LangGraphにて入力情報が不十分な場合に、ユーザへ追加質問をするAIエージェントを作る方法
はじめに
先日、LangGraphを利用して少し複雑なAIエージェントを実装する方法について記事を書きました。
前回の記事で実施したことは、「今日、明日、明後日」の日付の範囲内で、「天気」もしくは「日付」に関してのユーザ質問を回答するAIエージェントです。
AIエージェントはユーザの質問内容から、質問回答を適切な専門のLLMに割り振り、LLMはシステムプロンプトの情報に基づいて回答することをLangGraphで実装しました。
参考文献
LangChainとLangGraphによるRAG・AIエージェント[実践]入門
2024年11月9日に発売された良書です。こちら全て読ませていただきました。
LangChainのLCELからLangGraphによるAIエージェントの基礎と応用まで完全に網羅している素晴らしい書籍です。
本日の記事は、上記の書籍のコードの書き方を参考に、ちゃんとLCEL(LangChain Expression Language)を利用して実装するようにしました。
LCELを知らない方には少しわかりにくい記事になっているかもですが、挙動は前回の記事の書き方とほぼ同じなので、合わせてご参考ください。
また、LCELに関しての解説記事も12月頭に公開予定です。
早く知りたい方は、ぜひ、上の参考書籍をご購入ください!LCELについてもよく理解できると思います。
また、ユーザの入力が不十分な際に、動的にグラフを中断して、ユーザに再質問をするために必要な、「動的ブレークポイント」を設定する部分に関しては、公式のドキュメントを主に参考にして実装しました。
問題設定
今回は、前回作ったAIエージェントに、「詳細確認機能」を追加します。
例えば、「天気」の質問に関して、専門LLMは「午前」と「午後」で天気が違うことを知っていたとします。
その際、ユーザが「明日の午前の天気を教えて?」と質問した場合は、そのまま知っている明日の午前の天気を回答すれば良いです。
しかし、ユーザが「明日の天気を教えて?」と質問した場合は、「午前の天気」と「午後の天気」のどちらを回答すれば良いかLLMには判断できません。
(あくまで仮の問題設定でトイモデルなので、午前の天気も午後の天気も両方回答すれば良いだろという批判はご遠慮ください。)
その時に、動的にLLMがユーザに対して「午前」か「午後」かを聞き直すような仕組みをAIエージェントに導入しようと思います。
今回の記事では、Google Colabで実験しますが、次回以降の記事では、Next.jsなどでフロントを作成し、実際にVercelなどで公開できるところまで進めようと思っていますので、今後ともぜひご覧ください。
成果物
今回も普通にGoogle Colabのipynbなので、そのままコードを公開します。
下記リポジトリをご覧ください
また、実際にGoogle Colabを実行すると下記のようにAIエージェントを利用できます。
問題設定の通り、ユーザの質問内容が不十分の場合だけ、「動的に」ワークフローを中断し、詳細を確認することができています。
実行方法
事前準備
前回の記事と同等なため、そちらをご覧ください
ただし、利用するipynbはこちらになります。
実行方法
基本的には前回の記事と同様ですが、
「ランタイム」→「すべてのセルを実行」で実行してください。
すると、一番最後のセルにおいて、ユーザ入力を受け付けるようになるので、質問してみてください。
例えば私が質問した例は下記です。
(テキスト)
Your message: 明日の午前の天気は?
Assistant: 明日の午前の天気は曇りです。
Your message: 明後日の天気は?
天気を知りたい時間を入力してください(例:「午前中」「20時」など): えーとどうしようかな?
天気を知りたい時間を入力してください(例:「午前中」「20時」など): 15:00
Assistant: 明後日の15:00の天気は霧です。
そのほかのログの出力結果も含めた出力
Your message: 明日の午前の天気は?
--select_tool--
--classify--
--classify_time--
--interrupt--
--chat_w2--
--response--
--response--
Assistant: 明日の午前の天気は曇りです。
Your message: 明後日の天気は?
--select_tool--
--classify--
--classify_time--
--interrupt--
天気を知りたい時間を入力してください(例:「午前中」「20時」など): えーとどうしようかな?
