高品質合成音声モデル【Style-Bert-VITS2】をGoogle Colabで学習し、【Aivis Speech】で利用する方法
宣伝
本記事は、日本最大級の音声系Discordサーバ「AI声づくり技術研究会」のアドベントカレンダーに投稿させていただいております。
そもそも、本記事は「AI声づくり技術研究会」の皆様がいたから書けた記事でございます。
改めて感謝申し上げます。
Discordサーバでも、常にハイレベルなアウトプット、議論が巻き起こっておりますが、今回のアドベントカレンダーも非常に楽しみにさせていただいております。
はじめに
最近、合成音声界隈が非常に盛り上がっており、以前書いた「Style-Bert-VITS2の使い方メモ」の記事のViewがまた増えてきたため、便乗して、今度は学習について詳しく書きたいと思います。
(前回の記事では、学習方法に関しては簡単にしか書いていなかったため)
そもそも、Style-Bert-VITS2をご存知ない方は、下記の記事をご覧ください。
そして、学習したモデルをAivis Speechという合成音声ソフトで利用しようと思います。
Aivis SpeechはVOICEVOX 互換の直感的な UIで、SBV2の合成音声を利用できる画期的なソフトです。
さらに、現時点でのSBV2で使われているg2pよりも、より高性能なものが使われているとか何とか。
とにかく、UIとして使いやすいのは当然として、合成音声の質も速度も大幅に向上しています。
今後の合成音声の主流になるかも、ということで、今回はこれを試すところまで行きたいなと思います。
記事の構成
本記事を読むことで下記のことができるようになります。
-
無料版のGoogle Colabを利用して、Style-Bert-VITS2(SBV2)のモデルを作る
- Style-Bert-VITS2(SBV2)を学習するためのデータを整理する
- 音声データを用意する
- 音声データを学習可能な形に分割する
- 分割された学習データの文字起こしを実施する
- SBV2の学習フォーマットに合わせて整理する
- Style-Bert-VITS2(SBV2)をGoogle Colabで学習する
- 学習済みモデルの評価を行い、最も良さそうなモデルを選定する
- 学習済みモデルを利用して、Google Colab上で合成音声をする
- Style-Bert-VITS2(SBV2)を学習するためのデータを整理する
-
学習済みのモデルをAivis Speechで利用する
- 学習済みのモデルをAivis Speechで利用できる形式に変換する
- 学習したモデルをAivis Hubに登録する
- Aivis Speech上で合成音声をする
なお、コードの説明などは、実際に利用するipynbに記載しておくことにします。
本記事では主に、どのように進めれば学習ができるのかを記載していきます。
準備
今回、SBV2を学習するとき、Google Colab環境を利用します。
Google Colab環境を利用することで、GPUを搭載していないPCであっても、高速に学習を行うことができます。
ただし、Google Colabの無料版でWebUIを利用するのは、利用規約的にNGのため、今回はWebUIを利用しない形で学習を行おうとおもいます。
Google Colabを利用してSBV2を学習する
まずは、無料版のGoogle Colabを利用して、SBV2を学習します。そのための手順を記載します。
事前準備
リポジトリをクローンする
まず、学習用のipynbなどが存在する下記のリポジトリをクローンしてください
git clone https://github.com/personabb/colab_AI_sample.git
このリポジトリは、さまざまな生成AIモデルをGoogle Colabで利用するためのサンプルコードが格納されています。使い方は、私の過去の記事をご覧ください。
この記事では、本リポジトリの中のcolab_SBV2train_sampleフォルダのみを利用します。
リポジトリをGoogle Driveにアップロードする
クローンした後、フォルダをGoogle DriveのMyDrive直下においてください。
下記のようなフォルダ構成を想定します。
MyDrive/
└ colab_SBV2train_sample/
├ model_assets/
├ inputs/
├ dict_data/
├ Data/
├ SBV2-prepare.ipynb
├ SBV2-prepare_ITA.ipynb
├ SBV2-train.ipynb
├ SBV2-evaluation.ipynb
└ SBV2-ONNXconvert.ipynb
学習音声データを準備する
SBV2を学習させるためには、10分以上の音声データを用意する必要があります。
多ければ多いほどいいというわけではないですが、質の高い音声データであれば、長時間の音声を学習させることで、モデルの質が向上することが期待できます。
また、音声データには、学習させたい一人の話者の音声のみが入っているデータセットである必要があります。
従って、データセット全体において、学習させたい話者以外の話し声が入っている音声データは利用できません。
何ファイルあっても良いですし、何時間の音声ファイルを用意してもいいですが、
- 合計で10分以上
- 一人の人物のみの音声データであること
を守っている必要があります。
なお、今回の記事では下記の「あみたろの声素材工房」様のライブ音声データを利用させていただきます。 (利用に関して、「あみたろの声素材工房」様の利用規約を必ずご確認ください)
こちらの「04_対談・元気にパズル」と「05_ひそひそ」をダウンロードいただき、中に入っている、「2024-04-28_対談あみたろのみ.wav」と「2024-06-03_SVB2.wav」を利用することにします。
準備した音声ファイルを、inputsフォルダに格納する
inputsフォルダの中に、conversationとwhisperフォルダを作成してください。
そして、conversationフォルダの中に「2024-04-28_対談あみたろのみ.wav」ファイルを、whisperフォルダの中に「2024-06-03_SVB2.wav」ファイルをアップロードしてください。
下記のようなフォルダ構成になります。
MyDrive/
└ colab_SBV2train_sample/
├ model_assets/
├ inputs/
| ├ conversation/
| | └ 2024-04-28_対談あみたろのみ.wav
| └ whisper/
| └ 2024-06-03_SVB2.wav
├ dict_data/
├ Data/
├ SBV2-prepare.ipynb
├ SBV2-prepare_ITA.ipynb
├ SBV2-train.ipynb
├ SBV2-evaluation.ipynb
└ SBV2-ONNXconvert.ipynb
学習データを整形する
音声データだけを用意した場合
ここからは実際にipynbノートブックを利用します。
「SBV2-prepare.ipynb」を開いてください。

