Cloud Storage・BigQuery・dbt cloud・LookerStudioでブラウザ履歴可視化ツールのパイプライン作成
はじめに
以前ブラウザ履歴の可視化ツールをdbt cloudなしで作成してみました。
さらなる自動化の前段階として今度はdbt cloudをETLツールとして使用して同じようなツールを作成しました。
今回は
①ローカルからpythonで履歴情報をcsv化
②CLIで設定後pythonでcsvファイルをCloudStorageにアップロード
③CloudStorageからBigQueryへ
④BigQueryで外部テーブル作成
⑤dbt CloudでBigQuery上のデータを処理・結合しBigQueryへ
⑥LookerStudioで可視化
という流れでやってみます。
Cloud Storage
前回は加工したcsvをCloud Storageに置いたが今回は生データを置き、データ前処理はdbt Cloudに委ねることとする。
CloudStorage
生データとしてブラウザ履歴のデータ二つ(urlsとvisit)をcsvとして保存する。
前回は履歴データの特定の列を取得してcsvとしCloud Storageに保管した。
しかし今回はそうではなく生データを取得してCloud Storageに置きたい。なので以前のコードを修正しました。
urls,visitsテーブルをcsvへ変換
import os
import shutil
import duckdb
from datetime import datetime
# Chrome履歴ファイルのパス
history_path = os.path.expanduser('~/Library/Application Support/Google/Chrome/Profile 6/History')
temp_path = '/tmp/ChromeHistory_temp'
shutil.copy2(history_path, temp_path)
con = duckdb.connect(temp_path)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
urls_csv = f"browser_history_urls_{timestamp}.csv"
con.sql(f"""
COPY (
SELECT *
FROM urls
) TO '{urls_csv}' (HEADER, DELIMITER ',')
""")
visits_csv = f"browser_history_visits_{timestamp}.csv"
con.sql(f"""
COPY (
SELECT *
FROM visits
) TO '{visits_csv}' (HEADER, DELIMITER ',')
