Azure Data Lake StorageでCSVファイルを直接クエリする
はじめに
ストレージにあるCSVなどのファイルに対して、SQLなどで検索できるAzure Data Lake Storageというサービスがあります。
他社の類似サービスですと、AWSでいうとAthena、Google CloudでいうとBigqueryのExternal Tableになりますでしょうか。
少し触ってみましたので、内容を記事にしました。
概要
- アカウントは無料アカウントで行っています。
- ファイルの保存場所として、Azure Storage Accountを作成します。
- Standard 汎用 v2で、階層型名前空間を有効にします。
- Azure Synapse Analyticsワークスペースを作成して、Synapse StudioからSQLを実行します。
参考
やってみた
Azure Storage Account作成
パフォーマンスは Standard 汎用 v2 または Premium ブロック BLOB である必要があるので、Standardにします。(冗長性は安くするためにLRSにしています)
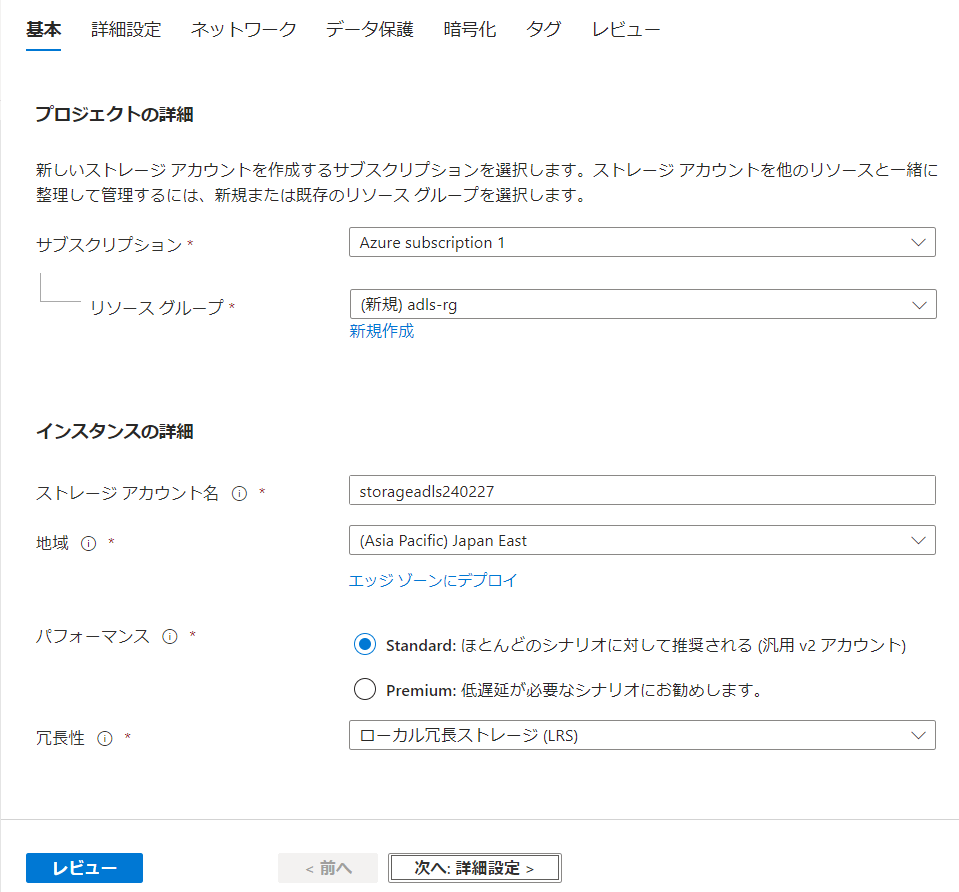
詳細設定で、階層型名前空間を有効にします。