ここで、3セル目の下記の部分を変更してください。
model_name = "amitaro"
この部分に、今回作りたいモデルの名前を指定してください。
さらに、ここで指定した名前は今後も利用します。
(今回の記事ではamitaroのまま実行します)
「ランタイム」→「全てのセルを実行」で実行してください。
実行後はDataフォルダに、amitaroフォルダができていると思います。
その中にrawフォルダとesd.listが作成されており、rawフォルダの中に、元々の動画を10秒ほどに区切って分割した音声ファイルが保存されていれば、成功です。
esd.listの中身は下記のようになっているはずです。

左から、
「音声ファイル名」|「モデル名」|「言語(JPは日本語)」|「音声の文字起こし文章」
のように出力されます。
(逆にいうと、上記のipynbを利用しなくても、この形式でesd.listを用意すれば何の問題もありません)
ITAコーパスなどのコーパス音声を用意した場合
ITAコーパスなどのコーパス音声を用意した場合
若干、話が逸れるので、こちらに書きます。
ITAコーパスなどのコーパス音声を用意した場合は、ある意味台本を読んでいる形になるため、台本のテキストをesd.listに反映させれば問題ありません。
例えば、「あみたろの声素材工房」様にもITAコーパス音声はあります。
こちらを利用したことを想定します。
ITAコーパスは、下記のリポジトリから台本テキストが取得できます。
今回はそれを読み込み、esd.listを作成しようと思います。
まず、Data/{model_name}/rawフォルダを作成します。
{model_name}の部分は、今回作りたいモデルの名前を自由に設定してください。
例えば、amitaro_ITAなどです。今回はこちらを利用したとします。
その後、Data/amitaro_ITA/rawフォルダに、音声データをフォルダごと突っ込んでください。
例えばITAコーパスであれば、emotionとrecitationの二つの音声フォルダがあると思います。
そのフォルダを、Data/amitaro_ITA/raw/ITA_emotion、Data/amitaro_ITA/raw/ITA_recitationというように、格納してください。
その後、「SBV2-prepare_ITA.ipynb」を実行してください。
すると、Data/amitaro_ITA/raw/esd.listが作成されていると思います。
SBV2を実際に学習する
基本
学習する場合は、ランタイムのタイプをT4 GPUに設定したのち、「SBV2-train.ipynb」をそのまま一番上のセルから実行してください。