""")
con.close()
os.remove(temp_path)
作成した2つのcsvをcloud_storageへとアップロードする。
ひとまずローカルからcloud storageにcsvをアップロードするためにCLIで操作します。
なので以下のコマンドを使用します。
uv add google-cloud-storage
brew install google-cloud-sdk
以下を入力すると自分のGoogleアカウントでのログインが求められますので自分のアカウントでログインします。この辺りはgoogleのログインに慣れてる人にとっては楽ですね。
gcloud auth application-default login
プロジェクトを設定
gcloud config set project YOUR_PROJECT_ID
これでアップロード先のプロジェクトを指定します。その後以下のpythonコードを作成します。
cloud_storageへのアップロード
from google.cloud import storage
import os
import glob
from datetime import datetime
def upload_browser_history_to_gcs(bucket_name='browser-viz-data'):
"""
ローカルのCSVファイルをCloud Storageにアップロード
"""
# Cloud Storageクライアント初期化
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
# 最新のCSVファイルを探す
csv_files = glob.glob('browser_history_raw_*.csv')
if not csv_files:
print("❌ CSVファイルが見つかりません")
return
# 最新のファイルを選択
latest_csv = max(csv_files, key=os.path.getctime)
# Cloud Storageのパス(raw/フォルダに保存)
blob_name = f'raw/{os.path.basename(latest_csv)}'
blob = bucket.blob(blob_name)
# アップロード
blob.upload_from_filename(latest_csv)
print(f"✅ アップロード完了: gs://{bucket_name}/{blob_name}")
# ローカルファイルを削除(オプション)
# os.remove(latest_csv)
if __name__ == "__main__":
# 実行
upload_browser_history_to_gcs()