必要ではないですが、データ保護で論理削除は無効にしておきました。

この状態で作成します。
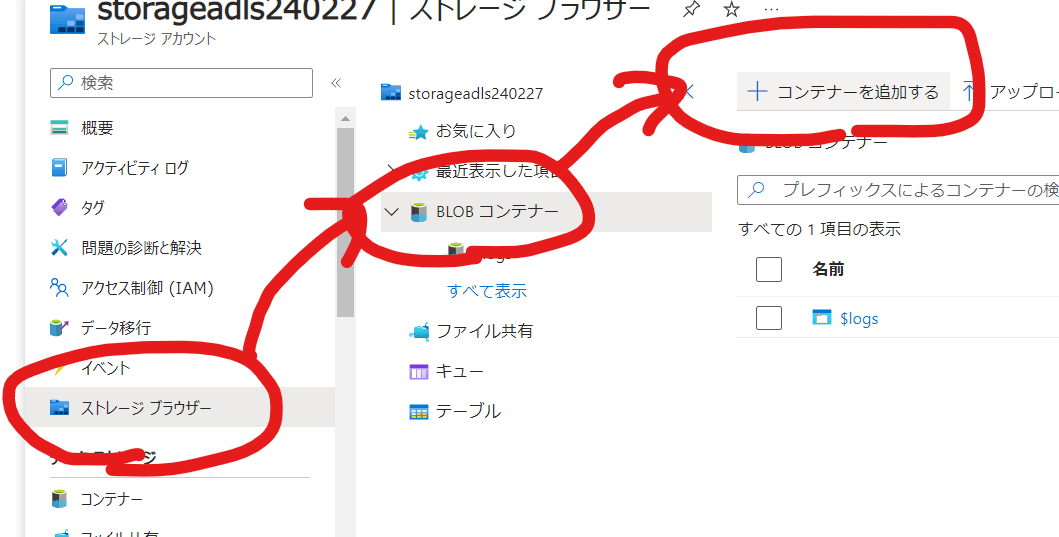
サンプルデータ格納
格納場所として、dataという名前のコンテナーを作成します。
格納するサンプルデータは以下を使います。各データ1行目はカラム名になっています。
| ファイル名 | データ数 |
|---|---|
| 130001_tokyo_covid19_patients_2020.csv | 60,312 |
| 130001_tokyo_covid19_patients_2021.csv | 322,748 |
| 130001_tokyo_covid19_patients_2022.csv | 1,000,000 |
| 130001_tokyo_covid19_patients_2022-1.csv | 1,000,000 |
| 130001_tokyo_covid19_patients_2022-2.csv | 764,921 |
| 合計 | 3,147,981 |