当然今までと同様に、3セル目のモデル名とフォルダパスを適切に変更してください。
また、5セル目の学習パラメータを変更することもできますが、基本的にはそのままで良いです。
変更する場合は、コメントを参考に変更してください。
特に、日本語以外の合成音声を達成したい場合は、use_jp_extra = Falseに設定してください。
一方で、基本的に日本語での合成音声ができれば十分な場合は、use_jp_extra = Trueで実行してください。
実行後、Google Driveのmodel_assets/amitaroフォルダに、style_vectors.npyとconfig.jsonとamitaro_exxx_sxxxx.safetensorsがあれば成功です。
6セル目と7セル目には非常に時間がかかるため、お待ちください。
もし、7セル目にて学習が途中で停止してしまった場合は、もう一度、6セル目(前処理)以外のセルを最後まで実行することで、途中で保存されたモデルを利用して、学習を途中から再開できます。
(6セル目は実行しないでください)
(オプション)ユーザ辞書を設定する場合
ユーザ辞書というのは下記のようなものです。

辞書自体の説明は、過去に書いた記事をご覧ください。
このユーザ辞書は学習時にも反映させることができます。
ユーザ辞書を反映させた、default.csvを用意して、Google Driveのdict_dataフォルダにアップロードしてください。
その後、4セル目のdir_update_FLAGをTrueに設定してから、上から順番に実行してください。
6セル目完了後、Data/amitaro/esd.list.cleanedを見ると、文字起こしに対して、「phones」と「tones」と「word2ph」が追記されていることがわかります。(詳細はこちら)
ユーザ辞書の設定に成功していれば、「phones」の部分が、ユーザ辞書に設定した通りに出力されているはずです。
無料版のGoogle Colabのセッション制限が厳しい場合
(オプション)無料版のGoogle Colabのセッション制限が厳しい場合
1つの無料アカウントでは、T4 GPUをおおよそ4時間程度利用することができますが、SBV2の学習にはそれ以上の時間がかかることもあります。
その場合、2つ以上のアカウントを作成して、フォルダごと引っ越しをすれば、新たにT4 GPUを4時間追加で利用することができます。
しかしながら、このフォルダの引越はかなり面倒です。
そこで、「共有フォルダ」機能と「ショートカット」機能を利用して、フォルダの引っ越しをせずに、サブアカウントから、メインアカウントのフォルダを参照して、T4 GPUを追加で4時間利用する方法を記載します。
メインアカウントでの作業
メインアカウント側では、利用しているフォルダをサブアカウントに共有する作業が必要です。
下記の画像のように、colab_SBV2train_sampleフォルダを右クリックして、「共有」を実施してください。
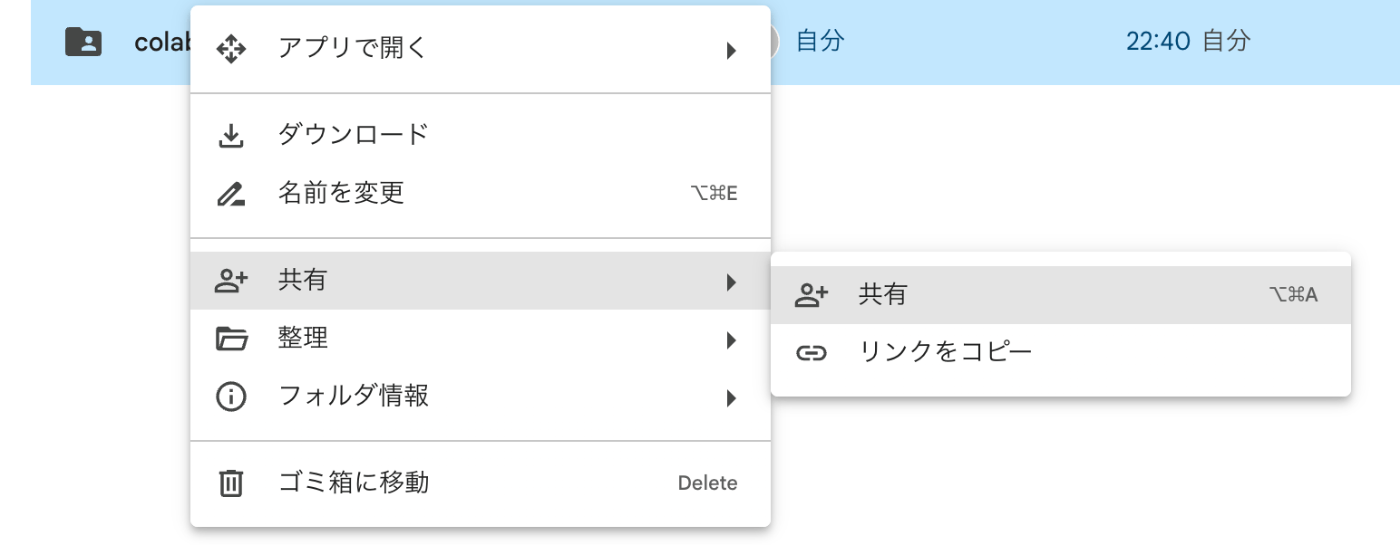
この後、サブアカウントのメールアドレスを追加すると共有ができます。
以上でメインアカウント側での操作は完了です。
サブアカウント側での作業
サブアカウント側でGoogle Driveにログインし、「共有アイテム」欄を見ると、下記の画像の通り、メインアカウント側から、colab_SBV2train_sampleフォルダが共有されていると思います。

その後、colab_SBV2train_sampleフォルダを右クリックして、「整理」→「ショートカットを追加」をクリックしてください。

その後、下記のように「マイドライブ」の直下にショートカットを作成してください。

すると、下記のようにサブアカウントのマイドライブから、colab_SBV2train_sampleが参照できることがわかります。

そして、サブアカウントから、ショートカットを経由して、共有ドライブに入り、所望のipynbを実行してください。
この状態であれば、Google Driveから、このショートカットを経由して、メインアカウントのDriveにマウントすることができるので、サブアカウント側で学習して、新しい重みファイルが保存された場合、メインアカウントのDriveに格納されます。
また、サブアカウントのGoogle Colabの制限は、メインアカウントとは独立のため、サブアカウントを複数作成し、同様の処理を繰り返すことで、時間制約をほぼ気にせずに、Google Colabを利用することができます。
SBV2のモデル重みを評価する
「SBV2-evaluation.ipynb」をそのまま一番上のセルから、4セル目まで、実行してください。
これまでと同様に3セル目において、パスやモデル名は適宜修正してください。
4セル目の実行が完了したら、コンソールにモデル名と評価点数が表示されます。