--classify_time--
--interrupt--
天気を知りたい時間を入力してください(例:「午前中」「20時」など): 15:00
--classify_time--
--interrupt--
--chat_w3--
--response--
--response--
Assistant: 明後日の15:00の天気は霧です。
ログでは、グラフ内のどのノードを経由したのかがわかるように出力しています。
この通り、前回の記事と同様に、適切なワークフローが選択されて、適切な専門家LLMが呼び出されていることで、そのLLMしか知らない情報を用いて回答されていることがわかります
(例えば、明後日が晴れであることや、明日の天気・日付の情報は、私がプロンプトに埋め込んだダミーのデータなので、適切な(たった一つの)LLMしか知らない情報です)
加えて、「天気」の質問の中でユーザの質問が不十分の場合(時間に関する記述がない場合)には、ユーザに対して追加の情報を要求してくるようになっており、そのやり取りで詳細が確認できて初めてLLMが回答するようになっています。
コードの解説
前回の記事で解説した部分は省略します。
今回追加された部分に絞って解説します。
LCELに書き換えた部分
前回の記事のコードからLCEL記法に書き換えたところを下記に記載します。
LCELに関しての詳細は、後日記載する記事をご覧ください。
(もしくは、参考文献の良書をご覧ください)
StateでPydanticを利用
# グラフを流れるStateの方の定義
class State(BaseModel):
message_type: str = Field(default = "", description="ユーザからの質問の分類結果")
query: str = Field(default = "", description="これまでのプロンプト内容")
AI_messages: str = Field(default = "", description="AIからのメッセージ内容")
bool_time: bool = Field(default = False, description="時刻情報が含まれているかどうかの判定結果")
advance_messages: str = Field(default = "", description="追加質問のユーザ回答")
Stateにおいて、明確に型を指定して定義するために、Pydanticを利用しています。
Pydanticは、データのバリデーションや型ヒントを提供してくれます。
LLMを利用するすべてのノードにおいてLCELを採用
下記は「今日の日付を回答するLLM」ノードの例ですが、すべてのノードにおいてLCELを採用しています。
output_parser = StrOutputParser()
・・・
def chat_d1(State):
print("--chat_d1--")
if State.query:
sys_prompt = "あなたはユーザの質問内容を繰り返し発言した後、それに対して回答してください。ただし今日は10/23です"
prompt = ChatPromptTemplate.from_messages(
[
("system",sys_prompt),
("human", "{user_input}")
]
)
chain = prompt | model | output_parser
return {
"query":State.query,
"AI_messages": chain.invoke({"user_input": State.query})
}
return {
"AI_messages": "No user input provided"
}
前回の記事よりも長いコードになってしまっていますが、その分、メンテナンス性や可読性、拡張性などが向上しています。
prompt | model | output_parserでchainを組むことで、ユーザのstrの入力を受け付けて、str型の出力を吐き出すようになります。
あとはそれを元に、下記のようにStateを更新するだけです。
return {
"query":State.query,
"AI_messages": chain.invoke({"user_input": State.query})
}
基本的にLangGraphでは、Stateの持つすべてのkeyに対してreturnを定義しなくても、更新がある部分だけreturnを定義すれば良いようです。
ユーザの質問が不十分かどうかを確認する
下記からは、本記事にて新しく実装した「ユーザの入力情報が不十分な場合に追加質問をする機能」の部分になります。
・・・
# 天気の質問において、必要情報がすでに埋まっているかを判定する判定器の出力
class TimeType(BaseModel):
message_type: bool = Field(description="The bool of the time", example=True)
・・・
classifier_time = model.with_structured_output(TimeType)
def classify_time(State):
print("--classify_time--")
# プロンプトの作成
classification_prompt = """
## You are a message classifier.
## ユーザが、日付以外の時間を指定して質問している場合(例えば、「午前」「午後」「12時」「5:20」などがある場合)はTrueと返答してください。
## そうでない場合はFalseと返答してください。
TrueかFalse以外では回答しないでください。
"""
if State.query:
if not State.advance_messages:
prompt = ChatPromptTemplate.from_messages(
[
("system",classification_prompt),
("human", "{user_input}")
]
)
else:
prompt = ChatPromptTemplate.from_messages(
[
("system",classification_prompt),
("human", "{user_input}ただし、{advance_messages}")
]
)
chain = prompt | classifier_time
if State.advance_messages:
dicts = {
"bool_time": chain.invoke({"user_input": State.query, "advance_messages": State.advance_messages}).message_type,
}
return dicts
else:
dicts = {
"bool_time": chain.invoke({"user_input": State.query}).message_type,
}
return dicts
else:
return {"AI_messages": "No user input provided"}
classifier_timeというLLMを定義し、classify_time関数(後のノード)で判定を行っています。
判定結果は下記のプロンプトの通り、boolで出力されるようになっており、それがStateのbool_timeのkeyに格納されます。
(プロンプト)
classification_prompt = """