以下のようにフォルダに分けて格納します。
C:.
└─corona-tokyo
├─2020
│ 130001_tokyo_covid19_patients_2020.csv
│
├─2021
│ 130001_tokyo_covid19_patients_2021.csv
│
└─2022
130001_tokyo_covid19_patients_2022-1.csv
130001_tokyo_covid19_patients_2022-2.csv
130001_tokyo_covid19_patients_2022.csv
ストレージブラウザからファイルをアップロードします。
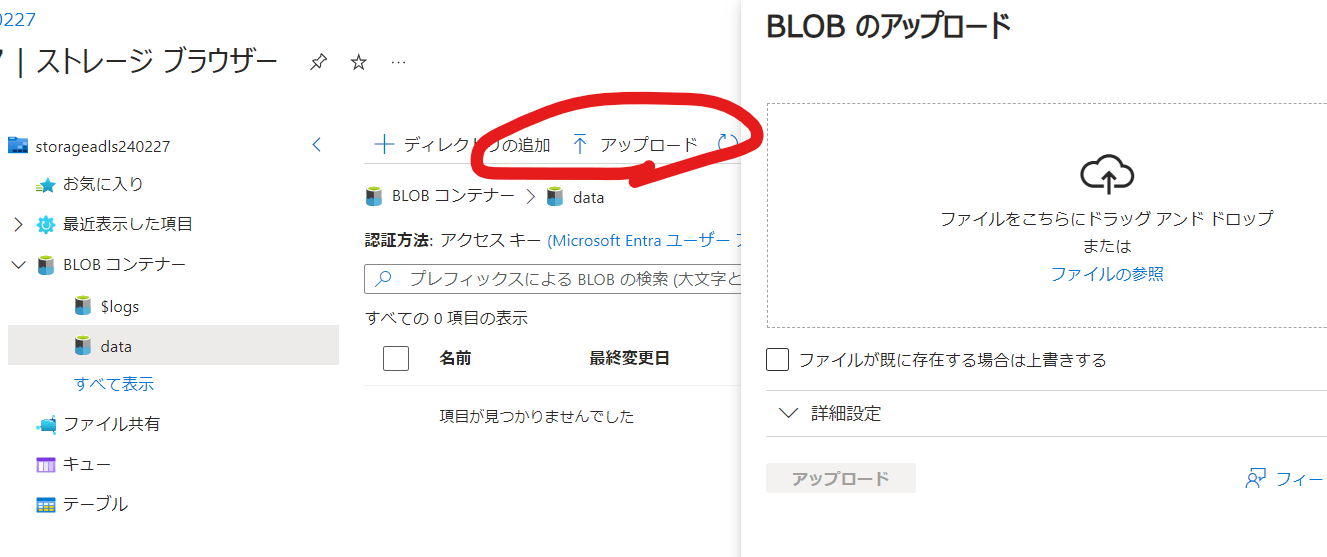
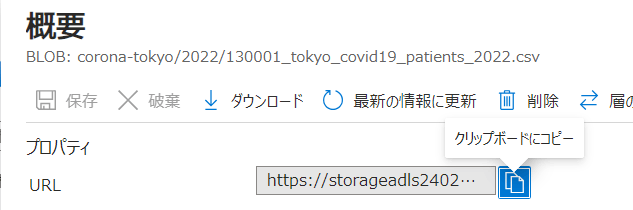
後でファイルのURLを指定するので、アップロード後に、ファイルのURLを保持しておきます。
Synapse Analyticsワークスペース作成
Synapseで検索すると、Azure Synapse Analyticsが出てきますので、クリックします。