評価結果
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e4_s1200.safetensors: 1.9102470576763153
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e12_s4000.safetensors: 1.8772405087947845
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e18_s6000.safetensors: 1.8724862784147263
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e15_s5000.safetensors: 1.8204307854175568
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e20_s6810.safetensors: 1.8181726783514023
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e6_s2000.safetensors: 1.813872441649437
11-29 13:52:56 | INFO | speech_mos.py:101 | amitaro_e9_s3000.safetensors: 1.7941004931926727
点数が高い方が必ず、質が高い合成音声が達成できるというわけではないですが、一つに指標には使えると思います。
この点数が高いものから、数個候補を選び、発話させたい音声を聴き比べることを推奨します。
今回は、上から3番目で比較的上位であり、学習の後半の重みである、amitaro_e18_s6000.safetensorsを利用します。
SBV2の合成音声を確認する
上の章と同様に、「SBV2-evaluation.ipynb」を利用します。
4セル目までの結果を元に、5セル目で実際に試す重みの名前を提示してください。
例えば下記のようになります。
safetensor = "amitaro_e18_s6000.safetensors"
その後、9セル目まで実行してください。
スタイルごとに、発話される音声を聞くことができるはずです。
下記が、合成音声を実施している箇所です。
sr, audio = model.infer(text="そうだね!楽しみだね!", style = "Neutral")
text="そうだね!楽しみだね!の部分を変更することで、発話させる内容を変更することができます。
これで、自身で学習させたデータセットから、合成音声の発話まで完了できました。
また、inferメソッドで、Styleを変更することができます。基本はNeutralです。
一方で、私たちは今回、通常の会話音声としてconversationを、囁き声としてwhisperのフォルダ分けをして学習させました。
この場合は、Styleとして、上記二つを指定することができ、それぞれで異なる質の合成音声を生成することができます。
下記のように利用してください。
sr, audio = model.infer(text="えー!ほんとかなあ", style = "conversation")
sr, audio = model.infer(text="こんにちは、今日もお疲れ様。", style = "whisper")
学習済みのモデルをAivis Speechで利用する
ここまでで、Google Colabを利用して、SBV2のモデルを「あみたろ」様の学習データで学習しました。
ここからは、自分たちで学習して作ったモデルをAivis Speechで利用できるようにしたいと思います。
Aivis Speechで学習済みのSBV2を利用するためには、「AIVM / AIVMX ファイル」形式にモデルを変換する必要があります。
現時点で、私たちが持っているファイルは
- safetensorファイル
- style_vectors.npy
- config.json
の3つです。
これらは、変換後、「AIVM」ファイルになるそうで、GPU搭載のマシンで高品質な合成音声をするために利用されるそうです。
一方、変換にはもう一つ、「ONNX」形式のファイルが必要とのことです。
「ONNX」のファイルは、変換後「AIVMX」ファイルになり、CPUでも高速に合成音声を可能にするそうです。
従って、私たちはまず、上の3種類のファイルを利用して、「ONNX」ファイルを作成します。
その後、作成した「ONNX」ファイルから「AIVM Generator」というWebツールを利用して、「AIVM / AIVMX ファイル」を作成します。
ONNX形式に変換する
「SBV2-ONNXconvert.ipynb」を上から順番に実行します。(ランタイムはCPUで十分です)
これまでと同様に3セル目にて、パスやモデル名を変更してください。
特に、変換元のsafetensorファイル名も指定する必要があります。
model_name = "amitaro"
safetensor = "amitaro_e18_s6000.safetensors"
上記の部分は、正しく設定して、ipynbを全て実行してください。
するとmodel_assets/amitaro/フォルダに、model_amitaro.onnxファイルが新しく生成されていると思います。
このファイルこそが、ONNXファイルになります。
AIVM/AIVMXファイルに変換する
ここまでで、私たちは下記のファイルを取得しています。
- safetensorファイル
- style_vectors.npy
- config.json
- ONNXファイル
これらのファイルを持って、下記のWebツール「AIVM Generator」に接続してください

