages"])}
return {"messages": "No user input provided"}
# 最終出力ノードを定義
def response(State):
return State
ここでは、天気か日付かの質問が分類された後において、専門のLLMがSYSTEMプロンプトに記載されている専門知識を元に回答をします。
また、最後に出力用のノードも定義しています。
7セル目(3つのワークフローの流れを定義)
#各ワークフローは整理のため、子ノードとして定義する
#子ノードを流れるデータの型を定義
class ChildState(TypedDict, total=False):
message_type: Optional[str]
messages: Optional[str]
#tool01ワークフローのノードとエッジを定義する
# ノードの追加
child_builder1 = StateGraph(ChildState)
child_builder1.add_node("classify1", classify)
child_builder1.add_node("chat_w1", chat_w1)
child_builder1.add_node("chat_d1", chat_d1)
child_builder1.add_node("response1", response)
# エッジの追加
child_builder1.add_edge("chat_d1", "response1")
child_builder1.add_edge("chat_w1", "response1")
# 条件分岐
child_builder1.add_conditional_edges("classify1", lambda state: state["message_type"], {"weather": "chat_w1", "day": "chat_d1"})
# 開始位置、終了位置の指定
child_builder1.set_entry_point("classify1")
child_builder1.set_finish_point("response1")
#tool02ワークフローのノードとエッジを定義する
# ノードの追加
child_builder2 = StateGraph(ChildState)
child_builder2.add_node("classify2", classify)
child_builder2.add_node("chat_w2", chat_w2)
child_builder2.add_node("chat_d2", chat_d2)
child_builder2.add_node("response2", response)
# エッジの追加
child_builder2.add_edge("chat_d2", "response2")
child_builder2.add_edge("chat_w2", "response2")
# 条件分岐
child_builder2.add_conditional_edges("classify2", lambda state: state["message_type"], {"weather": "chat_w2", "day": "chat_d2"})
# 開始位置、終了位置の指定
child_builder2.set_entry_point("classify2")
child_builder2.set_finish_point("response2")
#tool03ワークフローのノードとエッジを定義する
# ノードの追加
child_builder3 = StateGraph(ChildState)
child_builder3.add_node("classify3", classify)
child_builder3.add_node("chat_w3", chat_w3)
child_builder3.add_node("chat_d3", chat_d3)
child_builder3.add_node("response3", response)
# エッジの追加
child_builder3.add_edge("chat_d3", "response3")
child_builder3.add_edge("chat_w3", "response3")
# 条件分岐
child_builder3.add_conditional_edges("classify3", lambda state: state["message_type"], {"weather": "chat_w3", "day": "chat_d3"})
# 開始位置、終了位置の指定
child_builder3.set_entry_point("classify3")
child_builder3.set_finish_point("response3")
ここでは、3つのワークフローをそれぞれ流れの定義を行なっています。