以下のような感じで二つのcsvをアップロードできました。
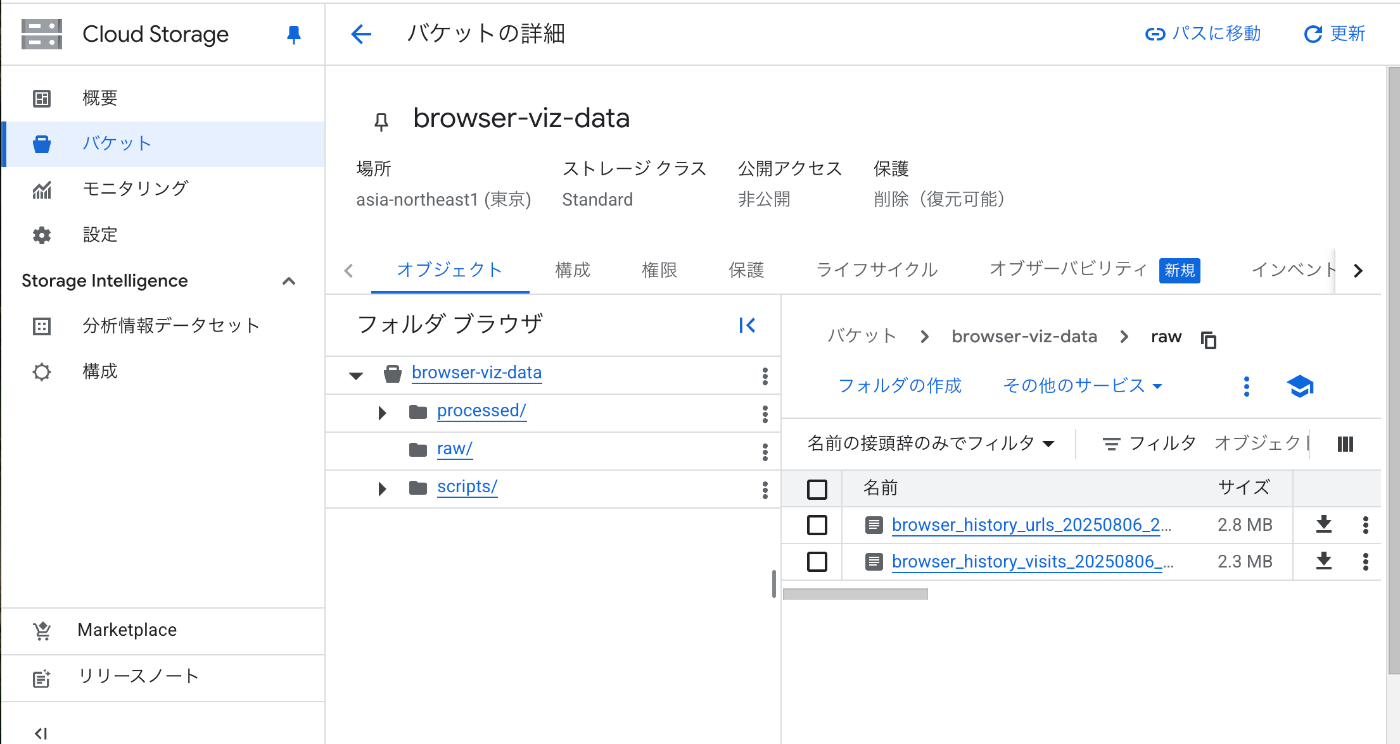
BigQuery
BigQueryで外部テーブルを作成
今生データはCloud Storage上にあるが、dbt CloudがCloud StorageのCSVを読み込めるようにしたい。そのため外部テーブルを作成します。(visitsも同様)
CREATE OR REPLACE EXTERNAL TABLE `browser-viz.browser_analytics_raw.urls_external`
OPTIONS (
format = 'CSV',
uris = ['gs://browser-viz-data/raw/browser_history_urls_*.csv'],
skip_leading_rows = 1,
field_delimiter = ',',
allow_jagged_rows = true,
allow_quoted_newlines = true
);
dbt cloud
dbt cloudの環境設定
以下が初期画面です。

とりあえずOrchestration / Environments / Create New Environment
で環境設定します。

connectionの部分は今回Bigqueryを使用するのでBigQueryを選択します。

ここでUpload a Service Account JSON file というような文言が出てきます。
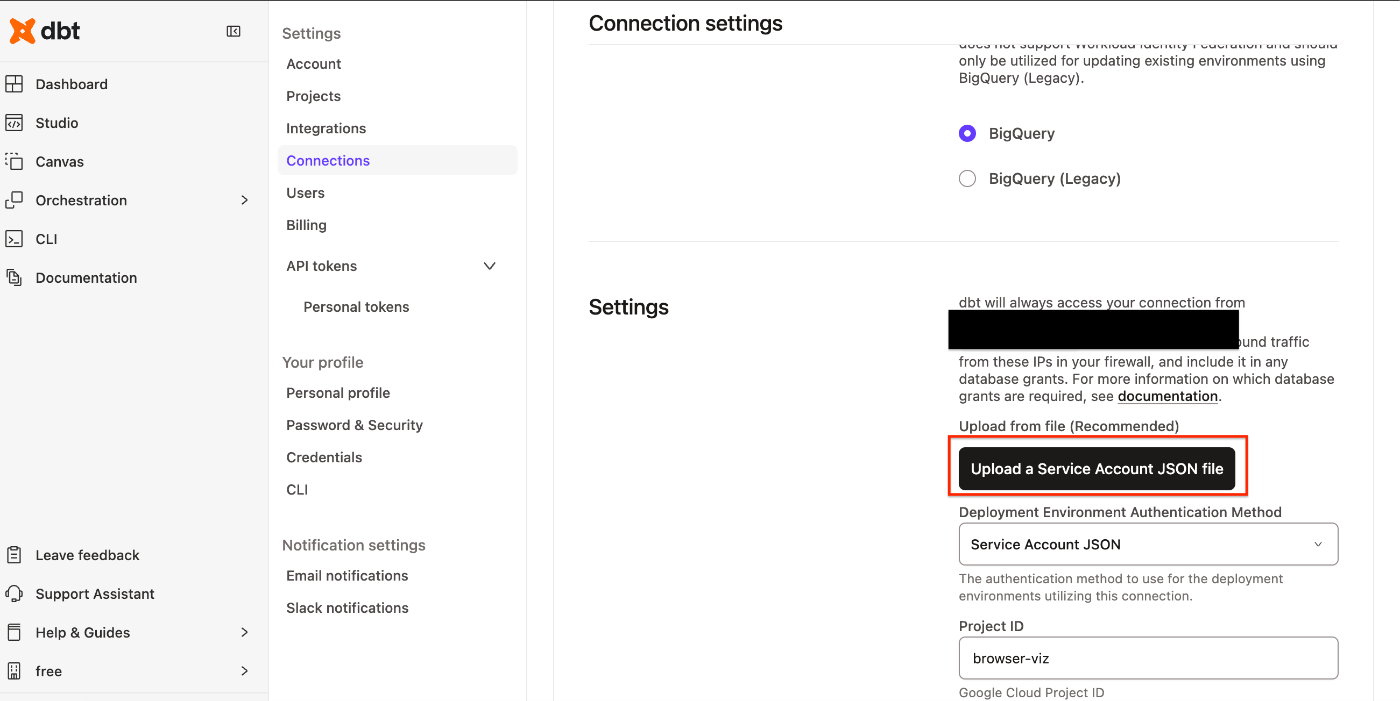
接続情報用のjsonを作成する必要があります。
例えば以下のようなコードを実行して作成します。
gcloud iam service-accounts create dbt-cloud-sa \
--display-name="dbt Cloud Service Account" \
--project=browser-viz
またロールなどは以下のようなコードで設定します。
gcloud projects add-iam-policy-binding browser-viz \
--member="serviceAccount:dbt-cloud-sa@xxxxxxxxxxxxx" \
--role="roles/bigquery.dataEditor"
そして以下のコマンドでjsonファイルをダウンロードし先ほどのところでアップロードします。
gcloud iam service-accounts keys create ~/dbt-cloud-key.json \
--iam-account=xxxxxxxxxxxxxxxxx
あとはテスト接続しうまくいっているかどうか確認します。

Credentialのエラー対応?