下記の箇所にて、これまでに取得した4つのファイルを選択してください
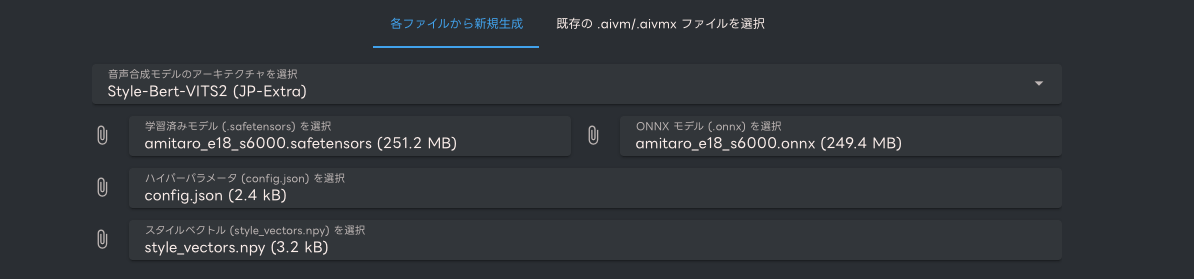
続いて、「2. メタデータ編集」にて必要情報を入力してください。

最後に、「3. AIVM / AIVMX ファイルを生成」にて、ボタンをクリックして、生成を開始します。

生成後、AIVM / AIVMX ファイルがダウンロードされます。
Aivis Speechで利用する。
Aivis Speechをダウンロード
Aivis Speech自体は、下記から無料でダウンロードできます。
下記の「無料ダウンロード」から取得できます。

