GCP ✖️ Looker studioでブラウザ履歴からどのサイトを頻繁に見たか可視化してみた
はじめに
何か小規模でも良いのでデータ基盤を作った面白そうな物がつくれないかなと思っていました。
そしてふと自分のブラウザ履歴のドメイン部分のみ取得してどのサイトによくアクセスするか可視化したら面白そうだなと思い今回この記事を作ることにしました。
GCPの各種サービスで簡易的なデータパイプラインを作ってみます!
使用技術
GCP: Cloud Storage, BigQuery, Looker Studio
ハンズオン
まずはGCPを触る。-GCPプロジェクトの作成-
GCPについてはあまり触る機会がなく、思い出しながらやってみました。
どうも最初にGCPプロジェクトというものを作るみたいですね。
以下のサイトに飛んでみましょう。以前プロジェクトを作成していたので最初の設定や課金の設定などは今回は省きます。
ヘッダー部分の赤枠部分をクリックします。(最初は以前作成したプロジェクト名がある状態でした。)

次に新しいプロジェクトを作成を選択します。

プロジェクト名は「browser-viz」とし、作成を押します。
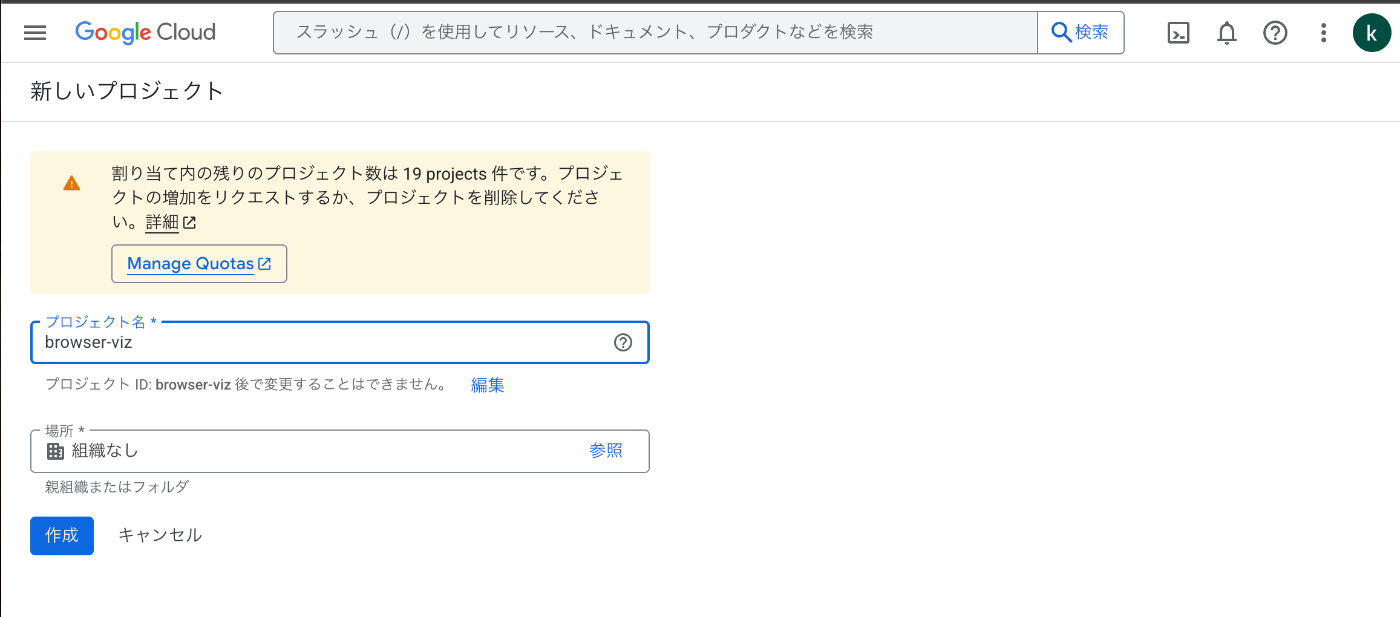
これでプロジェクトが作成されました🙌
必要なAPIの有効化
今回使用するのは以下のAPIとなります。
BigQuery API
Cloud Storage API
上二つはプロジェクト作成時に有効化されていた?ようなので
APIを有効化するには一番上の検索窓に該当のAPI名を入力すると候補が出てきます。