クエリを作成するためにStudioを利用しようとしたが以下のエラーが出た。
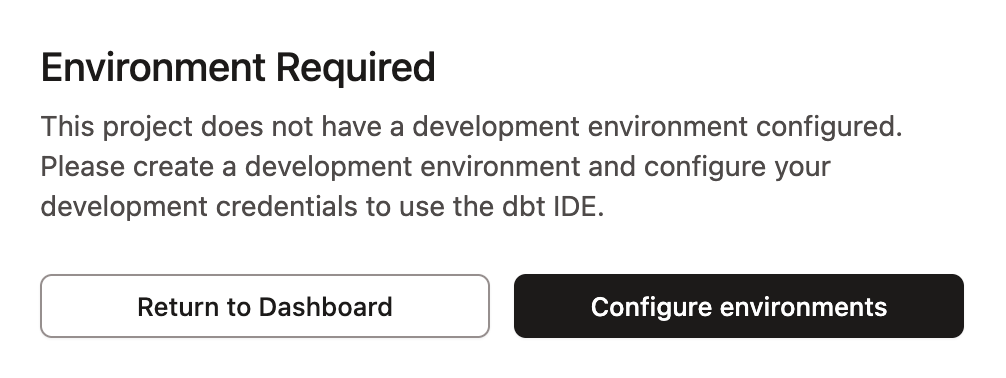
Set deployment type の部分でProdでないといけない?のか設定すると問題なく使用できるようになった。(要検証)


またlocationもBigQuery側に合わせることが必要?(dbtが別のロケーションをデフォルトで探しにいくエラーが自分の場合は出てしまったため。)
Studio でクエリを作成する。
Create New fileで新しいファイルを作成します。

このような画面が出てくるので、initialize します。

すると左のサイドバーにdbtのディレクトリ構成が出てきますのでこれでdbtの機能が使用できます。
クエリを置くmodelフォルダに新たにrawフォルダを作成し次にファイル作成します。