## You are a message classifier.
## ユーザが、日付以外の時間を指定して質問している場合(例えば、「午前」「午後」「12時」「5:20」などがある場合)はTrueと返答してください。
## そうでない場合はFalseと返答してください。
TrueかFalse以外では回答しないでください。
"""
また、今回は、ユーザの質問内容が不十分であり、かつ再質問の回答も不十分であることを想定する必要があります。
再質問をしても、不十分な回答をするユーザがいるので、しつこく同じ質問を繰り返す必要があるということです。
したがって、この確認フェーズは、初回だけでなく、再質問を行った後のユーザの回答も通る可能性があります。
そこで下記のように条件分岐をしています。
(再質問後)
if State.advance_messages:
prompt = ChatPromptTemplate.from_messages(
[
("system",classification_prompt),
("human", "{user_input}ただし、{advance_messages}")
]
)
・・・
chain = prompt | classifier_time
・・・
if State.advance_messages:
dicts = {
"bool_time": chain.invoke({"user_input": State.query, "advance_messages": State.advance_messages}).message_type,
}
return dicts
(初回)
else:
prompt = ChatPromptTemplate.from_messages(
[
("system",classification_prompt),
("human", "{user_input}")
]
)
・・・
chain = prompt | classifier_time
・・・
else:
dicts = {
"bool_time": chain.invoke({"user_input": State.query}).message_type,
}
return dicts
まず、簡単な初回(下)の方を解説します。
ここではStateのbool_timeに対して、LLMが結果を格納しています。
システムプロンプト中のuser message: {user_message}の部分にState["messages"]、つまりユーザの質問文章を入れ込んで判定しています。
一方で、
再質問後では、if State.advance_messages:の条件が入ります。
再質問をした場合は、再質問に対するユーザの回答内容がState.advance_messagesに格納されているからです。
加えて、前回の記事の時点と比較して、Stateにおいても、2つのkeyが追加されています。
bool_timeとadvance_messagesです。
advance_messagesには、再質問後のユーザの入力内容が記載されています。つまり、適切にユーザが回答していれば、「午前中」や「15:00」などの時間の情報が入っているはずです。
bool_timeでは、埋め込まれる文章が、初回の質問内容に加えて、advance_messagesも埋め込まれています。
こうすることにより、再質問後のユーザの回答も踏まえて、現時点でAIエージェントが取得している情報が十分であるかを判定しています。
動的にグラフを中断する
from langgraph.errors import NodeInterrupt
def interrupt(State):
print("--interrupt--")
if not State.bool_time:
raise NodeInterrupt("天気を知りたい時間を入力してください")
return State
・・・
graph_builder.add_edge("classify_time_1", "interrupt_1")
こちらでは、ユーザの質問内容が不十分かどうかを動的に確認し、不十分な場合は、グラフを中断させています。
中断部分は下記です。
if not State.bool_time:
raise NodeInterrupt("天気を知りたい時間を入力してください")
記載の通り、Stateのbool_timeの値がFalseの場合、グラフを中断させています。
これは、上述した通り、前段のLLMが「ユーザの質問内容が不十分」と判断したらbool_timeにFalseを格納しているからです。
実際、下記の通り、前述した「ユーザの質問が不十分かどうかを確認する」LLMは、このinterrupt関数の直前にノードとして置かれています。
graph_builder.add_edge("classify_time_1", "interrupt_1")
また、「ユーザの質問内容が十分」の場合は、そのままStateを次のノードに送ることを考えています。
天気を回答するLLMにおいて、ユーザの追加入力を考慮する
def chat_w1(State):
print("--chat_w1--")
if State.query:
sys_prompt = "あなたはユーザからの質問を繰り返してください。その後、質問に回答してください。ただし今日の午前は雨で、午後は雪です"
prompt = None
if not State.advance_messages:
prompt = ChatPromptTemplate.from_messages(