その後有効化するを押すと...無事有効化され下のような画面に遷移します。
DuckDBでブラウザ履歴データを前処理・エクスポート
まずはどんなデータか見てみる。
以下のコードでローカルにある履歴データを取得し一時ファイルにコピーします。そもそもブラウザ履歴データはsqlite形式で保存されている?らしくcon = duckdb.connect(temp_path)でduckdbに直繋ぎして「urls」テーブルの「url」列を選択すると履歴のURLが見れる状態になってます。
ブラウザ履歴から履歴データを抽出するコード
import os
import shutil
import duckdb
history_path = os.path.expanduser('~/Library/Application Support/Google/Chrome/Profile 6/History')
temp_path = '/tmp/ChromeHistory_temp'
shutil.copy2(history_path, temp_path)
con = duckdb.connect(temp_path)
print(con.sql("SELECT url FROM urls"))
とりあえずProfile 6というのが仕事用アカウントのファイルのようなのでそこから履歴を抽出しました。
この結果例えば以下のようなurlが取得できます。(自分の場合は9552件ありました。)
「https://www.youtube.com/watch?v=XXXXXXXXXXX」
URLからドメイン名のみ抜き出す。
今回はどのサイトをよくみるか?なのでドメイン部分のyoutube.comとかを抜き出せるようにすれば良いかなと思い以下のコードにしてみました。
ブラウザ履歴から履歴データを抽出するコード
import os
import shutil
import duckdb
history_path = os.path.expanduser('~/Library/Application Support/Google/Chrome/Profile 6/History')
temp_path = '/tmp/ChromeHistory_temp'
shutil.copy2(history_path, temp_path)
con = duckdb.connect(temp_path)
result = con.sql("""
SELECT
regexp_extract(url, 'https?://(?:www\.)?([^/]+)', 1) as domain,
visit_count
FROM urls
WHERE url NOT LIKE '%file://%'
AND url NOT LIKE '%chrome://%'
AND url NOT LIKE '%chrome-extension://%'
""")
print(result)
regexp()でurlからドメイン名を取得しています。(www.がついている場合は除去)
あとはvisit_countという訪問回数を格納する列が元々あったのでそこから訪問回数を取得しました。
大体以下の感じになります。
┌──────────────────────────┬─────────────┐
│ domain │ visit_count │
│ varchar │ int64 │
├──────────────────────────┼─────────────┤
│ connpass.com │ 7 │
│ · │ · │
│ · │ · │
│ · │ · │
│ console.cloud.google.com │ 1 │
│ console.cloud.google.com │ 1 │
│ claude.ai │ 1 │
├──────────────────────────┴─────────────┤
│ 9552 rows (20 shown) 2 columns │
└────────────────────────────────────────┘
現状だと重複している物もあるのですがとりあえずこのまま読み込みます。
csvとして保存する。
duckdbならSQLの前後にCOPY TOでcsvにそのまま変換できます。
csvとして保存
import os
import shutil
import duckdb
from datetime import datetime
# Chrome履歴ファイルのパス
history_path = os.path.expanduser('~/Library/Application Support/Google/Chrome/Profile 6/History')
temp_path = '/tmp/ChromeHistory_temp'
# 一時ファイルにコピー
shutil.copy2(history_path, temp_path)
# DuckDBに接続
con = duckdb.connect(temp_path)
# CSVファイル名
csv_filename = f"browser_history.csv"
# 直接CSVにエクスポート
con.sql(f"""
COPY (
SELECT
regexp_extract(url, 'https?://(?:www\.)?([^/]+)', 1) as domain,
visit_count
FROM urls
WHERE url NOT LIKE '%file://%'
AND url NOT LIKE '%chrome://%'
AND url NOT LIKE '%chrome-extension://%'
AND regexp_extract(url, 'https?://(?:www\.)?([^/]+)', 1) IS NOT NULL
) TO '{csv_filename}' (HEADER, DELIMITER ',')
""")
con.close()
os.remove(temp_path)
これで必要そうなデータを出力できました。
Cloud Storageバケットの作成(コンソール)
次はcsvの置き場をGCPに作ります。
以下を開くとCloud Storageバケットが開きます。
Google Storage
バケットを作成を押し、バケット名やロケーション、ストレージクラスなどを選択します。

バケットが作成されたのであとはファイルをアップロードします。(ドラッグ&ドロップでも可)

このあたりはAWS の S3と変わらないですね。

BigQueryでのテーブル作成
BigQueryでデータセットの作成。
次はBigQueryでストレージのデータをSQLで取得してみましょう。
BigQuery

赤枠部分を押すと以下のような画面が開きました。

ここにデータセット名やロケーション名を入力します。
BigQueryでテーブルを作成しcsvからデータを読み込む。
作成したデータセットを選択しテーブルを作成を押します。