source.ymlを置き、必要な設定を書きます。BigQueryの外部テーブル用の設定です。


今度はstageフォルダにurls用のクエリを書くためのファイルを作成します。
以下を実行してみます!
urls
WITH source AS (
-- sourceマクロを使わず、直接テーブル名を指定
SELECT * FROM `テーブル名`
)
SELECT
*,
REGEXP_EXTRACT(url, r'https?://(?:www\.)?([^/]+)') AS domain
FROM source
WHERE url NOT LIKE '%chrome://%'
AND url NOT LIKE '%file://%'
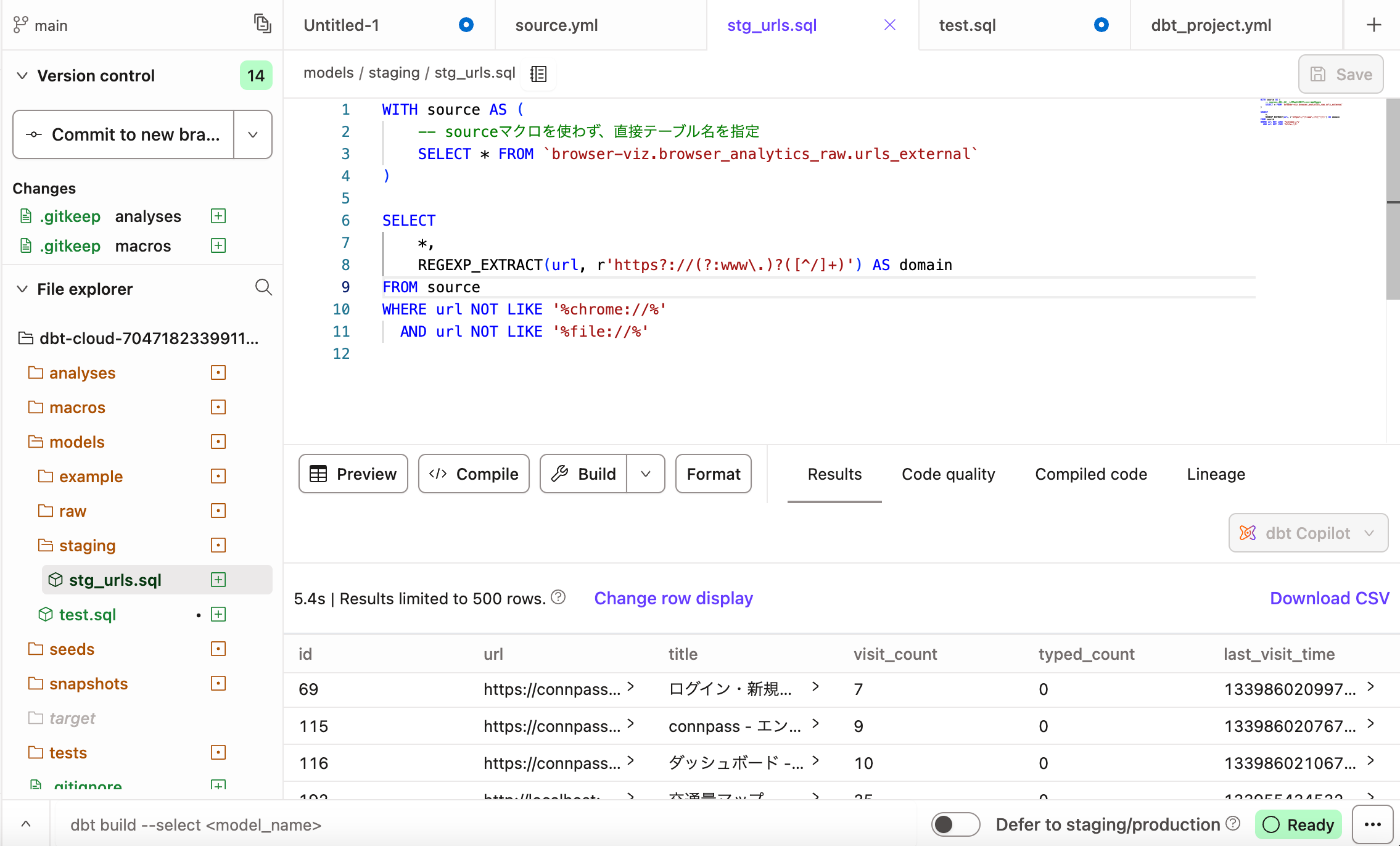
これでBigquery上のデータをdbt cloudから接続できました。
visit用のクエリも同様です。