[
("system",sys_prompt),
("human", "{user_input}")
]
)
else:
prompt = ChatPromptTemplate.from_messages(
[
("system",sys_prompt),
("human", "{user_input}"),
("assistant", "天気を知りたい時間を入力してください(例:「午前中」「20時」など): "),
("human",State.advance_messages)
]
)
chain = prompt | model | output_parser
dict = {
"query":State.query,
"AI_messages": chain.invoke({"user_input": State.query})
}
return dict
return {
"AI_messages": "No user input provided"
}
上記は、「今日の天気を回答する」LLMのノードの関数になりますが、明日も明後日も同様に実装しています。
まず、初回の質問への回答と追加質問後の回答で違うことは、State.advance_messagesに追加情報が入っているかどうかです。
したがって、State.advance_messagesに情報がある場合は、それをプロンプトに適応させる必要があります。
それは下記のように実装しています。
if not State.advance_messages:
prompt = ChatPromptTemplate.from_messages(
[
("system",sys_prompt),
("human", "{user_input}")
]
)
else:
prompt = ChatPromptTemplate.from_messages(
[
("system",sys_prompt),
("human", "{user_input}"),
("assistant", "天気を知りたい時間を入力してください(例:「午前中」「20時」など): "),
("human",State.advance_messages)
]
)
上記の通りState.advance_messagesの有無において、初回の質問への回答か、追加質問後の回答かを分岐し、追加質問の場合は、State.advance_messagesをプロンプトに反映させています。
その後、通常のLCEL記法に則って、chainを組んで、str型の出力を受け取り、stateを更新しています。
chain = prompt | model | output_parser
dict = {
"query":State.query,
"AI_messages": chain.invoke({"user_input": State.query})
}
return dict
最終的なグラフ構造
下記のコードにより、最終的なグラフ構造を可視化できます。
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
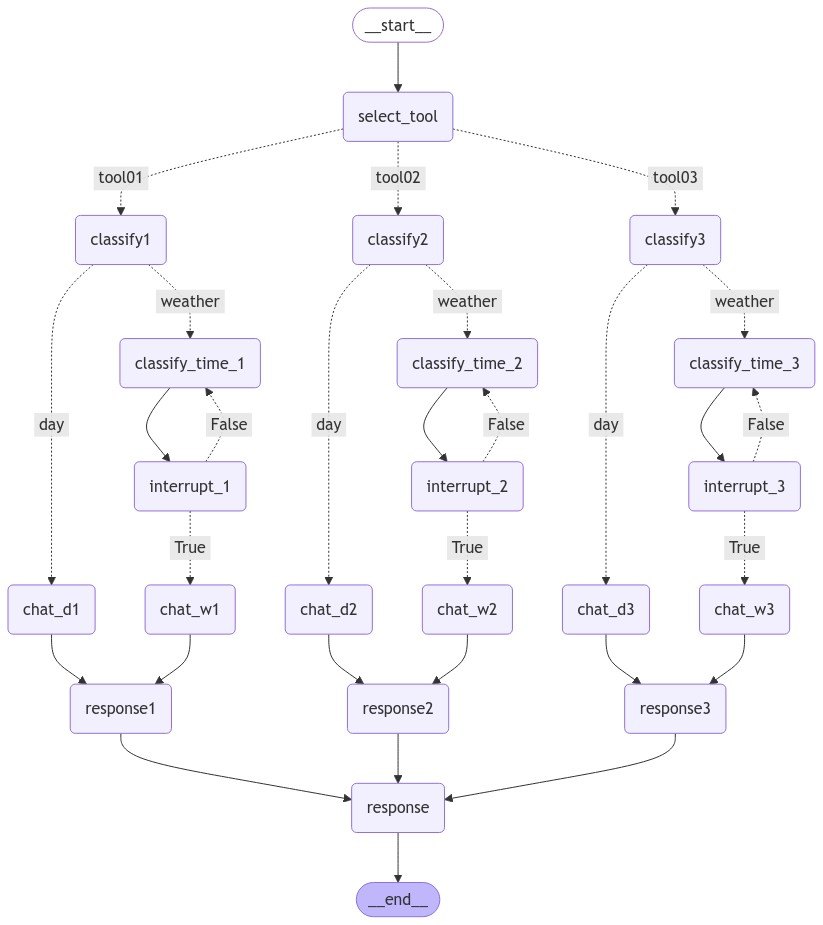
「interrupt」のノードにおいて、動的にグラフが次に進むか、前に戻るかが選ばれていることがわかると思います。
中断されたグラフの再開
グラフの中断の検出
for event in graph.stream(state, thread_config):
#グラフ途中の中断を検出
event_list.append(event)
if "__interrupt__" in event:
interrupt = True
break
グラフが中断されたかどうかは上記のように取得しています。
グラフをstreamで実行すると、各ノードごとで出力結果を辞書形式で取得できます。
グラフが中断された時は、__interrupt__をkeyとする辞書が発行されるため、それをキャッチして、中断フラグを立てます。
breakはあっても無くてもいいですが、ここでは明示的に記載しています。
また、中断時、その一個前のノードから再開したいため、eventは全てevent_listに格納しておきます。
中断後の再開処理の実装
elif interrupt:
interrupt = True
for key in event_list[-2].keys():
#中断した処理の直前のノードの名前によって処理を変える。(ただし、今回は一つだけ)
if "classify_time" in key:
while interrupt:
#ユーザへの追加のメッセージを依頼する
user_input_add_times = input("天気を知りたい時間を入力してください(例:「午前中」「20時」など): ")
#memoryにて履歴が保存されているので、stateを更新する部分だけ用意すれば良い
add_state = {
"query": user_input,
"advance_messages":user_input_add_times,
}
all_states = []
for state in graph.get_state_history(thread_config):
all_states.append(state)
to_replay = all_states[1]
branch_config = graph.update_state(config=to_replay.config, values=add_state)