私の環境は「M2 Mac」なので、下記のように指定して、「インストーラー版」をクリックしてダウンロードします。

ダウンロードされた「AivisSpeech-macOS-arm64-1.0.0.dmg」を実行して、ダウンロードを完了してください。
ちなみに、初回起動に関しては、諸々初期化の処理が入るそうなので、起動にかかる時間は長いです。
初回だけですので、気長に待ちましょう。
Aivis Speechのデフォルトモデルを試してみる
起動後、下記のような画面になると思います。
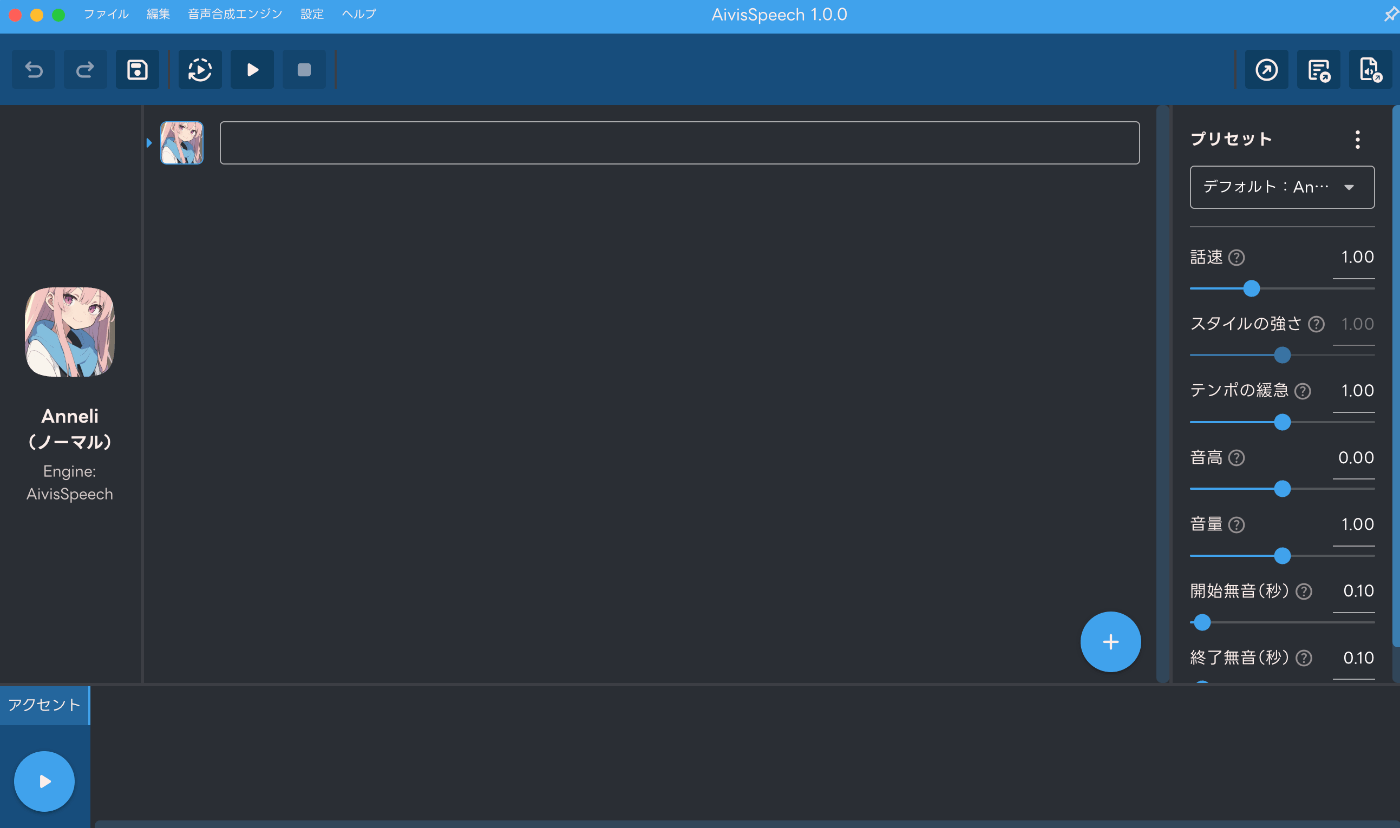