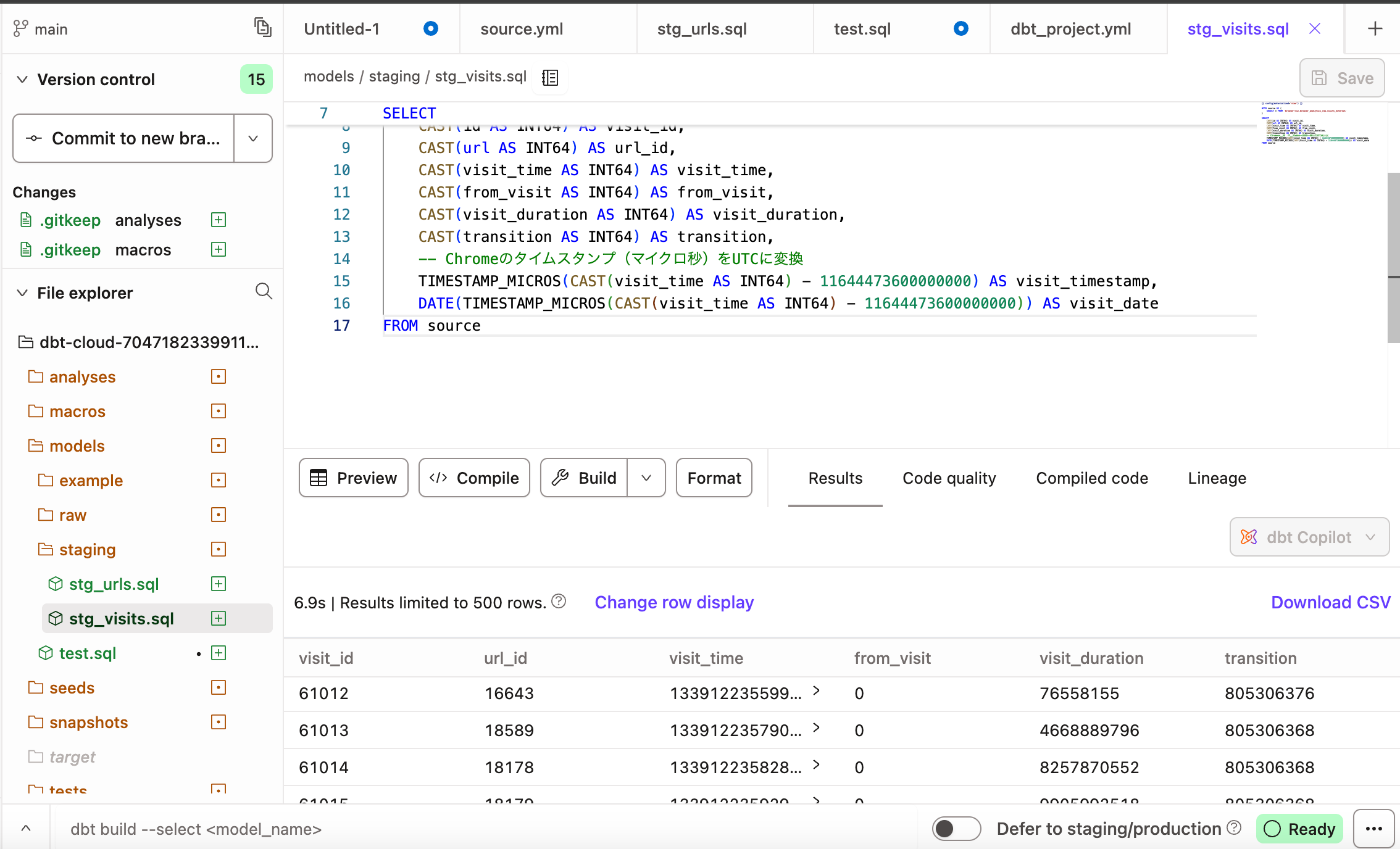
またurls とvisitを結合するクエリも以下のように書きます。
domain
{{ config(materialized='table') }}
WITH url_visits AS (
SELECT
u.domain,
COUNT(DISTINCT v.visit_id) AS actual_visit_count,
MAX(u.visit_count) AS recorded_visit_count,
COUNT(DISTINCT v.visit_date) AS days_visited,
MAX(v.visit_timestamp) AS last_visit_time
FROM {{ ref('stg_urls') }} u
LEFT JOIN {{ ref('stg_visits') }} v