バケットにcsvが既に入っているのでGCSバケットからデータを選択が使用できます。
これでテーブル作成を押します。(スキーマは自動検出とします。)
BigQueryで作成したテーブルのデータを見てみる
テーブル作成されたので簡単なクエリでデータを見てみます。
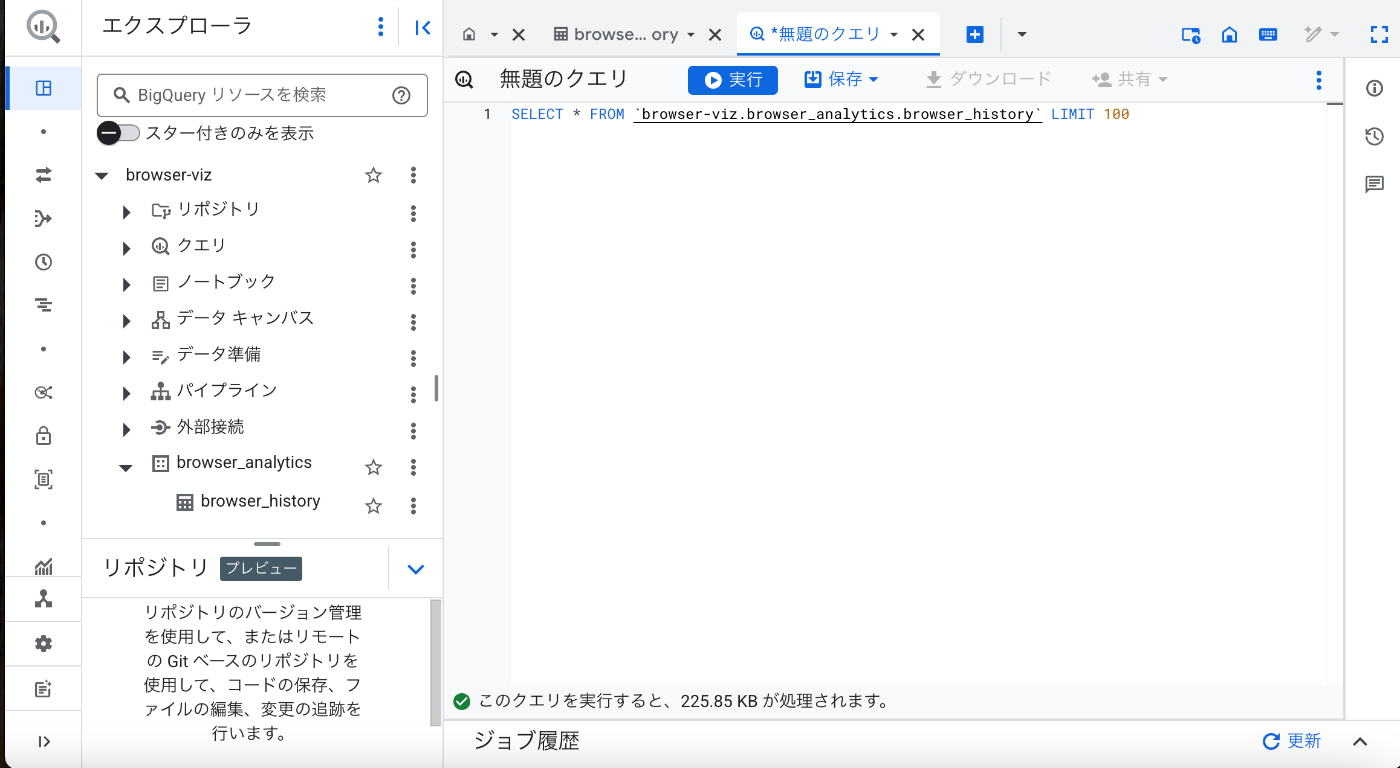
SELECT * FROM `browser-viz.browser_analytics.browser_history` LIMIT 100
これでデータは表示されました。

visitcountが0回になっているものもありますがどうも大元のデータだと正しくカウントされないようなことがあるみたいです。
最後に可視化してみましょう。
Looker Studioでの可視化
データの接続
以下のURLでLooker Studioに飛び、作成→データセットを選択します。
Lookerstudio
先ほどBigQueryでテーブルを作成したのでそれをデータソースにします。