作成時の設定値は以下のようにしました。



ほぼデフォルト値のまま作成しました。
Synapse StudioからSQLを実行
作成後、リソースの概要の真ん中ほどに、Synapse Studioを開くという項目があるのでクリックします。
新規でSQLスクリプトを指定します。

以下のような画面になりました。

エディタの部分に、以下のようなSQLを入れていきます。BULKのところは、先ほど保存していたURLに置き換えて実行します。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '<ファイルのURL>',
FORMAT='CSV',
PARSER_VERSION='2.0'
) AS [result]
下の方に、結果が表示されます。

オプションを変更
結果を変更するためのオプションは、以下のページにあります。
1行目を項目名として扱う
HEADER_ROW=TRUEを入れることで、1行目を項目名として扱います。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '<ファイルのURL>',
FORMAT='CSV',
HEADER_ROW=TRUE,
PARSER_VERSION='2.0'
) AS [result]
1行目が項目名として扱われました。

日本語を扱う
OPENROWSET()の後に、以下のようにWITH 句を使用して、読み取る列とタイプ・照合順序を指定できます。
日本語列に、文字化けしない照合順序を指定します。
WITH (
No VARCHAR (10)
,全国地方公共団体コード VARCHAR (10)
,都道府県名 VARCHAR (10) COLLATE Latin1_General_100_BIN2_UTF8
,市区町村名 VARCHAR (10)
,公表_年月日 VARCHAR (10)
,発症_年月日 VARCHAR (10)
,確定_年月日 VARCHAR (10)
,患者_居住地 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,患者_年代 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,患者_性別 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,患者_職業 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,患者_状態 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,患者_症状 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,患者_渡航歴の有無フラグ VARCHAR (1)
,患者_接触歴の有無フラグ VARCHAR (1)
,備考 VARCHAR (100) COLLATE Latin1_General_100_BIN2_UTF8
,退院済フラグ VARCHAR (1)
)
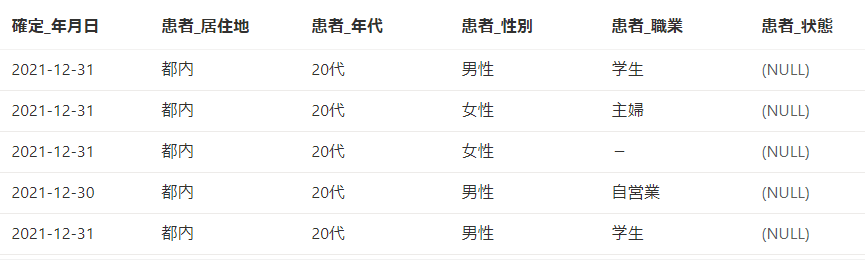
結果は以下のようになります。
複数ファイル・サブフォルダ
ワイルドカードを使うと、該当する複数ファイルを対象にします。
SELECT
count(*) as count
FROM
OPENROWSET(
BULK 'https://<コンテナーのURL>/corona-tokyo/2022/130001_tokyo_covid19_patients_2022-*',
FORMAT='CSV',
HEADER_ROW=TRUE,
PARSER_VERSION='2.0'
) AS [result]

フォルダパスにすると、フォルダ内の全ファイルを対象とします。
SELECT
count(*) as count
FROM
OPENROWSET(
BULK 'https://<コンテナーのURL>/corona-tokyo/2022/',
FORMAT='CSV',
HEADER_ROW=TRUE,
PARSER_VERSION='2.0'
) AS [result]
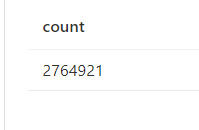
サブフォルダ内のファイルを全部検索する際は**と指定します、。
SELECT
count(*) as count
FROM
OPENROWSET(
BULK 'https://<コンテナーのURL>/corona-tokyo/**',
FORMAT='CSV',
HEADER_ROW=TRUE,
PARSER_VERSION='2.0'
) AS [result]

ファイルの削除・追加
試しにファイル130001_tokyo_covid19_patients_2022.csv(1,000,000行)を削除して、先ほどのSQLを実行してみます。

件数はちゃんと減っていました。

1件のデータのファイルをアップして検索してみます。確かに1件だけ増えています。

データソースを作ってアクセスする
今までは一つのSQLで検索していましたが、データソースやテーブルをあらかじめ作っておくことができます。
まずはデータベースを作成します。デフォルトのmasterではcreateできませんので、専用のデータベースを設けます。
CREATE DATABASE hogehoge
作成したら、Synapse Studioで接続データベースを変更します。

以下のcreate文を実行してデータソースを作成します。
CREATE EXTERNAL DATA SOURCE mysample
WITH ( LOCATION = 'https://<コンテナーのURL>/' )
その後、以下のSQLで検索できます、
SELECT count(*) FROM OPENROWSET(
BULK 'corona-tokyo/**'
, DATA_SOURCE='mysample'
,FORMAT='CSV'
, PARSER_VERSION='2.0'
) AS [result];
テーブルまで作る方法もあるのですがうまく動かなかったので、出来たら追記します。
料金について
作成したリソースが2つありますので、その両方が対象になりそうです。
ストレージ
以下のページに詳細があります。下の質問の箇所に例があります。
以下の点にかかるようです。
- 保存料金
- トランザクション料金
Synapse Analytics
Synapse Analyticsにも料金が発生する模様です。
今回はサーバレスを用いましたので、[データウェアハウス]タブの[サーバレス]が該当しそうです。
1TBあたりのデータ処理数が$5なので、Athenaと同じくらいでしょうか。
おわりに
今回は、ストレージ上のファイルに対してSQLなどでクエリ出来るAzure Data Lake Storageを紹介しました。
常々、DBデータの管理が面倒と感じていますので、小規模であればファイルの管理で賄える、これらのサービスに期待をしております。
この記事がどなたかのお役に立てれば幸いです。
Discussion