ON u.id = v.url_id
WHERE u.domain IS NOT NULL
GROUP BY 1
),
ranked AS (
SELECT
*,
ROW_NUMBER() OVER (ORDER BY actual_visit_count DESC) AS rank
FROM url_visits
)
SELECT * FROM ranked
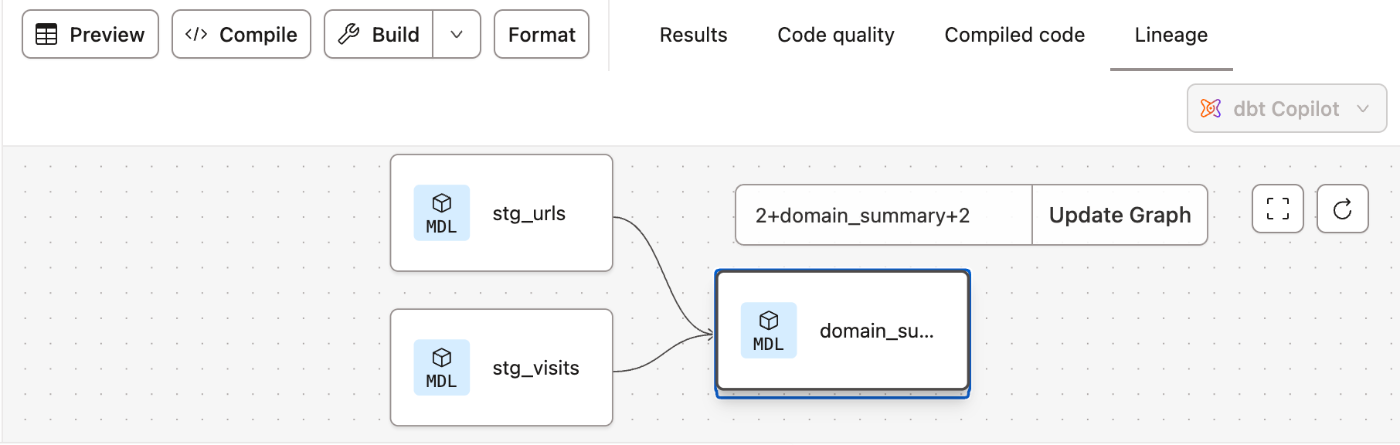
リネージを見るとこういった感じになります。
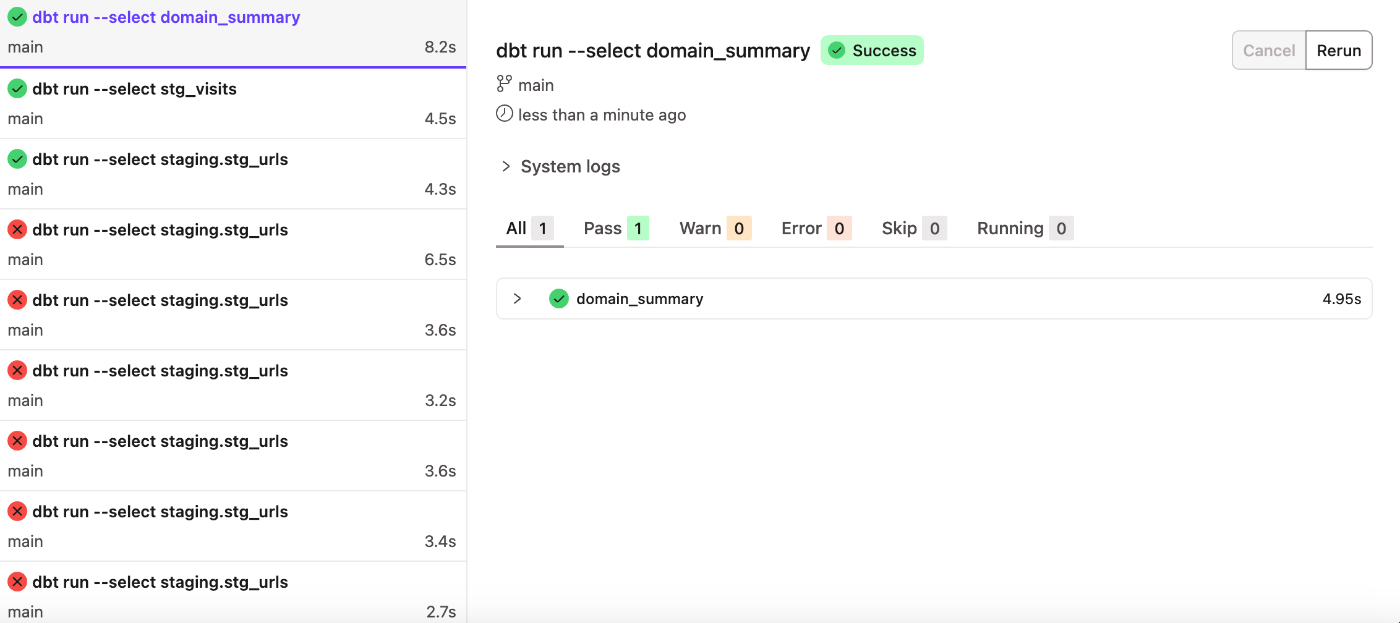
dbt runでBigQuery上にデータを送る。
以下をdbt cloudのコンソールで実行することでBigQueryのデータセットにdbt上でデータ処理したデータを送ることができます。
dbt run --select クエリファイル名