現時点では「Anneli」というモデルがデフォルトで利用できるようになっており、中央の枠に喋らせたい文章を入れて、左下の「三角」ボタンをクリックすることで、合成音声が再生されます。
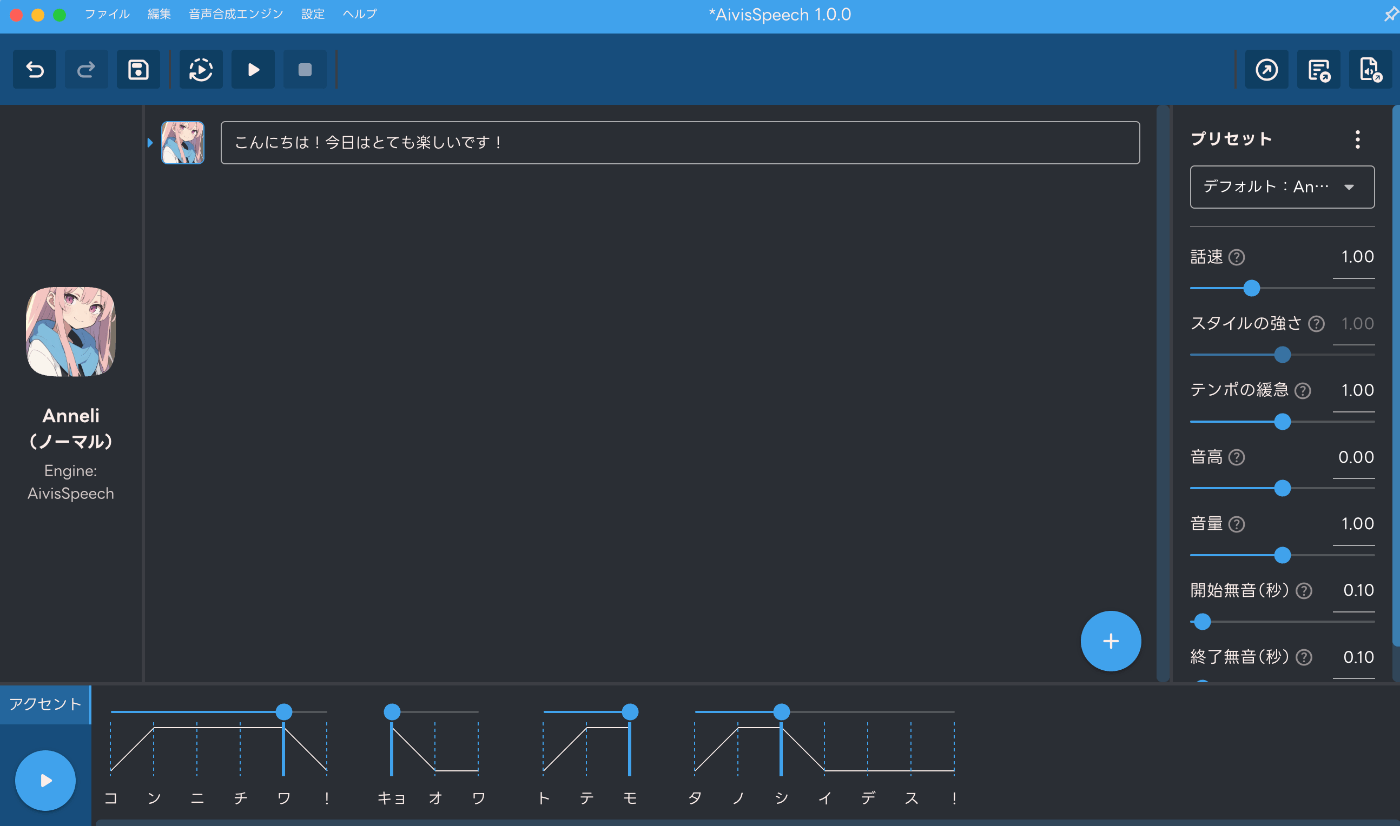
2文目を作成したかったら、右下の「+」マークをクリックしてください。
また、右側のスライドバーを変更することで、諸々再生のパラメータを調整できます。
また、入力テキスト左のアイコンをクリックすることで、(モデルがインポートされていれば)モデルを変更したり、Styleを変更することもできます。