同じようなことが3回繰り返されてるだけなので、一つに絞って説明します。
#子ノードを流れるデータの型を定義
class ChildState(TypedDict, total=False):
message_type: Optional[str]
messages: Optional[str]
ここでは、ワークフロー内のデータの型を定義しています。
基本的には、一個上のエージェントLLMと同様です。
child_builder1 = StateGraph(ChildState)
ここでワークフローが作成されます。
ここではchild_builder1という名前のワークフローが作成されます。
ワークフロー内はChildStateで定義された型が流れます。
child_builder1.add_node("classify1", classify)
child_builder1.add_node("chat_w1", chat_w1)
child_builder1.add_node("chat_d1", chat_d1)
child_builder1.add_node("response1", response)
ここではワークフローのグラフに「ノード」を追加しています。
ノードでは定義された関数の処理を行います。
上記では、
- 質問内容を分類する処理を行う
classify1ノード - 天気質問を回答する専門LLMが処理を行う
chat_w1ノード - 日付質問を回答する専門LLMが処理を行う
chat_d1ノード - 出力である
response1ノード
を追加しています。
入出力は、ChildStateクラスで定義された型になります。
# エッジの追加
child_builder1.add_edge("chat_d1", "response1")
child_builder1.add_edge("chat_w1", "response1")
続いて、ノードとノードのつながりを「エッジ」として定義します。
上記では
-
chat_d1からresponse1へつながるエッジ -
chat_w1からresponse1へつながるエッジ
がつながっています。
この接続は、条件分岐もなく一直線で確定しているため、上記の定義が可能です。
一方で、条件分岐がある場合は下記にように定義します。
child_builder1.add_conditional_edges("classify1", lambda state: state["message_type"], {"weather": "chat_w1", "day": "chat_d1"})
上記では、state["message_type"]に応じて、classify1ノードから、データが流れるノードが変化するように定義できます。
天気の質問ならchat_w1、日付の質問ならchat_d1のノードが呼ばれます。
# 開始位置、終了位置の指定
child_builder1.set_entry_point("classify1")
child_builder1.set_finish_point("response1")
このグラフの最初のノードと最後のノードが定義されます。
以上の処理から、最初のノードから最後のノードまで順番にエッジを繋ぐことができました。
これがグラフの定義方法です。後は、2つ目3つ目のワークフローで同じように定義しているだけです。
8セル目(エージェントの流れを定義)
#子ノードとして定義したワークフローを利用して、AiエージェントのStateGraphを定義する
# ノードの追加
graph_builder = StateGraph(State)
graph_builder.add_node("select_tool", select_tool)
graph_builder.add_node("start_tool01", child_builder1.compile())
graph_builder.add_node("start_tool02", child_builder2.compile())
graph_builder.add_node("start_tool03", child_builder3.compile())
graph_builder.add_node("response", response)
# エッジの追加
graph_builder.add_edge("start_tool01", "response")
graph_builder.add_edge("start_tool02", "response")
graph_builder.add_edge("start_tool03", "response")
# 条件分岐
graph_builder.add_conditional_edges("select_tool", lambda state: state["message_type"], {"tool01": "start_tool01", "tool02": "start_tool02", "tool03": "start_tool03"})