for event in graph.stream(None, branch_config):
if "__interrupt__" in event:
interrupt = True
break
# 最後の 'response' から 'messages' の content を取得
if "response" in event and "AI_messages" in event["response"]:
last_content = event["response"]["AI_messages"]
中断したノードの直前のノードを取得する
for key in event_list[-2].keys():
上記で、中断直前のノードのkeyを取得しています。
中断直前のノードの種類によって、どんな対処をするべきかは変わるので、この部分の処理は必要です。
今回のモデルでは、中断処理は一箇所にしか入っていないですが、例えば、一番最初に「そもそも日付か天気の質問でない文章が入ってきたらブロックする」みたいな処理を入れたい場合は、中断箇所が2つになるので、それぞれにおいて処理を実装する必要があります。
今回は、天気の質問において、時間情報が入っているかどうかの一箇所だけなので、一個だけ実装しています。
特定の中断ノードにおける再質問メッセージとプロンプト
if "classify_time" in key:
while interrupt:
#ユーザへの追加のメッセージを依頼する
user_input_add_times = input("天気を知りたい時間を入力してください(例:「午前中」「20時」など): ")
add_state = {
"query": user_input,
"advance_messages":user_input_add_times,
}
上記のコードでは、interruptフラグが立っている間は、ループし続けます。
これは、再質問したが、ユーザの回答がまた不十分だった場合に、再度再質問をする必要があるためです。
また、その下で、中断したノードの直前のノードのkeyにclassify_timeを含む場合の処理の実装をしています。
天気の質問に対して、時間の記載がないことで中断しているため、時間に関しての情報を再質問しています
その後、得られた追加情報と事前の質問内容をプロンプトに組み込んでいます。またStateにはメッセージ全体と、追加質問の文章advance_messagesを組み込みます。
グラフの再開箇所の設定
for state in graph.get_state_history(thread_config):
all_states.append(state)
to_replay = all_states[1]
branch_config = graph.update_state(config=to_replay.config, values=add_state)
グラフにはcheckpointとして過去の処理内容が保存されています。
get_state_historyメソッドを実行すると、過去の履歴のうち、新しい履歴から取得できます。
したがって、all_states[1]は中断した処理ノードの一個前での処理を取得しているため、中断したノードの一個前のノードの情報を取得しています。
加えて、その下の行にてupdate_stateメソッドを実行し、Stateの情報を更新しています。
更新内容は、configとして中断したノードの一個前のノードを指定しており、再開した場合に中断したノードの一個前のノードから再開されるようにしています。
加えて、Stateの中身として、上記で指定した再質問結果も格納したStateに更新しています。
グラフの再開
for event in graph.stream(None, branch_config):
if "__interrupt__" in event:
interrupt = True
break
# 最後の 'response' から 'messages' の content を取得
if "response" in event and "AI_messages" in event["response"]:
last_content = event["response"]["AI_messages"]
中断後のグラフを再度途中から実行する場合は、下記のように記載します。
graph.stream(None, branch_config)
Stateの部分にNoneを指定することで、中断箇所から再開することになり、その時どのノードからどんなStateで実行するかはconfigが支配しています。
また、上記の処理の中でも、中断処理があるかどうかをキャッチしています。
これは、再質問した後のユーザの回答が不十分だった場合に、十分になるまで何度でも繰り返し同じ質問を繰り返すことを意味しています。
十分な入力が得られ、グラフが最後の出力結果まで中断されずに処理を完了したら、interruptフラグがFalseになるため、ループを抜けて、新しい質問を受け付けるため待機します。
まとめ
ここまで読んでくださってありがとうございました!
前回作成したトイモデルをベースに、さらに詳細な処理を組み込んでみました!
(Difyとかでもこういう処理は実装できるんですかね?まだ勉強が不十分なので詳しい方いたら教えてください)
次回以降では、より複雑なAIエージェントにするための機能追加をしたり、実際にWebアプリとしてフロントエンドから触れるようにしていきたいと思いますのでそちらもぜひご覧ください!
Discussion