Aivis Speechは内部的にSBV2を利用しています。
SBV2は、テキストをBertという自然言語処理モデルで解析し、感情表現を含む特徴量を取得し、それを元に音声を合成します。
したがって、楽しそうな文章は楽しそうに読むし、悲しそうな文章は悲しそうに読んでくれます。
色々試してみると面白いですよ。
AIVMX ファイルをインポートする
「設定」→「合成音声モデルの管理」をクリックしてください。

一番右上の「インストール/更新」をクリックしてください。

「ファイルからインストール」にて、先ほど変換した「AIVMX ファイル」を選択し、画面右下の「インストール/更新」をクリックすると、Aivis Speechにモデルをインポートできます。

Aivis Speechで再生する
先ほど説明した通り、モデルを変更したり、Styleを変更したりしながら、合成音声を再生してみてください。
自分たちで学習したモデルをもとに、Aivis Speechで合成音声をすることができました。
まとめ
ここまでで、既存のライブ音声をもとに、学習データの整理から、SBV2の学習を行いました。
そして、学習モデルを変換して、Aivis Speechで利用するまでの流れを記述しました。
学習モデルの品質をもっと上げたい場合は、下記のような工夫が考えられます
- Styleを分けずに、モデルを分ける
- 会話音声と囁き音声を分けて、別々のモデルを用意する方が安定すると思います。
- 音声データ量を減らしても良いから、文字起こしの品質を高める
- 学習音声データ量が10-20分程度でも、文字起こしを完璧にして学習した方が、品質は上がる体感です。
ここまで読んでくださってありがとうございました。
参考
「AI声づくり技術研究会」のDiscordサーバでの皆様のアウトプット内容
Discussion