# 開始位置、終了位置の指定
graph_builder.set_entry_point("select_tool")
graph_builder.set_finish_point("response")
# グラフ構築
graph = graph_builder.compile()
次は、3つのワークフローを束ねるエージェントLLMのグラフを定義します。
基本的には前のセルでの解説と同様にノードとエッジを定義していきます。
ワークフローは前のセルでグラフとして定義しているので、この定義したグラフ自体を、ここでノードとして定義することができます。
下記のように記載します。
graph_builder.add_node("start_tool01", child_builder1.compile())
グラフ化したワークフローを呼び出すときは、グラフ名child_builder1を指定しつつ、.compile()にてCompiledGraphクラスのインスタンスを用意して、ノードとして定義します。
最終的に、グラフを全て定義できたら、.compile()メソッドでグラフを構築します。
# グラフ構築
graph = graph_builder.compile()
9セル目(グラフの可視化)
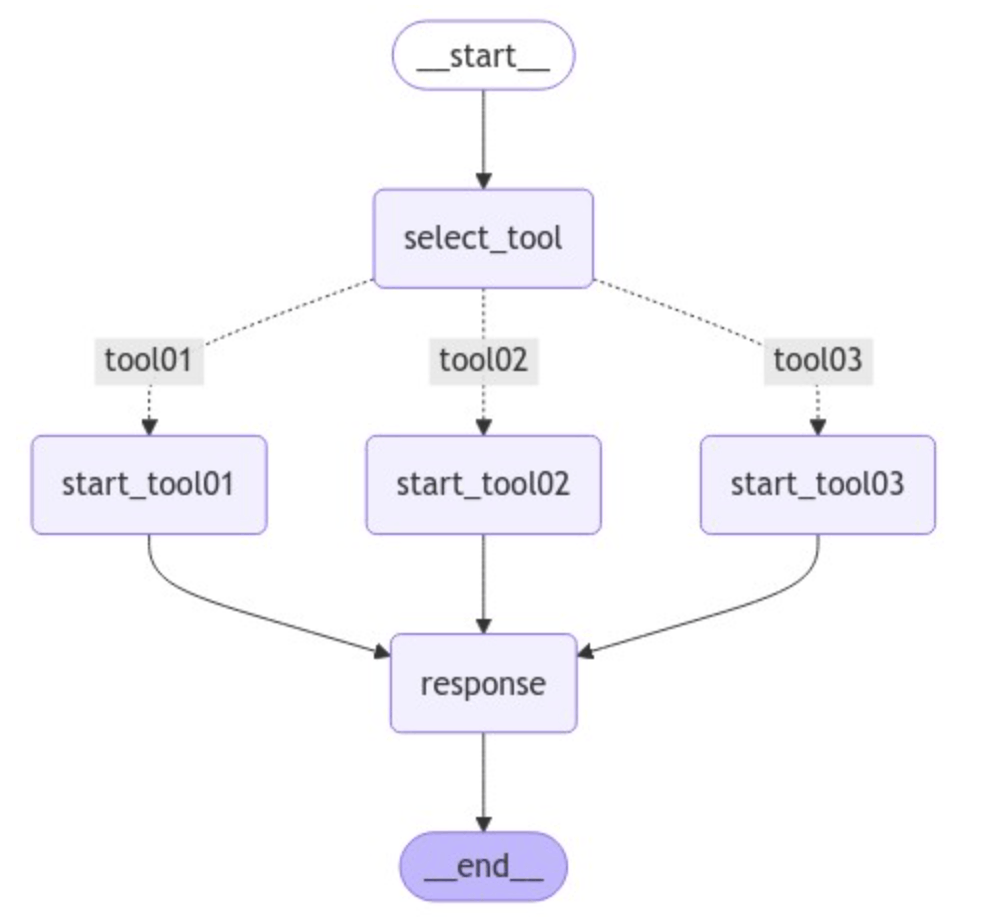
#最終的なグラフを可視化する
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
グラフは上記のような形で可視化できます。
今回可視化すると下記のようになります
10セル目(対話の実行)
# インタラクションループ
user_input = input("Your message: ")
while user_input.lower() != "exit":
# 入力を State 構造に合わせる
state = {
"messages": [
("system",""),
("human", user_input),
]
}
# 応答を取得して表示
last_content = None
for event in graph.stream(state):
# 最後の 'response' から 'messages' の content を取得
if "response" in event and "messages" in event["response"]:
messages = event["response"]["messages"]
# AIMessage オブジェクトなら content 属性を取得
if hasattr(messages, "content"):
last_content = messages.content
# 最後のメッセージを表示
if last_content:
print("Assistant:", last_content)
else:
print("No content found.")
user_input = input("Your message: ")
print("Goodbye!")
上記では、ユーザ入力をコンソールが受け付けながら、入力された質問をStateの形に設定して、graph.stream(state)によって構築したグラフに流し込みます。
今回Stateクラスでは、message_typeは任意になっているので、最初はなくても問題ありません。したがって、最初はユーザの入力だけが、グラフに入力されています。
また、state変数を見ると、ユーザ入力以外に、空のsystemプロンプトを用意しています。
これは、LLMが処理をする関数を見てもらえるとわかると思いますが、モデルにメッセージが入力される前に実は下記にような処理が割り込んでいます。
State["messages"][0] = ("system", "あなたはユーザからの質問を繰り返してください。その後、質問に回答してください。ただし明後日は晴れです")
つまり、各LLMが異なるSystemプロンプトを上書きできるように、空の要素を用意してあります。
最終的に、グラフから帰ってきた値から、LLMの回答テキスト部分のみを抽出して、コンソールに表示させています。
また、exitとユーザが入力するまで、何度も繰り返し処理ができるようになっています。
まとめ
ここまで読んでくださってありがとうございました!
やはりDIfyを同じことをするのに、LangGraphを利用するのは、かなり大変だなと思いました。
しかしながら、やはりコードとして書き下せるので、中の自由度は高いはずです。
DifyだとAPI呼び出しでしかシステムと関われないですが、LangGraphならシステムの中に直接書き下したり、Websocket通信などのDifyではサポートされていない接続方法で、システムと関わることができます。
今後のLangGraphのアップデートなどでさらに使いやすくなってくれると嬉しいですね!
参考文献
Discussion