Looker Studio
BigQueryからLookerStuio でデータ可視化
BigQueryのデータセットを確認すると以下のようなデータが確認できます。
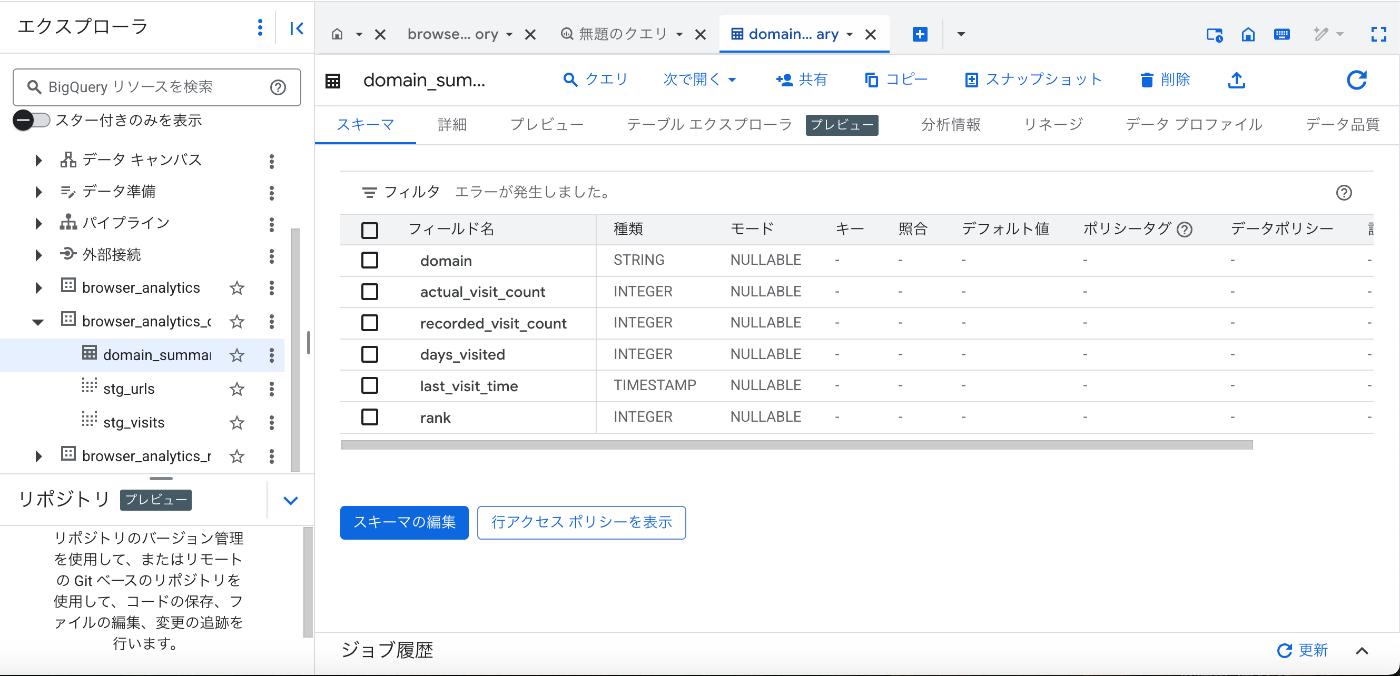
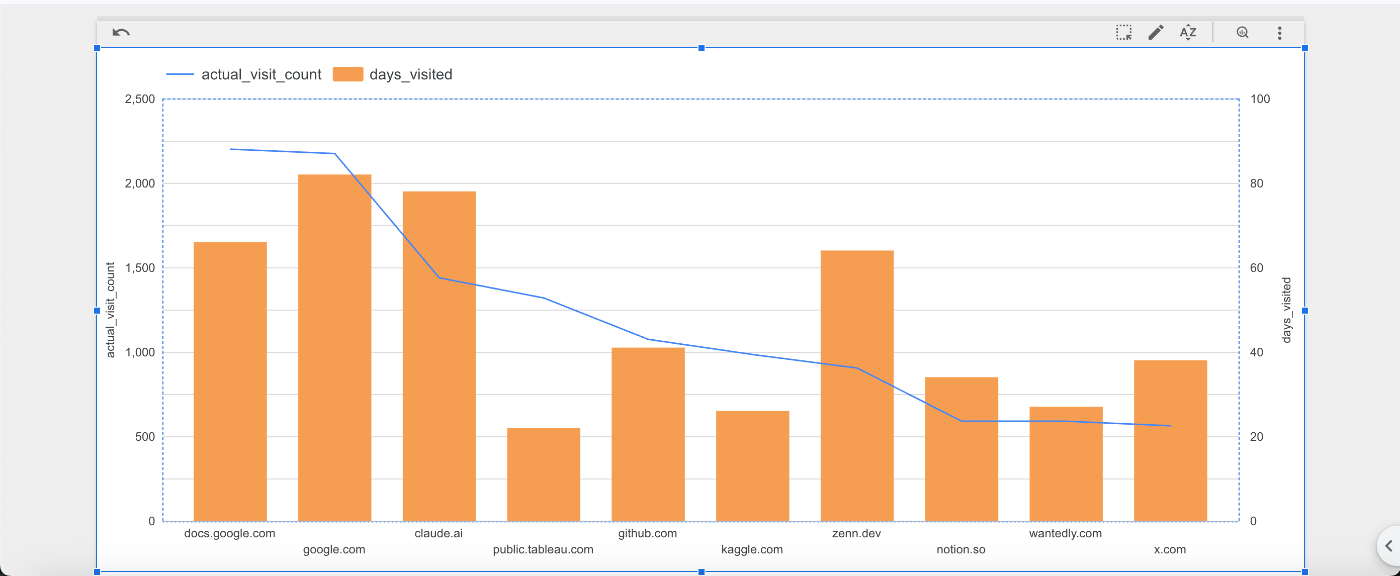
このdomainをLooker Studioで可視化すると以下のようになりました。
前回と違って日毎のカウントやvisitテーブルから取得した訪問数を使用したりできました!
まとめ
今回は最初のデータは生データとしdbt cloudで加工してみました。
途中記事の下書きが飛ぶなどしたのでどこか間違っているかもしれませんが、簡易的なパイプラインの構築はできたと思います。
次はインフラ構築の自動化やパイプラインの自動化を試したいと思います!
Discussion