🔍
sqlcmdで、Azure Data Lake Storageを利用する(SAS利用)
はじめに
ストレージ上のファイルに直接クエリできるAzure Data Lake Storageを以前紹介しました。
また前回はこのサービスに対して、sqlcmdでアクセスしてみました。ストレージへの認証は、匿名アクセスを使っています。
今回はSAS(Shared Access Signature:共有アクセス署名)を使ってやってみました。
概要
- Cloud Shellのsqlcmdからアクセスします
- Azure Data Lake Storageを検索するためのAzure Synapse Analyticsのエンドポイントにアクセスします
- データが格納されているストレージへの認可は、SASを使います
参考
やってみた
環境は、最初に作ったものを利用します。
やることとしては、対象のファイルに、SASを生成します。
また、以下のリソースを作ります。
- データベース
- データベースマスターキー
- データベースの資格情報
- 外部データソース
SAS生成
対象のファイルのSASを生成します。

生成されたシークレットは後で使います。
リソース作成
以下のページに倣って作っていきます。
今回使用するDBのユーザーは、環境構築時に作成されるSQL管理ユーザーsqladminuserを使用しています。
各クエリはSynapse Studioから実行しました。
-- データベース作成。作成後にデータベースを変更します
CREATE DATABASE hogehoge
-- データベースマスターキー作成
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong password>'
-- データベース資格情報作成。先ほどのSASのシークレットを指定
CREATE DATABASE SCOPED CREDENTIAL SasCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'sv=2019-10-1********ZVsTOL0ltEGhf54N8KhDCRfLRI%3D'
-- データソース作成
CREATE EXTERNAL DATA SOURCE mysample
WITH ( LOCATION = '<コンテナーのURL>'
, CREDENTIAL = SasCredential
)
検索
Cloud Shellのsqlcmdからログインします。
# パスワード確認がでます。
sqlcmd -S <サーバーレス SQL エンドポイント> -d master -U sqladminuser
使用するデータベースを指定して、SELECTを実行します。
USE hogehoge
go
SELECT count(*) FROM OPENROWSET(
BULK 'corona-tokyo/2022/130001_tokyo_covid19_patients_2022.csv'
, DATA_SOURCE='mysample'
, FORMAT='CSV'
, PARSER_VERSION='2.0'
) AS [result];
go
単体のファイルに対してクエリができました。
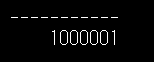
サブフォルダ以下を検索するために**を使うには、以下を行います。
- 対象のコンテナーでSAS生成
- 読み取り権限に加え、リストの権限を付与

データベース資格情報を再作成した後、以下を実行します。
SELECT count(*) FROM OPENROWSET(
BULK 'corona-tokyo/**'
, DATA_SOURCE='mysample'
, FORMAT='CSV'
, PARSER_VERSION='2.0'
) AS [result];
サブフォルダ以下のファイルに対してもクエリされました。
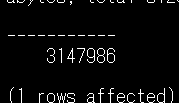
おわりに
今回はAzure Data Lake Storageを、SQLServerにアクセスするように、sqlcmdで実行してみました。
外部から利用できるため、さらに使いどころがあるかと思います。
この記事がどなたかのお役に立てれば幸いです。
Discussion