先ほど作成したテーブルを選択し接続します。

あとはレポートの作成を押します。
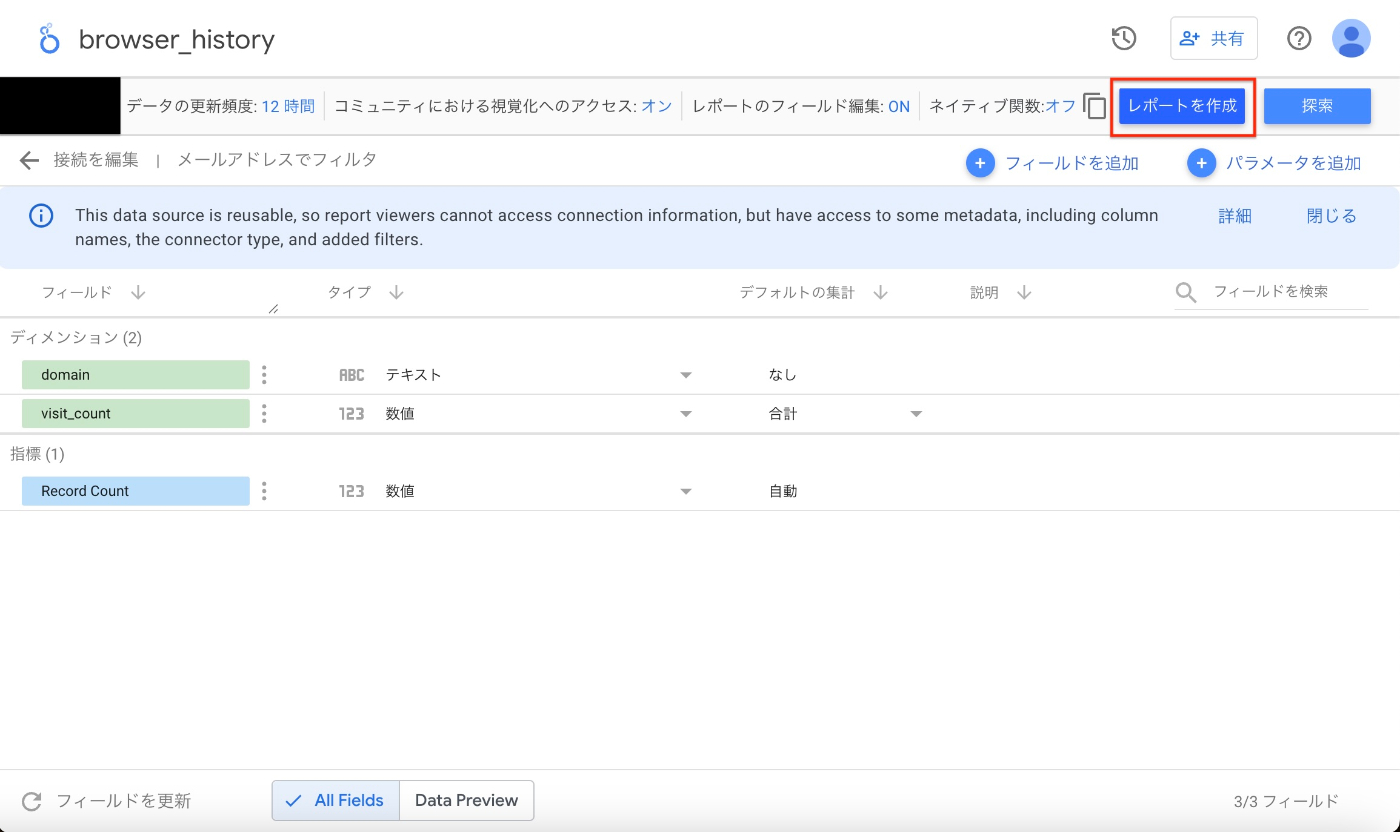
これでLooker Studioの可視化画面を表示できました!

ドメイン別訪問回数を可視化してみる。
domainをフィールドにドラッグ&ドロップすると表が自動で作成されます。

あとはvisitcountを「指標」にドラッグ&ドロップします。
そしてグラフの種類を棒グラフにすると...
グラフが表示されました!あとは降順に並び替えします。

最終的にはこんな感じのグラフになりました。

スタイルで棒の数を変更することで表示数も変更可能です!
結構claudeの使用量がやっぱり多くなっていますね。(Githubの訪問回数の方が少ないのは問題...)
ただgoogleも数が多いのは当然だし、docsと重複していたりするのでgoogleは省いても良かったかもしれませんね。
まとめ
今回はWebブラウザ履歴をcsv化し、BigQueryに読み込みしたあとLookerStudioで可視化までやってみました。権限周りなども複雑な設定なく意外とすんなりいってびっくりしています。
次回はvisitcountの修正とCI/CDによる自動化、データ前処理をdbtで行ってみるなどにトライしてみたいと思います。
Discussion